Hadoop 大数据启蒙:深入解析分布式基石 HDFS
分布式存储的本质:用廉价机器集群解决海量数据的存储与容错问题
一、为什么需要 HDFS?
当数据规模突破单机极限(如 PB 级),传统存储面临核心瓶颈:
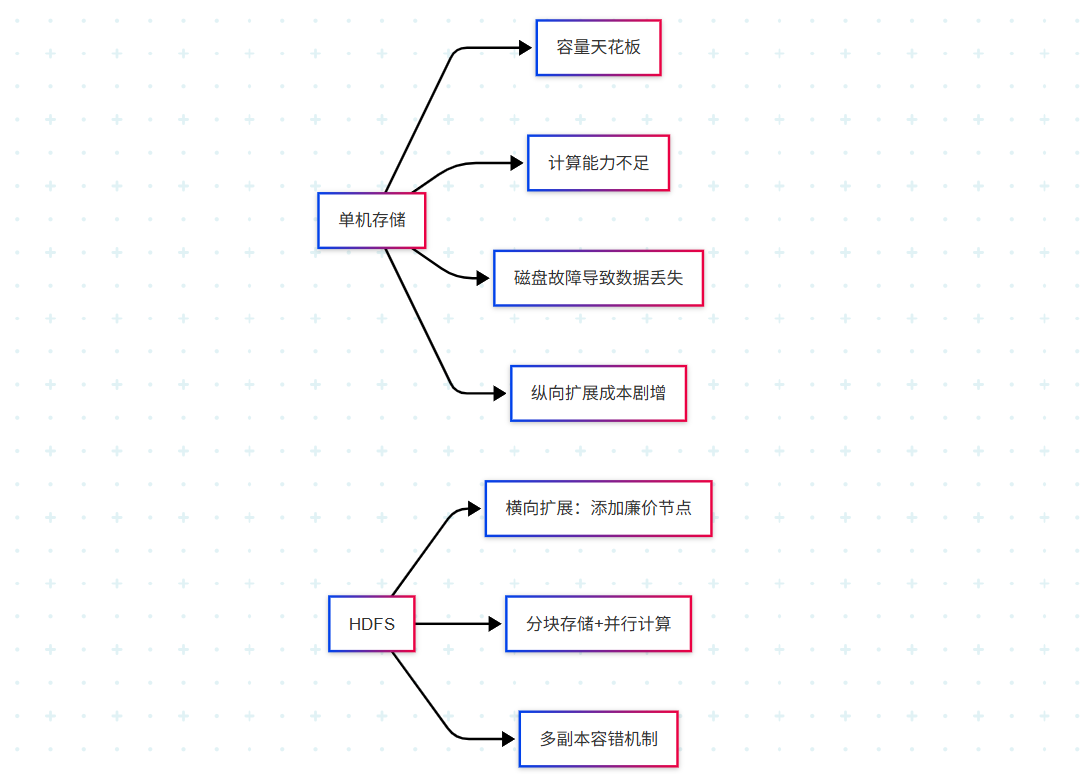
二、HDFS 核心架构解析
1. 主从架构设计
| 组件 | 角色 | 关键职责 | 容灾方案 |
|---|---|---|---|
| NameNode | 集群指挥官 | - 管理文件系统命名空间 - 维护文件→Block映射关系 - 监控DataNode心跳 | Active/Standby HA + ZKFC |
| DataNode | 数据存储节点 | - 实际存储数据块 - 执行数据读写 - 定期发送Block报告 | 多副本自动修复 |
| JournalNode | 元数据同步器(HA方案) | 共享EditLog实现主备NameNode元数据同步 | 至少3节点部署 |
2. 核心运行机制
▶ Block 分块策略
-
默认大小 :Hadoop 2.x+ 为 128MB(可配置为 256MB/512MB)
-
分块优势 :
python# 分块存储伪代码示例 def split_file(file): blocks = [] while file.has_more_data(): block = file.read(128 * 1024 * 1024) # 读取128MB blocks.append(distribute_to_datanodes(block)) # 分发到不同DN return blocks # 文件被拆分为独立存储的块
▶ 多副本机制(Replication)
- 默认副本数 :3份(可动态调整)
- 智能放置策略 :
写入请求 选择DN 副本1 副本2 副本3 Client NameNode 机架Rack1-DN1 机架Rack2-DN2 机架Rack3-DN3
三、HDFS 核心流程剖析
1. 文件写入流程(Pipeline 管道机制)
Client NameNode DN1 DN2 DN3 1. 创建文件请求 2. 返回DN列表DN1,DN2,DN3 3. 发送数据包(Packet) 4. 转发数据包 5. 转发数据包 6. ACK确认 7. ACK确认 8. ACK确认 Client NameNode DN1 DN2 DN3
2. 文件读取流程(就近访问原则)
Client NameNode 最近节点 获取文件 Block 位置 返回含拓扑距离的 DN 列表 直接读取 Block 返回数据 请求下一个 Block 位置 Client NameNode 最近节点
四、HDFS 的适用场景与局限
最佳实践场景 ✅
| 场景类型 | 案例 | 优势体现 |
|---|---|---|
| 海量冷数据存储 | 历史日志归档 | 高吞吐量低成本存储 |
| 批处理数据源 | MapReduce/Spark输入源 | 分块并行读取加速计算 |
| 流式写入场景 | IoT传感器数据收集 | 追加写入(append)优化 |
