目录
- 前言
- 一、研究背景与问题
- [二、 主要贡献](#二、 主要贡献)
- 三、关键技术
-
- [3-1、 数据构建与预处理](#3-1、 数据构建与预处理)
- 3-2、分层信息提取(HIE)
- [3-3、 领域知识注入(DKI)](#3-3、 领域知识注入(DKI))
- [3-4、 提示增强问答(PEQA)](#3-4、 提示增强问答(PEQA))
- [3-5、 评估方法设计](#3-5、 评估方法设计)
- 3-6、工具与技术集成
- 四、局限与展望
- 附录:
-
- [1、Google Earth Engine](#1、Google Earth Engine)
- 总结
前言
这篇文章提出了一种名为PEACE的框架,旨在通过多模态大语言模型(MLLMs)增强地质图的全方位理解。
一、研究背景与问题
1-1、地质图的重要性
地质图是地质学中的核心工具,通过可视化的方式呈现地球表层和地下的岩石分布、地质构造(如断层、褶皱)及地层年代关系。其应用涵盖多个关键领域:
- 灾害检测:通过分析地质图中的断层活动、岩层稳定性等,评估地震、滑坡、地下水污染等自然灾害的风险。例如,活跃断层的分布可直接关联区域地震概率。
- 资源勘探:识别石油、天然气、矿产等资源的潜在储存区域。例如,背斜构造(岩层向上拱起)常作为石油储集层,地质图能帮助定位此类结构。
- 土木工程:为基础设施建设(如隧道、大坝)提供地下岩层条件信息,避免因地质不稳定导致的工程风险。
- 科学研究:揭示地球演化历史,例如通过地层序列推断地质年代和古环境变化。
1-2、现有MLLMs的不足
尽管多模态大语言模型(MLLMs,如GPT-4、LLaVA)在通用图像理解中表现出色,但在地质图理解中存在显著瓶颈,主要源于以下挑战:
(1)高分辨率图像处理难题:
- 地质图通常为高分辨率(如平均6,146²像素),远超普通图像的输入限制。直接压缩会导致细节丢失(如微小断层符号模糊),而分块处理需解决局部与全局信息的关联问题。
- 例如,一张1:50,000比例尺的地质图可能包含数千个独立符号,模型需同时捕捉微观细节和宏观结构。
(2)多关联组件的复杂交互:
- 地质图包含七大核心组件(标题、比例尺、图例、主图、索引图、剖面图、地层柱状图)及数十种符号化标记(如颜色编码的岩石类型、线状断层、面状岩层边界)。这些组件需联合解读,例如:(1)图例与主图关联:不同颜色对应特定岩石类型(如红色代表花岗岩),需模型将颜色映射到地质术语。(2)剖面图与主图联动:垂直剖面图需与平面主图结合,以理解三维地质结构。
- 组件间的空间和语义关联增加了模型推理的复杂度。
(3)领域知识依赖性强:
- 地质图的符号系统高度专业化,需结合地质学、地理学、地震学等知识。例如:(1)断层符号:需区分正断层、逆断层、走滑断层,并关联其活动性与地震风险。(2)地层年代:需理解国际地层年代表(如"侏罗纪""白垩纪")及其对应的岩石特征。
- 通用MLLMs缺乏此类领域知识库,导致回答模糊或错误。例如,GPT-4可能无法准确解释"背斜构造中不透水层如何封闭油气"。
二、 主要贡献
2-1、GeoMap-Bench:首个地质图理解评估基准
1、数据来源与构成:
