本项目代码在个人github链接:https://github.com/KLWU07/Machine-learning-Project-practice/tree/main/1-Wine cluster analysis
如果对于聚类算法理论不理解可参考这篇之前文章机器学习中无监督学习方法的聚类:划分式聚类、层次聚类、密度聚类;如果降维方法主成分分析PCA降维理解可参考这篇文章机器学习数据降维方法。数据wine.data可在个人github链接下载。
一、聚类分析功能说明
1. 数据准备与预处理
从wine.data文件加载葡萄酒数据集,包含 178 个样本和 14 个特征;将类别标签从 1/2/3 重新编码为 0/1/2;提取特征数据(X)和类别标签(y)。
2. 数据降维和标准化
使用 PCA(主成分分析)将原始 13 个特征降至 3 个维度;对数据进行标准化处理,确保各特征具有相同尺度。
3. 聚类分析
使用 K-Means 算法进行聚类,指定聚类数为 3;计算每个样本到三个聚类中心的距离并打印;输出聚类结果的标签和聚类中心坐标。
4. 模型评估
计算并打印六项评估指标:
(1)同质性得分(Homogeneity)
衡量聚类结果中每个簇是否仅包含同一类别的样本(即聚类结果的 "纯度")。若所有簇中的样本都属于同一真实类别,则同质性为 1;若簇中样本混杂不同类别,则得分越低,随机聚类时接近 0。
(2)完整性得分(Completeness)
衡量同一真实类别中的样本是否都被分配到同一个簇中(即真实类别的 "完整性")。若同一真实类别的所有样本都被聚到同一簇,则完整性为 1;若真实类别样本被分到多个簇,则得分越低,随机聚类时接近 0。
(3)V-measure 得分
同质性(Homogeneity)和完整性(Completeness)的调和平均,用于综合评估聚类结果的准确性。
(4)调整兰德指数(ARI)
衡量聚类结果与真实类别之间的一致性,考虑了随机聚类的影响("调整" 即扣除随机因素)。
(5)调整互信息(AMI)
衡量聚类标签与真实类别之间的互信息(MI),同样扣除了随机因素的影响。互信息(MI)表示两个变量的共享信息量,调整互信息(AMI)通过标准化使结果更易解释。
(6)轮廓系数(Silhouette Score)
衡量单个样本与其所在簇的紧密程度(内聚性)和与其他簇的分离程度(分离性),适用于评估聚类数 k 的合理性。
5. 三维可视化
创建 3D 图形展示 PCA 降维后的聚类结果;使用不同颜色区分三个聚类;用红色星形标记聚类中心;添加坐标轴标签、标题和图例;优化图形布局和视角,提升可视化效果。
二、代码演示
python
# 导入必要的库(保持不变)
from pandas import read_csv
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
from sklearn import metrics
# 数据加载和预处理(保持不变)
filename = 'wine.data'
names = ['class', 'Alcohol', 'MalicAcid', 'Ash', 'AlclinityOfAsh', 'Magnesium', 'TotalPhenols', 'Flavanoids',
'NonflayanoidPhenols', 'Proanthocyanins', 'ColorIntensiyt', 'Hue', 'OD280/OD315', 'Proline']
dataset = read_csv(filename, names=names)
dataset['class'] = dataset['class'].replace(to_replace=[1, 2, 3], value=[0, 1, 2])
array = dataset.values
X = array[:, 1:13]
y = array[:, 0]
# 数据降维和聚类(保持不变)
pca = PCA(n_components=3)
X_scale = StandardScaler().fit_transform(X)
X_reduce = pca.fit_transform(X_scale)
model = KMeans(n_clusters=3, n_init=10)
model.fit(X_reduce)
labels = model.labels_
centers = model.cluster_centers_
print(model.transform(X_reduce))
# 输出模型评估指标(保持不变)
print('%.3f %.3f %.3f %.3f %.3f %.3f' % (
metrics.homogeneity_score(y, labels),
metrics.completeness_score(y, labels),
metrics.v_measure_score(y, labels),
metrics.adjusted_rand_score(y, labels),
metrics.adjusted_mutual_info_score(y, labels),
metrics.silhouette_score(X_reduce, labels)
))
# 绘制模型的分布图(修改部分)
fig = plt.figure(figsize=(10, 6)) # 添加图形尺寸
ax = fig.add_subplot(111, projection='3d', elev=30, azim=120) # 修改3D轴创建方式,调整视角
ax.scatter(X_reduce[:, 0], X_reduce[:, 1], X_reduce[:, 2], c=labels, cmap='tab10', s=60, alpha=0.8) # 优化散点图配置
ax.scatter(centers[:, 0], centers[:, 1], centers[:, 2], marker='*', color='red', s=300, label='Cluster Centers') # 添加图例标签
# 添加坐标轴标签和标题
ax.set_xlabel('PC1')
ax.set_ylabel('PC2')
ax.set_zlabel('PC3')
ax.set_title('KMeans Clustering Result (3D PCA)')
ax.legend() # 显示图例
plt.tight_layout() # 优化布局
plt.show()
python
0.740 0.736 0.738 0.740 0.735 0.413 #评估指标六个值