不适用场景 ❌
| 场景类型 | 问题根源 | 替代方案 |
|---|---|---|
| 低延迟读写 | 多次网络跳转 | HBase, Cassandra |
| 大量小文件存储 | NameNode内存压力 | HAR文件/SequenceFile |
| 文件随机修改 | 只支持追加写入 | 云存储/Object Storage |
五、HDFS 高可用(HA)方案演进
单NameNode
SPOF风险 Secondary NameNode
冷备份 HA with QJM
热切换 Observer NameNode
读写分离
QJM(Quorum Journal Manager)原理 :
使用奇数个JournalNode(通常3/5台)组成集群,通过Paxos算法保证EditLog的一致性,实现秒级主备切换。
六、运维实战命令手册
bash
# 1. 文件操作
hdfs dfs -put local_file /data/input/ # 上传文件
hdfs dfs -cat /data/input/file.txt # 查看文件
hdfs dfs -setrep -w 5 /data/large_file # 动态修改副本数为5
# 2. 系统管理
hdfs dfsadmin -report # 查看集群状态
hdfs haadmin -getServiceState nn1 # 检查NameNode角色
hdfs fsck / -files -blocks # 检查文件块健康度七、HDFS 在生态中的核心地位
存储 数据源 底层存储 HFile存储 训练数据 HDFS MapReduce Spark Hive Metastore HBase MLlib
总结与进阶方向
HDFS 的核心价值在于通过 分布式存储 + 多副本机制 + 主从架构 解决了海量数据的存储可靠性问题。其设计哲学深刻影响了后续分布式系统(如 Ceph、OSS 等)。
推荐学习路径:
- 掌握 HDFS 基准测试工具:
TestDFSIO、NNBench - 研究 Erasure Coding(EC)如何降低存储成本
- 探索 Ozone:下一代 Hadoop 对象存储方案
- 实践 HDFS 与 Kubernetes 的整合部署
思考题:当集群达到 5000 个 DataNode 时,NameNode 可能遇到什么瓶颈?如何优化?(提示:思考内存元数据管理、RPC 吞吐量、联邦架构)
扩展阅读建议:
- HDFS Architecture Guide
- Facebook 的 HDFS 规模化实践
- 《Hadoop: The Definitive Guide》Chapter 3
整理后的技术博客强化了以下关键点:
- 增加架构图/流程图提升理解效率
- 补充企业级高可用方案细节
- 明确适用边界与替代方案
- 添加运维实战命令增强实用性
- 提出进阶思考题引导深度探索
可根据读者群体深度调整技术细节的颗粒度,如需面向运维人员可扩展故障处理章节,面向开发者可增加 Java API 操作示例。