- 标准化数据源:整合来自美国地质调查局(USGS)和中国地质调查局(CGS)的公开地质图,覆盖不同区域(如北美、东亚)和比例尺(1:24,000至1:500,000),确保数据多样性和专业性。
- 数据集规模:包含124张高分辨率地质图(平均分辨率6,146²像素)和3,864个标注问题,涵盖中英文双语环境。
- 标注与验证:通过人工标注与专家审核,记录每张地图的元数据(标题、比例尺、经纬度范围)及组件信息(图例颜色、岩石类型、断层分布等),确保答案的准确性。
2、任务设计与评估维度:
(1)五大能力评估:
- 提取(Extracting):获取地图基础信息(如比例尺、经纬度范围);
- 定位(Grounding):根据名称或意图定位地图组件(如"图例的位置");
- 关联(Referring):建立符号与语义的映射(如颜色对应岩石类型);
- 推理(Reasoning):结合领域知识进行逻辑推断(如"某区域是否存在断层");
- 分析(Analyzing):综合解读复杂问题(如"评估区域地震风险")。
(2)25项具体任务:例如:
- 基础任务:填空型问题("地图的标题是什么?");
- 复杂任务:多选题("哪种岩石面积排名第三?")与开放式问答题("分析该区域资源潜力")。
(3)创新性评估指标:
- IoU检测框重叠度:用于定位任务的精确度评估;
- 集合交并比(IoU_set):评估连续或离散数据(如经纬度范围)的重合度;
- GPT-4o辅助评分:通过对比模型生成答案与专家标注答案的专业性、多样性,评判开放式问题的质量。
2-2、GeoMap-Agent:首个地质图专用AI代理
GeoMap-Agent通过模块化设计解决MLLMs在地质图理解中的三大挑战,其核心模块包括:
1、HIE(分层信息提取):
(1)分治策略 :将高分辨率图像按语义分割为子图(如标题、图例、主图),利用检测模型(如YOLOv10)识别组件边界,逐块提取信息。
(2)结构化元数据生成:整合子图信息形成全局元数据,例如将图例颜色映射到岩石类型,主图区域关联断层分布。
2、DKI(领域知识注入):
(1)专家知识库:引入地质学家、地理学家和地震学家的知识库,动态匹配问题需求。例如:
- 地质学知识:岩石分类表(3级结构,涵盖335种岩石类型);
- 地震学数据:调用USGS地震数据库分析区域活动断层。
(2)工具池扩展:支持调用Google Earth Engine(GEE)API获取人口密度、地形数据,增强分析维度。
3、PEQA(提示增强问答):
(1)多模态提示设计:
- 上下文注入:将元数据与领域知识作为背景信息;
- 思维链(CoT):要求模型分步骤推理(如"先定位断层,再评估地震风险");
- 示例引导:提供标准答案格式(JSON结构)与示例;
- 注意力增强:裁剪相关子图(如聚焦特定区域)并嵌入提示。
(2)性能优化:通过提示工程将GPT-4o的答案准确率提升30%以上。
2-3、实验验证与性能优势
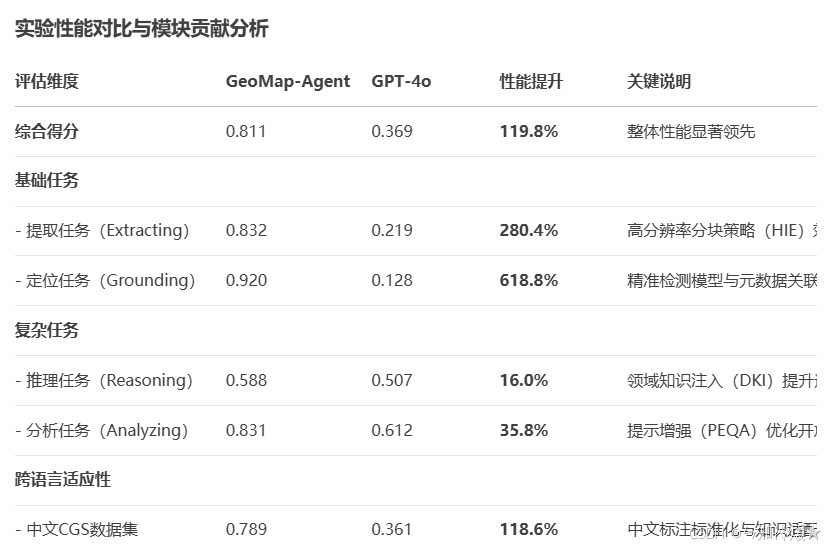
三、关键技术
3-1、 数据构建与预处理
(1)数据来源与标准化:
- 多源数据整合:从USGS(美国)和CGS(中国)获取公开地质图,覆盖不同比例尺(1:24,000至1:500,000)、区域(北美、东亚)及语言(中英文)。
