作者:流利说 Ibson(大数据负责人)/ Bruce(数据工程师)
背景介绍
行业
- 流利说是领先的科技驱动的教育公司,公司自主研发了领先的英语口语评测、写作打分引擎和深度自适应学习系统,致力于为用户提供一整套系统性的英语学习解决方案,从听、说、读、写多个维度提升用户的英语水平。
业务特征
- AI 打分:利用大数据和人工智能算法对用户英语口语评测、写作打分。
- 个性化推荐:根据用户学习目标及评级,自动推荐专项和强化课程内容。
- 数据驱动:通过分析用户画像和学习效果,优化推荐策略,提升用户满意度。
- 数据运营:基于大数据及用户特征,提高运行效率,提升用户黏度及用户满意度。
原有架构痛点
- 弹性资源管理问题:资源配置不够灵活,定时定量弹出,任务提交高峰会出现任务等待,低峰时段资源利用率低。
- 费用问题:Master 和 Core 节点为常驻节点,空闲时仍会产生费用,导致成本增加。
- 性能问题:当前架构缺乏类似于 Fusion 的加速技术,部分任务执行速度较慢,尤其是在处理大规模数据时。
- 运维问题:多组件架构使得故障排查和恢复变得复杂,增加了运维的工作负担。
- 监控问题:仅包含集群层面及组件的监控,缺乏对 Spark 任务状态及资源监控。
- 扩容问题:临时需求需手动扩容,扩容响应较慢。
为了应对新的业务挑战,流利说选择与阿里云合作,利用其 EMR Serverless Spark ,构建了符合业务场景和分析师习惯的工程解决方案。
为什么选择阿里云 Serverless Spark
EMR Serverless Spark 是一款面向 Data+AI 的高性能 Lakehouse 产品。它为企业提供了一站式的数据平台服务,包括任务开发、调试、调度和运维等,极大地简化了数据处理和模型训练的全流程。同时,它100%兼容开源 Spark 生态,能够无缝集成到客户现有的数据平台。使用 EMR Serverless Spark,企业可以更专注于数据处理分析和模型训练调优,提高工作效率。
- 元数据管理:支持对接外部 Hive MetaStore 元数据服务。
- 调度引擎支持:提供了市场主流调度引擎集成,例如 Airflow 和 DolphinScheduler 等。
- 完善的周边服务:提供全面的监控和告警功能,能够实时跟踪任务状态和性能,及时发现并解决问题。
- 托管弹性伸缩功能:自动调整资源,减少手动干预。
- 集群稳定性:由云服务商管理,提供高稳定性和可靠性。
- 弹性资源管理:按需进行分配资源,避免资源浪费。
- 按需计费:仅为实际使用的资源付费,降低成本。
- 快速启动:无需预配置资源,能够快速启动和运行任务。
- 自动扩展:根据工作负载自动调整资源,提升灵活性。
- 性能优化:Serverless Spark 通过技术如 Fusion 加速任务执行,提高效率,降低成本。
- Shuffle 性能:内置 Celeborn 服务,解决了大 Shuffle 场景下的磁盘限制问题。
技术方案设计
- 架构图
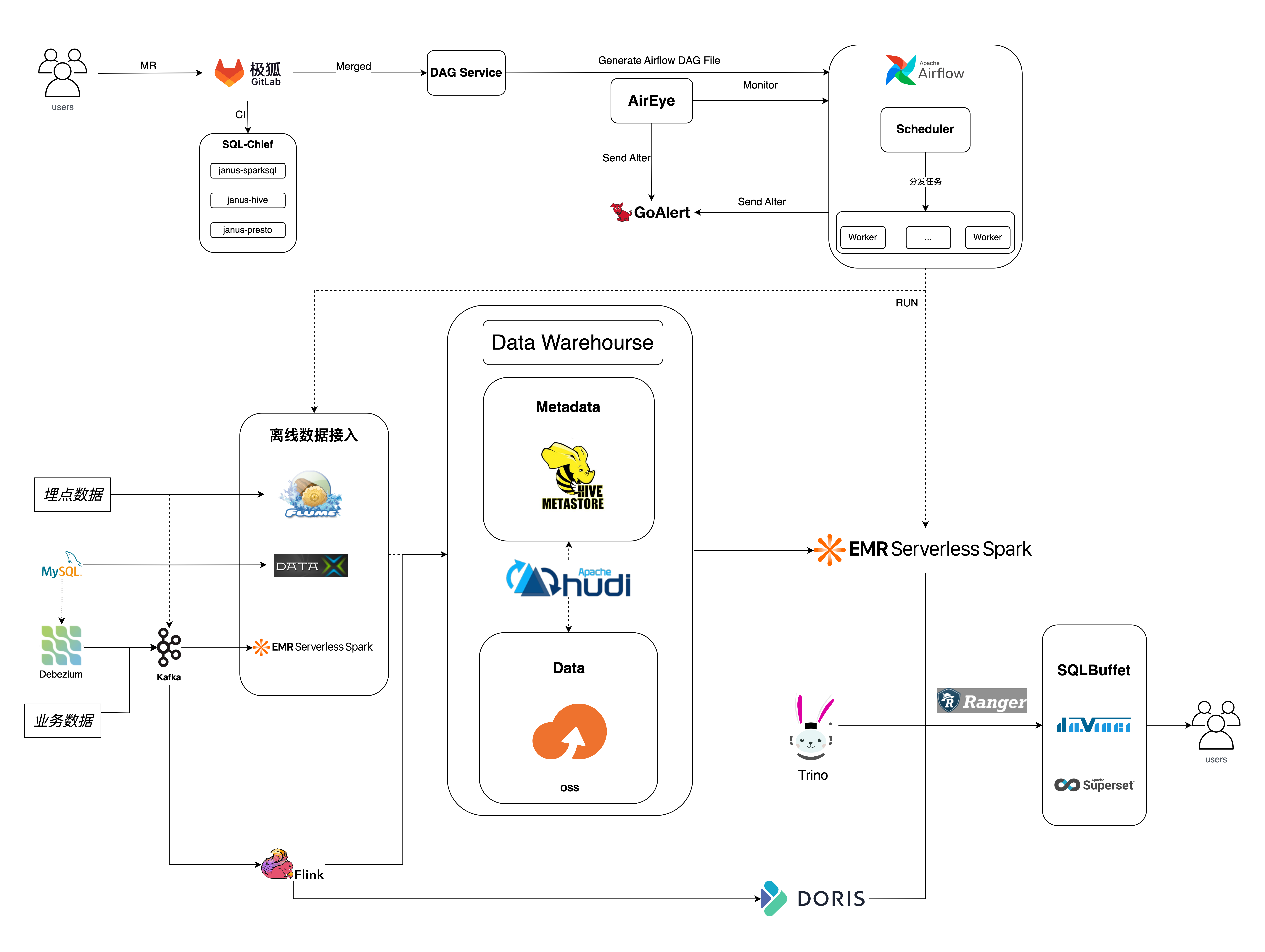
流利说数据平台涵盖从数据采集、接入、存储、计算到管理、查询与可视化的完整能力。支持多种源数据接入,提供毫秒级实时处理、分钟级近实时流处理及 T+1 离线批处理能力,能满足多样化业务需求。离线 ETL 脚本存储于 GitLab,依赖于 GitLab 的分支管理、版本管理和 review 机制,实现可追溯、可协作的脚本管理;平台以 Airflow 作为调度系统,实现高效、可靠且可视化的工作流调度;以 EMR Serverless Spark 做为核心计算引擎,结合 Fusion 引擎加速,实现高效、弹性、可靠且低成本的数据处理。以 Hive Metastore 作为元数据管理,提供统一的数据目录服务,实现元数据的集中存储与管理,支持多引擎数据共享和跨平台数据访问,简化数据治理流程。数据存储阿里云 OSS ,提供高可靠、低成本的对象存储。平台配合 AirEye 监控及 GoAlert 告警,构建完整的可观测性系统,实现对关键指标的实时监控与异常检测,提高系统可靠性和运维效率。
