摘要
由于数学推理具有复杂且结构化的特性,这对语言模型构成了重大挑战。在本文中,我们介绍了 DeepSeekMath 7B 模型,该模型在 DeepSeek-Coder-Base-v1.5 7B 模型的基础上,使用从 Common Crawl 获取的 1200 亿个与数学相关的标记,以及自然语言和代码数据继续进行预训练。在不依赖外部工具包和投票技术的情况下,DeepSeekMath 7B 在竞赛级 MATH 基准测试中取得了 51.7% 的优异成绩,接近 Gemini-Ultra 和 GPT-4 的性能水平。通过对 DeepSeekMath 7B 生成的 64 个样本进行自洽性验证,其在 MATH 基准测试上的准确率达到了 60.9%。DeepSeekMath 的数学推理能力归因于两个关键因素:首先,我们通过精心设计的数据选择流程,充分利用了公开可用的网络数据的巨大潜力。其次,我们引入了组相对策略优化(Group Relative Policy Optimization,GRPO)算法,这是近端策略优化(Proximal Policy Optimization,PPO)算法的一个变体,它在增强数学推理能力的同时,还能优化 PPO 的内存使用。
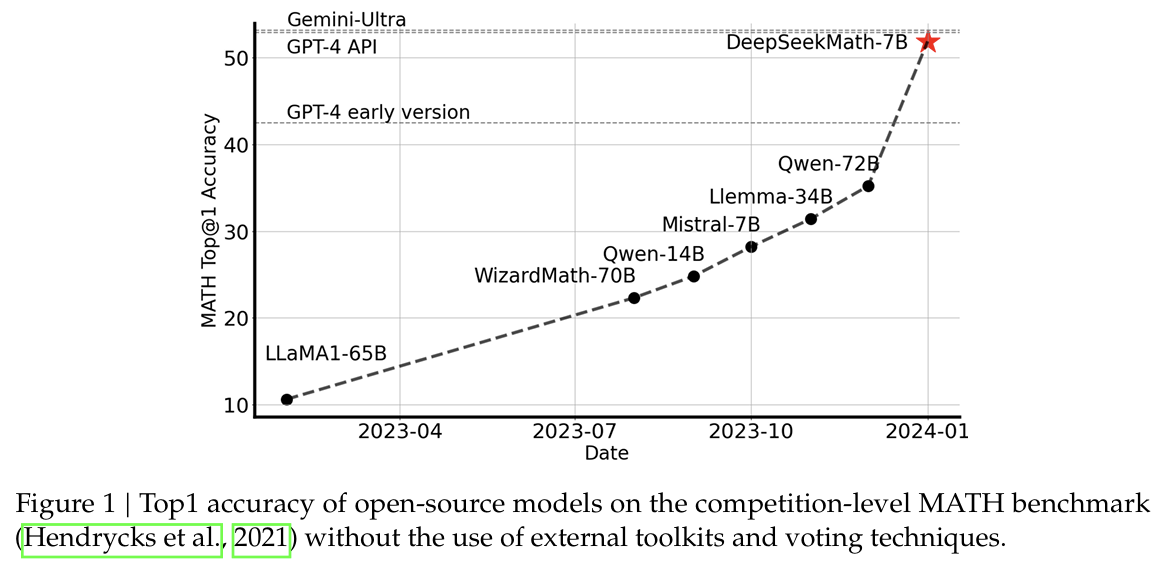
1. 引言
大型语言模型(LLM)彻底改变了人工智能领域中数学推理的方法,在定量推理基准测试(Hendrycks 等人,2021 年)和几何推理基准测试(Trinh 等人,2024 年)方面均取得了重大进展。此外,这些模型在协助人类解决复杂数学问题方面也发挥了重要作用(Tao,2023 年)。然而,像 GPT-4(OpenAI,2023 年)和 Gemini-Ultra(Anil 等人,2023 年)这样的前沿模型并未公开,而且目前可用的开源模型在性能上明显落后。
在本研究中,我们介绍了 DeepSeekMath,这是一种特定领域的语言模型,其数学能力显著优于开源模型,并且在学术基准测试中的性能接近 GPT-4。为了实现这一目标,我们创建了 DeepSeekMath 语料库,这是一个大规模高质量的预训练语料库,包含 1200 亿个数学标记。该数据集是使用基于 fastText 的分类器(Joulin 等人,2016 年)从 Common Crawl(CC)中提取的。在初始迭代中,使用来自 OpenWebMath(Paster 等人,2023 年)的实例作为正例来训练分类器,同时选取多种其他网页作为负例。随后,我们利用该分类器从 CC 中挖掘额外的正例,并通过人工标注进一步优化这些实例。然后,利用这个增强后的数据集更新分类器以提高其性能。评估结果表明,这个大规模语料库质量很高,因为我们的基础模型 DeepSeekMath-Base 7B 在 GSM8K(Cobbe 等人,2021 年)上的准确率达到了 64.2%,在竞赛级 MATH 数据集(Hendrycks 等人,2021 年)上的准确率达到了 36.2%,优于 Minerva 540B(Lewkowycz 等人,2022a 年)。此外,DeepSeekMath 语料库是多语言的,因此我们在中文数学基准测试(Wei 等人,2023 年;Zhong 等人,2023 年)中也观察到了性能提升。我们认为,我们在数学数据处理方面的经验是研究界的一个起点,未来还有很大的改进空间。
DeepSeekMath-Base 是基于 DeepSeek-Coder-Base-v1.5 7B(Guo 等人,2024 年)进行初始化的,因为我们发现,与通用的大型语言模型(LLM)相比,从代码训练模型开始是一个更好的选择。此外,我们观察到数学训练还能提升模型在 MMLU(Hendrycks 等人,2020 年)和 BBH(Suzgun 等人,2022 年)基准测试上的能力,这表明它不仅增强了模型的数学能力,还放大了模型的通用推理能力。
在预训练之后,我们使用思维链(Wei 等人,2022 年)、程序思维(Chen 等人,2022 年;Gao 等人,2023 年)以及工具集成推理(Gou 等人,2023 年)数据对 DeepSeekMath-Base 进行了数学指令微调。得到的模型 DeepSeekMath-Instruct 7B 击败了所有 7B 规模的同类模型,并且可以与 700 亿参数的开源指令微调模型相媲美。
此外,我们引入了组相对策略优化(Group Relative Policy Optimization,GRPO),这是近端策略优化(Proximal Policy Optimization,PPO)(Schulman 等人,2017 年)的一种变体强化学习(RL)算法。GRPO 摒弃了评判模型,而是通过组分数来估计基准线,从而显著减少了训练资源。在强化学习阶段,仅使用英语指令微调数据的一个子集,GRPO 就在强大的 DeepSeekMath-Instruct 模型上取得了显著提升,包括领域内(GSM8K: 82.9 % → 88.2 % 82.9\% \rightarrow 88.2\% 82.9%→88.2%,MATH: 46.8 % → 51.7 % 46.8\% \rightarrow 51.7\% 46.8%→51.7%)和领域外数学任务(例如,CMATH: 84.6 % → 88.8 % 84.6\% \rightarrow 88.8\% 84.6%→88.8%)。我们还提供了一个统一的范式来理解不同的方法,如拒绝采样微调(Rejection Sampling Fine-Tuning,RFT)(Yuan 等人,2023a 年)、直接偏好优化(Direct Preference Optimization,DPO)(Rafailov 等人,2023 年)、PPO 和 GRPO。基于这一统一范式,我们发现所有这些方法在概念上都可以归类为直接或简化的强化学习技术。我们还进行了广泛的实验,例如在线训练与离线训练、结果监督与过程监督、单轮强化学习与迭代强化学习等,以深入探究这一范式的基本要素。最后,我们解释了为什么我们的强化学习能够提升指令微调模型的性能,并进一步基于这一统一范式总结了实现更有效强化学习的潜在方向。
1.1. 贡献
我们的贡献包括可扩展的数学预训练,以及对强化学习的探索与分析。
大规模数学预训练
- 我们的研究提供了令人信服的证据,表明公开可访问的 Common Crawl 数据中包含了用于数学目的的有价值信息。通过实施精心设计的数据选择流程,我们成功构建了 DeepSeekMath 语料库,这是一个从经过数学内容过滤的网页中提取的高质量数据集,包含 1200 亿个标记,其规模几乎是 Minerva(Lewkowycz 等人,2022a 年)所用数学网页的 7 倍,也是最近发布的 OpenWebMath(Paster 等人,2023 年)所用数学网页的 9 倍。
- 我们的预训练基础模型 DeepSeekMath-Base 7B 取得了与 Minerva 540B(Lewkowycz 等人,2022a 年)相当的性能,这表明参数数量并非数学推理能力的唯一关键因素。在高质量数据上预训练的较小模型也能取得出色的性能。
- 我们分享了数学训练实验的发现。在数学训练之前进行代码训练,无论是否使用工具,都能提高模型解决数学问题的能力。这为长期以来一直存在的问题------代码训练是否能提高推理能力------提供了部分答案。我们认为,至少对于数学推理而言,代码训练确实能提高推理能力。
- 尽管在 arXiv 论文上进行训练很常见,尤其是在许多与数学相关的论文中,但在本文采用的所有数学基准测试上,这种训练并未带来显著的性能提升。
强化学习的探索与分析
- 我们引入了组相对策略优化(GRPO),这是一种高效且有效的强化学习算法。与近端策略优化(PPO)相比,GRPO 摒弃了评判模型,而是通过组分数来估计基准线,从而显著减少了训练资源。
- 我们证明,仅使用指令微调数据,GRPO 就能显著提升我们的指令微调模型 DeepSeekMath-Instruct 的性能。此外,在强化学习过程中,我们还观察到了领域外性能的提升。
- 我们提供了一个统一的范式来理解不同的方法,如 RFT、DPO、PPO 和 GRPO。我们还进行了广泛的实验,例如在线训练与离线训练、结果监督与过程监督、单轮强化学习与迭代强化学习等,以深入探究这一范式的基本要素。
- 基于我们的统一范式,我们探讨了强化学习有效性的原因,并总结了实现大型语言模型更有效强化学习的几个潜在方向。
1.2. 评估与指标总结
- 英语和中文数学推理 :我们在英语和中文基准测试上对我们的模型进行了全面评估,涵盖了从小学到大学水平的数学问题。英语基准测试包括 GSM8K(Cobbe 等人,2021 年)、MATH(Hendrycks 等人,2021 年)、SAT(Azerbayev 等人,2023 年)、OCW 课程(Lewkowycz 等人,2022a 年)、MMLU-STEM(Hendrycks 等人,2020 年)。中文基准测试包括 MGSM-zh(Shi 等人,2023 年)、CMATH(Wei 等人,2023 年)、Gaokao-MathCloze(Zhong 等人,2023 年)和 Gaokao-MathQA(Zhong 等人,2023 年)。我们评估了模型在不使用工具的情况下生成自包含文本解决方案的能力,以及使用 Python 解决问题的能力。
