目录
理解一切皆文件
我们之前老是说一切皆文件,但是没深入说过。
⾸先,在windows中是⽂件的东西,它们在linux中也是⽂件;其次⼀些在windows中不是⽂件的东 西,⽐如进程、磁盘、显⽰器、键盘这样硬件设备也被抽象成了⽂件,你可以使⽤访问⽂件的⽅法访 问它们获得信息;甚⾄管道,也是⽂件;将来我们要学习⽹络编程中的socket(套接字)这样的东西, 使⽤的接⼝跟⽂件接⼝也是⼀致的。
总之一句话,在linux中把所有的东西都抽象成文件。
在OS看来一个个硬件都是文件,访问读写硬件都是本质上都是硬件文件的访问读写。
这样做最明显的好处是,开发者仅需要使⽤⼀套API和开发⼯具,即可调取Linux系统中绝⼤部分的资源。
举个简单的例⼦,Linux中⼏乎所有读(读⽂件,读系统状态,读PIPE)的操作都可以⽤ read 函数来进⾏;⼏乎所有更改(更改⽂件,更改系统参数,写PIPE)的操作都可以⽤ 数来进⾏。
看底层代码:
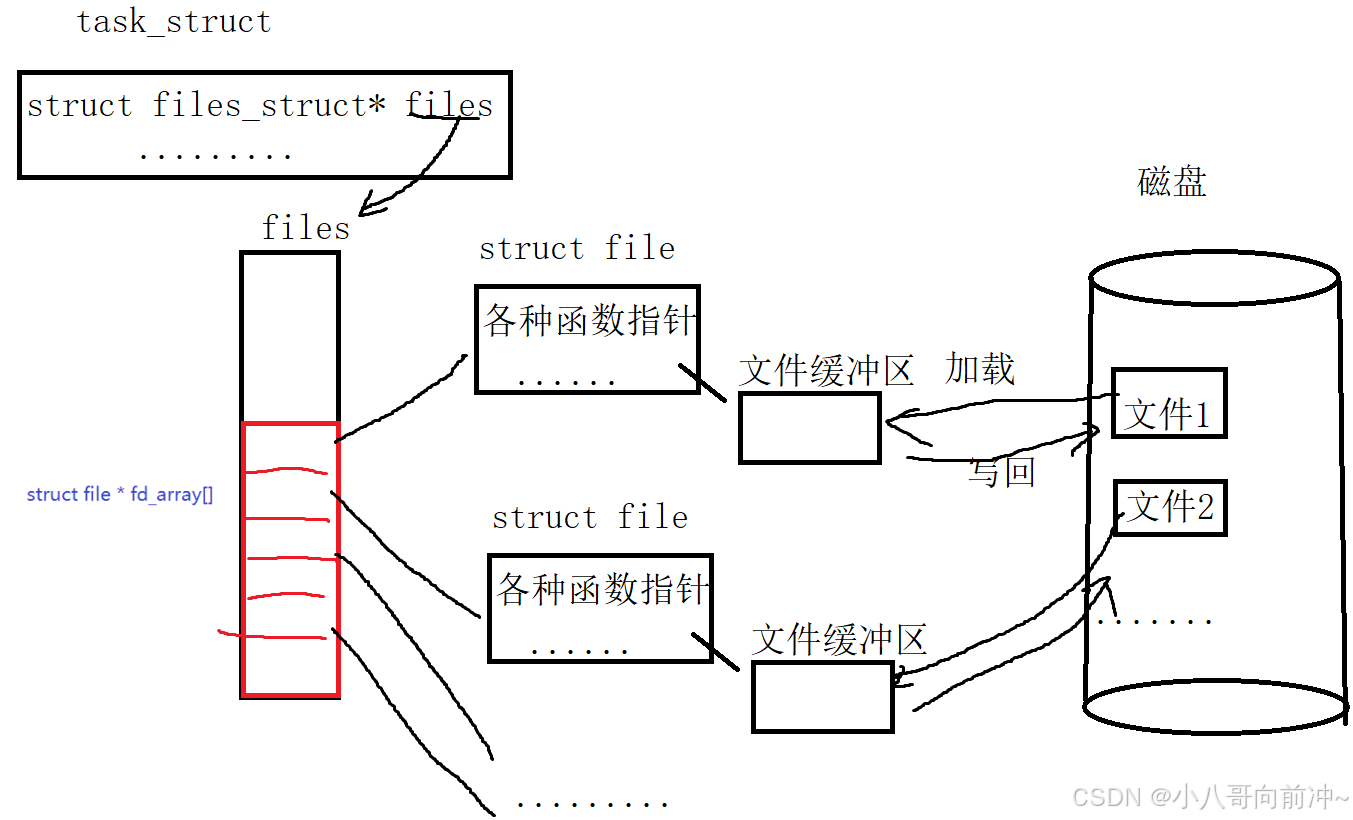
struct file 中的 f_op 指针指向了⼀个 file_operations 结构体,这个结构 体中的成员除了structmodule*owner其余都是函数指针。file_operation 就是把系统调⽤和驱动程序关联起来的关键数据结构,这个结构的每⼀个成员都 对应着⼀个系统调⽤。读取 file_operation 中相应的函数指针,接着把控制权转交给函数,从⽽ 完成了Linux设备驱动程序的⼯作。
这样对硬件的读写,只需要统一通过它们的read,write函数指针方法进行访问即可!

