理解线性回归及梯度下降优化
引言
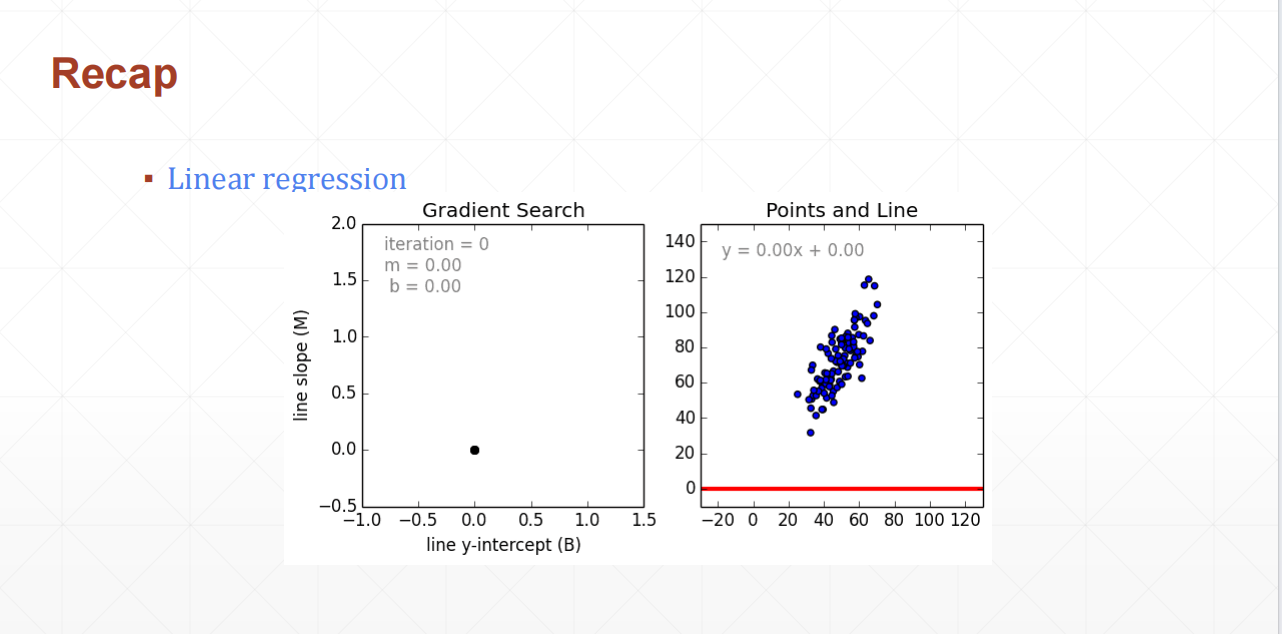
在机器学习的基础课程中,我们经常遇到的一个重要概念就是线性回归。今天,我们将深入探讨这一主题,并通过具体的例子来了解如何利用梯度下降方法对模型进行优化。
线性回归简介
线性回归是一种统计方法,用于确定两个变量之间的关系。简单来说,如果我们有一个自变量 XX 和因变量 YY,线性回归可以帮助我们找到一条最佳拟合直线,这条直线可以用公式 Y=WX+bY=WX+b 来表示,其中 WW 是权重,bb 是偏置。
损失函数
为了评估模型的好坏,我们需要定义一个损失函数。对于线性回归而言,通常使用平方误差作为损失函数,即 loss=(WX+b−y)2loss=(WX+b−y)2。

梯度下降优化
梯度下降是一种迭代优化算法,用来最小化损失函数。每次迭代过程中,我们会更新参数 WW 的值,具体更新规则为 w′=w−lr×∇loss/∇ww′=w−lr×∇loss/∇w,这里的 lrlr 表示学习率,控制着每一步调整的幅度。