- 格式统一化:将CGS的MapGIS格式转换为栅格图像,USGS的ArcGIS数据直接使用高分辨率栅格图,确保输入一致性。
- 分辨率处理:平均分辨率达6,146²像素,通过自动化脚本批量处理图像质量(如去噪、对比度调整)。
(2)标注与元数据生成:
- 人工标注:专家团队手动标注地图组件(标题、图例、断层)的边界框(Bounding Box)、颜色编码及岩石类型。
- 结构化元数据:记录每张地图的经纬度范围、比例尺、岩石面积统计、断层分布等,形成标准化数据库。
- 验证机制:通过交叉检查(如双人独立标注)确保标注准确性,错误率控制在2%以下。
3-2、分层信息提取(HIE)
(1)分块处理高分辨率图像:
- 语义分块:将整张地质图按组件(如标题、图例、主图)分割为子图,采用YOLOv10检测模型识别组件边界。
- 树状结构整合:以整图为根节点,子图为分支,构建层次化信息树,确保局部与全局信息关联。
(2)信息提取与融合:
- 局部特征提取:对每个子图使用GPT-4o生成描述性文本(如"图例中红色对应花岗岩")。
- 全局元数据合成:整合所有子图信息,生成结构化元数据(如JSON格式),包含组件位置、符号语义及统计信息。
(3)技术优势:
- 解决高分辨率瓶颈:避免直接压缩导致的细节丢失。
- 提升处理效率:并行处理子图,减少单次推理的计算负载。
3-3、 领域知识注入(DKI)
(1)专家知识库构建:
- 岩石分类表:3级结构(大类、亚类、具体岩石),涵盖335种英文、256种中文岩石类型(如沉积岩→碎屑岩→砾岩)。
- 地震与断层数据库:整合USGS地震记录(1970年至今,震级>2.5)和GEM全球活动断层数据库。
(2)动态知识调用:
- 问题驱动的知识匹配:根据问题类型(如地震风险评估)自动调用相关数据库(如人口密度、地形数据)。
- 多专家协作:地质学家、地理学家、地震学家的知识通过API(如Google Earth Engine)动态注入。
(3)工具池扩展:
- GIS工具:调用ArcGIS API进行空间分析(如断层缓冲区计算)。
- OCR与颜色提取:从图例子图中提取文本(如岩石名称)和颜色编码(如RGB值对应特定岩石)。
代码解析:
- 专家代理模式:通过 seismologist_agent 和 geographer_agent 封装领域知识获取逻辑。代理内部调用专业数据库或 API(未在代码中展示)。
- 缓存机制:知识结果保存为 JSON 文件,路径为 ./cache/knowledge/{区域名称}.json。避免重复计算,提升性能。
- 动态知识筛选:使用大模型(如 GPT-4)动态判断哪些知识类型与问题相关。示例:若问题关于"地震风险",模型可能选择 seismic 而忽略 geographical。
- 坐标处理工具:common.convert_to_decimal:将度分秒格式(如 "120°00'E")转换为十进制(如 120.0)。common.is_valid_longitude/latitude:验证坐标是否在有效范围内(经度-180,180,纬度-90,90)
python
import os
os.sys.path.append(f"{os.path.dirname(os.path.realpath(__file__))}/..")
