【初中生也能看得懂的讲解】
想象一下,我们能不能直接用"脑子想"来画画?比如你想到一只猫,电脑就能画出一只猫。这听起来是不是很酷?科学家们一直在努力实现这个"意念画画"的梦想。
以前,科学家们可能会用一种叫做"核磁共振(fMRI)"的大型机器来扫描你的大脑,看看你在想什么,然后尝试画出来。但这种机器又贵又大,不方便。
这篇论文里的科学家们想了一个新办法:他们用一种更小巧、更便宜的设备,叫做"脑电图(EEG)"帽子,来记录你大脑的"电波"(就像你思考时大脑发出的小小声音)。
他们遇到的难题:
- 大脑的"电波"信号很微弱,还夹杂着很多"杂音",就像收音机信号不好一样。
- 电脑里的"画家"(一种叫做"扩散模型"的AI,它很擅长根据文字描述画画,比如你告诉它"一只戴帽子的猫",它就能画出来)听不懂这些"电波"信号,它只习惯听文字命令。
- 每个人的"电波"信号可能都不太一样。
科学家们的解决方案(DreamDiffusion系统):
他们设计了一个叫做"DreamDiffusion"的系统,分三步走:
-
教电脑听懂"脑电波":
- 他们收集了很多人看各种东西时的"脑电波"数据。
- 然后,他们用一种叫"蒙面信号建模"的方法训练一个"脑电波翻译器"(EEG编码器)。这就像做填空题:把一段"脑电波"的一部分遮住,让"翻译器"猜被遮住的是什么。通过大量练习,这个"翻译器"就能更好地理解"脑电波"里的意思了。
-
让"画家"AI听"脑电波翻译":
- 他们找来一个已经很会根据文字画画的"画家"AI(叫做"稳定扩散模型",Stable Diffusion)。
- 然后,他们对这个"画家"AI进行微调,让它不仅能听文字命令,还能听懂前面那个"脑电波翻译器"翻译过来的信号。
-
让"脑电波翻译"、"文字描述"和"图像"更合拍:
- 为了让"脑电波翻译器"翻译出来的信号,更接近"画家"AI习惯听的"文字描述"的风格,他们又请来一个"裁判"AI(叫做CLIP)。
- 这个"裁判"AI特别擅长判断一张图片和一段文字描述是不是匹配的。科学家们就利用这个"裁判",来指导"脑电波翻译器",让它翻译出来的信号和真实图片所对应的"感觉"(以及文字描述的感觉)更像。这样,EEG信号、文字信号和图像信号就能在同一个"频道"上对话了。
最终效果:
通过这三步,DreamDiffusion系统就能在你戴着EEG帽子思考某个物体(比如一只狗、一把椅子)的时候,尝试生成出这个物体的图像了。虽然还不完美,比如有时候可能会把形状或颜色搞错,但这已经是"意念画画"领域一个很大的进步了,因为它更方便、成本更低!
详细分析
I. 核心目标与挑战
- 目标: 开发 DreamDiffusion 系统,直接从便携、低成本的脑电图 (EEG) 信号生成高质量图像,实现"思想转图像"。
- 主要挑战:
- EEG 信号质量差: 噪声大、信噪比低、空间分辨率低、个体差异大。
- 模态鸿沟: EEG 特征空间与图像生成模型 (Stable Diffusion) 习惯的文本/图像语义空间差异巨大。
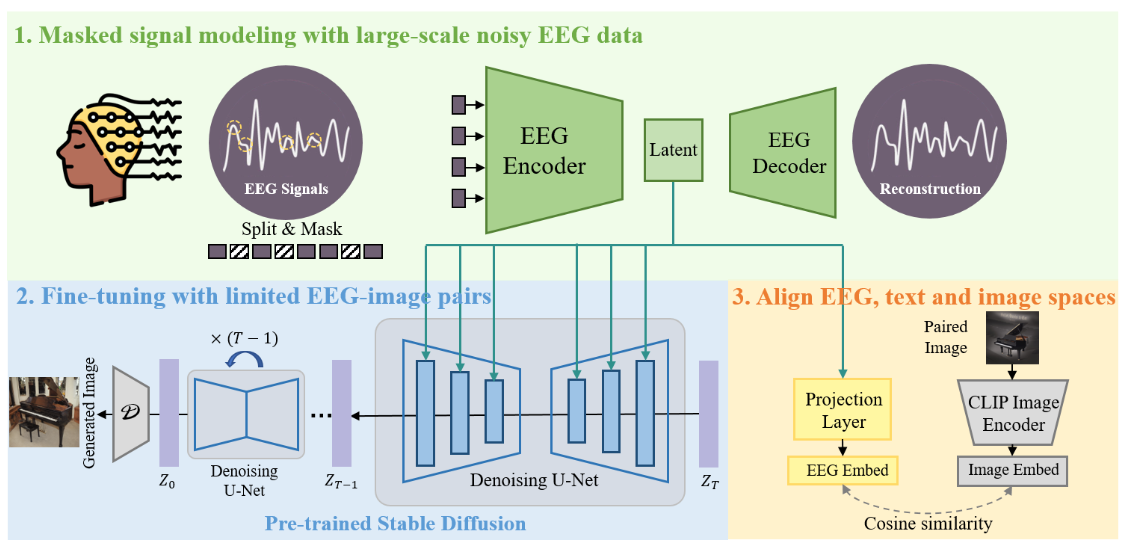
II. DreamDiffusion 核心方法与损失函数
-
EEG 编码器预训练 (MSM):学习鲁棒 EEG 表征