三、K-Means 算法13个特征无降维聚类3类
python
# 导入必要的库(保持不变)
from pandas import read_csv
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
# 数据加载和预处理(保持不变)
filename = 'wine.data'
names = ['class', 'Alcohol', 'MalicAcid', 'Ash', 'AlclinityOfAsh', 'Magnesium', 'TotalPhenols', 'Flavanoids',
'NonflayanoidPhenols', 'Proanthocyanins', 'ColorIntensiyt', 'Hue', 'OD280/OD315', 'Proline']
dataset = read_csv(filename, names=names)
dataset['class'] = dataset['class'].replace(to_replace=[1, 2, 3], value=[0, 1, 2])
array = dataset.values
X = array[:, 1:14] # 选择所有13个特征
y = array[:, 0]
# 数据标准化(保持不变)
X_scale = StandardScaler().fit_transform(X)
# 聚类(使用全部13个特征)
model = KMeans(n_clusters=3, n_init=10)
model.fit(X_scale)
labels = model.labels_
centers = model.cluster_centers_
# 输出模型评估指标(保持不变)
print('%.3f %.3f %.3f %.3f %.3f %.3f' % (
metrics.homogeneity_score(y, labels),
metrics.completeness_score(y, labels),
metrics.v_measure_score(y, labels),
metrics.adjusted_rand_score(y, labels),
metrics.adjusted_mutual_info_score(y, labels),
metrics.silhouette_score(X_scale, labels)
))
python
0.879 0.873 0.876 0.897 0.875 0.285 # 评价指标三、K-Means 算法13个特征降维维聚类3类
python
# 导入必要的库(保持不变)
from pandas import read_csv
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from matplotlib import pyplot as plt
import numpy as np
from sklearn import metrics
# 数据加载和预处理(保持不变)
filename = 'wine.data'
names = ['class', 'Alcohol', 'MalicAcid', 'Ash', 'AlclinityOfAsh', 'Magnesium', 'TotalPhenols', 'Flavanoids',
'NonflayanoidPhenols', 'Proanthocyanins', 'ColorIntensiyt', 'Hue', 'OD280/OD315', 'Proline']
dataset = read_csv(filename, names=names)
dataset['class'] = dataset['class'].replace(to_replace=[1, 2, 3], value=[0, 1, 2])
array = dataset.values
X = array[:, 1:13]
y = array[:, 0]
# 数据降维和聚类(修改降维部分)
pca = PCA(n_components=2) # 修改为2维降维
X_scale = StandardScaler().fit_transform(X)
X_reduce = pca.fit_transform(X_scale)
model = KMeans(n_clusters=3, n_init=10)
model.fit(X_reduce)
labels = model.labels_
centers = model.cluster_centers_
print(model.transform(X_reduce))
# 输出模型评估指标(保持不变)
print('%.3f %.3f %.3f %.3f %.3f %.3f' % (
metrics.homogeneity_score(y, labels),
metrics.completeness_score(y, labels),
metrics.v_measure_score(y, labels),
metrics.adjusted_rand_score(y, labels),
metrics.adjusted_mutual_info_score(y, labels),
metrics.silhouette_score(X_reduce, labels)
))
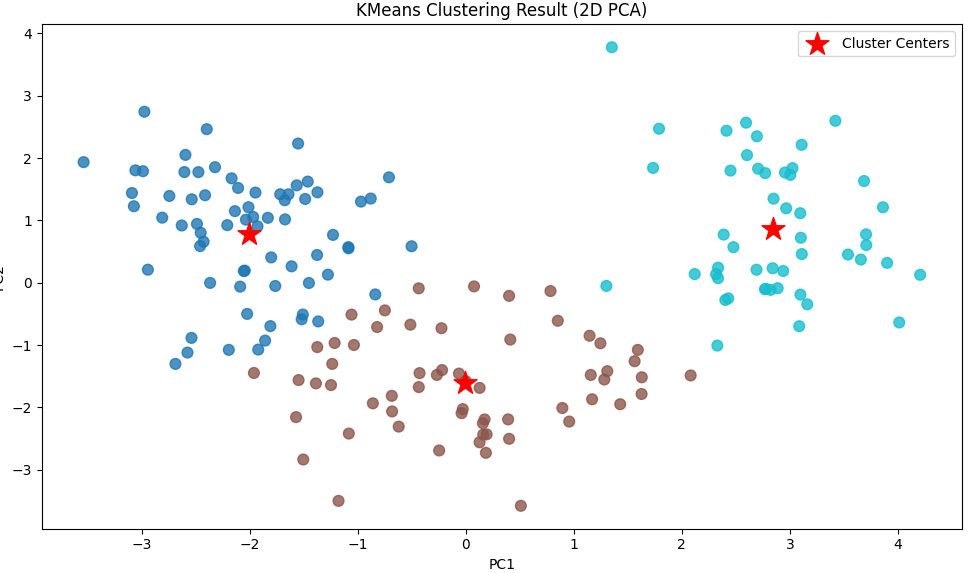
# 绘制模型的分布图(修改为2D散点图)
plt.figure(figsize=(10, 6)) # 添加图形尺寸
plt.scatter(X_reduce[:, 0], X_reduce[:, 1], c=labels, cmap='tab10', s=60, alpha=0.8) # 优化散点图配置
plt.scatter(centers[:, 0], centers[:, 1], marker='*', color='red', s=300, label='Cluster Centers') # 添加图例标签
# 添加坐标轴标签和标题
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.title('KMeans Clustering Result (2D PCA)')
plt.legend() # 显示图例
plt.tight_layout() # 优化布局
plt.show()
python
0.740 0.738 0.739 0.726 0.737 0.521 # 六个评价指标