点一下关注吧!!!非常感谢!!持续更新!!!
Java篇:
- MyBatis 更新完毕
- 目前开始更新 Spring,一起深入浅出!
大数据篇 300+:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(已更完)
- Prometheus(已更完)
- Grafana(已更完)
- 离线数仓(已更完)
- 实时数仓(正在更新...)
- Spark MLib (正在更新...)
背景情况
在以往的开发任务中,我们发现随着项目规模的扩大,AI 模型容易出现"前后不一致"的问题:它在处理后续逻辑时,常常遗忘前面的上下文,从而引发新的 Bug。
本质上,这是因为模型的上下文窗口存在限制。早期 GPT-4 仅支持 4K 上下文,后来 GPT-4 Turbo 提升到了 128K,而如今部分前沿模型已支持高达 1M 的上下文长度。
当前,行业内的技术演进主要集中在两个方向:一是不断扩展上下文长度,二是持续增加模型参数量。但无论上下文有多大,总会有装不下的内容;即便模型参数再庞大,也依然可能生成不准确、不连贯的结果。
因此,为了解决这一类"遗忘"问题,社区逐步发展出一系列策略:从扩大上下文窗口,到引入 RAG(Retrieval-Augmented Generation)与摘要机制;从 Step-by-Step 的逐步推理,到 Chain-of-Thought(思维链)等更复杂的推理结构。这些方法的共同目标,都是延长模型的思考过程、缓存关键信息,以对抗其作为概率模型带来的推理局限。
恰巧在上周的分享会上,有人提到在 AI 协助开发的过程中,经常会遇到"遗忘"或"执行偏差"的问题。我当时也简单分享了几个应对思路。借这个机会,顺便整理一下目前社区中较为标准的解决方案。
