在如今信息爆炸时代,风控系统离不开大数据技术的支撑,大数据技术可以帮助风控系统跑的更快,算的更准。因此,风控技术研发需要掌握大数据相关技术。然而大数据技术栈内容庞大丰富,风控研发同学很可能会面临以下这些痛点:
1 大数据技术栈太庞大,不知从何学起
2 学了理论但不知如何落地到风控场景
3 团队缺乏大数据工程化经验
4 现有系统遇到性能瓶颈需要优化方案
因此,结合风控业务场景,整理了一个大数据技术学习路线和应用策略:
一、风控大数据技术矩阵
风控系统的核心能力依赖于以下大数据技术栈:
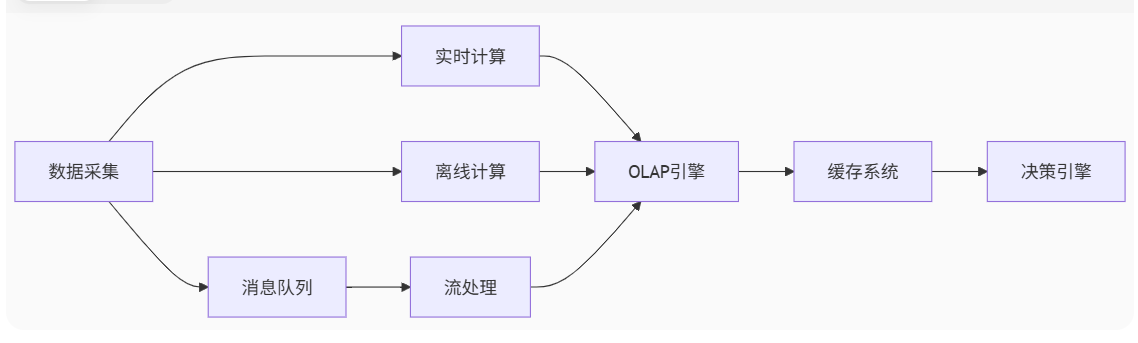
关键技术栈及学习重点:
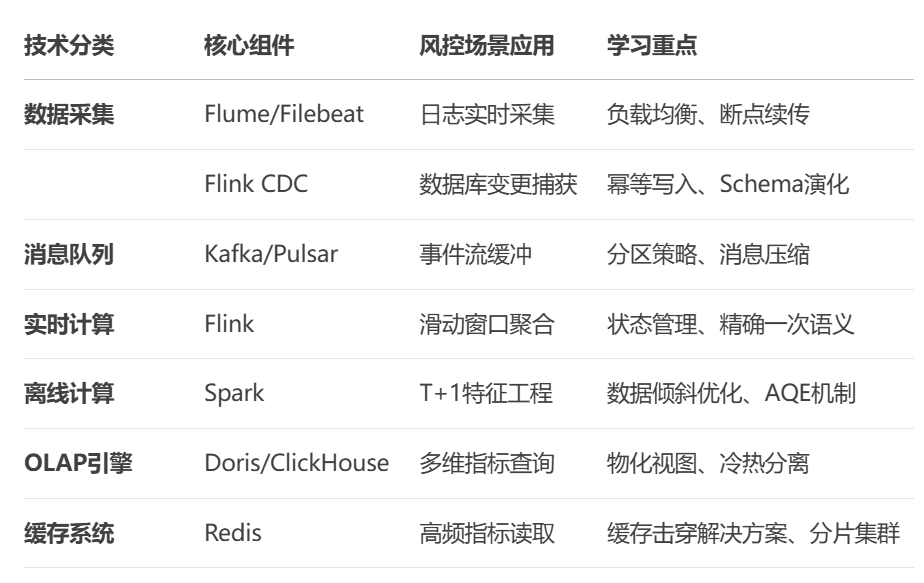
二、关键技术学习路径(附实战案例)
- 实时流处理(Flink)
**学习路线**:
```mermaid
graph LR
A基础API --> B状态管理
B --> C窗口机制
C --> D容错机制
D --> E性能调优
```
**风控实战案例**:
```java
// 实时计算用户转账频次(5分钟滑动窗口)
DataStream<Transaction> stream = env.addSource(kafkaSource);
stream.keyBy(Transaction::getUserId)
.window(SlidingProcessingTimeWindows.of(Time.minutes(5), Time.minutes(1))
.aggregate(new AggregateFunction<Transaction, Tuple2<Long, Integer>, Tuple2<Long, Integer>>() {
@Override
public Tuple2<Long, Integer> createAccumulator() {
return Tuple2.of(0L, 0);
}
@Override
public Tuple2<Long, Integer> add(Transaction value, Tuple2<Long, Integer> acc) {
return Tuple2.of(acc.f0 + value.getAmount(), acc.f1 + 1);
}
@Override
public Tuple2<Long, Integer> getResult(Tuple2<Long, Integer> acc) {
return acc;
}
// 合并逻辑省略...