- 方法: 采用时间蒙面信号建模 (Temporal Masked Signal Modeling - MSM) ,在大量无标签 EEG 数据上预训练 EEG 编码器 (类似 ViT-Large)。
- (核心:让模型通过"完形填空"理解 EEG 的时间动态和深层语义。)
- 损失函数 (预训练):
L_EEG_recon- 公式: L EEG_recon = 1 ∣ M ∣ ∑ i ∈ M ( x i − x ^ i ) 2 L_{\text{EEG\recon}} = \frac{1}{|M|} \sum{i \in M} (x_i - \hat{x}_i)^2 LEEG_recon=∣M∣1i∈M∑(xi−x^i)2
- 含义: 计算重建的EEG信号片段与原始被遮蔽的EEG信号片段之间的均方误差 (Mean Squared Error)。这个损失只在被模型预测的被遮蔽部分计算,鼓励模型准确恢复缺失的信息。
- 产出: 一个能有效提取 EEG 语义特征的编码器。
- 方法: 采用时间蒙面信号建模 (Temporal Masked Signal Modeling - MSM) ,在大量无标签 EEG 数据上预训练 EEG 编码器 (类似 ViT-Large)。
-
Stable Diffusion (SD) 微调:EEG 条件下的图像生成
- 方法:
- 将预训练的 EEG 编码器输出的 EEG 嵌入,通过投影层
τ_θ作为条件。 - 注入到预训练的 Stable Diffusion (v1.5) 的 U-Net 的交叉注意力模块。
- 只微调 EEG 编码器和 SD 的交叉注意力头。
- 将预训练的 EEG 编码器输出的 EEG 嵌入,通过投影层
- 损失函数 (微调 - SD部分):
L_SD- 公式 (论文公式2): L SD = E x , ϵ ∼ N ( 0 , I ) , t ∥ ϵ − ϵ θ ( x t , t , τ θ ( y ) ) ∥ 2 2 L_{\text{SD}} = \mathbb{E}_{x, \epsilon \sim \mathcal{N}(0, \mathbf{I}), t} \left \\left\\\| \\epsilon - \\epsilon_\\theta (x_t, t, \\tau_\\theta(y)) \\right\\\|_2\^2 \\right LSD=Ex,ϵ∼N(0,I),t∥ϵ−ϵθ(xt,t,τθ(y))∥22
- 含义: 这是 Stable Diffusion 标准的去噪损失 (epsilon-prediction loss) 。它衡量在图像
x加噪到x_t(时间步t,噪声为ε) 后,模型预测出的噪声ε_θ(在EEG条件τ_θ(y)下) 与真实添加的噪声ε之间的L2距离 (平方欧氏距离)。目标是让模型准确预测出用于去噪的噪声。
- 方法:
-
CLIP 辅助对齐:弥合模态鸿沟,提升语义一致性
- 方法:
- 利用固定的 CLIP 图像编码器
E_I。 - 将 EEG 嵌入 (经
τ_θ和另一投影层h) 与对应真实图像I的 CLIP 图像嵌入E_I(I)进行对比。 - (核心:让 EEG"语言"接近 CLIP 的图文共享"语言",从而更好地驱动 SD。)