在英语基准测试上,DeepSeekMath-Base 与闭源的 Minerva 540B(Lewkowycz 等人,2022a 年)具有竞争力,并且超越了所有开源基础模型(例如,Mistral 7B(Jiang 等人,2023 年)和 Llemma-34B(Azerbayev 等人,2023 年)),无论这些模型是否进行过数学预训练,且通常优势显著。值得注意的是,DeepSeekMath-Base 在中文基准测试上表现更优,这可能是因为我们在收集数学预训练数据时并未遵循以往的工作(Azerbayev 等人,2023 年;Lewkowycz 等人,2022a 年)仅收集英语数据,而是还纳入了高质量的非英语数据。通过数学指令微调和强化学习,得到的 DeepSeekMath-Instruct 和 DeepSeekMath-RL 展现了强大的性能,首次在开源社区中在竞赛级 MATH 数据集上取得了超过 50 % 50\% 50% 的准确率。 - 形式化数学:我们使用(Jiang 等人,2022 年)中的非形式化到形式化定理证明任务,在 miniF2F(Zheng 等人,2021 年)上对 DeepSeekMath-Base 进行了评估,并选择 Isabelle(Wenzel 等人,2008 年)作为证明助手。DeepSeekMath-Base 展现了强大的少样本自动形式化性能。
- 自然语言理解、推理与代码:为了全面评估模型的通用理解、推理和编码能力,我们在大规模多任务语言理解(MMLU)基准测试(Hendrycks 等人,2020 年)上对 DeepSeekMath-Base 进行了评估,该测试包含 57 个涵盖不同学科的多项选择题任务;还在 BIG-Bench Hard(BBH)(Suzgun 等人,2022 年)上进行了评估,该测试包含 23 个主要需要多步推理才能解决的具有挑战性的任务;此外,还在 HumanEval(Chen 等人,2021 年)和 MBPP(Austin 等人,2021 年)上进行了评估,这两个测试广泛用于评估代码语言模型。数学预训练对语言理解和推理性能均有益处。
2. 数学预训练
2.1. 数据收集与去污
在本节中,我们将概述从 Common Crawl 构建 DeepSeekMath 语料库的过程。如图 2 所示,我们展示了一个迭代流程,该流程展示了如何从 Common Crawl 中系统地收集大规模数学语料库,从种子语料库(例如,一个规模较小但高质量的数学相关数据集集合)开始。值得注意的是,这种方法也适用于其他领域,如编码。
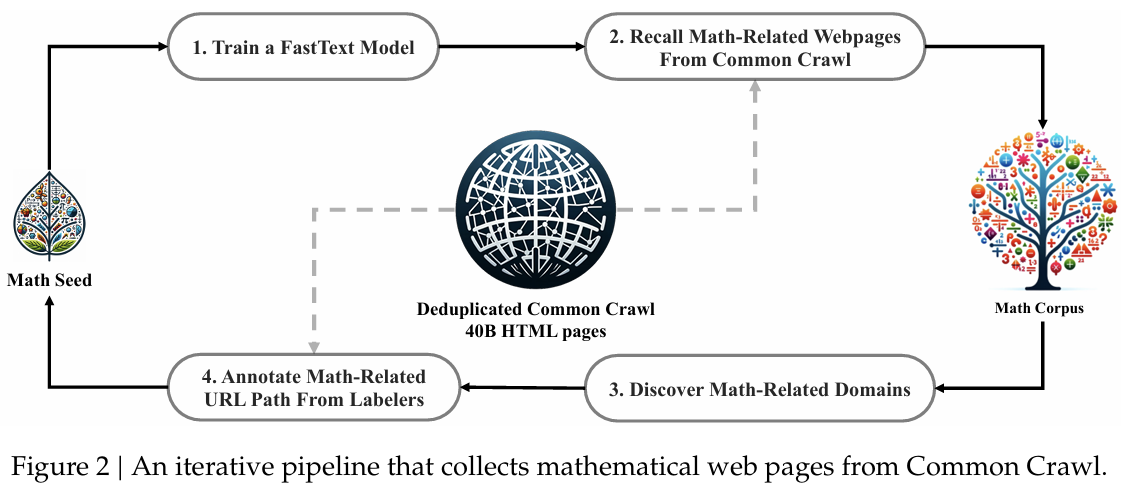
首先,我们选择 OpenWebMath(Paster 等人,2023 年),这是一个高质量的数学网页文本集合,作为我们的初始种子语料库。利用该语料库,我们训练了一个 fastText 模型(Joulin 等人,2016 年),以召回更多类似 OpenWebMath 的数学网页。具体而言,我们从种子语料库中随机选取 500,000 个数据点作为正训练样本,并从 Common Crawl 中选取另外 500,000 个网页作为负样本。我们使用一个开源库 1 ^{1} 1进行训练,将向量维度配置为 256,学习率设置为 0.1,单词 n-gram 的最大长度设置为 3,单词出现次数的最小值设置为 3,训练轮数设置为 3。为了减小原始 Common Crawl 的规模,我们采用了基于 URL 的去重和近似去重技术,最终得到 400 亿个 HTML 网页。然后,我们使用 fastText 模型从去重后的 Common Crawl 中召回数学网页。为了过滤掉低质量的数学内容,我们根据 fastText 模型预测的分数对收集到的网页进行排序,并仅保留排名靠前的网页。通过在排名前 400 亿、800 亿、1200 亿和 1600 亿个标记上进行预训练实验,来评估保留数据的规模。在第一次迭代中,我们选择保留排名前 400 亿个标记。
在第一次数据收集迭代之后,仍有许多数学网页未被收集,这主要是因为 fastText 模型是在一组缺乏足够多样性的正样本上训练的。因此,我们识别了更多的数学网页来源以丰富种子语料库,从而优化 fastText 模型。具体而言,我们首先将整个 Common Crawl 组织成互不重叠的域;一个域被定义为共享相同基础 URL 的网页集合。对于每个域,我们计算在第一次迭代中收集到的网页所占的百分比。将超过 10% 的网页被收集的域归类为数学相关域(例如,mathoverflow.net)。随后,我们手动标注这些已识别域中与数学内容相关的 URL(例如,mathoverflow.net/questions)。与这些 URL 相关联但未被收集的网页将被添加到种子语料库中。这种方法使我们能够收集到更多的正样本,从而训练出一个改进的 fastText 模型,该模型能够在后续迭代中召回更多的数学数据。经过四次数据收集迭代后,我们最终得到了 3550 万个数学网页,总计 1200 亿个标记。在第四次迭代中,我们注意到近 98% 的数据已经在第三次迭代中被收集,因此我们决定停止数据收集。
为了避免基准测试污染,我们遵循 Guo 等人(2024 年)的方法,过滤掉包含来自英语数学基准测试(如 GSM8K(Cobbe 等人,2021 年)和 MATH(Hendrycks 等人,2021 年))以及中文基准测试(如 CMATH(Wei 等人,2023 年)和 AGIEval(Zhong 等人,2023 年))的问题或答案的网页。过滤标准如下:从我们的数学训练语料库中移除任何包含与评估基准测试中任何子串完全匹配的 10-gram 字符串的文本段。对于长度短于 10-gram 但至少有 3-gram 的基准测试文本,我们采用精确匹配来过滤掉受污染的网页。
2.2. 验证 DeepSeekMath 语料库的质量
我们进行了预训练实验,以研究 DeepSeekMath 语料库与最近发布的数学训练语料库相比表现如何:
- MathPile(Wang 等人,2023c 年):一个多源语料库(89 亿个标记),由教科书、维基百科、ProofWiki、CommonCrawl、StackExchange 和 arXiv 聚合而成,其中大部分(超过 85%)来自 arXiv;
- OpenWebMath(Paster 等人,2023 年):经过筛选的包含数学内容的 CommonCrawl 数据,总计 136 亿个标记;
- Proof-Pile-2(Azerbayev 等人,2023 年):一个数学语料库,由 OpenWebMath、AlgebraicStack(103 亿个数学代码标记)和 arXiv 论文(280 亿个标记)组成。在对 Proof-Pile-2 进行实验时,我们遵循 Azerbayev 等人(2023 年)的方法,使用 arXiv:Web:Code 比例为 2:4:1。
2.2.1. 训练设置
我们将数学训练应用于一个具有 13 亿个参数的通用预训练语言模型,该模型与 DeepSeek LLMs(DeepSeek-AI,2024 年)共享相同的框架,记为 DeepSeekLLM 1.3B。我们分别在每个数学语料库上训练一个模型,训练 1500 亿个标记。所有实验均使用高效且轻量级的 HAI-LLM(High-flyer,2023 年)训练框架进行。遵循 DeepSeek LLMs 的训练实践,我们使用 AdamW 优化器(Loshchilov 和 Hutter,2017 年),其中 β 1 = 0.9 \beta_{1}=0.9 β1=0.9, β 2 = 0.95 \beta_{2}=0.95 β2=0.95,weight_decay = 0.1 =0.1 =0.1,并采用多阶段学习率调度策略,其中学习率在 2000 个预热步骤后达到峰值,在训练过程的 80% 后下降到峰值的 31.6%,在训练过程的 90% 后进一步下降到峰值的 10.0%。我们将学习率的最大值设置为 5.3 e − 4 5.3\mathrm{e}-4 5.3e−4,并使用 400 万个标记的批量大小和 4K 的上下文长度。
2.2.2. 评估结果
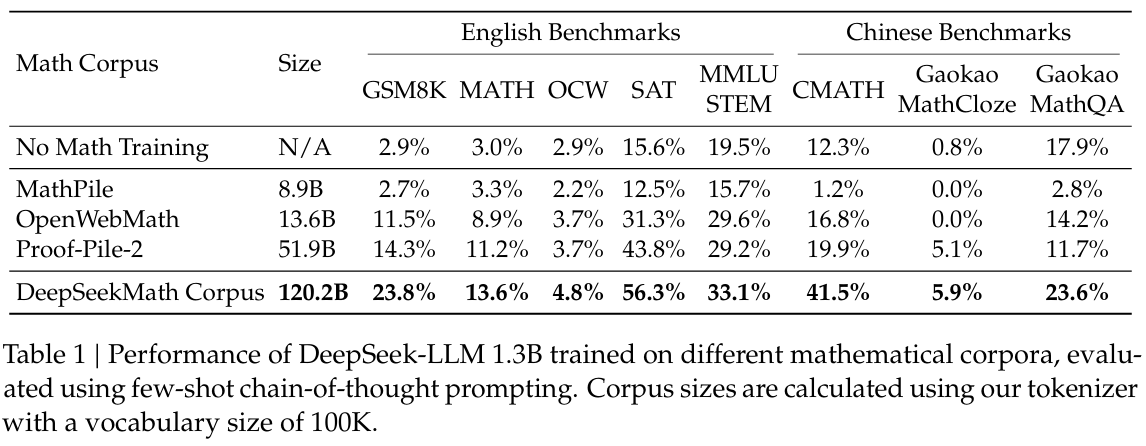
DeepSeekMath 语料库质量高、涵盖多语言数学内容且规模最大。
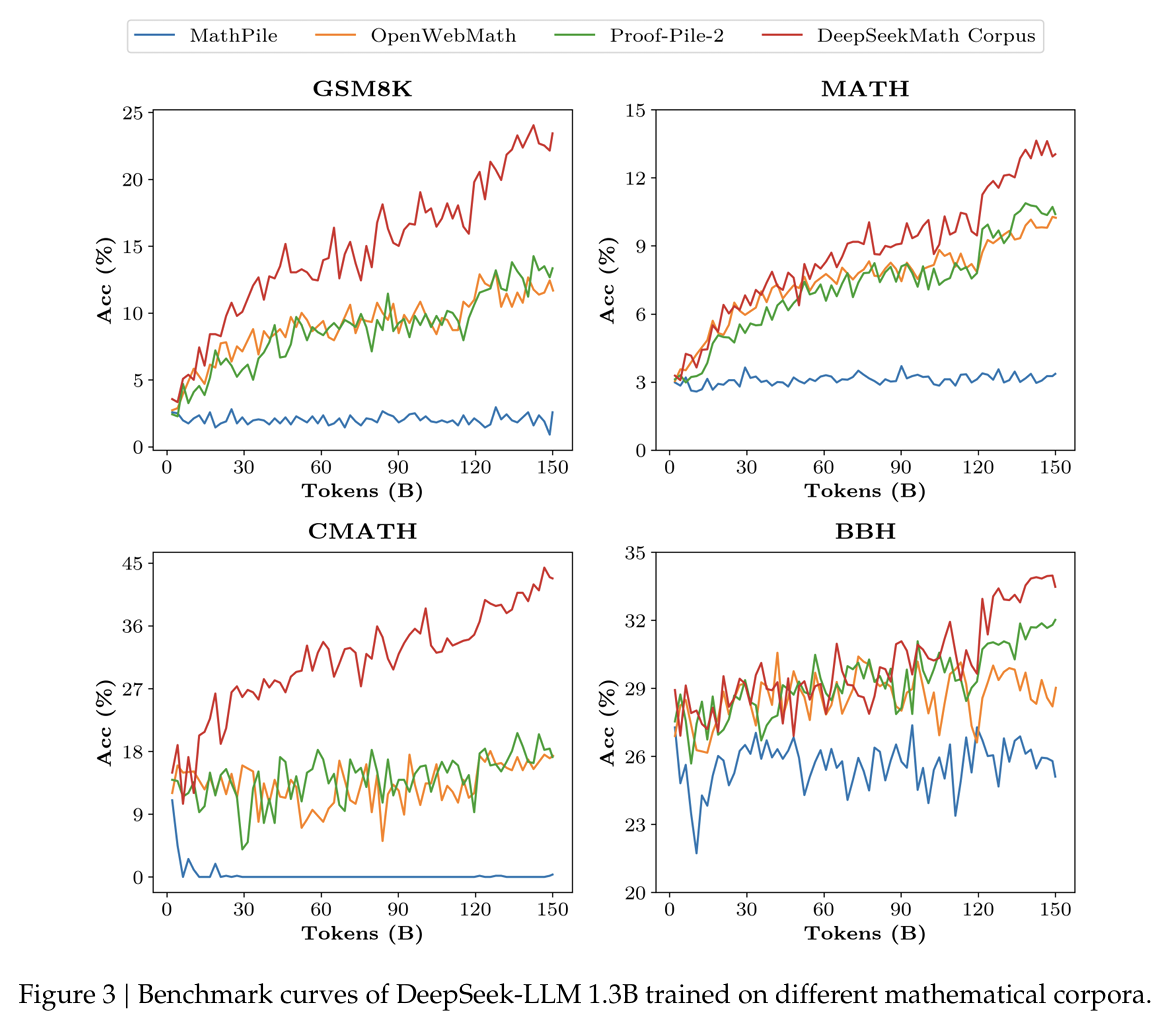