});
```
**关键调优参数**:
```yaml
flink-conf.yaml
taskmanager.memory.process.size: 4096m
state.backend: rocksdb
state.checkpoints.dir: hdfs:///flink-checkpoints
```
- 分布式批处理(Spark)
**风控场景核心能力**:
-
大规模特征工程
-
模型批量预测
-
历史数据回溯
**解决数据倾斜方案**:
```scala
// 双重聚合解决用户交易金额倾斜
val saltedDF = transactionDF
.withColumn("salt", (rand() * 100).cast(IntegerType))
.groupBy(col("user_id"), col("salt"))
.agg(sum("amount").as("partial_sum"))
val resultDF = saltedDF
.groupBy("user_id")
.agg(sum("partial_sum").as("total_amount"))
```
**资源优化公式**:
```
Executor数量 = (总核数 / 每个Executor核数)
Executor内存 = (总内存 / Executor数量) * 0.8 // 保留20%系统开销
```
- OLAP引擎(Doris)
**风控场景四大优势**:
-
**实时分析**:支持秒级数据可见
-
**高并发**:单集群可承载10K QPS
-
**易用性**:兼容MySQL协议
-
**低成本**:数据压缩比>5:1
**风控指标表设计范式**:
```sql
CREATE TABLE risk_user_indicators (
user_id BIGINT,
indicator_time DATETIME DEFAULT CURRENT_TIMESTAMP,
txn_count_1h BIGINT SUM DEFAULT "0",
reject_rate_1d DOUBLE SUM DEFAULT "0.0",
last_device VARCHAR(50) REPLACE -- 最新设备号
) ENGINE=OLAP
DUPLICATE KEY(user_id, indicator_time) -- 明细模型
PARTITION BY RANGE(indicator_time)()
DISTRIBUTED BY HASH(user_id) BUCKETS 64;
```
- 缓存系统(Redis)
**风控查询加速方案**:
```mermaid
graph TD
A查询请求 --> B{本地缓存}
B -->|命中| C返回
B -->|未命中| D{Redis集群}
D -->|命中| E异步刷新本地缓存
D -->|未命中| F查询Doris
F --> G写入Redis
```
**防缓存穿透代码**:
```python
def get_risk_indicator(user_id):
bloom_key = f"bloom:{user_id}"
布隆过滤器拦截
if not redis_client.bf.exists(bloom_key):
return None
cache_key = f"indicator:{user_id}"
data = redis_client.get(cache_key)
if data:
return deserialize(data)
获取分布式锁
with redis_lock.lock(f"lock:{user_id}", timeout=3):
data = query_doris(user_id) # 回源查询