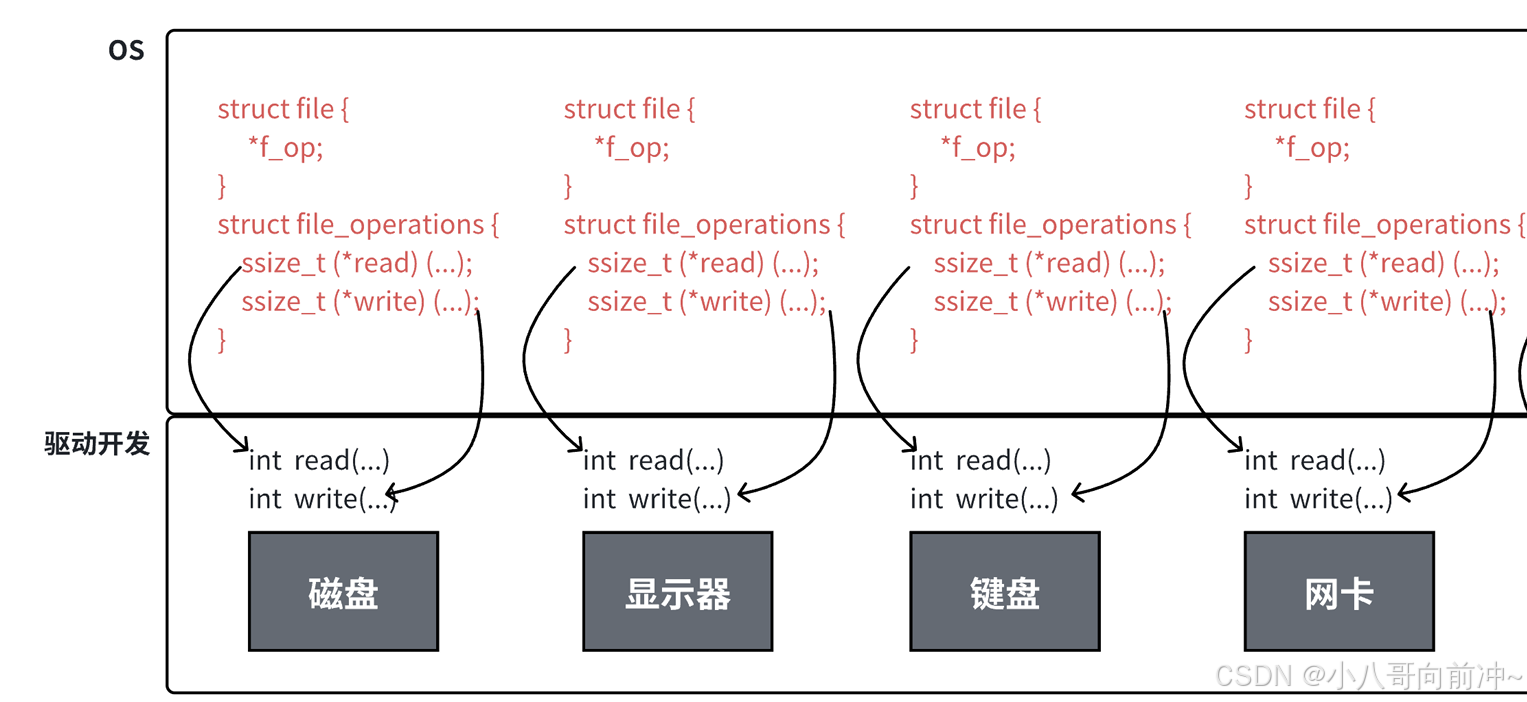
上图中的外设,每个设备都可以有⾃⼰的read、write,但⼀定是对应着不同的操作⽅法!!但通过 struct file 下 file_operation 中的各种函数回调,让我们开发者只⽤file便可调取Linux系 统中绝⼤部分的资源!!这便是"linux下⼀切皆⽂件"的核⼼理解。
缓冲区
缓冲区是内存空间的⼀部分。也就是说,在内存空间中预留了⼀定的存储空间,这些存储空间⽤来缓 冲输⼊或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输⼊设备还是输出设 备,分为输⼊缓冲区和输出缓冲区。
为什么要引⼊缓冲区机制
- 读写⽂件时,如果不会开辟对⽂件操作的缓冲区,直接通过系统调⽤对磁盘进⾏操作(读、写等),那么 每次对⽂件进⾏⼀次读写操作时,都需要使⽤读写系统调⽤来处理此操作,即需要执⾏⼀次系统调 ⽤,执⾏⼀次系统调⽤将涉及到CPU状态的切换,即从⽤⼾空间切换到内核空间,实现进程上下⽂的 切换,这将损耗⼀定的CPU时间,频繁的磁盘访问对程序的执⾏效率造成很⼤的影响。