迭代优化
通过不断调整 WW 和 bb 的值,使得损失函数逐渐减小,直到达到局部或全局最小值点。这个过程需要多次迭代计算,直至满足预设的停止条件为止。
下一课时预告
接下来的一课时,我们将一起探索著名的MNIST手写数字识别任务,敬请期待!
结语
感谢大家的关注与支持,希望今天的分享能够加深您对线性回归以及梯度下降算法的理解。让我们共同期待下一节课的到来吧!
实战代码
python
import numpy as np
# y = wx + b
def compute_error_for_line_given_points(b, w, points):
totalError = 0
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
totalError += (y - (w * x + b)) ** 2
return totalError / float(len(points))
def step_gradient(b_current, w_current, points, learningRate):
b_gradient = 0
w_gradient = 0
N = float(len(points))
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
b_gradient += -(2/N) * (y - ((w_current * x) + b_current))
w_gradient += -(2/N) * x * (y - ((w_current * x) + b_current))
new_b = b_current - (learningRate * b_gradient)
new_m = w_current - (learningRate * w_gradient)
return [new_b, new_m]
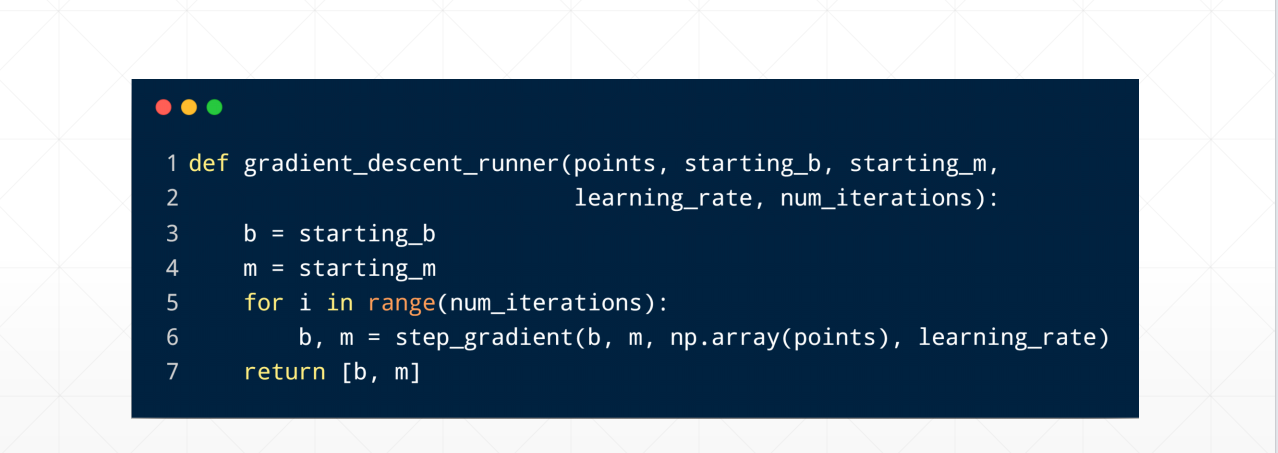
def gradient_descent_runner(points, starting_b, starting_m, learning_rate, num_iterations):
b = starting_b
m = starting_m
for i in range(num_iterations):
b, m = step_gradient(b, m, np.array(points), learning_rate)
return [b, m]
def run():
points = np.genfromtxt("data.csv", delimiter=",")
learning_rate = 0.0001
initial_b = 0 # initial y-intercept guess
initial_m = 0 # initial slope guess
num_iterations = 1000
print("Starting gradient descent at b = {0}, m = {1}, error = {2}"
.format(initial_b, initial_m,
compute_error_for_line_given_points(initial_b, initial_m, points))
)
print("Running...")
[b, m] = gradient_descent_runner(points, initial_b, initial_m, learning_rate, num_iterations)
print("After {0} iterations b = {1}, m = {2}, error = {3}".
format(num_iterations, b, m,
compute_error_for_line_given_points(b, m, points))
)
if __name__ == '__main__':
run()🧠 一、代码概述
这段代码的主要目的是:
- 使用一个简单的线性模型:
y = mx + b - 给定一个二维数据集
data.csv,其中每行有两个值:x和y - 使用梯度下降算法 迭代地更新
m和b,使得预测的y尽可能接近真实值 - 最终输出经过多次迭代后的最优
m和b值,并计算最终误差
📁 二、文件结构说明
-
导入库
pythonimport numpy as np -
- 引入 NumPy 库,用于高效的数值计算和数组操作。
-
函数定义
compute_error_for_line_given_points(b, w, points)
计算当前直线的平均平方误差(MSE)step_gradient(b_current, w_current, points, learningRate)
执行一次梯度下降步骤,返回更新后的b和mgradient_descent_runner(points, starting_b, starting_m, learning_rate, num_iterations)
迭代运行梯度下降过程run()
主函数,加载数据、调用训练函数、打印结果
-
主程序入口
python
if __name__ == '__main__':
run()📌 三、函数详解
1. compute_error_for_line_given_points(b, w, points)
功能:
计算当前模型参数下的均方误差(Mean Squared Error, MSE)
公式:
MSE=1N∑i=1N(yi−(wxi+b))2MSE=N1i=1∑N(yi−(wxi+b))2
参数:
b: 当前截距(bias / y-intercept)w: 当前斜率(weight / slope)points: 数据点集合,是一个二维数组,每行表示一个(x, y)点
返回值:
- 平均误差值(越小越好)
2. step_gradient(b_current, w_current, points, learningRate)
功能:
执行一次梯度下降步骤 ,根据当前的 b 和 m 更新它们的值。
核心公式(梯度下降更新规则):
b′=b−η⋅∂MSE∂bb′=b−η⋅∂b∂MSE
m′=m−η⋅∂MSE∂mm′=m−η⋅∂m∂MSE
其中:
- ηη 是学习率(learning rate)
- 梯度是通过对损失函数分别对
b和m求导得到的
导数推导:
∂MSE∂b=2N∑i=1N(yi−(mxi+b))⋅(−1)∂b∂MSE=N2i=1∑N(yi−(mxi+b))⋅(−1)
∂MSE∂m=2N∑i=1N(yi−(mxi+b))⋅(−xi)∂m∂MSE=N2i=1∑N(yi−(mxi+b))⋅(−xi)
你在代码中实现了这两个梯度的累加。
返回值:
[new_b, new_m]:更新后的模型参数
3. gradient_descent_runner(...)
功能:
循环执行 step_gradient 多次,完成完整的梯度下降过程。
参数:
points: 数据集starting_b,starting_m: 初始参数learning_rate: 学习率num_iterations: 迭代次数
输出:
- 最终的
b和m
4. run()
功能:
- 加载 CSV 数据文件
- 设置初始参数
- 调用梯度下降函数进行训练
- 打印训练前后误差和参数变化
输出结果展示

这表明经过 1000 次迭代后,模型已经基本收敛。