Sequential Thinking
项目地址
https://github.com/modelcontextprotocol/servers/tree/main/src/sequentialthinking
能够将复杂的问题拆分成一个个可管理的小步骤,让 AI 可以逐步进行分析和处理。例如,在处理一个复杂的编程任务时,它会把任务分解为多个子任务,如先确定算法框架,再处理数据输入输出,最后进行代码优化等。
配置方式
MCP的配置方式老生常谈了,全部略过。
shell
npx -y @modelcontextprotocol/server-sequential-thinkingJSON内容如下:
json
{
"mcpServers": {
"SequentialThinking": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-sequential-thinking"]
}
}
}配置结果如下:
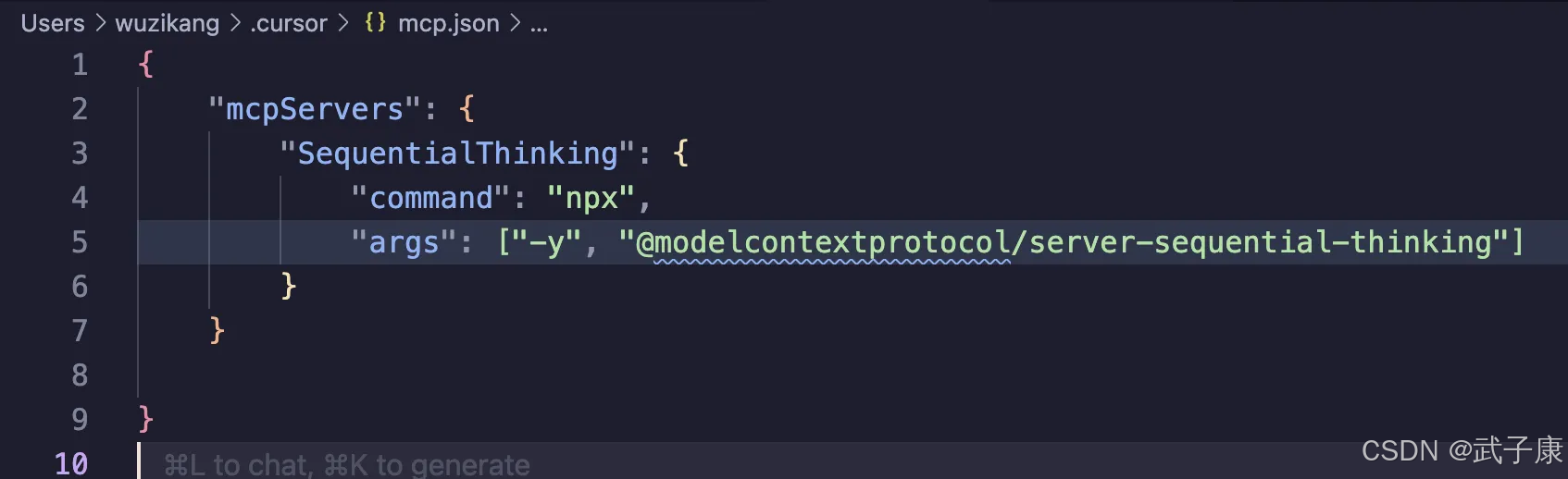
确保Cursor中的状态是正常的:
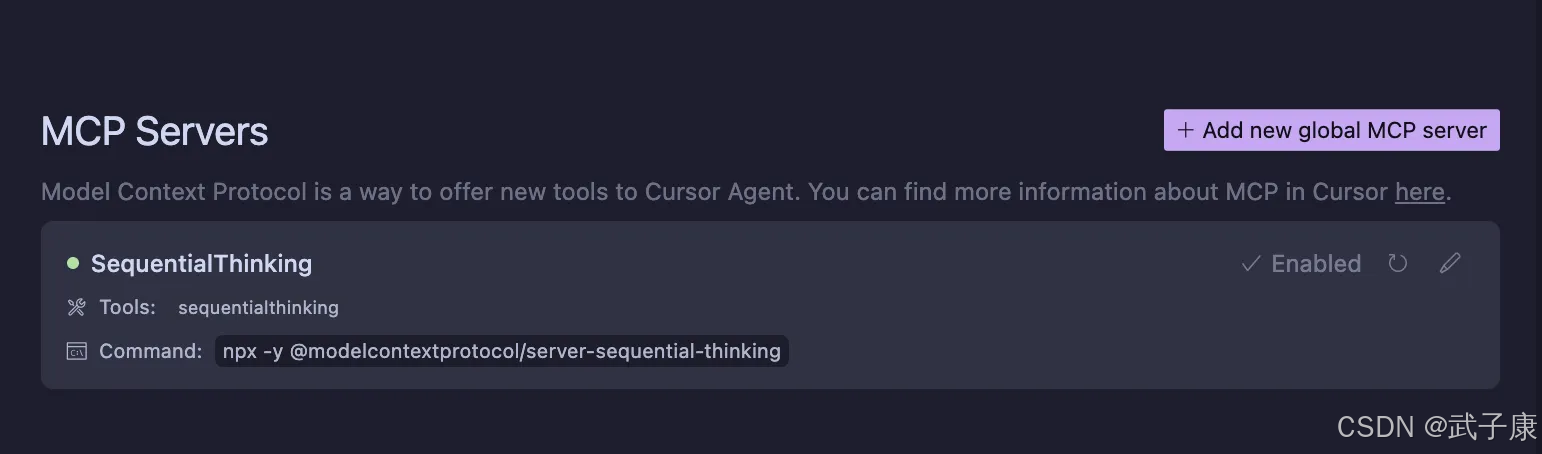
使用方式
对于一些复杂问题,可以使用Sequential Thinking服务,将复杂问题分解为小的问题,逐个解决。同时每调用一次,都可以从thought中获取到LLM当前的思考过程以及采取的方法,有时还会提供多种方案,我们可以通过再次提问,实现对于方案的选取以及之前思考过程的调整。
shell