- 为了减少使⽤系统调⽤的次数,提⾼效率,我们就可以采⽤缓冲机制。⽐如我们从磁盘⾥取信息,可 以在磁盘⽂件进⾏操作时,可以⼀次从⽂件中读出⼤量的数据到缓冲区中,以后对这部分的访问就不 需要再使⽤系统调⽤了,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数, 再加上计算机对缓冲区的操作⼤⼤快于对磁盘的操作,故应⽤缓冲区可⼤⼤提⾼计算机的运⾏速度。
- ⼜⽐如,我们使⽤打印机打印⽂档,由于打印机的打印速度相对较慢,我们先把⽂档输出到打印机相 应的缓冲区,打印机再⾃⾏逐步打印,这时我们的CPU可以处理别的事情。可以看出,缓冲区就是⼀ 块内存区,它⽤在输⼊输出设备和CPU之间,⽤来缓存数据。它使得低速的输⼊输出设备和⾼速的 CPU能够协调⼯作,避免低速的输⼊输出设备占⽤CPU,解放出CPU,使其能够⾼效率⼯作。
我们这里说的缓冲区是用户级,语言级,C语言提供的库缓冲区。
但是OS中也有一个内核级的文件缓冲区,当利用库函数将内容写入文件时(fwrite等),写入的是C语言库缓冲区,并不是内核级的缓冲区,所以才有我们为什么有时候printf没有加\n时,打印的内容不会立马出现。
由库函数写入C语言库缓冲区的内容,然后会写入内核级的缓冲区,最终才会真正写入磁盘文件。
调用系统调用将内容写入文件,是直接写入内核级的缓冲区,所以根本不需要考虑刷新问题。
那这个C语言提供的库缓冲区是要怎么才会刷新到内核级别的缓冲区?
