
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
博主简介:努力学习的22级本科生一枚 🌟;探索AI算法,C++,go语言的世界;在迷茫中寻找光芒🌸
博客主页:羊小猪~~-CSDN博客
内容简介:NLP入门一。
🌸箴言🌸:去寻找理想的"天空""之城
文章目录
👀 参考资料
- 哈工大nlp课件
1、NLP概论
什么是NLP?
📑自然语言处理可以定义为研究在人与人交际中以及在人与计算机交际 中的语言问题的一门学科。自然语言处理要研制表示语言能力(linguistic competence)和语言应用(linguistic performance)的模型,建立计算框架来实现这样的语言模型,提出相应的方法来不断地完善这样的语言模型,根据这样的语言模型设计各种实用系统,并探讨这些实用系统的评测技术。
👓 有两个关键词:人与人交际、人与计算机交际,说白了就是机器理解人说话。
NLP存在的歧义问题
在自然语言处理的各个阶段广泛大量地存在着形形色色的歧义问题,这是自然语言与人工语言的根本差别之一,也是自然语言处理的难点所在。
⚜️ 如下案例:
-
分词
- 严守一把手机关了
- 严守/ 一把手/ 机关/ 了
- 严守一/ 把/ 手机/ 关/ 了
- 严守一把手机关了
-
词性标注
- 我/pro 计划/v 考/v 研/n
- 我/pro 完成/v 了/aux 计划/n
可以看出,不同分词意思是不一样的。
NLP处理内容


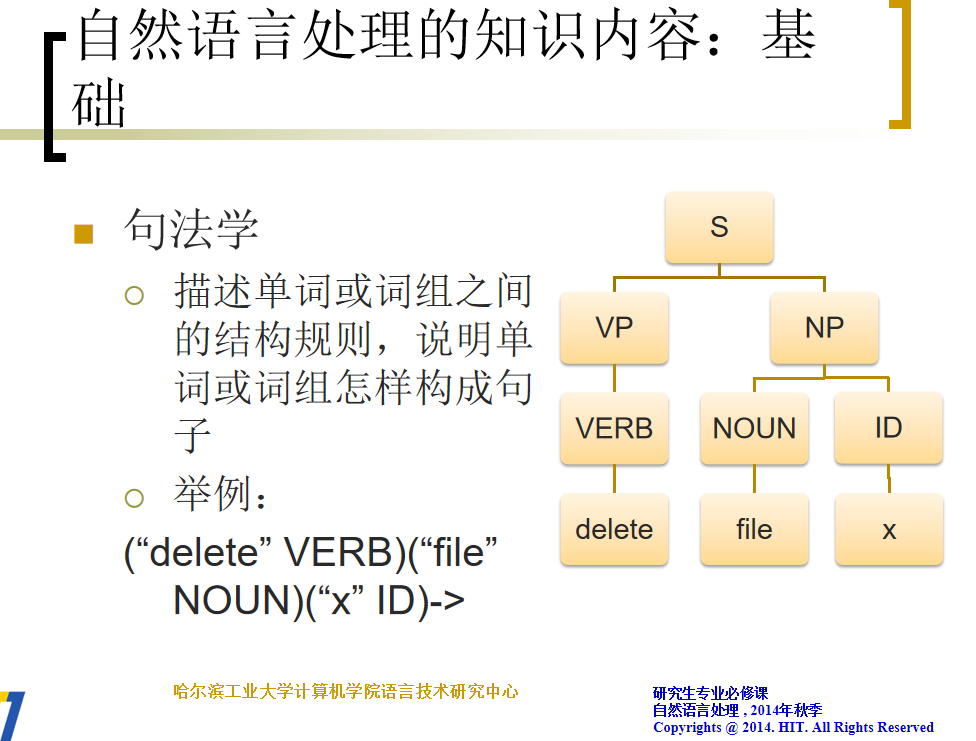


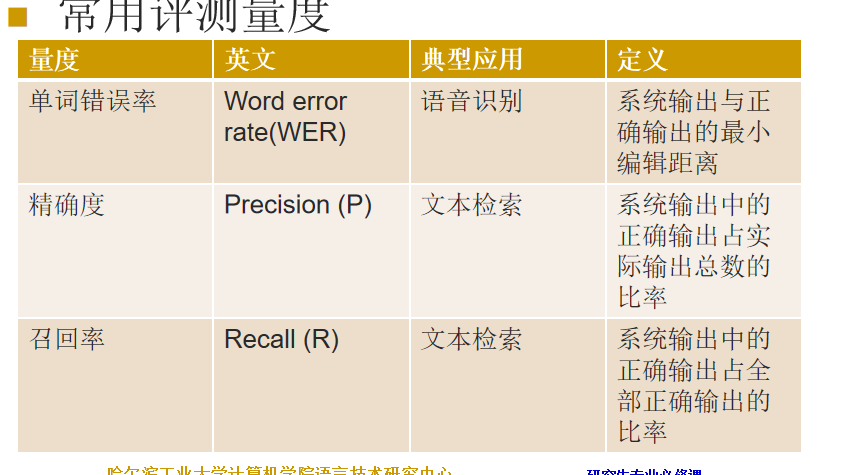
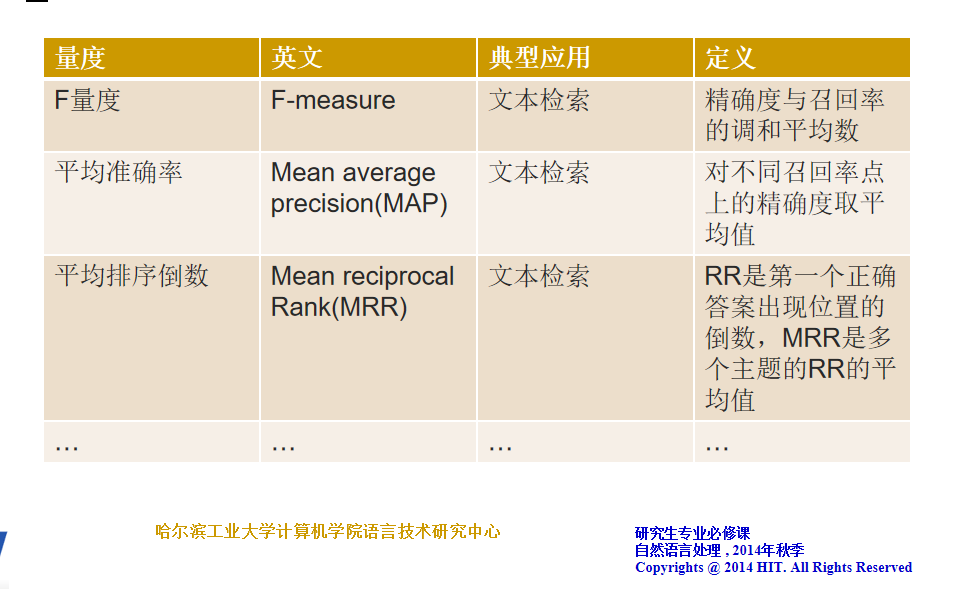
NLP评测
从汉字信息处理到汉语
📘 词处理
**词:**词是自然语言中最小的有意义的构成单位
分词规范:《信息处理用现代汉语分词规范》(中华人民共和国国家标准GB13715)
研究内容: 分词、词性标注、词义消歧等
📖 语句处理
- 语法分析
- 语句的语义分析
2、独热编码
概念
👀 词向量 :
文字对于计算机来说就仅仅只是一个个符号,计算机无法理解其中含义,更无法处理。因此,NLP第一步就是:将文本数字化。
NLP中最早期 的文本数字化方法,就是将文本转换为字典序列。如:"阿"是新华字典中第1个单词所以它的字典序列就是 1。

但是,这种数字化方法存在一个问题,就是模型可能会错误地认为不同类别之间存在一些顺序或距离关系 ,而实际上这些关系可能是不存在的或者不具有实际意义的。
📘 独热编码
one-hot编码的基本思想是将每个类别映射到一个向量,其中只有一个元素的值为1,其余元素的值为0。这样,每个类别之间就是相互独立的,不存在顺序或距离关系。
例如,对于三个类别的情况,可以使用如下的one-hot编码:
- 类别1:1,0, 0
- 类别2:0,1,0
- 类别3:0,0, 1
💛 优点
解决了分类器不好处理离散数据的问题,食能够处理非连续型数值。
特征。
😢 缺点
- one-hot 编码是一个词袋模型,是不考虑词和词之间的顺序问题 ,它是假设词和词之间是相互独立的,但是在大部分情况下词和词之间是相互影响的。
- one-hot编码得到的特征是离散稀疏的,每个单词的one-hot编码维度是整个词汇表的大小,维度非常巨大,编码稀疏,会使得计算代价变大。
英文本文案例
python
import torch
import torch.nn.functional as F
# 案例文本
texts = ['Hello, how are you?', 'I am doing well, thank you!', 'Goodbye.']
# 构造词汇表
word_index = {}
index_word = {}
for i, word in enumerate(set(" ".join(texts).split())): # " ".join(texts)字符串拼接,用' '; split默认空格分割; set去重重复项(哈希表)
word_index[word] = i # word: i
index_word[i] = word # i: word
# 将文本转化为整数序列
sequences = [[word_index[word] for word in text.split()] for text in texts] # 每句话分割,每句话就是一个特征向量
# 获取词汇表大小
vocab_size = len(word_index)
# 整数序列转化为独立编码
one_hot_results = torch.zeros(len(texts), vocab_size) # 创建矩阵
for i, seq in enumerate(sequences): # 遍历每个特征向量的元素
one_hot_results[i, seq] = 1
# 打印结果
print("词汇表:")
print(word_index)
print("文本: ")
print(texts)
print("文本序列: ")
print(sequences)
print("one-hot:")
print(one_hot_results)词汇表:
{'you!': 0, 'doing': 1, 'well,': 2, 'are': 3, 'how': 4, 'you?': 5, 'am': 6, 'Hello,': 7, 'thank': 8, 'Goodbye.': 9, 'I': 10}
文本:
['Hello, how are you?', 'I am doing well, thank you!', 'Goodbye.']