- 高质量:我们使用少样本思维链提示(Wei 等人,2022 年)在 8 个数学基准测试上评估下游性能。如表 1 所示,在 DeepSeekMath 语料库上训练的模型具有明显的性能优势。图 3 显示,在 500 亿个标记(Proof-Pile-2 的 1 个完整轮次)时,在 DeepSeekMath 语料库上训练的模型比在 Proof-Pile-2 上训练的模型表现出更好的性能,这表明 DeepSeekMath 语料库的平均质量更高。
- 多语言:DeepSeekMath 语料库包含多种语言的数据,其中英语和中文是最主要的两种语言。如表 1 所示,在 DeepSeekMath 语料库上进行训练可以提高英语和中文的数学推理性能。相比之下,现有的数学语料库主要以英语为中心,在中文数学推理方面的改进有限,甚至可能阻碍性能。
- 大规模:DeepSeekMath 语料库比现有的数学语料库大几倍。如图 3 所示,在 DeepSeekMath 语料库上训练的 DeepSeek-LLM 1.3B 模型显示出更陡峭的学习曲线和更持久的性能提升。相比之下,基线语料库要小得多,并且在训练过程中已经重复了多轮,导致模型性能迅速达到平稳期。
2.3. 训练与评估 DeepSeekMath-Base 7B
在本节中,我们介绍 DeepSeekMath-Base 7B,这是一个具有强大推理能力的基础模型,尤其在数学方面表现出色。我们的模型以 DeepSeek-Coder-Base-v1.5 7B(Guo 等人,2024 年)为基础进行初始化,并训练了 5000 亿个标记。数据的分布如下:56% 来自 DeepSeekMath 语料库,4% 来自 AlgebraicStack,10% 来自 arXiv,20% 是 Github 代码,剩余的 10% 是来自 Common Crawl 的中英文自然语言数据。我们主要采用第 2.2.1 节中指定的训练设置,但将学习率的最大值设置为 4.2 e − 4 4.2\mathrm{e}-4 4.2e−4,并使用 1000 万个标记的批量大小。
我们对 DeepSeekMath-Base 7B 的数学能力进行了全面评估,重点关注其无需依赖外部工具即可生成自洽数学解决方案的能力、使用工具解决数学问题的能力以及进行形式化定理证明的能力。除了数学之外,我们还提供了该基础模型更一般的概况,包括其在自然语言理解、推理和编程技能方面的表现。
逐步推理解决数学问题
我们使用少样本思维链提示(Wei 等人,2022 年)评估了 DeepSeekMath-Base 在解决英语和汉语中八个基准测试的数学问题上的表现。这些基准测试涵盖了定量推理(例如,GSM8K(Cobbe 等人,2021 年)、MATH(Hendrycks 等人,2021 年)和 CMATH(Wei 等人,2023 年))以及多项选择题(例如,MMLU-STEM(Hendrycks 等人,2020 年)和 Gaokao-MathQA(Zhong 等人,2023 年)),涉及从小学到大学复杂度的各个数学领域。
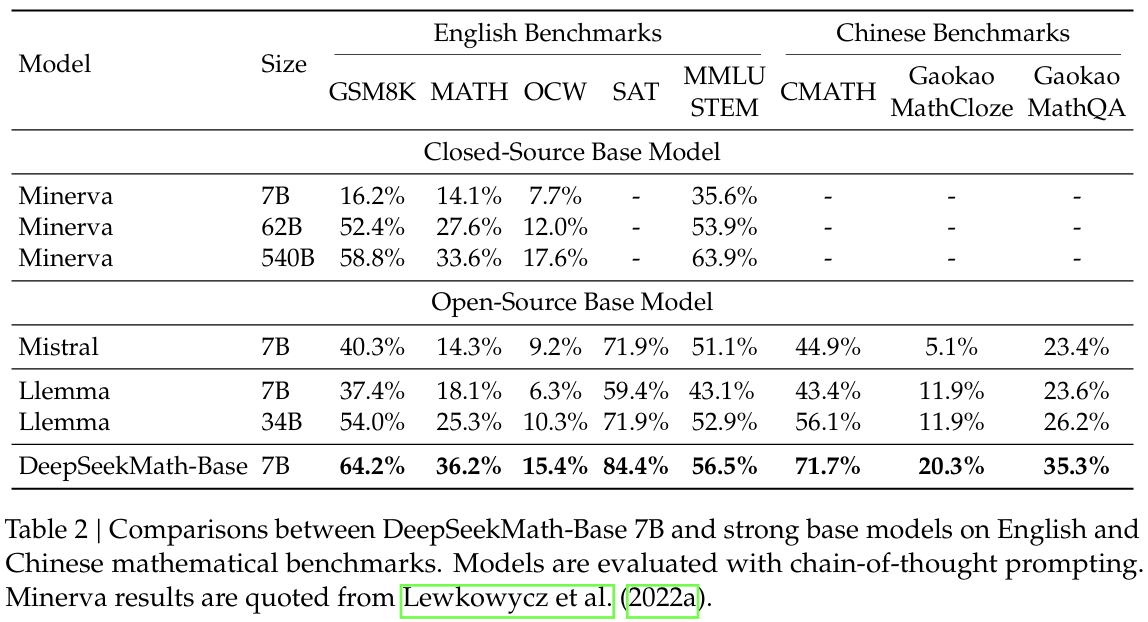
如表 2 所示,在开源基础模型中(包括广泛使用的通用模型 Mistral 7B(Jiang 等人,2023 年)和最近发布的在 Proof-Pile-2(Azerbayev 等人,2023 年)上进行数学训练的 Llemma 34B(Azerbayev 等人,2023 年)),DeepSeekMath-Base 7B 在所有八个基准测试中的性能均处于领先地位。值得注意的是,在具有竞赛级别的 MATH 数据集上,DeepSeekMath-Base 的表现比现有开源基础模型高出绝对值 10% 以上,并且超过了 Minerva 540B(Lewkowycz 等人,2022a 年),这是一个基于 PaLM(Lewkowycz 等人,2022b 年)构建并进一步在数学文本上进行训练的闭源基础模型,其规模是 DeepSeekMath-Base 的 77 倍。
使用工具解决数学问题
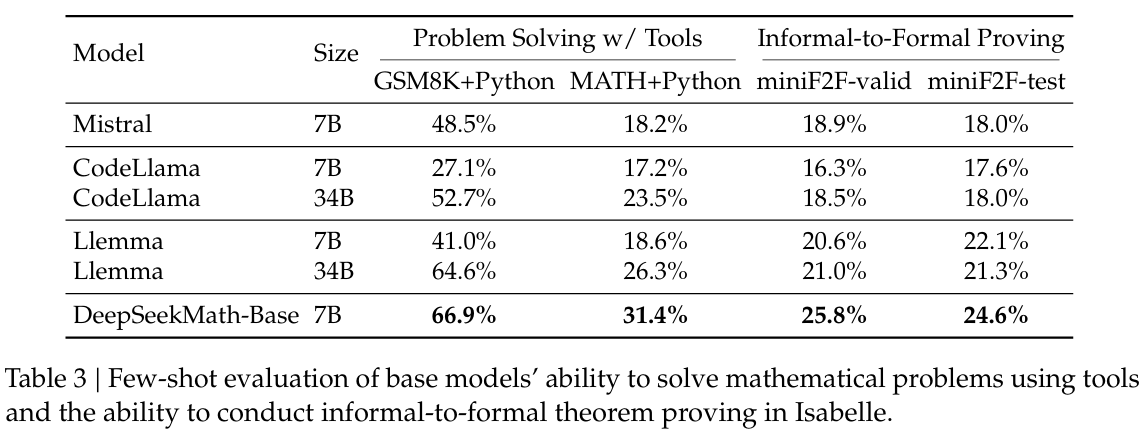
我们使用少样本程序思维提示(Chen 等人,2022 年;Gao 等人,2023 年)在 GSM8K 和 MATH 上评估了程序辅助的数学推理能力。模型被提示通过编写 Python 程序来解决问题,其中可以使用 math 和 sympy 等库进行复杂计算。程序的执行结果被评估为答案。如表 3 所示,DeepSeekMath-Base 7B 的性能优于之前最先进的 Llemma 34B。
形式化数学
形式化证明自动化有助于确保数学证明的准确性和可靠性,并提高效率,近年来受到了越来越多的关注。我们在(Jiang 等人,2022 年)提出的从非形式化到形式化证明的任务上评估了 DeepSeekMath-Base 7B,即根据非形式化陈述、该陈述的形式化对应物以及非形式化证明来生成形式化证明。我们在 miniF2F(Zheng 等人,2021 年)上进行评估,这是一个用于形式化奥林匹克级别数学问题的基准测试,并使用少样本提示为每个问题在 Isabelle 中生成形式化证明。遵循 Jiang 等人(2022 年)的方法,我们利用模型生成证明草图,并使用现成的自动化证明器 Sledgehammer(Paulson,2010 年)来填补缺失的细节。如表 3 所示,DeepSeekMath-Base 7B 在证明自动形式化方面表现出强大的性能。
自然语言理解、推理和代码
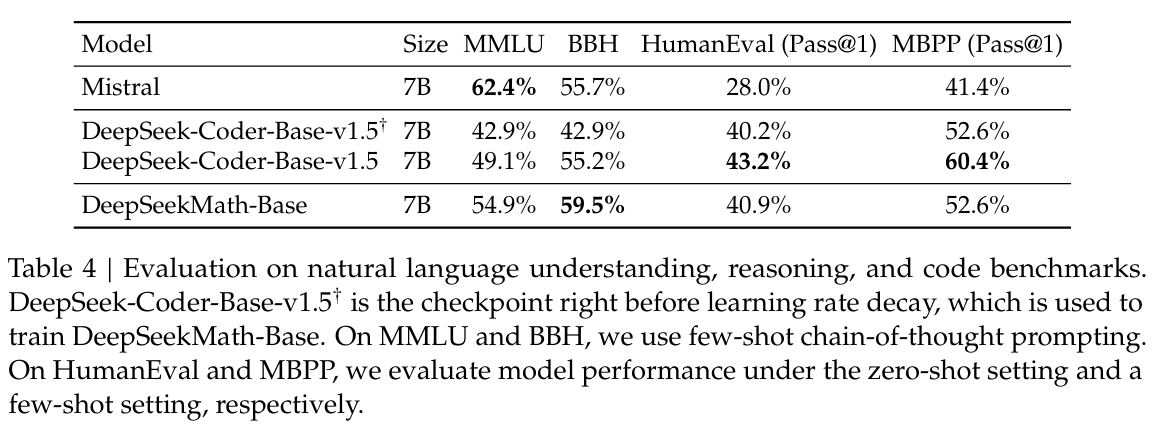
我们在 MMLU(Hendrycks 等人,2020 年)上评估了模型的自然语言理解能力,在 BBH(Suzgun 等人,2022 年)上评估了推理能力,在 HumanEval(Chen 等人,2021 年)和 MBPP(Austin 等人,2021 年)上评估了编码能力。如表 4 所示,与前体模型 DeepSeek-Coder-Base-v1.5(Guo 等人,2024 年)相比,DeepSeekMath-Base 7B 在 MMLU 和 BBH 上的性能有了显著提升,这表明数学训练对语言理解和推理产生了积极影响。此外,通过包含用于持续训练的代码标记,DeepSeekMath-Base 7B 在两个编码基准测试上有效地保持了 DeepSeek-Coder-Base-v1.5 的性能。总体而言,在三个推理和编码基准测试上,DeepSeekMath-Base 7B 的性能显著优于通用模型 Mistral 7B(Jiang 等人,2023 年)。
3. 有监督微调
3.1. SFT 数据整理
我们构建了一个数学指令微调数据集,涵盖了来自不同数学领域且复杂度各异的英语和汉语问题:每个问题都配有以思维链(CoT)(Wei 等人,2022 年)、程序思维(PoT)(Chen 等人,2022 年;Gao 等人,2023 年)以及工具集成推理格式(Gou 等人,2023 年)呈现的解决方案。训练样本总数为 77.6 万个。
- 英语数学数据集:我们为 GSM8K 和 MATH 中的问题标注了集成工具的解决方案,并采用了 MathInstruct(Yue 等人,2023 年)的一个子集以及 Lila-OOD(Mishra 等人,2022 年)的训练集,其中问题通过 CoT 或 PoT 解决。我们的英语数据集涵盖了代数、概率论、数论、微积分和几何等多个数学领域。
- 汉语数学数据集:我们收集了涵盖 76 个子主题(如线性方程)的汉语 K-12 数学问题,并分别用 CoT 和工具集成推理格式标注了解决方案。
3.2. 训练与评估 DeepSeekMath-Instruct 7B
在本节中,我们介绍 DeepSeekMath-Instruct 7B,该模型基于 DeepSeekMath-Base 进行了数学指令微调。训练样本被随机拼接,直到达到最大上下文长度 4K 个标记。我们使用 256 的批量大小和 5 e − 5 5\mathrm{e}-5 5e−5 的恒定学习率对模型进行了 500 步的训练。
我们在 4 个英语和汉语的定量推理基准测试上,评估了模型在不使用工具和使用工具情况下的数学性能。我们将我们的模型与当时领先的模型进行了对比:
- 闭源模型 包括:(1)GPT 系列,其中 GPT-4(OpenAI,2023 年)和 GPT-4 Code Interpreter 2 {}^{2} 2 功能最为强大;(2)Gemini Ultra 和 Pro(Anil 等人,2023 年);(3)Inflection-2(Inflection AI,2023 年);(4)Grok-1 3 {}^{3} 3,以及中国公司最近发布的模型,包括(5)百川-3 4 {}^{4} 4;(6)GLM 系列(Du 等人,2022 年)中最新的 GLM-4 5 {}^{5} 5。这些模型均为通用目的模型,其中大多数已经过一系列对齐处理。