刷新到了内核缓冲区,最后写入到磁盘文件是由OS决定的,我们目前认为只要内容到了内核缓冲区就是写入到了磁盘文件。
缓冲类型
标准I/O提供了3种类型的缓冲区。
- 全缓冲区:这种缓冲⽅式要求填满整个缓冲区后才进⾏I/O系统调⽤操作。对于磁盘⽂件的操作通 常使⽤全缓冲的⽅式访问。(这种效率最高)
- ⾏缓冲区:在⾏缓冲情况下,当在输⼊和输出中遇到换⾏符时,标准I/O库函数将会执⾏系统调⽤ 操作。当所操作的流涉及⼀个终端时(例如标准输⼊和标准输出),使⽤⾏缓冲⽅式。因为标准 I/O库每⾏的缓冲区⻓度是固定的,所以只要填满了缓冲区,即使还没有遇到换⾏符,也会执⾏ I/O系统调⽤操作,默认⾏缓冲区的⼤⼩为1024字节(1KB)。
- ⽆缓冲区:⽆缓冲区是指标准I/O库不对字符进⾏缓存,直接调⽤系统调⽤。标准出错流stderr通 常是不带缓冲区的,这使得出错信息能够尽快地显⽰出来。
一句话,对于显示器写入,一般是行缓冲,对于磁盘普通文件写入,一般是全缓冲。
除了上述列举的默认刷新⽅式,下列特殊情况也会引发缓冲区的刷新:
- 缓冲区满时
- 强制刷新(执⾏flush语句)
- 进程退出
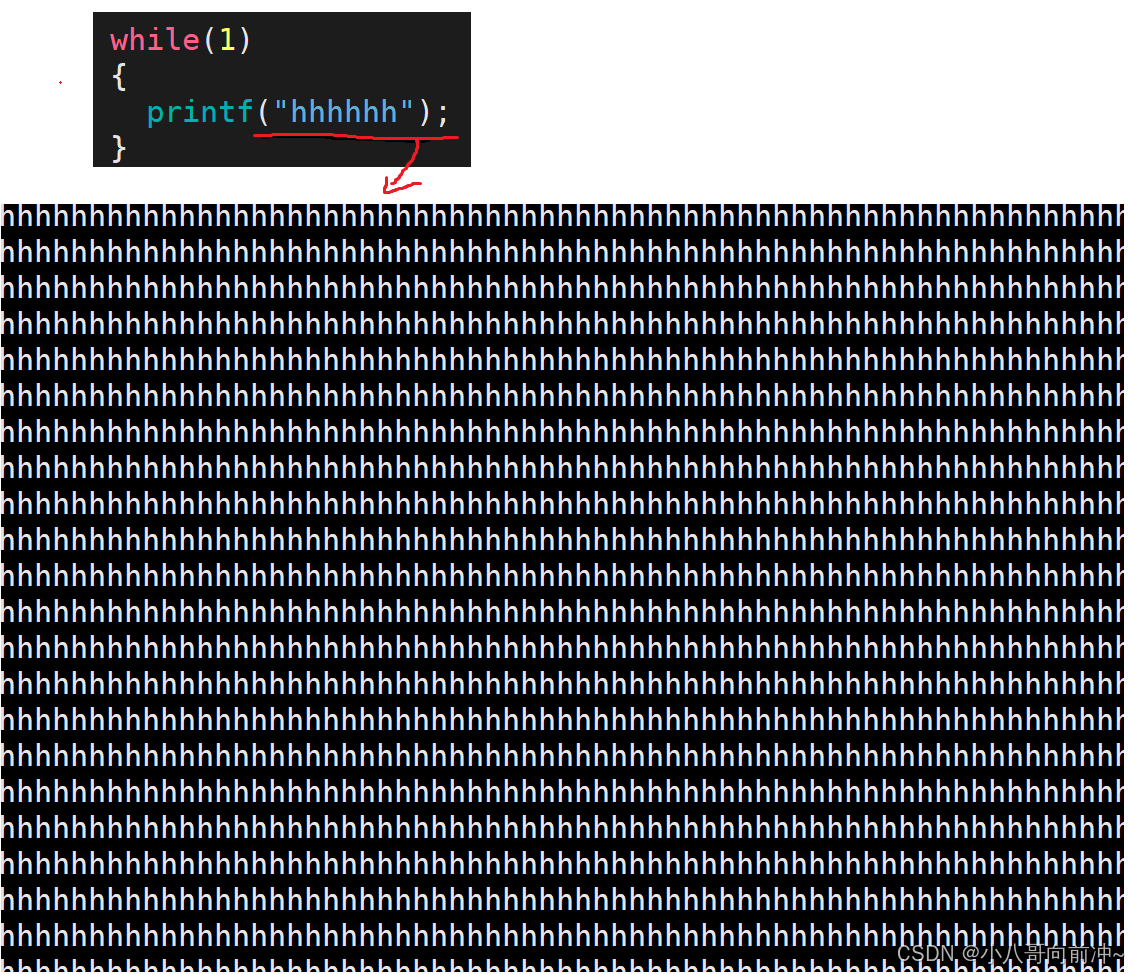
看代码:
理解:
我们看到是立马就能看到,且一直打印。
循环打印到显示器,是行刷新,也就是说要写满缓冲区一行(1024字节)才刷新,但是写的很快,一下就写满了1024,所以可以立马看到(也就是说立马就刷新到了内核缓冲区)。
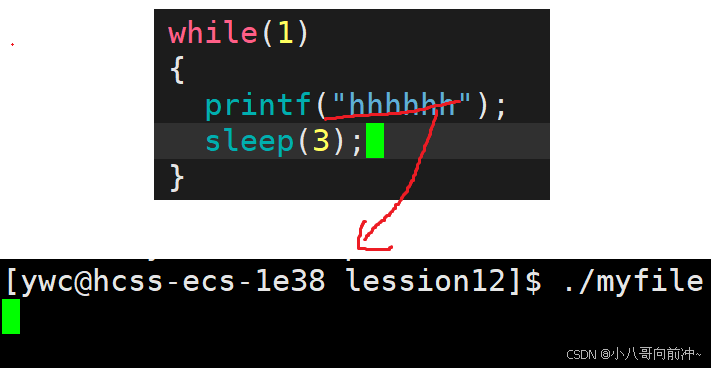
再看代码:
理解:
现象:一直看不到打印内容。
因为打印到显示器是行刷新,只有写满了1024字节(缓冲区的一行)就刷新,每3s写入,而不是立马写入,写的很慢,所以一直看不到打印内容。
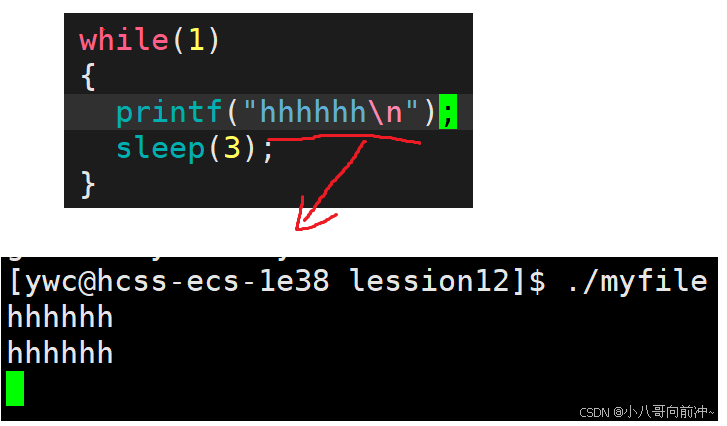
再看代码:
理解:
现象:每三秒看见打印内容。
因为打印到显示器是行刷新,本来要写满1024字节(一行)才刷新,但是加上了\n可以立马刷新,也就是说执行一次printf就刷新一次,所以可以一下看到内容。
再看:
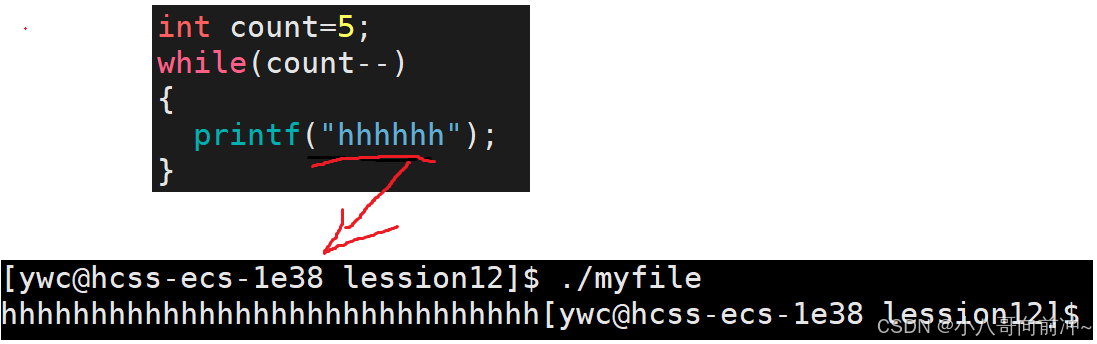
理解:
因为打印到显示器是行刷新,但是只打印5次,肯定不满1024字节(一行),但是为什么又能在显示器上看到?因为进程退出,会自动刷新!