文本序列:
[[7, 4, 3, 5], [10, 6, 1, 2, 8, 0], [9]]
one-hot:
tensor([[0., 0., 0., 1., 1., 1., 0., 1., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 1., 0., 1., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.]])独热编码很想构造线性无关的特征向量,结合本案例,行表示每句话,列表示这句话有啥单词
中文文本案例
python
import torch
import torch.nn.functional as F
# 文本
texts = ['你好,最近怎么样?', '我过得很好,谢谢!', '羊小猪']
# 词汇表
word_index = {}
index_word = {}
for i, word in enumerate(set(" ".join(texts))): # 中文和英文不同注意,英文每个词都是空格分开
word_index[word] = i
index_word[i] = word
# 将文本转化为整数序列
sequences = [[word_index[word] for word in text] for text in texts]
# 获取词汇表大小
vocab_size = len(word_index)
# 将整数转化为one-hot
one_hot_results = torch.zeros(len(texts), vocab_size) # 创建矩阵
for i, seq in enumerate(sequences):
one_hot_results[i, seq] = i
# 打印结果
print("词汇表:")
print(word_index)
print("文本: ")
print(texts)
print("文本序列: ")
print(sequences)
print("one-hot:")
print(one_hot_results)词汇表:
{' ': 0, '样': 1, '你': 2, '?': 3, '猪': 4, '小': 5, '怎': 6, '过': 7, '很': 8, '么': 9, '最': 10, '得': 11, '好': 12, '羊': 13, '谢': 14, '我': 15, '近': 16, ',': 17, '!': 18}
文本:
['你好,最近怎么样?', '我过得很好,谢谢!', '羊小猪']
文本序列:
[[2, 12, 17, 10, 16, 6, 9, 1, 3], [15, 7, 11, 8, 12, 17, 14, 14, 18], [13, 5, 4]]
one-hot:
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0.],
[0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 1., 1., 0., 1., 1., 0., 1.,
1.],
[0., 0., 0., 0., 2., 2., 0., 0., 0., 0., 0., 0., 0., 2., 0., 0., 0., 0.,
0.]])注意 :上面案例都是以"字"为单位的,但是中文词拆开后会有歧义,不需要进行分词操作。
常用的分词有:结巴分词(jieba)
- 定义 :
jieba是一个开源的中文分词 Python 库,广泛用于自然语言处理(NLP)任务,如文本分析、词频统计、情感分析等。 - 特点 :
- 支持多种分词模式(精确模式、全模式、搜索引擎模式)。
- 支持自定义词典和词频调整。
- 支持繁体中文分词。
- 高效快速,基于前缀词典和动态规划算法。
- 提供关键词提取、词性标注等高级功能。
python
import torch
import torch.nn.functional as F
import jieba
# 文本
texts = ['你好,最近怎么样?', '我过得很好,谢谢!', '羊小猪']
# 分词
tokenized_texts = [list(jieba.cut(text)) for text in texts]
print("tokenized_texts: ", tokenized_texts)
# 词汇表
word_index = {}
index_word = {}
for i, word in enumerate(set([word for text in tokenized_texts for word in text])): # 将分词后的文本列表(tokenized_texts)合并为一个包含所有唯一词汇的集合
word_index[word] = i
index_word[i] = word
# 将文本转化为整数序列
sequences = [[word_index[word] for word in text] for text in tokenized_texts]
# 获取词汇表大小
vocab_size = len(word_index)
# 将整数转化为one-hot
one_hot_results = torch.zeros(len(texts), vocab_size) # 创建矩阵
for i, seq in enumerate(sequences):
one_hot_results[i, seq] = i
# 打印结果
print("词汇表:")
print(word_index)
print("文本: ")
print(texts)
print("文本序列: ")
print(sequences)
print("one-hot:")
print(one_hot_results)Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\WY118C~1\AppData\Local\Temp\jieba.cache
Loading model cost 1.109 seconds.
Prefix dict has been built successfully.
tokenized_texts: [['你好', ',', '最近', '怎么样', '?'], ['我过', '得', '很', '好', ',', '谢谢', '!'], ['羊', '小猪']]
词汇表:
{'得': 0, '好': 1, '羊': 2, '怎么样': 3, '很': 4, '最近': 5, '?': 6, '!': 7, '我过': 8, ',': 9, '你好': 10, '小猪': 11, '谢谢': 12}
文本:
['你好,最近怎么样?', '我过得很好,谢谢!', '羊小猪']
文本序列:
[[10, 9, 5, 3, 6], [8, 0, 4, 1, 9, 12, 7], [2, 11]]
one-hot:
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 0., 0., 1., 0., 0., 1., 1., 1., 0., 0., 1.],
[0., 0., 2., 0., 0., 0., 0., 0., 0., 0., 0., 2., 0.]])