ILM(Index Lifecycle Management)策略详解
- [1.什么是 ILM 策略?](#1.什么是 ILM 策略?)
- [2.ILM 解决的核心业务问题](#2.ILM 解决的核心业务问题)
- [3.ILM 生命周期阶段](#3.ILM 生命周期阶段)
-
- [3.1 Hot(热阶段)](#3.1 Hot(热阶段))
- [3.2 Warm(温阶段)](#3.2 Warm(温阶段))
- [3.3 Cold(冷阶段)](#3.3 Cold(冷阶段))
- [3.4 Delete(删除阶段)](#3.4 Delete(删除阶段))
- [4.如何创建 ILM 策略](#4.如何创建 ILM 策略)
-
- [4.1 基本 ILM 策略示例](#4.1 基本 ILM 策略示例)
- [5.ILM 核心操作详解](#5.ILM 核心操作详解)
-
- [5.1 Rollover(滚动更新)](#5.1 Rollover(滚动更新))
- [5.2 Shrink(收缩索引)](#5.2 Shrink(收缩索引))
- [5.3 Force Merge(强制合并段)](#5.3 Force Merge(强制合并段))
- [5.4 Freeze(冻结索引)](#5.4 Freeze(冻结索引))
- 6.实际应用案例
-
- [案例 1:日志管理系统](#案例 1:日志管理系统)
- [案例 2:电商订单数据](#案例 2:电商订单数据)
- 7.使用注意事项
-
- [7.1 节点属性配置](#7.1 节点属性配置)
- [7.2 监控 ILM 执行](#7.2 监控 ILM 执行)
- [7.3 常见问题处理](#7.3 常见问题处理)
- [7.4 性能考虑](#7.4 性能考虑)
- [7.5 与索引模板结合](#7.5 与索引模板结合)
- [7.6 测试策略](#7.6 测试策略)
- 8.最佳实践
-
- [8.1 合理设置阶段过渡时间](#8.1 合理设置阶段过渡时间)
- [8.2 优先级设置](#8.2 优先级设置)
- [8.3 结合快照备份](#8.3 结合快照备份)
- [8.4 容量规划](#8.4 容量规划)
- [8.5 版本兼容性](#8.5 版本兼容性)
1.什么是 ILM 策略?
ILM(Index Lifecycle Management,索引生命周期管理)是 Elasticsearch 提供的一种自动化管理索引生命周期的机制。它允许用户根据预先定义的策略,自动执行索引的 滚动更新 (rollover)、分片分配 、冻结和删除 等操作,无需人工干预。
2.ILM 解决的核心业务问题
- 自动化索引管理:减少人工维护成本。
- 存储优化:自动将旧数据迁移到成本更低的存储层。
- 性能优化:根据数据热度自动调整资源配置。
- 数据保留合规:自动清理过期数据。
- 资源利用率提升:合理分配集群资源。
3.ILM 生命周期阶段
ILM 策略包含四个可配置的阶段。
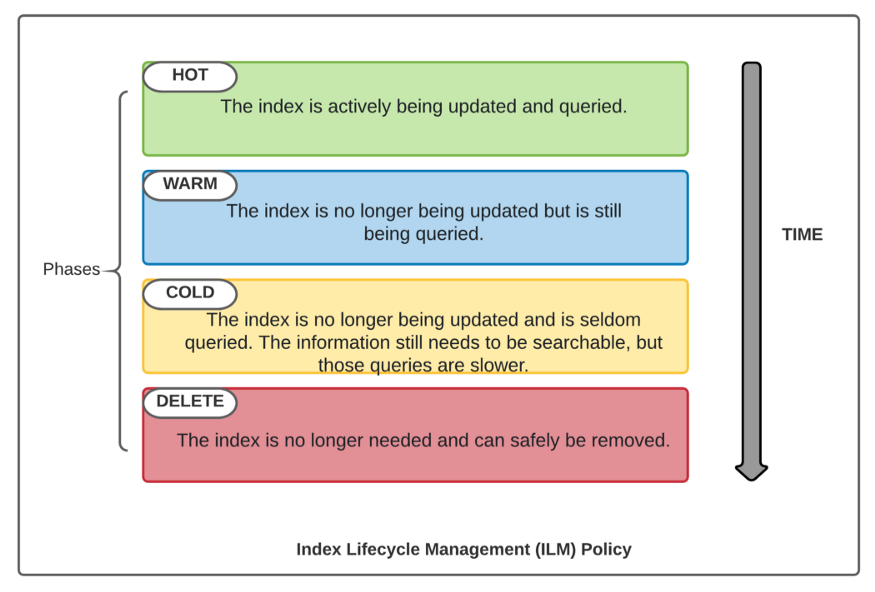
3.1 Hot(热阶段)
- 索引正在被频繁写入和查询。
- 需要高性能资源配置。
- 通常配置滚动更新(
rollover)条件。
3.2 Warm(温阶段)
- 索引不再被写入,但仍被频繁查询。
- 可以降低资源配置。
- 可执行分片合并(
forcemerge)、只读设置等。
3.3 Cold(冷阶段)
- 索引很少被查询,但需要保留。
- 可以转移到更经济的存储。
- 可冻结索引(
freeze)以减少资源占用。
3.4 Delete(删除阶段)
- 索引达到保留期限。
- 自动删除释放空间。
4.如何创建 ILM 策略
4.1 基本 ILM 策略示例
bash
PUT /_ilm/policy/logs_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "50GB",
"max_age": "30d",
"max_docs": 10000000
},
"set_priority": {
"priority": 100
}
}
},
"warm": {
"min_age": "7d",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"allocate": {
"number_of_replicas": 1,
"require": {
"data": "warm"
}
},
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "30d",
"actions": {
"allocate": {
"require": {
"data": "cold"
}
},
"freeze": {},
"set_priority": {
"priority": 0
}
}
},
"delete": {
"min_age": "90d",
"actions": {
"delete": {}
}
}
}
}
}5.ILM 核心操作详解
5.1 Rollover(滚动更新)
作用:当索引达到指定条件时自动创建新索引。
常见触发条件:
max_age:自索引创建后的最长时间。max_docs:索引包含的最大文档数。max_size:索引的最大主分片大小。
使用示例:
bash
PUT /_ilm/policy/my_rollover_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_age": "7d",
"max_size": "50GB"
}
}
}
}
}
}5.2 Shrink(收缩索引)
作用:减少主分片数量。
适用场景:
- 索引不再写入后。
- 减少分片数以节省资源。
示例配置:
json
"warm": {
"actions": {
"shrink": {
"number_of_shards": 1
}
}
}5.3 Force Merge(强制合并段)
作用:合并分段以减少资源占用和提高查询性能.