综合理解
1.每个文件都有一个自己的内核级缓冲区!
2.一个进程对文件去进行读写操作,毫无疑问,在内存中,有进程pcb,文件描述符表,还有一个个文件结构体(struct file),也有每个文件对应的内核级缓冲区,当进程对文件做任何操作,都必须将文件加载到对应的内核级文件缓冲区(磁盘内容到内存的拷贝),然后对文件的操作,只需要调用对应file结构体中的函数指针即可!操作完毕,就会将内核级中的文件缓冲区写回磁盘文件(这涉及文件系统知识,讲文件系统部分详说)。
3.计算机数据流动的本质就是拷贝。
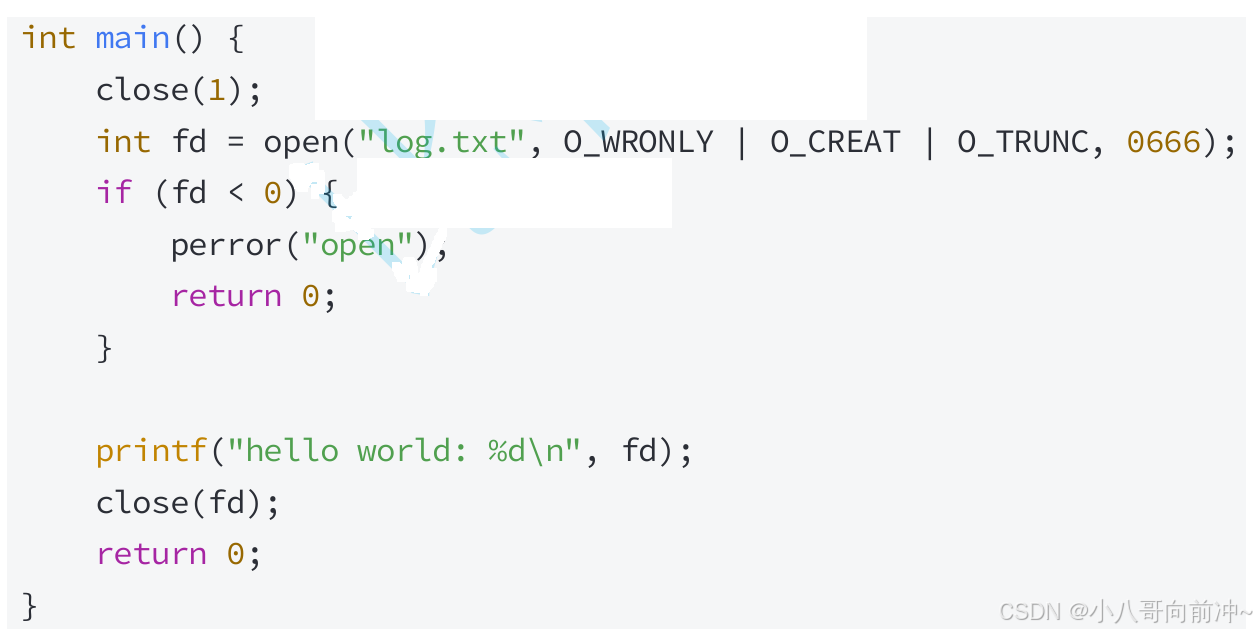
看代码:
 理解:
理解:
我们本来想使⽤重定向思维,让本应该打印在显⽰器上的内容写到"log.txt"⽂件中,但我们发现, 程序运⾏结束后,⽂件中并没有被写⼊内容:
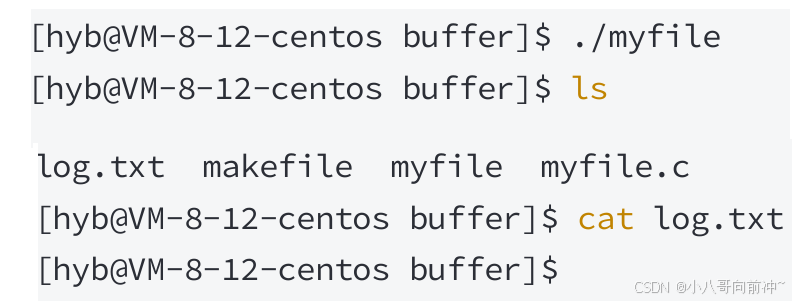
这是由于我们将1号描述符重定向到磁盘⽂件后,缓冲区的刷新⽅式成为了全缓冲。⽽我们写⼊的内容 并没有填满整个缓冲区,导致并不会将缓冲区的内容刷新到磁盘⽂件中。怎么办呢?可以使⽤fflush强 制刷新下缓冲区。