典型应用场景
1. CI & CD 与离线 ETL 计算
流利说数据团队自研了 DAG 自动生成服务,数据分析师和数仓工程师提交数据转换脚本到代码仓库后会,自动集成 CI 进行脚本校验,完成 review 并 Merged 后会触发自研 DAG Service 生成 Airflow 可以直接调度的 Dag 文件。Airflow 基于阿里云提供的 Operator 完成与 EMR Serverless Spark 的插件式集成,可直接提交任务到 EMR Serverless Spark,并监控任务状态。相比于之前 Airflow + EMR Gateway 的方式去提交任务,结合 EMR Serverless Spark 的高效弹性及 Fusion 引擎优化,显著提升了任务的执行效率、并发度、稳定性和可靠性。另外 EMR Serverless Spark 提供完善的监控,可显著降低运维成本。
2. 数据集成
流利说数据平台支持多种数据源数据接入,对业务数据库接入支持每天全量接入和增量接入。对业务数据库的增量接入引人数据湖 Hudi,用于支持数据更新、删除操作及 Schema 演进管理。增量接入通过 CDC 技术实时监控业务库日志,将变更事件推送到 Kafka,通过周期调度 EMR Serverless Spark 任务完成增量数据入湖。该场景同样是在 Airflow 中调度提交任务到 EMR Serverless Spark,由于增量数据可能会有周期性变化,借助于 Serverless 的弹性伸缩能力,可显著提高资源利用率,避免资源浪费,相比于之前半托管集群的定时弹性伸缩更加稳定和流畅。
3. 数据查询
流利说查询平台提供的 Trino 、Doris 和 Spark 三种查询引擎,用户可以根据使用场景来选择合适的引擎来进行数据查询、分析及ETL 脚本验证等。 查询平台 Spark 引擎切换到 EMR Serverless Spark 之前是基于 Spark 的 Thrift Server 构建的,服务稳定性差且无法进行细粒度的资源隔离,运维成本高;切换到 EMR Serverless Spark 后,可通过 Web 管理界面可以管理和运维 Thrift Server 会话,可显著降低运维成本。另外,查询平台实现用户级别的路由,可实现不同用户提交到不同 ThriftServer,避免了资源抢占。 另外,基于 EMR Serverless Spark 的弹性伸缩能力,减少了计算资源闲置,显著降低成本。
迁移后的收益
- 性能:离线任务开启 Fusion 耗时减少 40%,核心报表更早产出。
- 稳定性:任务稳定性显著提高,失败率降低 80%。
- 资源灵活:根据业务需求自动调整扩充计算资源。
- 运维成本:减少不必要的大数据组件,精简系统架构,降低平台运维成本。
- 性价比:真正的按量付费,不使用时没有资源消耗,成本降低 30%。
后续期待
基于阿里云 EMR Serverless Spark 技术栈快速构建了离线数据计算平台,EMR Serverless Spark 全托管免运维、自研 Fusion 引擎,内置高性能向量化计算和 RSS 能力,相比开源版本3倍以上的性能优势以及计算/存储分离的架构,为我们节省了总体成本。同时,EMR Serverless Spark 自身提供的丰富特性,也极大提升了我们数据团队的生产力,为数据分析业务的快速开展交付奠定了基础。未来,流利说希望与阿里云 EMR 团队针对湖仓场景输出更多行业先进解决方案。