- 开源模型 包括:通用模型如(1)DeepSeek-LLM-Chat 67B(DeepSeekAI,2024 年);(2)Qwen 72B(Bai 等人,2023 年);(3)SeaLLM-v2 7B(Nguyen 等人,2023 年);(4)ChatGLM3 6B(ChatGLM3 团队,2023 年),以及在数学方面有所增强的模型,包括(5)基于 InternLM2 并经过数学训练和指令微调的 InternLM2-Math 20B;(6)将 PPO 训练(Schulman 等人,2017 年)应用于 Mistral 7B(Jiang 等人,2023 年)并采用过程监督奖励模型的 Math-Shepherd-Mistral 7B;(7)WizardMath 系列(Luo 等人,2023 年),该系列使用进化指令(即一种使用人工智能进化指令的指令微调版本)和 PPO 训练,在 Mistral 7B 和 Llama-2 70B(Touvron 等人,2023 年)上改进了数学推理能力,训练问题主要来源于 GSM8K 和 MATH;(8)MetaMath 70B(Yu 等人,2023 年),该模型是在 GSM8K 和 MATH 的增强版本上对 Llama-2 70B 进行了微调;(9)ToRA 34B(Gou 等人,2023 年),该模型是对 CodeLlama 34B 进行微调以实现工具集成数学推理;(10)MAmmoTH 70B(Yue 等人,2023 年),该模型是在 MathInstruct 上对 Llama-2 70B 进行了指令微调。
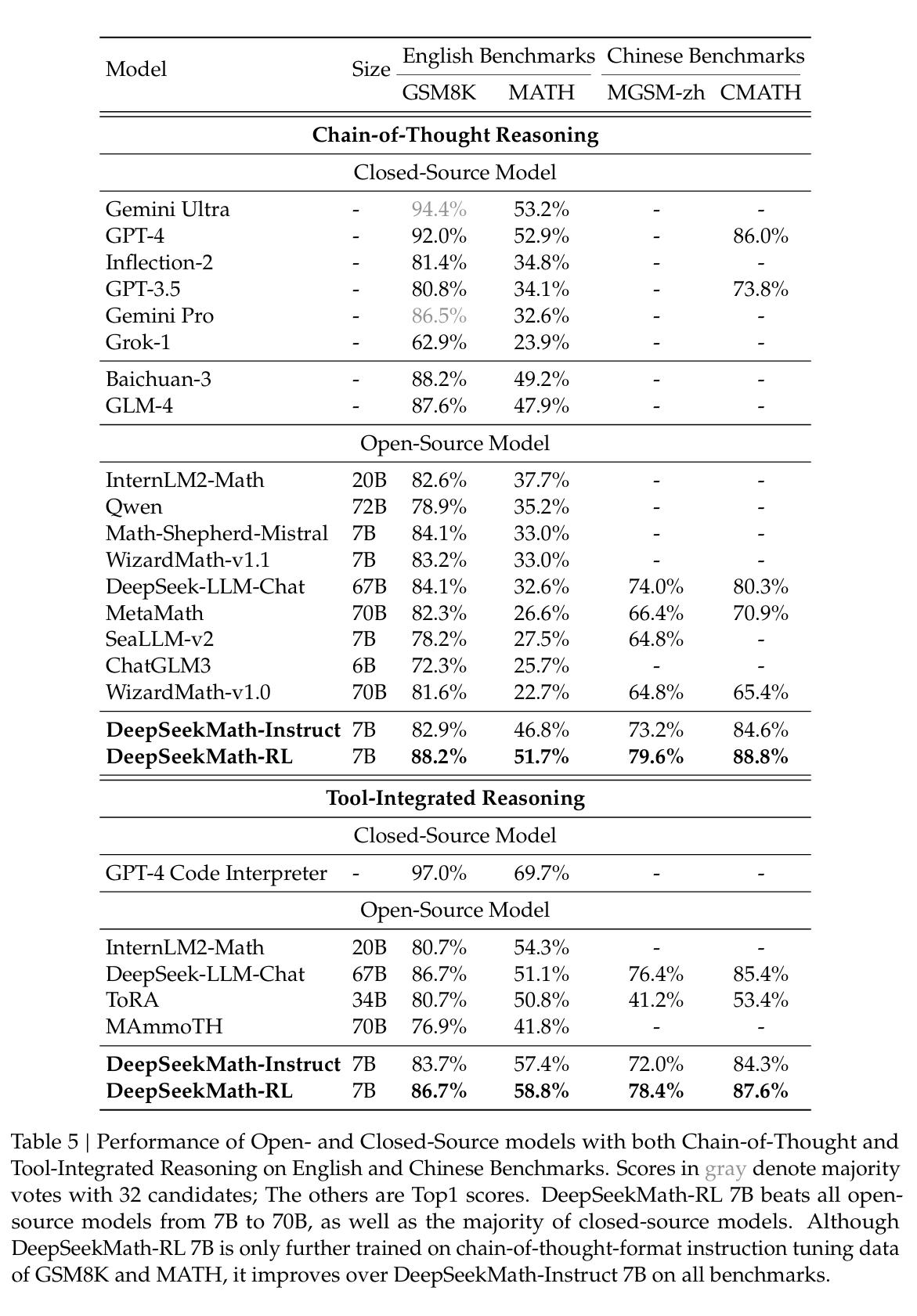
如表 5 所示,在不允许使用工具的评估设置下,DeepSeekMath-Instruct 7B 展示了强大的逐步推理能力。值得注意的是,在竞赛级别的 MATH 数据集上,我们的模型在绝对值上至少超越了所有开源模型和大多数专有模型(例如,Inflection-2 和 Gemini Pro)9%。即使对于规模明显更大的模型(例如,Qwen 72B)或通过专注于数学的强化学习进行了专门增强的模型(例如,WizardMath-v1.1 7B),也是如此。虽然 DeepSeekMath-Instruct 在 MATH 上与中国专有模型 GLM-4 和百川-3 相当,但其性能仍低于 GPT-4 和 Gemini Ultra。
在允许模型集成自然语言推理和基于程序的工具使用以解决问题的评估设置下,DeepSeekMath-Instruct 7B 在 MATH 上的准确率接近 60%,超越了所有现有开源模型。在其他基准测试上,我们的模型与规模是其 10 倍的先前最先进模型 DeepSeek-LLM-Chat 67B 相比具有竞争力。
4. 强化学习
4.1. 群组相对策略优化
强化学习(RL)已被证明在监督微调(SFT)阶段之后,能够进一步提升大型语言模型(LLM)的数学推理能力(Luo等人,2023;Wang等人,2023b)。在本节中,我们介绍一种高效且有效的强化学习算法------群组相对策略优化(Group Relative Policy Optimization,GRPO)。
4.1.1. 从近端策略优化(PPO)到群组相对策略优化(GRPO)
近端策略优化(PPO)(Schulman等人,2017)是一种广泛应用于LLM强化学习微调阶段的演员-评论家算法(Ouyang等人,2022)。具体而言,它通过最大化以下替代目标函数来优化LLM:
J P P O ( θ ) = E q ∼ P ( Q ) , o ∼ π θ old ( O ∣ q ) 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ min π θ ( o t ∣ q , o \< t ) π θ old ( o t ∣ q , o \< t ) A t , clip ( π θ ( o t ∣ q , o \< t ) π θ old ( o t ∣ q , o \< t ) , 1 − ε , 1 + ε ) A t \mathcal{J}{P P O}(\theta)=\mathbb{E}\leftq \\sim P(Q), o \\sim \\pi_{\\theta_{\\text {old }}}(O \\mid q)\\right \frac{1}{|o|} \sum{t=1}^{|o|} \min \left\\frac{\\pi_{\\theta}\\left(o_{t} \\mid q, o_{\
其中, π θ \pi_{\theta} πθ和 π θ old \pi_{\theta_{\text {old }}} πθold 分别是当前策略模型和旧策略模型, q q q和 o o o分别是从问题数据集和旧策略 π θ old \pi_{\theta_{\text {old }}} πθold 中采样得到的问题和输出。 ε \varepsilon ε是PPO中引入的用于稳定训练的截断相关超参数。 A t A_{t} At是优势函数,通过广义优势估计(GAE)(Schulman等人,2015)基于奖励 { r ≥ t } \left\{r_{\geq t}\right\} {r≥t}和学习的值函数 V ψ V_{\psi} Vψ计算得出。因此,在PPO中,需要同时训练值函数和策略模型,并且为了缓解奖励模型的过度优化,标准做法是在每个标记的奖励中添加来自参考模型的逐标记KL散度惩罚(Ouyang等人,2022),即:
r t = r φ ( q , o ≤ t ) − β log π θ ( o t ∣ q , o < t ) π r e f ( o t ∣ q , o < t ) r_{t}=r_{\varphi}\left(q, o_{\leq t}\right)-\beta \log \frac{\pi_{\theta}\left(o_{t} \mid q, o_{<t}\right)}{\pi_{r e f}\left(o_{t} \mid q, o_{<t}\right)} rt=rφ(q,o≤t)−βlogπref(ot∣q,o<t)πθ(ot∣q,o<t)
其中, r φ r_{\varphi} rφ是奖励模型, π r e f \pi_{r e f} πref是参考模型(通常是初始的SFT模型), β \beta β是KL散度惩罚的系数。
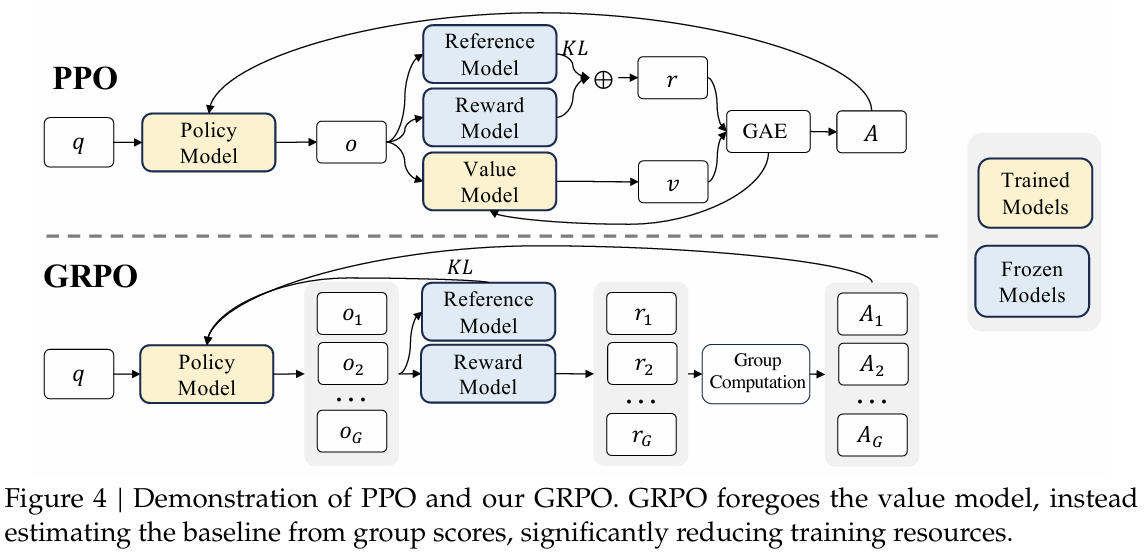
由于PPO中采用的值函数通常与策略模型大小相当,这带来了显著的内存和计算负担。此外,在强化学习训练过程中,值函数被用作计算优势函数以减少方差的基准。然而,在LLM的情境下,通常只有最后一个标记由奖励模型分配奖励分数,这可能会使训练一个在每个标记上都准确的值函数变得复杂。为了解决这个问题,如图4所示,我们提出了群组相对策略优化(GRPO),它无需像PPO那样进行额外的值函数近似,而是使用对同一问题的多个采样输出的平均奖励作为基准。更具体地说,对于每个问题 q q q,GRPO从旧策略 π θ old \pi_{\theta_{\text {old }}} πθold 中采样一组输出 { o 1 , o 2 , ⋯ , o G } \left\{o_{1}, o_{2}, \cdots, o_{G}\right\} {o1,o2,⋯,oG},然后通过最大化以下目标函数来优化策略模型:
J G R P O ( θ ) = E q ∼ P ( Q ) , { o i } i = 1 G ∼ π θ old ( O ∣ q ) 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ { min π θ ( o i , t ∣ q , o i , \< t ) π θ old ( o i , t ∣ q , o i , \< t ) A \^ i , t , clip ( π θ ( o i , t ∣ q , o i , \< t ) π θ old ( o i , t ∣ q , o i , \< t ) , 1 − ε , 1 + ε ) A \^ i , t − β D K L π θ ∣ ∣ π r e f } , \begin{aligned} \mathcal{J}{G R P O}(\theta) & =\mathbb{E}\leftq \\sim P(Q),\\left\\{o_{i}\\right\\}_{i=1}\^{G} \\sim \\pi_{\\theta_{\\text {old }}}(O \\mid q)\\right \\ & \frac{1}{G} \sum{i=1}^{G} \frac{1}{\left|o_{i}\right|} \sum_{t=1}^{\left|o_{i}\right|}\left\{\min \left\\frac{\\pi_{\\theta}\\left(o_{i, t} \\mid q, o_{i,\
其中, ε \varepsilon ε和 β \beta β是超参数, A ^ i , t \hat{A}{i, t} A^i,t是基于每组输出内部相对奖励计算的优势函数,将在下文子节中详细介绍。GRPO利用的群组相对方式来计算优势函数,与奖励模型的比较性质相契合,因为奖励模型通常是在同一问题的不同输出之间的比较数据集上进行训练的。另外,值得注意的是,GRPO没有在奖励中添加KL散度惩罚,而是通过直接将训练后的策略与参考策略之间的KL散度添加到损失函数中来进行正则化,避免了 A ^ i , t \hat{A}{i, t} A^i,t计算的复杂性。
与式(2)中使用的KL散度惩罚项不同,我们使用以下无偏估计器(Schulman,2020)来估计KL散度:
D K L π θ ∣ ∣ π r e f = π r e f ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − log π r e f ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − 1 , \mathbb{D}{K L}\left\\pi_{\\theta}\| \| \\pi_{r e f}\\right=\frac{\pi{r e f}\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta}\left(o_{i, t} \mid q, o_{i,<t}\right)}-\log \frac{\pi_{r e f}\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta}\left(o_{i, t} \mid q, o_{i,<t}\right)}-1, DKLπθ∣∣πref=πθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−logπθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−1,
该估计器保证为正。

4.1.2. 使用GRPO进行结果监督强化学习
形式上,对于每个问题 q q q,从旧策略模型 π θ old \pi_{\theta_{\text {old }}} πθold 中采样一组输出 { o 1 , o 2 , ⋯ , o G } \left\{o_{1}, o_{2}, \cdots, o_{G}\right\} {o1,o2,⋯,oG}。然后使用奖励模型对这些输出进行评分,得到相应的 G G G个奖励 r = { r 1 , r 2 , ⋯ , r G } \mathbf{r}=\left\{r_{1}, r_{2}, \cdots, r_{G}\right\} r={r1,r2,⋯,rG}。随后,这些奖励通过减去组平均值并除以组标准差来进行归一化。结果监督在每个输出 o i o_{i} oi的末尾提供归一化奖励,并将输出中所有标记的优势函数 A ^ i , t \hat{A}{i, t} A^i,t设置为归一化奖励,即 A ^ i , t = r ~ i = r i − mean ( r ) std ( r ) \hat{A}{i, t}=\widetilde{r}{i}=\frac{r{i}-\operatorname{mean}(\mathbf{r})}{\operatorname{std}(\mathbf{r})} A^i,t=r i=std(r)ri−mean(r),然后通过最大化式(3)中定义的目标函数来优化策略。
4.1.3. 使用GRPO进行过程监督强化学习
结果监督仅在每个输出的末尾提供一个奖励,这可能不足以监督复杂数学任务中的策略。遵循Wang等人(2023b)的研究,我们还探索了过程监督,它在每个推理步骤的末尾提供一个奖励。形式上,给定问题 q q q和 G G G个采样输出 { o 1 , o 2 , ⋯ , o G } \left\{o_{1}, o_{2}, \cdots, o_{G}\right\} {o1,o2,⋯,oG},使用过程奖励模型对输出的每个步骤进行评分,得到相应的奖励: R = { { r 1 index ( 1 ) , ⋯ , r 1 index ( K 1 ) } , ⋯ , { r G index ( 1 ) , ⋯ , r G index ( K G ) } } \mathbf{R}=\left\{\left\{r_{1}^{\text {index }(1)}, \cdots, r_{1}^{\text {index }\left(K_{1}\right)}\right\}, \cdots,\left\{r_{G}^{\text {index }(1)}, \cdots, r_{G}^{\text {index }\left(K_{G}\right)}\right\}\right\} R={{r1index (1),⋯,r1index (K1)},⋯,{rGindex (1),⋯,rGindex (KG)}},其中 index ( j ) \text{index}(j) index(j)是第 j j j个步骤的结束标记索引, K i K_{i} Ki是第 i i i个输出的总步骤数。我们也使用平均值和标准差对这些奖励进行归一化,即 r ~ i index ( j ) = r i index ( j ) − − mean ( R ) std ( R ) \tilde{r}{i}^{\text {index }(j)}=\frac{{r{i}^{\text {index }(j)}}^{-}-\operatorname{mean}(\mathbf{R})}{\operatorname{std}(\mathbf{R})} r~iindex (j)=std(R)riindex (j)−−mean(R)。随后,过程监督将每个标记的优势函数计算为后续步骤归一化奖励的总和,即 A ^ i , t = ∑ index ( j ) ≥ t r ~ i index ( j ) \hat{A}{i, t}=\sum{\text {index }(j) \geq t} \tilde{r}_{i}^{\text {index }(j)} A^i,t=∑index (j)≥tr~iindex (j),然后通过最大化式(3)中定义的目标函数来优化策略。
4.1.4. 使用GRPO进行迭代强化学习
随着强化学习训练过程的推进,旧的奖励模型可能不足以监督当前的策略模型。因此,我们还探索了使用GRPO的迭代强化学习。如图1算法所示,在迭代GRPO中,我们基于策略模型的采样结果为奖励模型生成新的训练集,并使用包含10%历史数据的回放机制持续训练旧的奖励模型。然后,我们将参考模型设置为策略模型,并使用新的奖励模型持续训练策略模型。
4.2. 训练和评估DeepSeekMath-RL
我们基于DeepSeekMath-Instruct 7B进行强化学习。RL的训练数据是来自SFT数据中与GSM8K和MATH相关的思维链格式问题,大约包含14.4万个问题。我们排除了其他SFT问题,以研究RL对在整个RL阶段缺乏数据的基准测试的影响。我们按照(Wang等人,2023b)的方法构建奖励模型的训练集。我们基于DeepSeekMath-Base 7B,使用2e-5的学习率训练初始奖励模型。对于GRPO,我们将策略模型的学习率设置为1e-6。KL散度系数为0.04。对于每个问题,我们采样64个输出。最大长度设置为1024,训练批次大小为1024。策略模型在每个探索阶段后只进行一次更新。我们按照DeepSeekMath-Instruct 7B的方法在基准测试上评估DeepSeekMath-RL 7B。对于DeepSeekMath-RL 7B,使用思维链推理的GSM8K和MATH可视为域内任务,而所有其他基准测试可视为域外任务。
表5展示了在英语和汉语基准测试上,使用思维链和工具集成推理的开源和闭源模型的性能。我们发现:1)DeepSeekMath-RL 7B在使用思维链推理的情况下,在GSM8K和MATH上分别达到了88.2%和51.7%的准确率。这一性能超越了7B到70B范围内所有开源模型以及大部分闭源模型。2)至关重要的是,DeepSeekMath-RL 7B仅在GSM8K和MATH的思维链格式指令微调数据上进行训练,从DeepSeekMath-Instruct 7B开始。尽管其训练数据范围有限,但它在所有评估指标上都优于DeepSeekMath-Instruct 7B,展示了强化学习的有效性。
5. 讨论
在本节中,我们将分享在预训练和强化学习(RL)实验中的发现。
5.1. 预训练中的经验教训
我们首先分享在预训练方面的经验。除非另有说明,我们将遵循第2.2.1节中概述的训练设置。值得注意的是,在本节提及DeepSeekMath语料库时,我们使用的是数据收集过程第二轮迭代中产生的890亿个标记(token)的数据集。
5.1.1. 代码训练有利于数学推理
一个流行但未经证实的假设认为,代码训练能提升推理能力。我们试图对此提供部分回应,特别是在数学领域:代码训练能提升模型在工具辅助和非工具辅助情况下的数学推理能力。