还有⼀种解决⽅法,刚好可以验证⼀下stderr是不带缓冲区的,代码如下:

这种⽅式便可以将2号⽂件描述符重定向⾄⽂件,由于stderr没有缓冲区,"helloworld"不⽤fflash 就可以写⼊⽂件:

看代码:
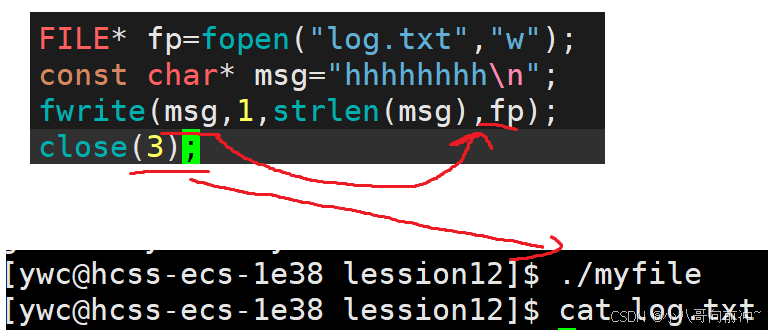
理解:
将msg内容写入log.txt,但是并没有写入,因为fwrite将内容写入到了C语言级的缓冲区,而且是全缓冲,只写入一行肯定不会刷新(缓冲区要满才会刷新),按理来说,进程结束会刷新,但是结果却是没有写入到磁盘文件,因为在进程结束之前,调用了系统调用,将内核级的缓冲区关闭了,所以就算进程结束刷新了,也不会刷新到内核级缓冲区!所以没有写入到磁盘文件。
再看代码:
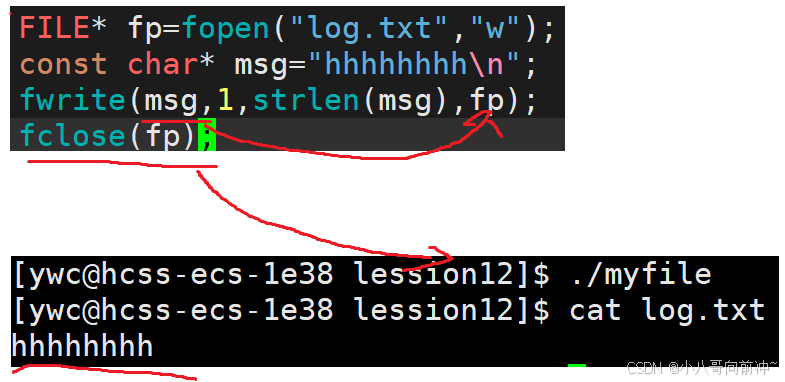
理解:
fclose并没有关闭对应文件的内核缓冲区,所以进程结束写入了磁盘文件。
所以当使用C语言库函数对文件进行读写操作时,尽量别写系统调用close。