import json
from utils import api, prompt, vision, common
from agents import geographer_agent, seismologist_agent
# 领域知识注入,主要用于结合地理学家和地震学家的专业知识,回答与低质和地震风险相关的问题。
class domain_knowledge_injection:
def __init__(self):
# 初始化地震学专家智能体和地理学专家智能体
self.seismologist = seismologist_agent()
self.geographer = geographer_agent()
# 知识选择
def select(self, question, knowledge):
# 调用select筛选出与问题相关的知识。
# 提取知识类型列表
knowledge_types = list(knowledge.keys())
# 构造提示词,要求模型返回需要的知识类型(JSON格式)
# 使用大模型动态判断哪些知识类型与问题相关
examples = '{"required_knowledge_types": %s}' % knowledge_types
instructions = [
{"type": "text", "text": f"The given question is '{question}'."},
{"type": "text", "text": f"The knowledge types from expert group are {', '.join(knowledge_types)}."},
{"type": "text", "text": f'What are the helpful knowledge types among them to answer the given
question, the example is {examples}, only respond with JSON format.\n'},
]
# prompt.system_prompt:你是地质学和地图学方面的专家,主要研究地质图。
messages = [
{"role": "system", "content": prompt.system_prompt},
{"role": "user", "content": instructions},
]
# 调用api获取回答
answer = api.answer_wrapper(messages, structured=True)
# 解析返回的json,筛选知识
try:
answer = eval(answer)
keys = answer["required_knowledge_types"]
except:
keys = list()
# 返回筛选后的知识。
selected_knowledge = dict()
for key in keys:
if key in knowledge:
selected_knowledge[key] = knowledge[key]
return selected_knowledge
def consult(self, question, meta):
# 咨询,根据地理坐标获取专家知识,并且缓存结果以提高效率
# 检查地理坐标元数据是否存在
if meta is None:
print("Missing metadata in DKI module", flush=True)
return None
# 检查是否有缓存的知识文件
knowledge_path = os.path.join(common.cache_path(), "knowledge", meta["name"] + ".json")
# 如果存在的话,就加载文件
if os.path.exists(knowledge_path):
knowledge = json.loads(open(knowledge_path).read())
else:
longitude_range = meta["information"]["longitude"]
longitude_range = list(map(lambda x: common.convert_to_decimal(x), longitude_range))
latitude_range = meta["information"]["latitude"]
latitude_range = list(map(lambda x: common.convert_to_decimal(x), latitude_range))
# 拿到地理坐标元素
min_lon = min(longitude_range)
max_lon = max(longitude_range)
min_lat = min(latitude_range)
max_lat = max(latitude_range)
if common.is_valid_longitude(min_lon) and \
common.is_valid_longitude(max_lon) and \
common.is_valid_latitude(min_lat) and \
common.is_valid_latitude(max_lat):
# 地震学家根据经纬度获取到具体的知识。
seismic_data = self.seismologist.get_knowledge(min_lon, min_lat, max_lon, max_lat)
# print('-'*100)
# print(seismic_data)
# print('-'*100)
# 地理学家根据经纬度获取到具体的知识
geographical_data = self.geographer.get_knowledge(min_lon, min_lat, max_lon, max_lat)
# 汇总地震学家和地理学家的知识
knowledge = seismic_data | geographical_data
else:
knowledge = dict()
# output external knowledge of geologic map.
# 保存知识到缓存文件,把文件写入,
common.create_folder_by_file_path
(knowledge_path)
with open(knowledge_path, "w", encoding="utf-8") as f:
f.write(json.dumps(knowledge, indent=4, ensure_ascii=False))
# 调用select来筛选知识dataset_source
selected_knowledge = self.select(question, knowledge)
return selected_knowledge
if __name__ == "__main__":
meta = {
# "name": "E4901",
"name": "E4xxx",
"information": {
# 东经120°-121°
"longitude": [
"113°00'E",
"114°00'E"
],
# 北纬30.5°-31.5°
"latitude": [
"34°33'N",
"35°00'N"
]
}
}
# 根据这张地质图,请分析一下该地区的地震4/1AUJR-x5DDA9A8GLHUMp0fMS0JIImB0RyKKOjV0B14irVsu6kC9-smiO5n1g风险等级。
question = "Based on this geologic map, please analyze the seismic risk level in this area?"