为研究代码训练对数学推理的影响,我们进行了以下两阶段训练和单阶段训练的实验:
两阶段训练
- 代码训练4000亿个标记(Tokens)→数学训练1500亿个标记(Tokens):我们对DeepSeekLLM 1.3B进行4000亿个代码标记的训练,随后进行1500亿个数学标记的训练;
- 通用训练4000亿个标记(Tokens)→数学训练1500亿个标记(Tokens):作为对照实验,我们还在训练的第一阶段使用通用标记(从DeepSeek-AI创建的大型通用语料库中采样)而非代码标记,以探究代码标记在提升数学推理能力方面相对于通用标记的优势。
单阶段训练
- 数学训练1500亿个标记(Tokens):我们对DeepSeek-LLM 1.3B进行1500亿个数学标记的训练;
- 4000亿个代码标记和1500亿个数学标记混合训练 :代码训练后的数学训练会降低编码性能。我们探究在单阶段训练中,将代码标记与数学标记混合是否仍能提升数学推理能力,并缓解灾难性遗忘问题。
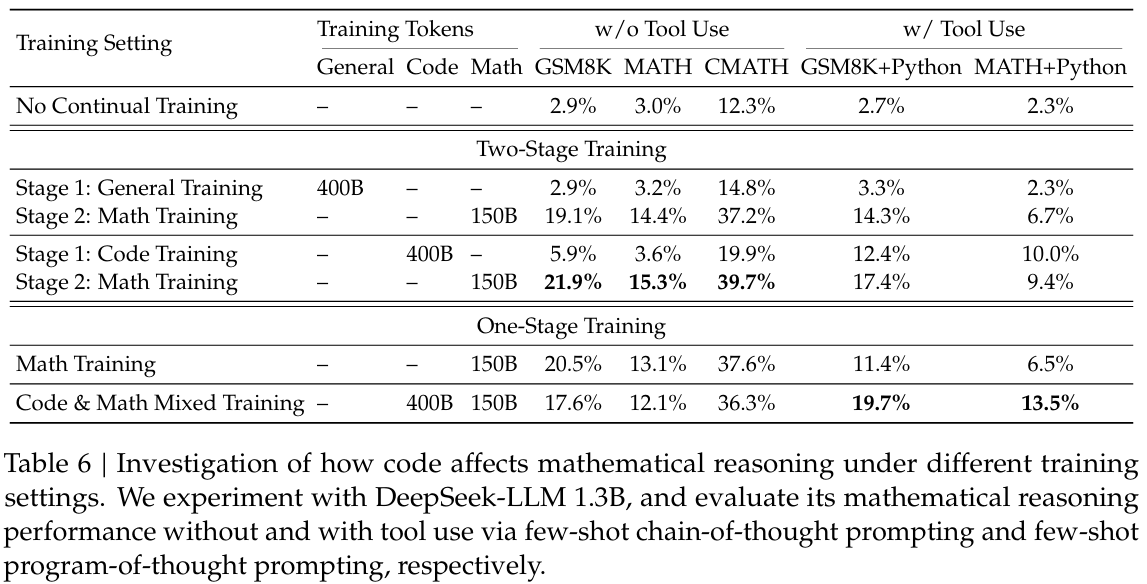
表6和表7展示了不同训练设置下的下游性能。
代码训练在两阶段训练和单阶段训练设置下均有利于程序辅助的数学推理。如表6所示,在两阶段训练设置下,仅代码训练就已显著提升使用Python解决GSM8K和MATH问题的能力。第二阶段的数学训练进一步提升了性能。有趣的是,在单阶段训练设置下,将代码标记和数学标记混合能有效缓解两阶段训练中出现的灾难性遗忘问题,同时还能协同提升编码能力(表7)和程序辅助的数学推理能力(表6)。
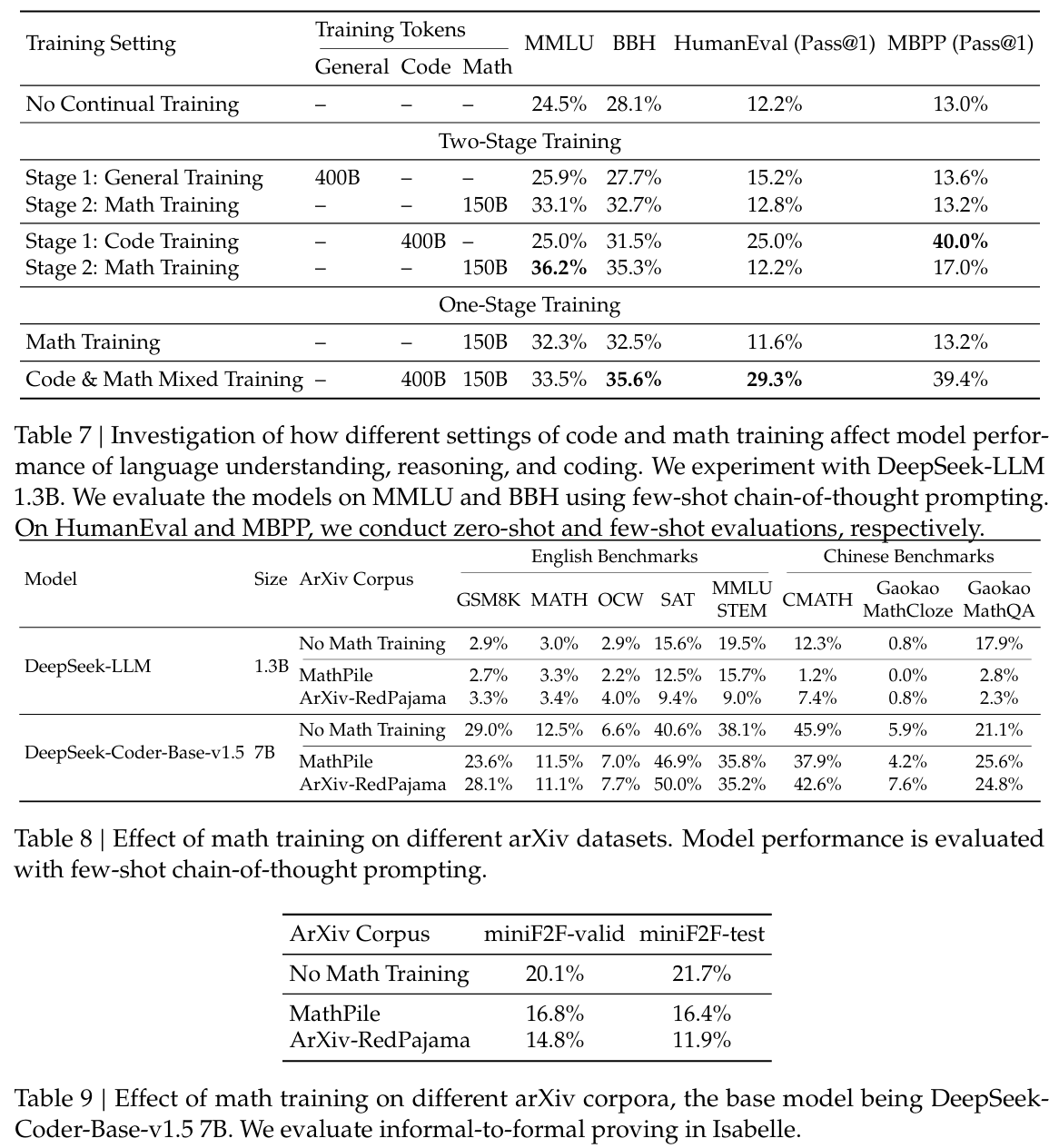
代码训练还能提升非工具辅助的数学推理能力。在两阶段训练设置下,代码训练的初始阶段已带来中等程度的性能提升。它还提高了后续数学训练的效率,最终带来最佳性能。然而,将代码标记和数学标记混合进行单阶段训练会损害非工具辅助的数学推理能力。一种推测是,由于DeepSeek-LLM 1.3B的规模有限,无法同时充分吸收代码和数学数据。
5.1.2. ArXiv论文似乎对提升数学推理能力无效
ArXiv论文通常被作为数学预训练数据的一部分(Azerbayev等人,2023年;Lewkowycz等人,2022a年;Polu和Sutskever,2020年;Wang等人,2023c年)。然而,关于其对数学推理能力影响的详细分析尚未广泛开展。或许与直觉相反,根据我们的实验,ArXiv论文似乎对提升数学推理能力无效。我们使用经过不同处理流程的ArXiv语料库,对不同规模的模型进行了实验,包括DeepSeek-LLM 1.3B和DeepSeek-Coder-Base-v1.5 7B(Guo等人,2024年):
- MathPile(Wang等人,2023c年):一个经过清洗和过滤启发式规则开发的89亿个标记的语料库,其中超过85%是科学ArXiv论文;
- ArXiv-RedPajama(Computer,2023年):移除了前导、注释、宏和参考文献的ArXiv LaTeX文件全集,共计280亿个标记。
在我们的实验中,我们分别在每个ArXiv语料库上对DeepSeek-LLM 1.3B进行了1500亿个标记的训练,对DeepSeek-Coder-Base-v1.5 7B进行了400亿个标记的训练。看起来,ArXiv论文对提升数学推理能力无效。当仅在ArXiv语料库上进行训练时,两个模型在本研究中采用的不同复杂度的各种数学基准测试中均未显示出显著的性能提升,甚至出现性能下降。这些基准测试包括GSM8K和MATH等定量推理数据集(表8)、MMLU-STEM等多项选择题挑战(表8)以及miniF2F等形式数学(表9)。
然而,这一结论有其局限性,应谨慎对待。我们尚未研究:
- ArXiv标记对本研究中未包含的特定数学相关任务的影响,例如定理的非形式化,即将正式陈述或证明转换为非正式版本;
- ArXiv标记与其他类型数据结合时的影响;
- ArXiv论文的优势是否会在更大规模的模型上显现出来。
因此,需要进一步探索,我们将此留待未来研究。
5.2. 强化学习的见解
5.2.1. 迈向统一范式
在本节中,我们提供了一个统一范式来分析不同的训练方法,如监督微调(SFT)、拒绝采样微调(RFT)、直接偏好优化(DPO)、近端策略优化(PPO)、广义拒绝策略优化(GRPO)等,并进一步进行实验以探索统一范式的因素。一般来说,训练方法关于参数 θ \theta θ的梯度可以表示为:
∇ θ J A ( θ ) = E ( q , o ) ∼ D ⏟ 数据源 ( 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ G C A ( q , o , t , π r f ) ⏟ 梯度系数 ∇ θ log π θ ( o t ∣ q , o < t ) ) \nabla_{\theta} \mathcal{J}{\mathcal{A}}(\theta)=\mathbb{E}\\underbrace{(q, o) \\sim \\mathcal{D}}_{\\text {数据源}}(\frac{1}{|o|} \sum{t=1}^{|o|} \underbrace{G C_{\mathcal{A}}\left(q, o, t, \pi_{r f}\right)}{\text {梯度系数}} \nabla{\theta} \log \pi_{\theta}\left(o_{t} \mid q, o_{<t}\right)) ∇θJA(θ)=E数据源 (q,o)∼D(∣o∣1∑t=1∣o∣梯度系数 GCA(q,o,t,πrf)∇θlogπθ(ot∣q,o<t))
存在三个关键组成部分:1)数据源 D \mathcal{D} D,它决定了训练数据;2)奖励函数 π r f \pi_{r f} πrf,它是训练奖励信号的来源;3)算法 A \mathcal{A} A,它将训练数据和奖励信号处理为梯度系数 G C GC GC,该系数决定了对数据的惩罚或强化的程度。我们基于这样一个统一范式来分析几种具有代表性的方法:
- 监督微调(SFT):SFT在人类选择的SFT数据上对预训练模型进行微调。
- 拒绝采样微调(RFT):RFT在基于SFT问题从SFT模型中采样的过滤输出上进一步微调SFT模型。RFT根据答案的正确性来过滤输出。
- 直接偏好优化(DPO):DPO通过使用成对的DPO损失在从SFT模型中采样的增强输出上进一步微调SFT模型来优化SFT模型。
- 在线拒绝采样微调(Online RFT):与RFT不同,Online RFT使用SFT模型初始化策略模型,并通过使用从实时策略模型中采样的增强输出进行微调来优化它。
- PPO/GRPO:PPO/GRPO使用SFT模型初始化策略模型,并使用从实时策略模型中采样的输出来强化它。
我们在表10中总结了这些方法的组成部分。请参考附录A.1以获取更详细的推导过程。
关于数据源的观察 :我们将数据源分为在线采样和离线采样两类。在线采样表示训练数据来自实时训练策略模型的探索结果,而离线采样表示训练数据来自初始SFT模型的采样结果。RFT和DPO遵循离线风格,而Online RFT和GRPO遵循在线风格。
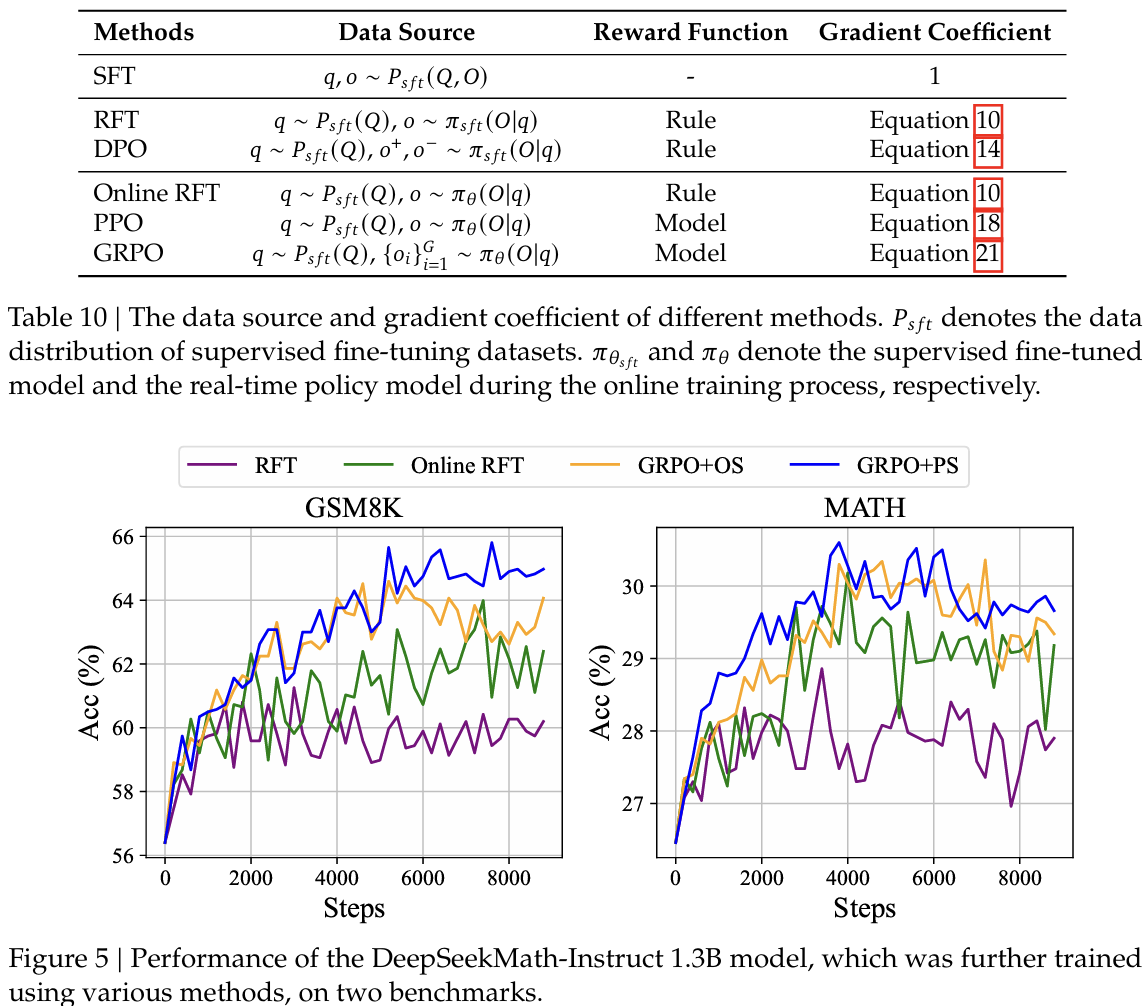
如图5所示,我们发现Online RFT在两个基准测试上显著优于RFT。具体来说,Online RFT在训练的早期阶段与RFT相当,但在后期阶段获得了绝对优势,展示了在线训练的优越性。这是直观的,因为在初始阶段,执行器与SFT模型非常相似,采样数据仅显示出微小差异。然而,在后期阶段,从执行器中采样的数据将显示出更显著的差异,实时数据采样将提供更大的优势。
关于梯度系数的观察 :算法将奖励信号处理为梯度系数以更新模型参数。在我们的实验中,我们将奖励函数分为"规则"和"模型"两类。规则指的是根据答案的正确性来判断响应的质量,模型表示我们训练一个奖励模型来对每个响应进行评分。奖励模型的训练数据基于规则判断。等式10和21突出了GRPO和Online RFT之间的一个关键区别:GRPO根据奖励模型提供的奖励值独特地调整其梯度系数。这使得能够根据响应的不同程度对响应进行差异化的强化和惩罚。相比之下,Online RFT缺乏这一特性;它不会惩罚不正确的响应,并且以相同的强度水平统一强化所有答案正确的响应。
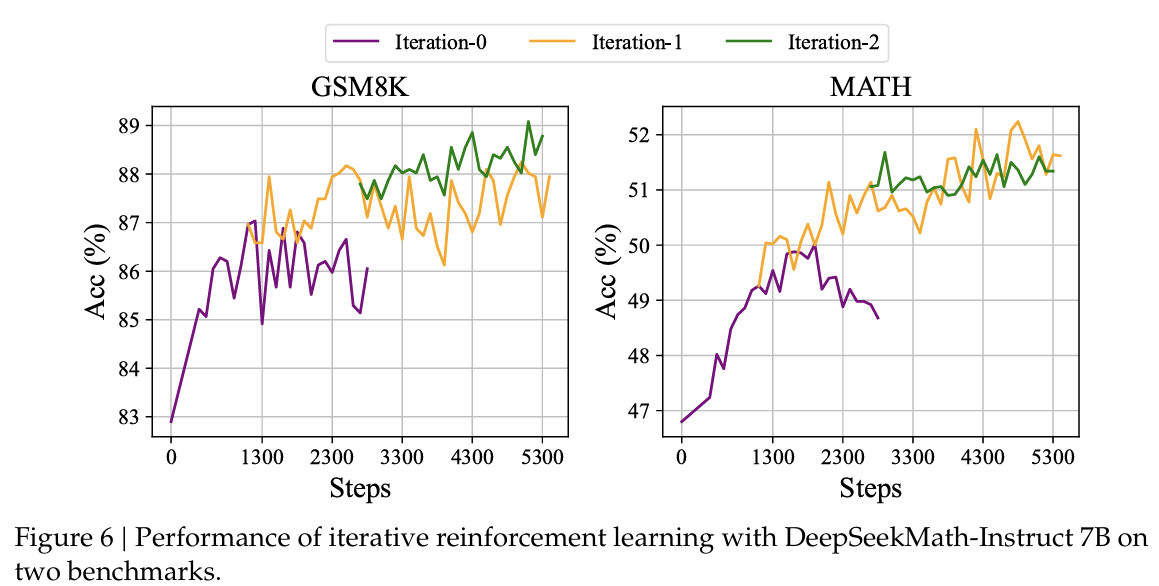
如图5所示,GRPO超越了Online RFT,从而突出了改变正负梯度系数的效率。此外,GRPO+PS相比GRPO+OS表现出更优越的性能,表明使用细粒度、步骤感知的梯度系数的益处。此外,我们探索了迭代强化学习,在我们的实验中,我们进行了两轮迭代。如图6所示,我们注意到迭代强化学习显著提升了性能,特别是在第一轮迭代中。
5.2.2. 为什么强化学习有效?
