与模型训练相关问题
-
- [损失函数Cross entropy loss的含义](#损失函数Cross entropy loss的含义)
- 训练数据有脏数据,怎么处理?
- loss一直不收敛,怎么排查?
- 连续值的特征怎么处理后输入到机器学习模型当中
损失函数Cross entropy loss的含义
在深度学习中,可以看作通过概率分布q ( x )(预测概率)表示概率分布p ( x ) (label)
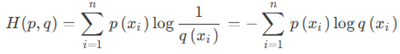 物理意义:可以理解为在相对熵中,一个目标事件已确定(label),求另一个概率分布到目标概率分布的距离
物理意义:可以理解为在相对熵中,一个目标事件已确定(label),求另一个概率分布到目标概率分布的距离
训练数据有脏数据,怎么处理?
判断脏数据的类型,然后对症下药
a) 缺失值:删除、填充、插值。
b) 重复数据:删除。
c) 异常值:删除、修正、保留。
d) 噪声数据:平滑、数据清洗。
e) 类别数据:合并稀有类别、标签一致化。
f) 文本数据:拼写纠正、去除停用词、标准化。
g) 数据标准化/归一化:确保数据具有合适的尺度。
loss一直不收敛,怎么排查?
a) 学习率过大或过小:尝试使用学习率调度器,逐步减少学习率,或者尝试使用一些自适应优化算法(如Adam、RMSprop)来自动调整学习率。
b) 优化器选择:选择合适的优化器
c) 损失函数设计问题:检查损失函数的实现,确认它适合当前任务,并且在数值计算时没有出现溢出或下溢问题。
d) 数据问题:数据不平衡或者数据预处理问题,检查数据集的分布,确保数据没有问题。如果是分类问题,考虑使用类权重平衡或者使用过采样/欠采样方法调整数据分布。
e) 模型结构问题:模型过于简单或过于复杂,激活函数选择不当。检查模型结构,确保它适合当前问题,考虑逐步增加或减少网络的深度,或者尝试不同的激活函数(如LeakyReLU、ELU等)
f) 梯度爆炸/消失
g) 过拟合:虽然过拟合一般表现为训练损失低而验证损失高,但也有可能导致训练过程中的损失值不收敛。检查是否存在过拟合或欠拟合。
h) 数据泄漏:如果在训练过程中出现了数据泄漏(例如训练数据和验证数据存在重叠,或者特征和目标之间存在不合理的关联),也可能导致损失值不收敛。
通过逐步排查上述问题,你应该能够找到导致损失不收敛的根本原因,并采取相应的措施进行调整。
连续值的特征怎么处理后输入到机器学习模型当中
处理缺失值和异常值,然后对数据进行归一化或者标准化处理,根据实际情况决定是否需要进行特征工程(指从原始数据中提取、转换或创建出新的特征,以便提升机器学习模型的性能和准确性,如对数变换、组合特征、降维等),目前特征工程只用在传统机器学习中,深度学习中基本不用。