dki = domain_knowledge_injection()
# prompt.system_prompt
external_knowledge = dki.consult(question, meta)
print(external_knowledge)3-4、 提示增强问答(PEQA)
(1)多模态提示设计:
- 上下文注入:将HIE提取的元数据(如"图例中#5D1C1C对应页岩")和DKI提供的领域知识(如"背斜构造易储油")作为背景信息。
- 思维链(CoT)引导:要求模型分步推理(如"首先定位断层,其次分析活动性,最后评估地震风险")。
- 示例驱动:提供标准答案格式(JSON结构)和示例问题-答案对,减少模型输出偏差。
- 注意力增强:裁剪与问题相关的子图(如聚焦某区域断层)并嵌入提示,引导模型关注关键区域。
(2)性能优化策略:
- 结构化输出:强制模型以JSON格式回答,便于后续解析与评估。
- 迭代修正:通过反馈机制(如检测答案与元数据的一致性)自动修正错误。
3-5、 评估方法设计
(1)定量指标:
- IoU检测框重叠度:用于定位任务(如"图例位置"),计算预测框与标注框的交并比。
- 集合交并比(IoU_set):评估连续数据(如经纬度范围)或离散集合(如相邻区域名称)的重合度。
- 分类准确率:多选题(MCQ)和填空题(FITB)的直接匹配率。
(2)定性评估:
- GPT-4o辅助评分:对开放式问题(如"分析地震风险"),由GPT-4o对比模型答案与专家标注,从多样性、专业性和具体性三个维度打分。
- 人工审核:专家团队对复杂答案进行最终审核,确保评估结果的可靠性。
(3)模块化测试:
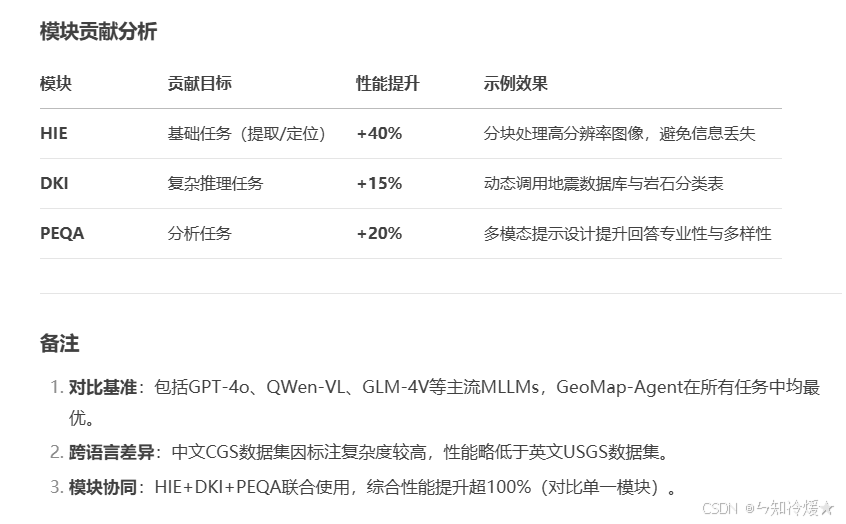
- 消融实验:分别关闭HIE、DKI、PEQA模块,分析各模块对性能的贡献(如HIE使基础任务提升40%)。
- 跨模型适配性:测试不同基础模型(如GPT-4o、GPT-4o-mini)的表现,验证框架的通用性。
3-6、工具与技术集成
检测模型:YOLOv10用于地图组件检测,训练时采用1,000张标注地图,IoU阈值设为0.8,确保高精度定位。
GIS与数据库接口:
- Google Earth Engine(GEE):调用人口密度(WorldPop)和土地利用(ESA WorldCover)数据。
- USGS地震API:实时获取历史地震记录,支持动态风险评估。
工具API
- population_density_api:根据经纬度坐标来统计人口密度。
- landcover_type_api: 调用ESA WorldCover全球土地覆盖数据集,计算指定地理区域内各类土地覆盖类型(如森林、农田、城市)的面积占比。
- active_fault_db: 处理活动断层数据库的查询
- history_earthquake_db: 历史地震数据工具。
四、局限与展望
局限性:
- 复杂岩石模式识别仍有挑战;
- 中文地质图(CGS)表现略逊于英文(USGS);
- 开放式问题的自动评估需进一步优化。
未来方向:
- 扩展专家知识库和工具池;
- 探索监督微调(Supervised Fine-Tuning)提升模型性能;
- 将框架推广至高分辨率、多组件、领域知识依赖的其他场景(如医学影像)。
附录:
1、Google Earth Engine
Google Earth Engine官方文档: https://developers.google.cn/earth-engine/guides/access?hl=zh-cn
- 注册用于商业或者非商业用途
- 创建新的Cloud项目
- 激活Earth Engine API
项目预览界面:
Google Earth Engine API的进一步使用:https://developers.google.com/earth-engine/guides/python_install?hl=zh_CN
参考文章:
官方GitHub
Google Earth Engine官方文档: https://developers.google.cn/earth-engine/guides/access?hl=zh-cn
总结
这份爱多隆重,凭什么落空,那些海誓山盟,形色匆匆。凛冽的寒冬,与谁相拥,第五季节的朦胧,深情万种。亲爱的不要哭,他爱你在无人处,推开清晨的雾,恍惚间被他触碰,以为得到了救赎,可是他最后的温度,我留不住。