而使用系统调用去对文件进行读写操作时,使用fclose没有影响(系统调用是直接对内核文件缓冲区进行操作的)。
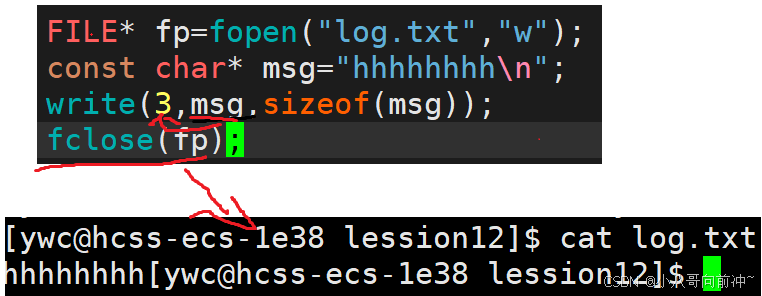
使用fclose依然写入了。
再看代码:
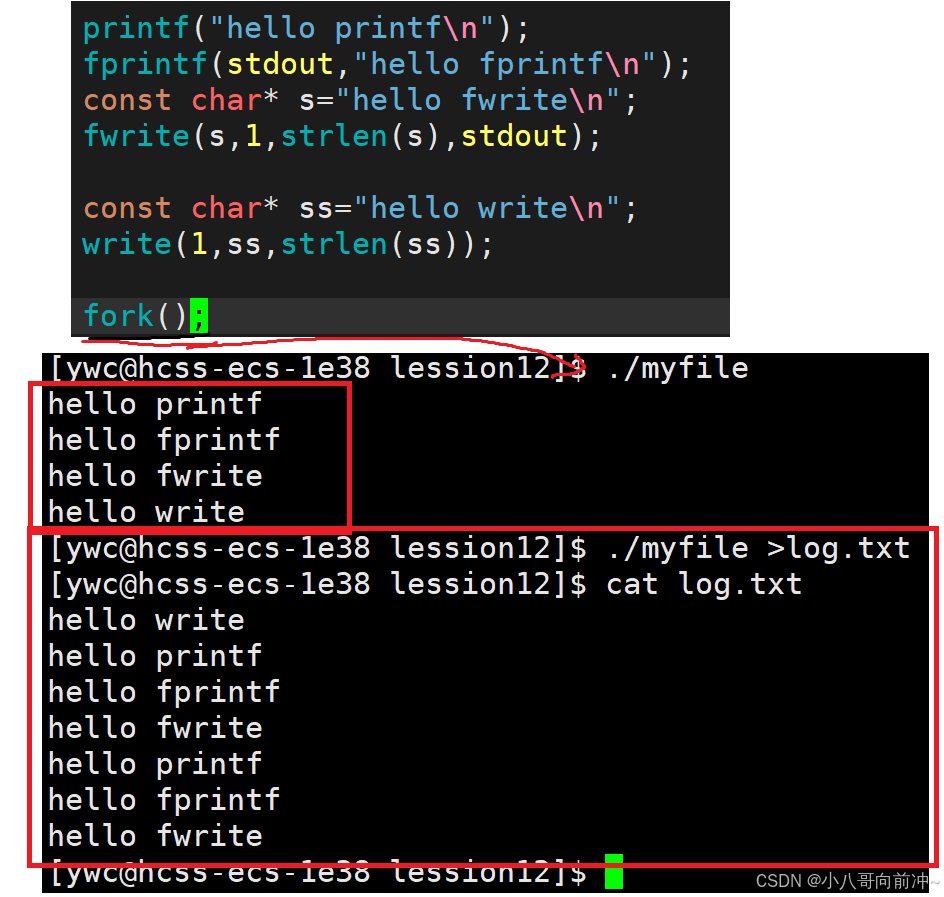
理解:
为什么文件中的内容和直接运行的内容不一样?
直接运行,是往显示器写入,是行刷新,但是有\n,可直接刷新,而系统调用不需要经过缓冲所以从上至下依次打印。
重定向操作,是往磁盘文件写入,是全刷新,要等到缓冲区刷新完才能真正写到文件中(所以此执行到C语言库函数根本不会往文件中写入),而系统调用不需要经过缓冲(所以先看到系统调用的打印信息),然后创建子进程,子进程也会有一个log.txt文件的缓冲区(拷贝的父进程的,所以此时父子进程缓冲区的内容一摸一样),最终父子进程都退出,进程退出,缓冲区刷新(父子进程都刷新,也就是说刷新两次)。所以看到文件中的内容系统调用写入的内容只有一次,而C语言库函数写入的内容有两次。
好了我们下期见!