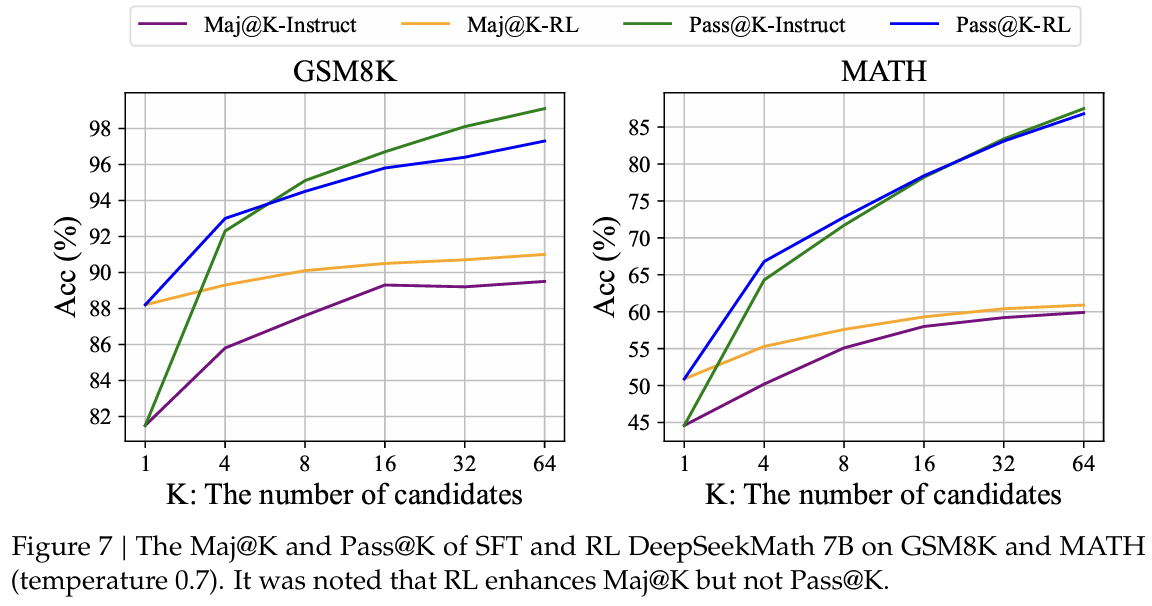
在本文中,我们基于指令微调数据的一个子集开展强化学习,并在指令微调模型上实现了显著的性能提升。为了进一步解释强化学习为何有效,我们在两个基准数据集上评估了指令模型(Instruct)和强化学习模型(RL)的Pass@K和Maj@K准确率。如图7所示,强化学习提升了Maj@K的性能,但并未提升Pass@K的性能。这些发现表明,强化学习通过使输出分布更加稳健来增强模型的整体性能,换句话说,这种改进似乎归因于从TopK中提升了正确响应的比例,而非基础能力的增强。类似地,(Wang等人,2023a)在监督微调(SFT)模型的推理任务中发现了不匹配问题,表明通过一系列偏好对齐策略(Song等人,2023;Wang等人,2023a;Yuan等人,2023b)可以改善SFT模型的推理性能。
5.2.3. 如何实现更有效的强化学习?
我们证明了强化学习在数学推理任务中表现良好。我们还提供了一个统一的范式来理解不同的代表性训练方法。在该范式中,所有方法都被概念化为直接或简化的强化学习技术。如公式5所总结,存在三个关键组成部分:数据源、算法和奖励函数。我们针对这三个组成部分提供了一些未来可能的研究方向。
数据源 数据源是所有训练方法的原材料。在强化学习的背景下,我们特别将数据源定义为从策略模型采样输出的未标注问题。在本文中,我们仅使用指令微调阶段的问题和朴素的核采样(naive nucleus sampling)来采样输出。我们认为,这是我们的强化学习流程仅提升Maj@K性能的一个潜在原因。未来,我们将结合先进的采样(解码)策略,如基于树搜索的方法(Yao等人,2023),在分布外问题提示上探索我们的强化学习流程。此外,确定策略模型探索效率的高效推理技术(Kwon等人,2023;Leviathan等人,2023;Xia等人,2023,2024)也起着至关重要的作用。
算法 算法将数据和奖励信号处理为梯度系数,以更新模型参数。基于公式5,在一定程度上,所有方法现在都完全信任奖励函数的信号来增加或减少某个标记的条件概率。然而,无法确保奖励信号始终可靠,尤其是在极其复杂的任务中。例如,即使是经过精心标注的PRM800K数据集(Lightman等人,2023),仍包含约20%的错误标注。为此,我们将探索对噪声奖励信号具有鲁棒性的强化学习算法。我们相信,这种从弱到强(Weak-to-Strong)(Burns等人,2023)的对齐方法将为学习算法带来根本性的变革。
奖励函数 奖励函数是训练信号的来源。在强化学习中,奖励函数通常是神经奖励模型。我们认为,奖励模型存在三个重要的研究方向:1)如何增强奖励模型的泛化能力。奖励模型必须有效地泛化,以处理分布外问题和高级解码输出;否则,强化学习可能仅稳定大语言模型(LLMs)的分布,而非提升其基础能力;2)如何反映奖励模型的不确定性。这种不确定性可能成为弱奖励模型和从弱到强学习算法之间的桥梁;3)如何高效地构建高质量的过程奖励模型,该模型能为推理过程提供细粒度的训练信号(Lightman等人,2023;Wang等人,2023b)。
6. 结论、局限性及未来工作
我们提出了DeepSeekMath模型,该模型在竞赛级别的MATH基准测试上表现优于所有开源模型,且性能接近闭源模型。DeepSeekMath以DeepSeek-Coder-v1.5 7B为基础进行初始化,并经过5000亿个token的持续训练,其中训练数据的重要组成部分是从Common Crawl中获取的1200亿个数学token。我们广泛的消融研究表明,网页为获取高质量的数学数据提供了巨大潜力,而arXiv可能并不像我们预期的那样有益。我们引入了组相对策略优化(Group Relative Policy Optimization,GRPO)算法,这是近端策略优化(Proximal Policy Optimization,PPO)算法的一个变体,该算法可以在减少内存消耗的情况下显著提升数学推理能力。实验结果表明,即使DeepSeekMath-Instruct 7B在基准测试上已经取得了高分,GRPO算法仍然有效。此外,我们还提供了一个统一的范式来理解一系列方法,并总结了实现更有效的强化学习的几个潜在方向。
尽管DeepSeekMath在定量推理基准测试上取得了令人印象深刻的成绩,但其在几何和定理证明方面的能力相对闭源模型而言较弱。例如,在我们的初步测试中,该模型无法处理与三角形和椭圆相关的问题,这可能表明在预训练和微调过程中存在数据选择偏差。此外,受限于模型规模,DeepSeekMath在少样本学习能力方面不如GPT-4。GPT-4能够通过少样本输入提升性能,而DeepSeekMath在零样本和少样本评估中的表现相似。未来,我们将进一步改进工程化的数据选择流程,以构建更高质量的预训练语料库。此外,我们还将探索实现大语言模型(LLMs)更有效的强化学习的潜在方向(见5.2.3节)。
附录
A. 附录
A.1. 强化学习分析
我们提供了各种方法(包括监督微调(SFT)、拒绝采样微调(RFT)、在线拒绝采样微调(Online RFT)、直接偏好优化(DPO)、近端策略优化(PPO)和组相对策略优化(GRPO))中数据源和梯度系数(算法和奖励函数)的详细推导过程。
A.1.1. 监督微调
监督微调的目标是最大化以下目标函数:
J S F T ( θ ) = E q , o ∼ P s f t ( Q , O ) ( 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ log π θ ( o t ∣ q , o < t ) ) \mathcal{J}{S F T}(\theta)=\mathbb{E}\leftq, o \\sim P_{s f t}(Q, O)\\right\left(\frac{1}{|o|} \sum{t=1}^{|o|} \log \pi_{\theta}\left(o_{t} \mid q, o_{<t}\right)\right) JSFT(θ)=Eq,o∼Psft(Q,O) ∣o∣1t=1∑∣o∣logπθ(ot∣q,o<t)
J S F T ( θ ) \mathcal{J}_{S F T}(\theta) JSFT(θ)的梯度为:
∇ θ J S F T = E q , o ∼ P s f t ( Q , O ) ( 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ ∇ θ log π θ ( o t ∣ q , o < t ) ) \nabla_{\theta} \mathcal{J}{S F T}=\mathbb{E}\leftq, o \\sim P_{s f t}(Q, O)\\right\left(\frac{1}{|o|} \sum{t=1}^{|o|} \nabla_{\theta} \log \pi_{\theta}\left(o_{t} \mid q, o_{<t}\right)\right) ∇θJSFT=Eq,o∼Psft(Q,O) ∣o∣1t=1∑∣o∣∇θlogπθ(ot∣q,o<t)
数据源 :用于SFT的数据集。
奖励函数 :可视为人工选择。
梯度系数:始终设为1。
A.1.2. 拒绝采样微调
拒绝采样微调首先从监督微调后的大语言模型(LLMs)中为每个问题采样多个输出,然后在采样输出上使用正确答案对LLMs进行训练。形式上,RFT的目标是最大化以下目标函数:
J R F T ( θ ) = E q ∼ P s f t ( Q ) , o ∼ π s f t ( O ∣ q ) ( 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ I ( o ) log π θ ( o t ∣ q , o < t ) ) \mathcal{J}{R F T}(\theta)=\mathbb{E}\leftq \\sim P_{s f t}(Q), o \\sim \\pi_{s f t}(O \\mid q)\\right\left(\frac{1}{|o|} \sum{t=1}^{|o|} \mathbb{I}(o) \log \pi_{\theta}\left(o_{t} \mid q, o_{<t}\right)\right) JRFT(θ)=Eq∼Psft(Q),o∼πsft(O∣q) ∣o∣1t=1∑∣o∣I(o)logπθ(ot∣q,o<t)
J R F T ( θ ) \mathcal{J}_{R F T}(\theta) JRFT(θ)的梯度为:
∇ θ J R F T ( θ ) = E q ∼ P s f t ( Q ) , o ∼ π s f t ( O ∣ q ) ( 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ I ( o ) ∇ θ log π θ ( o t ∣ q , o < t ) ) \nabla_{\theta} \mathcal{J}{R F T}(\theta)=\mathbb{E}\leftq \\sim P_{s f t}(Q), o \\sim \\pi_{s f t}(O \\mid q)\\right\left(\frac{1}{|o|} \sum{t=1}^{|o|} \mathbb{I}(o) \nabla_{\theta} \log \pi_{\theta}\left(o_{t} \mid q, o_{<t}\right)\right) ∇θJRFT(θ)=Eq∼Psft(Q),o∼πsft(O∣q) ∣o∣1t=1∑∣o∣I(o)∇θlogπθ(ot∣q,o<t)
数据源 :SFT数据集中的问题,输出从SFT模型采样。
奖励函数 :规则(答案是否正确)。
梯度系数:
G C R F T ( q , o , t ) = I ( o ) = { 1 答案 o 正确 0 答案 o 不正确 G C_{R F T}(q, o, t)=\mathbb{I}(o)=\left\{\begin{array}{ll} 1 & \text { 答案 } \mathrm{o} \text { 正确 } \\ 0 & \text { 答案 } \mathrm{o} \text { 不正确 } \end{array}\right. GCRFT(q,o,t)=I(o)={10 答案 o 正确 答案 o 不正确
A.1.3. 在线拒绝采样微调
RFT与在线拒绝采样微调(Online RFT)的唯一区别在于,Online RFT的输出是从实时策略模型 π θ \pi_{\theta} πθ中采样,而不是从SFT模型 π θ s f t \pi_{\theta_{s f t}} πθsft中采样。因此,Online RFT的梯度为:
∇ θ J OnRFT ( θ ) = E q ∼ P s f t ( Q ) , o ∼ π θ ( O ∣ q ) ( 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ I ( o ) ∇ θ log π θ ( o t ∣ q , o < t ) ) \nabla_{\theta} \mathcal{J}{\text {OnRFT }}(\theta)=\mathbb{E}\leftq \\sim P_{s f t}(Q), o \\sim \\pi_{\\theta}(O \\mid q)\\right\left(\frac{1}{|o|} \sum{t=1}^{|o|} \mathbb{I}(o) \nabla_{\theta} \log \pi_{\theta}\left(o_{t} \mid q, o_{<t}\right)\right) ∇θJOnRFT (θ)=Eq∼Psft(Q),o∼πθ(O∣q) ∣o∣1t=1∑∣o∣I(o)∇θlogπθ(ot∣q,o<t)
A.1.4. 直接偏好优化(DPO)
DPO的目标函数为:
J D P O ( θ ) = E q ∼ P s f t ( Q ) , o + , o − ∼ π s f t ( O ∣ q ) log σ ( β 1 ∣ o + ∣ ∑ t = 1 ∣ o + ∣ log π θ ( o t + ∣ q , o < t + ) π r e f ( o t + ∣ q , o < t + ) − β 1 ∣ o − ∣ ∑ t = 1 ∣ o − ∣ log π θ ( o < t − ∣ q , o < t − ) π r e f ( o < t − ∣ q , o < t − ) ) \mathcal{J}{D P O}(\theta)=\mathbb{E}\leftq \\sim P_{s f t}(Q), o\^{+}, o\^{-} \\sim \\pi_{s f t}(O \\mid q)\\right \log \sigma\left(\beta \frac{1}{\left|o^{+}\right|} \sum{t=1}^{\left|o^{+}\right|} \log \frac{\pi_{\theta}\left(o_{t}^{+} \mid q, o_{<t}^{+}\right)}{\pi_{\mathrm{ref}}\left(o_{t}^{+} \mid q, o_{<t}^{+}\right)}-\beta \frac{1}{\left|o^{-}\right|} \sum_{t=1}^{\left|o^{-}\right|} \log \frac{\pi_{\theta}\left(o_{<t}^{-} \mid q, o_{<t}^{-}\right)}{\pi_{\mathrm{ref}}\left(o_{<t}^{-} \mid q, o_{<t}^{-}\right)}\right) JDPO(θ)=Eq∼Psft(Q),o+,o−∼πsft(O∣q)logσ β∣o+∣1t=1∑∣o+∣logπref(ot+∣q,o<t+)πθ(ot+∣q,o<t+)−β∣o−∣1t=1∑∣o−∣logπref(o<t−∣q,o<t−)πθ(o<t−∣q,o<t−)
J D P O ( θ ) \mathcal{J}_{D P O}(\theta) JDPO(θ)的梯度为:
∇ θ J D P O ( θ ) = E q ∼ P s f t ( Q ) , o + , o − ∼ π s f t ( O ∣ q ) ( 1 ∣ o + ∣ ∑ t = 1 ∣ o + ∣ G C D P O ( q , o , t ) ∇ θ log π θ ( o t + ∣ q , o < t + ) − 1 ∣ o − ∣ ∑ t = 1 ∣ o − ∣ G C D P O ( q , o , t ) ∇ θ log π θ ( o t − ∣ q , o < t − ) ) \begin{array}{r} \nabla_{\theta} \mathcal{J}{D P O}(\theta)=\mathbb{E}\leftq \\sim P_{s f t}(Q), o\^{+}, o\^{-} \\sim \\pi_{s f t}(O \\mid q)\\right\left(\frac{1}{\left|o^{+}\right|} \sum{t=1}^{\left|o^{+}\right|} G C_{D P O}(q, o, t) \nabla_{\theta} \log \pi_{\theta}\left(o_{t}^{+} \mid q, o_{<t}^{+}\right)\right. \\ \left.-\frac{1}{\left|o^{-}\right|} \sum_{t=1}^{\left|o^{-}\right|} G C_{D P O}(q, o, t) \nabla_{\theta} \log \pi_{\theta}\left(o_{t}^{-} \mid q, o_{<t}^{-}\right)\right) \end{array} ∇θJDPO(θ)=Eq∼Psft(Q),o+,o−∼πsft(O∣q)(∣o+∣1∑t=1∣o+∣GCDPO(q,o,t)∇θlogπθ(ot+∣q,o<t+)−∣o−∣1∑t=1∣o−∣GCDPO(q,o,t)∇θlogπθ(ot−∣q,o<t−))
数据源 :SFT数据集中的问题,输出从SFT模型采样。
奖励函数 :通用领域中的人工偏好(在数学任务中可以是"规则")。
梯度系数:
G C D P O ( q , o , t ) = σ ( β log π θ ( o t − ∣ q , o < t − ) π r e f ( o t − ∣ q , o < t − ) − β log π θ ( o t + ∣ q , o < t + ) π r e f ( o t + ∣ q , o < t + ) ) G C_{D P O}(q, o, t)=\sigma\left(\beta \log \frac{\pi_{\theta}\left(o_{t}^{-} \mid q, o_{<t}^{-}\right)}{\pi_{\mathrm{ref}}\left(o_{t}^{-} \mid q, o_{<t}^{-}\right)}-\beta \log \frac{\pi_{\theta}\left(o_{t}^{+} \mid q, o_{<t}^{+}\right)}{\pi_{\mathrm{ref}}\left(o_{t}^{+} \mid q, o_{<t}^{+}\right)}\right) GCDPO(q,o,t)=σ(βlogπref(ot−∣q,o<t−)πθ(ot−∣q,o<t−)−βlogπref(ot+∣q,o<t+)πθ(ot+∣q,o<t+))
A.1.5. 近端策略优化(PPO)
PPO的目标函数为:
J P P O ( θ ) = E q ∼ P s f t ( Q ) , o ∼ π θ o l d ( O ∣ q ) 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ min π θ ( o t ∣ q , o \< t ) π θ o l d ( o t ∣ q , o \< t ) A t , clip ( π θ ( o t ∣ q , o \< t ) π θ o l d ( o t ∣ q , o \< t ) , 1 − ε , 1 + ε ) A t \mathcal{J}{P P O}(\theta)=\mathbb{E}\leftq \\sim P_{s f t}(Q), o \\sim \\pi_{\\theta_{o l d}}(O \\mid q)\\right \frac{1}{|o|} \sum{t=1}^{|o|} \min \left\\frac{\\pi_{\\theta}\\left(o_{t} \\mid q, o_{\
为简化分析,假设模型在每次探索阶段后仅进行一次更新,从而确保 π θ old = π θ \pi_{\theta_{\text {old }}}=\pi_{\theta} πθold =πθ。在这种情况下,可以移除min和clip操作:
J P P O ( θ ) = E q ∼ P s f t ( Q ) , o ∼ π θ o l d ( O ∣ q ) 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) A t \mathcal{J}{P P O}(\theta)=\mathbb{E}\leftq \\sim P_{s f t}(Q), o \\sim \\pi_{\\theta_{o l d}}(O \\mid q)\\right \frac{1}{|o|} \sum{t=1}^{|o|} \frac{\pi_{\theta}\left(o_{t} \mid q, o_{<t}\right)}{\pi_{\theta_{o l d}}\left(o_{t} \mid q, o_{<t}\right)} A_{t} JPPO(θ)=Eq∼Psft(Q),o∼πθold(O∣q)∣o∣1t=1∑∣o∣πθold(ot∣q,o<t)πθ(ot∣q,o<t)At
J P P O ( θ ) \mathcal{J}_{P P O}(\theta) JPPO(θ)的梯度为:
∇ θ J P P O ( θ ) = E q ∼ P s f t ( Q ) , o ∼ π θ o l d ( O ∣ q ) 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ A t ∇ θ log π θ ( o t ∣ q , o < t ) \nabla_{\theta} \mathcal{J}{P P O}(\theta)=\mathbb{E}\leftq \\sim P_{s f t}(Q), o \\sim \\pi_{\\theta_{o l d}}(O \\mid q)\\right \frac{1}{|o|} \sum{t=1}^{|o|} A_{t} \nabla_{\theta} \log \pi_{\theta}\left(o_{t} \mid q, o_{<t}\right) ∇θJPPO(θ)=Eq∼Psft(Q),o∼πθold(O∣q)∣o∣1t=1∑∣o∣At∇θlogπθ(ot∣q,o<t)
数据源 :SFT数据集中的问题,输出从策略模型采样。
奖励函数 :奖励模型。
梯度系数:
G C P P O ( q , o , t , π θ r m ) = A t G C_{P P O}\left(q, o, t, \pi_{\theta_{r m}}\right)=A_{t} GCPPO(q,o,t,πθrm)=At
其中 A t A_{t} At是优势函数,通过基于奖励 { r ≥ t } \left\{r_{\geq t}\right\} {r≥t}和学习到的价值函数 V ψ V_{\psi} Vψ应用广义优势估计(GAE)(Schulman等人,2015)来计算。
A.1.6. 组相对策略优化(GRPO)
GRPO的目标函数为(为简化分析,假设 π θ old = π θ \pi_{\theta_{\text {old }}}=\pi_{\theta} πθold =πθ):
J G R P O ( θ ) = E q ∼ P s f t ( Q ) , { o i } i = 1 G ∼ π θ old ( O ∣ q ) 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ π θ ( o i , t ∣ q , o i , \< t ) π θ old ( o i , t ∣ q , o i , \< t ) A \^ i , t − β ( π r e f ( o i , t ∣ q , o i , \< t ) π θ ( o i , t ∣ q , o i , \< t ) − log π r e f ( o i , t ∣ q , o i , \< t ) π θ ( o i , t ∣ q , o i , \< t ) − 1 ) . \begin{aligned} \mathcal{J}{G R P O}(\theta) & =\mathbb{E}\leftq \\sim P_{s f t}(Q),\\left\\{o_{i}\\right\\}_{i=1}\^{G} \\sim \\pi_{\\theta_{\\text {old }}}(O \\mid q)\\right \\ & \frac{1}{G} \sum{i=1}^{G} \frac{1}{\left|o_{i}\right|} \sum_{t=1}^{\left|o_{i}\right|}\left\\frac{\\pi_{\\theta}\\left(o_{i, t} \\mid q, o_{i,\