请你使用思考能力,完成XXXXXXX的任务。这样会调用 Sequential Thinking,对任务进行详细的拆解,避免出现比如:"实现一个购物系统",这样宽泛的需求而大模型无法理解的问题。
Server Memory
项目地址
https://github.com/modelcontextprotocol/servers/tree/main/src/memory
能够让 AI 记住之前的信息和交互内容,在处理后续任务时可以调用这些记忆,从而更连贯地进行分析和处理。例如,在进行多轮对话的编程对话时,AI 可以记住之前用户提出的代码问题和已解决的部分,在后续交流中基于这些记忆给出更合适的建议和指导。
配置方式
MCP配置略过
shell
npx -y @modelcontextprotocol/server-memory一般都是将思考和记忆放到一起使用,对应的JSON如下:
shell
{
"mcpServers": {
"SequentialThinking": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-sequential-thinking"]
},
"ServerMemory": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-memory"]
}
}
}配置完的结果如下:
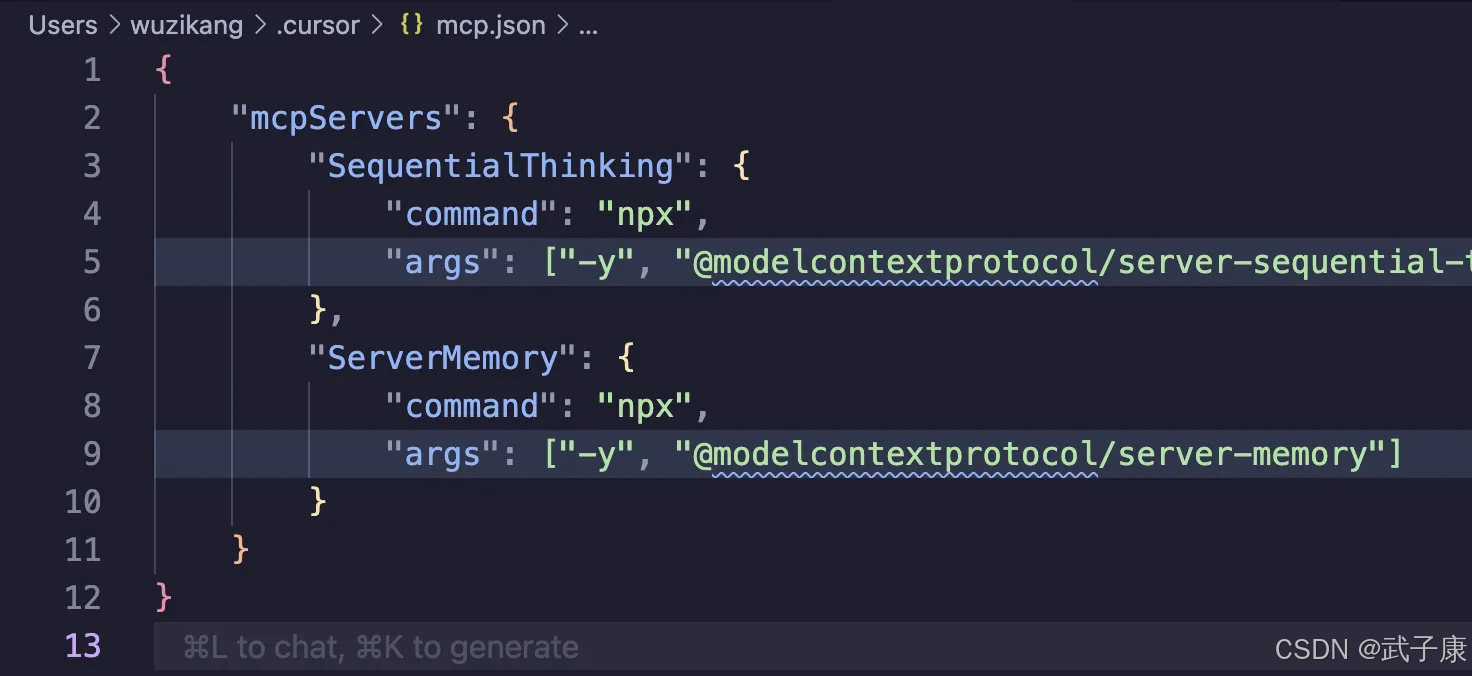
使用方式
对于一些需要多轮交互且依赖之前信息的复杂问题,可以使用 Server Memory 服务。比如在进行项目需求分析时,用户不断补充和修改需求,AI 能够记住之前的需求内容,在后续分析中综合考虑,给出更全面准确的分析结果。
随便测试一个结果:

可以看到思考完成后,会进行缓存:
