指令图像编辑现有方法的局限:
- 微调类方法(InstructPix2Pix、Emu Edit、 Ultra Edit):需要大规模数据和算力、精度高但效率低且泛化性低;
- 免训练方法(Prompt-to-Prompt、 StableFlow):高效但难以理解复杂语义、编辑质量低。
ICEdit 则关注如何在不牺牲编辑精度和泛化能力的前提下,极大提升训练和推理效率,实现高质量、低成本、易扩展的指令图像编辑范式。与以前的方法相比,ICEdit只有 1% 的可训练参数(200 M)和 0.1% 的训练数据(50 k),仅用 9s 推理。

将编辑指令嵌入专为语境化编辑设计的生成提示中,构建如下提示模板:"a side-by-side image of the same {subject}: the left depicts the original {description}, while the right mirrors the left but applies {edit instruction}." 分析 IC 提示下编辑指令对应的注意力图,发现待修改区域呈现更显著的激活值。借鉴大语言模型的上下文能力,构建双联画的输入。

本文设计了两种框架:
- T2I DiT:通过一种隐式的参考图像注入方法,将参考图像的特征融入到双联画的左边图像表示中,从而在右边图像生成时能够保留参考图像的风格和特征。具体而言,对参考图像进行反演,保留各层步骤的注意力值,将反演得到的注意力值注入代表双莲花左侧的 token,来重建参考图像。但这引入了额外的图像翻转步骤,增加了计算开销,且结果不够稳定。
- Impainting DiT:预设一张并排图像,左侧为图像,右侧为 Mask,使用相同的 IC 提示指导修复,让模型在 Mask 区域生成指令编辑结果。计算成本较低,且结果更稳定,但保留参考图像风格能力较弱。
最终采用 Impainting DiT 的方式 I t = E ( I s , T e ) = D ( I I C , M , T I C ) I_t=E(I_s,T_e)=D(I_{IC},M,T_{IC}) It=E(Is,Te)=D(IIC,M,TIC) DiT 采用 FLUX.1 Fill。
经过实验,在某些任务(风格转换和移除)上,使用单一 LoRA 效果不好,认为不同的任务需要不同的潜在特征操作,采取 LoRA-MoE,嵌入到 DiT 模块的注意力投影层中,在其他层使用标准 LoRA 进行调整。
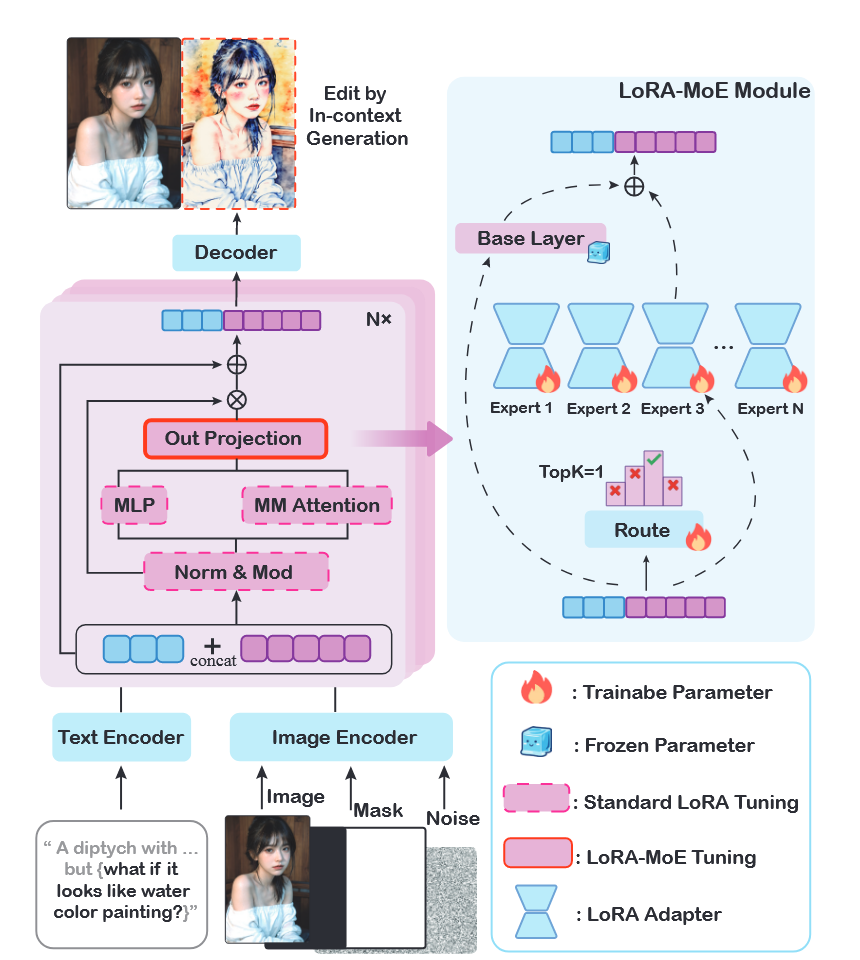
O u t p u t = B a s e L a y e r ( x ) + α ∑ i = 1 N G ( x ) i ⋅ B i ⋅ A i ⋅ x Output=BaseLayer(x)+\alpha \sum_{i=1}^NG(x)_i·B_i·A_i·x Output=BaseLayer(x)+αi=1∑NG(x)i⋅Bi⋅Ai⋅x
其中 B i ∈ R d × r A i ∈ R r × k B_i \in \mathbb{R}^{d×r}\quad A_i\in\mathbb{R}^{r×k} Bi∈Rd×rAi∈Rr×k 为 LoRA 参数, x ∈ R k x \in \mathbb{R}^k x∈Rk 是输入标记。路由分类器为每个专家分配一个选择概率 G ( x ) G(x) G(x),最终输出各个专家的加权和。同时 G ( x ) i = s o f t m a x ( T o p K ( g ( x ) , k ) ) G(x)_i=softmax(TopK(g(x),k)) G(x)i=softmax(TopK(g(x),k))。
由于在实验中发现,少数推理步骤即可对齐指令,并且与 Rectified Flow-based DiT 一致。与需要多步来实现细节和质量的生成任务不同,只需要少数步骤来评估编辑的成功。具体而言,少步去噪+VLM 筛选,提升编辑鲁棒性和主观质量(符合人类偏好)。
- 微调数据仅 5 万条,参数量仅为全量微调的 1%。
- 支持 text-to-image 和 inpainting 两种 DiT 框架,兼容多种编辑场景。
- 推理时可选用如 Qwen-VL-72B 等大模型作为 VLM 评判器。
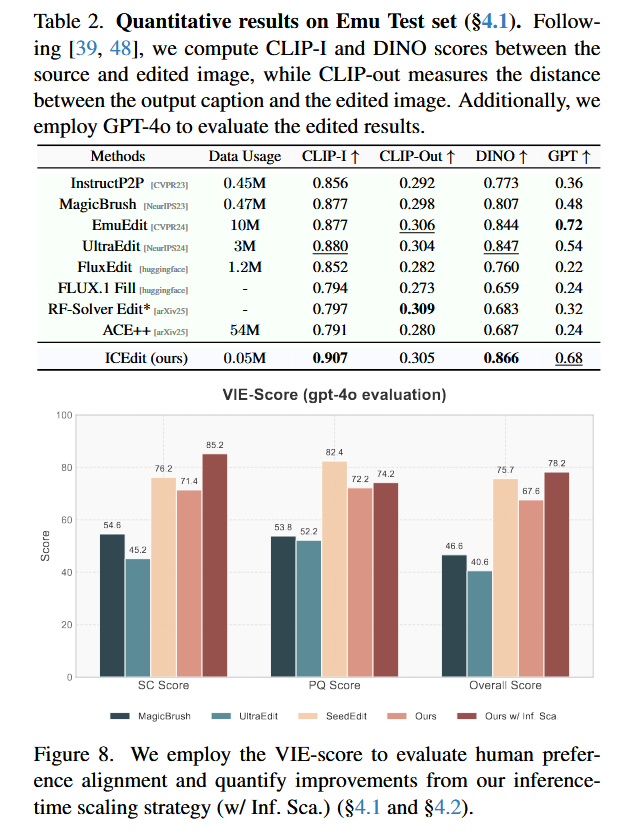
实验结果