redis_client.setex(cache_key, 300, serialize(data))
return data
```
三、性能优化黄金法则
- 实时计算优化三原则
| **问题类型** | **解决方案** | **实施效果** |
|-------------------|------------------------------|----------------------|
| 反压(Backpressure)| 动态扩缩容+流量控制 | 延迟降低80% |
| 状态膨胀 | TTL状态清理+RocksDB压缩 | 存储成本下降60% |
| 计算热点 | KeyBy前加盐分流 | 并行度利用率提升4倍 |
- Doris查询优化矩阵
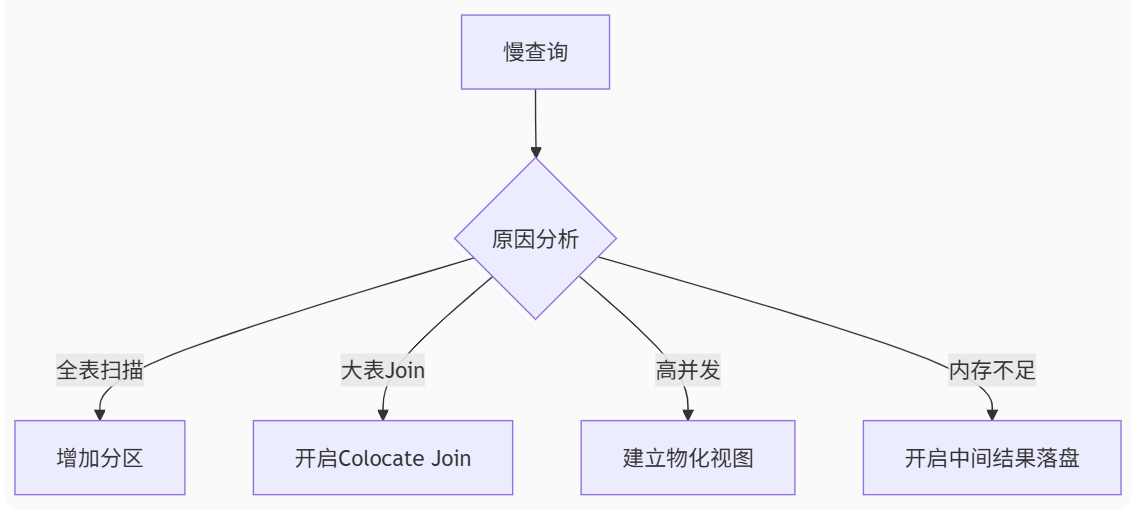
四、学习资源与实验平台
- 高效学习路径
**阶段1:基础入门**
-
《Flink权威指南》(https://flink-book.org)
-
Spark官方文档(https://spark.apache.org/docs/latest/)
**阶段2:场景实战**
```bash
搭建风控实验环境
git clone https://github.com/risk-lab/risk-simulator
docker-compose up -d # 包含Kafka+Flink+Doris
```
**阶段3:性能调优**
-
Doris性能调优手册(https://doris.apache.org/docs/dev/administrator-guide/optimization/)
-
Redis深度历险(https://book.douban.com/subject/30386804/)
- 推荐实验项目
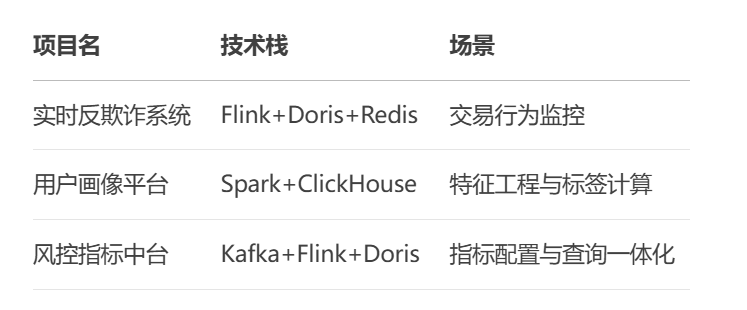
五、技术选型决策树
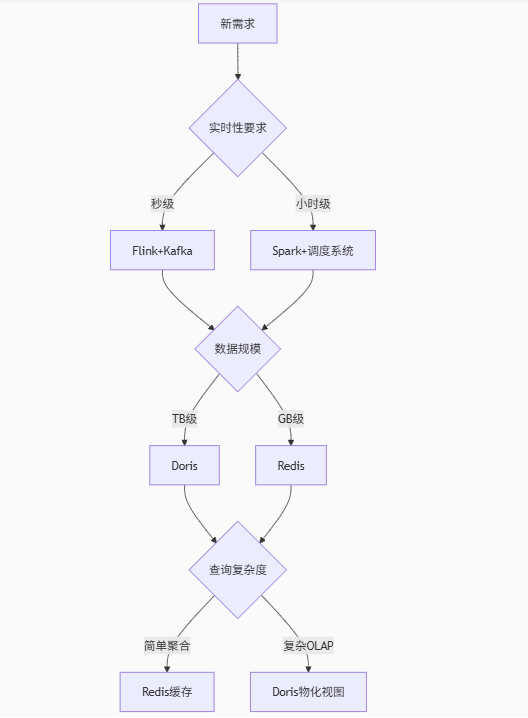
六、避坑指南:风控场景特有挑战
- 数据质量治理
**典型问题**:
-
业务系统埋点字段变更导致指标断裂
-
网络抖动引发数据丢失
**解决方案**:
```sql
-- Doris数据质量监控SQL
SELECT
data_date,
COUNT(*) AS total_rows,
SUM(CASE WHEN user_id=0 THEN 1 ELSE 0 END) AS error_cnt
FROM risk_events
GROUP BY data_date
HAVING error_cnt/total_rows > 0.01; -- 错误率超过1%报警
```
- 指标回溯难题
**最佳实践**:
-
使用**Delta Lake**存储历史快照
-
构建**时间旅行查询**能力:
```scala
spark.read.format("delta")
.option("versionAsOf", "2023-01-01")
.load("/risk_events")
```
结语:风控研发的大数据能力模型
```mermaid
pie
title 能力分布建议
"流处理能力" : 35
"OLAP优化" : 25
"数据建模" : 20
"资源调优" : 15
"故障处理" : 5
```
**行动建议**:
-
**建立技术雷达**:定期评估Doris/Flink等组件新特性
-
**构建基准测试**:对关键链路的性能指标持续监测
-
**培养全栈思维**:从数据采集到决策输出的端到端优化
> **风控大数据技术本质**:
> 不是追求技术先进性,而是通过合理的技术组合实现:
> - **更快的风险识别**(实时计算)
> - **更准的风险评估**(特征工程)
> - **更稳的系统支撑**(高可用架构)