示例配置:
json
"warm": {
"actions": {
"forcemerge": {
"max_num_segments": 1
}
}
}5.4 Freeze(冻结索引)
作用:将索引设为只读并减少内存占用。
示例配置:
json
"cold": {
"actions": {
"freeze": {}
}
}6.实际应用案例
案例 1:日志管理系统
需求:
- 热数据保留 7 7 7 天,高性能存储。
- 温数据保留 30 30 30 天,标准存储。
- 冷数据保留 90 90 90 天,低成本存储。
- 最终自动删除。
ILM 策略:
bash
PUT /_ilm/policy/logs_management_policy_v2
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms", # 明确从索引创建开始
"actions": {
"rollover": {
"max_age": "7d", # 更合理的rollover周期
"max_size": "50GB",
"max_docs": 10000000
},
"set_priority": {
"priority": 100
}
}
},
"warm": {
"min_age": "7d", # 从索引创建后7天进入warm
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"allocate": {
"number_of_replicas": 1,
"require": {
"data": "warm" # 明确要求warm节点
}
},
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "30d", # 从创建后30天进入cold
"actions": {
"allocate": {
"require": {
"data": "cold" # 明确要求cold节点
}
},
"freeze": {}, # 冻结索引节省资源
"set_priority": {
"priority": 0
}
}
},
"delete": {
"min_age": "90d", # 从创建后90天删除
"actions": {
"delete": {
"delete_searchable_snapshot": true # 可选:删除前检查快照
}
}
}
}
}
}配套的索引模板示例
bash
PUT /_index_template/logs_template
{
"index_patterns": ["logs-*"],
"template": {
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"index.lifecycle.name": "logs_management_policy_v2",
"index.lifecycle.rollover_alias": "logs"
},
"mappings": {
"properties": {
"@timestamp": { "type": "date" },
"log_level": { "type": "keyword" },
"message": { "type": "text" }
}
}
}
}案例 2:电商订单数据
需求:
- 热阶段:处理当前订单(高优先级)。
- 温阶段:近期订单可查询(优化存储)。
- 冷阶段:归档订单(低成本存储)。
- 3 3 3 年后自动删除。
ILM 策略:
bash
PUT /_ilm/policy/orders_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_age": "7d"
},
"set_priority": {
"priority": 100
}
}
},
"warm": {
"min_age": "30d",
"actions": {
"allocate": {
"require": {
"data": "warm"
}
}
}
},
"cold": {
"min_age": "365d",
"actions": {
"allocate": {
"require": {
"data": "cold"
}
}
}
},
"delete": {
"min_age": "1095d", // 3年
"actions": {
"delete": {}
}
}
}
}
}7.使用注意事项
7.1 节点属性配置
- 需要为温冷数据节点配置属性
bash
# 在elasticsearch.yml中
node.attr.data: warm
# 或
node.attr.data: cold7.2 监控 ILM 执行
bash
GET /_ilm/status
GET /_ilm/policy/logs_policy
GET logs-*/_ilm/explain7.3 常见问题处理
- 策略不生效:检查
min_age设置(默认是上次rollover后时间)。 - 阶段卡住:使用
GET _ilm/explain诊断。 - 权限问题:确保用户有足够权限。
7.4 性能考虑
- Force merge 操作资源消耗大,应在低峰期执行。
- 避免过于频繁的
rollover(会产生大量小索引)。
7.5 与索引模板结合
bash
PUT /_index_template/logs_template
{
"index_patterns": ["logs-*"],
"template": {
"settings": {
"index.lifecycle.name": "logs_policy",
"index.lifecycle.rollover_alias": "logs"
}
}
}7.6 测试策略
bash
POST /_ilm/move/logs-000001
{
"current_step": {
"phase": "new",
"action": "complete",
"name": "complete"
},
"next_step": {
"phase": "hot",
"action": "rollover",
"name": "attempt-rollover"
}
}8.最佳实践
8.1 合理设置阶段过渡时间
- 根据业务访问模式设置
min_age。 - 热 → 温:通常 1 − 7 1-7 1−7 天。
- 温 → 冷: 7 − 30 7-30 7−30天。
8.2 优先级设置
json
"set_priority": {
"priority": 100 // 热阶段最高
}8.3 结合快照备份
- 重要数据在删除前应考虑备份。
- 可以使用 SLM(
Snapshot Lifecycle Management)。
8.4 容量规划
- 根据
rollover条件预估索引数量。 - 监控各阶段存储使用情况。
8.5 版本兼容性
- ILM 在 Elasticsearch 6.6 + 6.6+ 6.6+ 可用。
-
- x 7.x 7.x 后功能更完善。
通过合理配置 ILM 策略,可以实现索引的全生命周期自动化管理,显著降低运维成本,同时优化存储和查询性能。