- 利用固定的 CLIP 图像编码器
- 损失函数 (微调 - CLIP对齐部分):
L_clip- 公式 (论文公式3): L clip = 1 − E I ( I ) ⋅ h ( τ θ ( y ) ) ∥ E I ( I ) ∥ 2 ∥ h ( τ θ ( y ) ) ∥ 2 L_{\text{clip}} = 1 - \frac{E_I(I) \cdot h(\tau_\theta(y))}{\|E_I(I)\|2 \|h(\tau\theta(y))\|_2} Lclip=1−∥EI(I)∥2∥h(τθ(y))∥2EI(I)⋅h(τθ(y))
- 含义: 目标是最大化 投影后的EEG嵌入
h(τ_θ(y))与对应图像的CLIP图像嵌入E_I(I)之间的余弦相似度 (cosine similarity) 。损失函数写成1 - similarity的形式,最小化这个损失等同于最大化相似度。这鼓励EEG特征在语义上更接近其对应图像的CLIP特征。
- 方法:
- 微调阶段总损失 (推测): 论文未明确给出,但逻辑上应该是
L_SD和L_clip的加权组合,例如L_finetune = L_SD + λ * L_clip,其中λ是一个超参数,用于平衡两个损失项的重要性。
III. 关键实验结果与分析
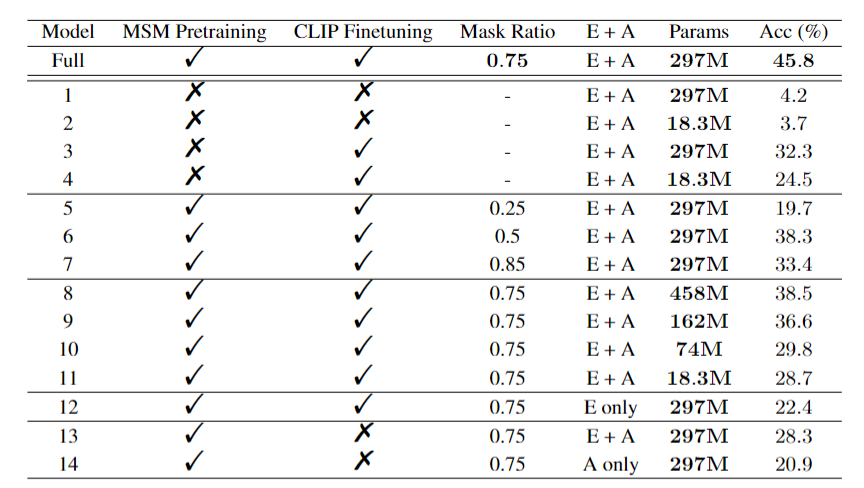
- 评估: 定量 (50路Top-1分类准确率) + 定性 (视觉检查)。主要结果来自 Subject 4。
- 核心发现:
- DreamDiffusion 效果显著: 生成图像质量和语义准确性远超先前 EEG 方法 (如 Brain2Image)。(见图4, 5)
- MSM 预训练至关重要 (
L_EEG_recon的贡献): 移除 MSM,性能大幅下降。(见表1) - CLIP 对齐不可或缺 (
L_clip的贡献): 移除 CLIP 对齐,性能同样大幅下降。(见表1) - 最佳 MSM 掩码率: 0.75。
- 失败案例: 存在类别混淆 (形状/颜色相似),可能与 EEG 信息粒度粗有关。(见图7)
IV. 主要贡献与创新点
- 高质量 EEG 图像生成突破: 成功将强大扩散模型 (SD) 应用于 EEG,显著提升生成质量。
- EEG 的 MSM 预训练: 创新性地将 MSM 用于 EEG 时间序列,学习鲁棒表征。
- CLIP 引导的多模态对齐: 有效解决 EEG 与图文模态的语义鸿沟。
- 推动便携式"思想转图像": 为低成本、易用技术路径奠定基础。
V. 局限性与未来方向
- 局限性: EEG 信号固有瓶颈 (信息粒度、噪声)、主要基于单人数据、对配对数据仍有依赖、伦理未讨论。
- 未来方向: 提升解码精度、跨被试泛化、复杂/动态场景生成、融合多模态数据、交互式生成、特定应用验证、伦理研究。
VI. 总结
DreamDiffusion 通过创新的 EEG 预训练 (由 L_EEG_recon 驱动) 和巧妙的多模态对齐 (由 L_clip 驱动),并结合标准的扩散模型微调 (由 L_SD 驱动),成功实现了从 EEG 信号直接生成高质量图像,是"思想可视化"领域的重要进展,展示了巨大的应用潜力。