机器学习入门核心算法:Mini-Batch K-Means算法
-
- 一、算法逻辑
- 二、算法原理与数学推导
-
- [1. 目标函数](#1. 目标函数)
- [2. Mini-Batch更新规则](#2. Mini-Batch更新规则)
- [3. 学习率衰减机制](#3. 学习率衰减机制)
- [4. 伪代码](#4. 伪代码)
- 三、模型评估
-
- [1. 内部评估指标](#1. 内部评估指标)
- [2. 收敛性判断](#2. 收敛性判断)
- [3. 超参数调优](#3. 超参数调优)
- 四、应用案例
-
- [1. 图像处理 - 颜色量化](#1. 图像处理 - 颜色量化)
- [2. 用户分群 - 电商推荐](#2. 用户分群 - 电商推荐)
- [3. 异常检测 - 网络安全](#3. 异常检测 - 网络安全)
- 五、面试题及答案
-
- [1. Q:为什么Mini-Batch K-Means比传统K-Means快?](#1. Q:为什么Mini-Batch K-Means比传统K-Means快?)
- [2. Q:如何选择批大小b?](#2. Q:如何选择批大小b?)
- [3. Q:学习率 η t = 1 / ( s k + 1 ) \eta_t = 1/(s_k+1) ηt=1/(sk+1) 的设计原理?](#3. Q:学习率 η t = 1 / ( s k + 1 ) \eta_t = 1/(s_k+1) ηt=1/(sk+1) 的设计原理?)
- [4. Q:何时不适合使用Mini-Batch版本?](#4. Q:何时不适合使用Mini-Batch版本?)
- 六、相关论文
- 七、优缺点对比
- 总结
一、算法逻辑
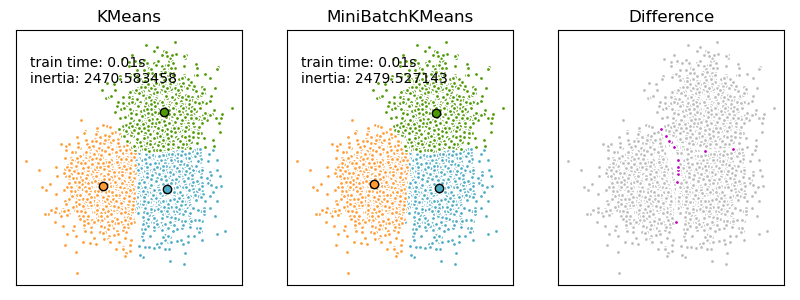
Mini-Batch K-Means 是传统K-Means算法的优化版本,专为大规模数据集 设计。其核心思想是:每次迭代仅使用数据集的随机子集(mini-batch)来更新聚类中心,而非整个数据集。这种方法在保持聚类质量的同时,显著降低计算复杂度和内存需求。
工作流程
否 是 初始化K个聚类中心 随机采样mini-batch 将样本分配到最近中心 更新聚类中心 达到停止条件? 输出聚类结果
与传统K-Means对比
| 特性 | 传统K-Means | Mini-Batch K-Means |
|---|---|---|
| 数据使用 | 全数据集 | 随机子集(mini-batch) |
| 计算复杂度 | O(T·n·K·d) | O(T·b·K·d) |
| 内存需求 | 高(需加载全数据) | 低(仅需小批量数据) |
| 收敛速度 | 较慢 | 快3-5倍 |
| 适用数据规模 | 中小型数据集 | 大规模数据集(>10^5) |
注:T=迭代次数,n=样本数,K=聚类数,d=特征维度,b=批大小
二、算法原理与数学推导
1. 目标函数
同K-Means,最小化簇内平方和 (Within-Cluster Sum of Squares, WCSS):
J = ∑ k = 1 K ∑ x ∈ C k ∥ x − μ k ∥ 2 J = \sum_{k=1}^K \sum_{x \in C_k} \|x - \mu_k\|^2 J=k=1∑Kx∈Ck∑∥x−μk∥2
其中 μ k \mu_k μk 是簇 C k C_k Ck 的中心。
2. Mini-Batch更新规则
对于每个mini-batch B t B_t Bt:
-
样本分配 :对 x i ∈ B t x_i \in B_t xi∈Bt,计算最近中心:
c ( t ) ( x i ) = arg min k ∥ x i − μ k ( t ) ∥ 2 c^{(t)}(x_i) = \arg\min_k \|x_i - \mu_k^{(t)}\|^2 c(t)(xi)=argkmin∥xi−μk(t)∥2 -
中心更新 :对每个簇 k k k,更新中心为历史分配的加权平均:
μ k ( t + 1 ) = μ k ( t ) + η t ⋅ ( 1 ∣ C k ∩ B t ∣ ∑ x i ∈ C k ∩ B t x i − μ k ( t ) ) \mu_k^{(t+1)} = \mu_k^{(t)} + \eta_t \cdot \left( \frac{1}{|C_k \cap B_t|} \sum_{x_i \in C_k \cap B_t} x_i - \mu_k^{(t)} \right) μk(t+1)=μk(t)+ηt⋅(∣Ck∩Bt∣1xi∈Ck∩Bt∑xi−μk(t))其中 η t \eta_t ηt 是学习率,通常设置为:
η t = 1 s k + 1 \eta_t = \frac{1}{s_k + 1} ηt=sk+11
s k s_k sk 是历史上分配到簇 k k k 的样本总数(随时间累积)
3. 学习率衰减机制
为平衡早期快速收敛和后期稳定性:
s k ← s k + n k ( t ) s_k \leftarrow s_k + n_k^{(t)} sk←sk+nk(t)
其中 n k ( t ) = ∣ { x i ∈ B t : c ( t ) ( x i ) = k } ∣ n_k^{(t)} = |\{x_i \in B_t : c^{(t)}(x_i) = k\}| nk(t)=∣{xi∈Bt:c(t)(xi)=k}∣
4. 伪代码
python
输入: 数据集 X, 聚类数 K, 批大小 b, 最大迭代次数 T
输出: 聚类中心 {μ₁, μ₂, ..., μ_K}
1. 初始化中心 μ_k (随机或K-Means++)
2. 初始化计数器 s_k = 0 for k=1..K
3. for t=1 to T:
4. 随机采样 mini-batch B_t ⊂ X, |B_t|=b
5. 对每个 x_i ∈ B_t:
6. c(x_i) = argmin_k ||x_i - μ_k||² // 分配样本
7. 对每个簇 k:
8. n_k = |{x_i ∈ B_t : c(x_i)=k}| // 批次中分配数量
9. if n_k > 0:
10. v_k = (1/n_k) ∑_{c(x_i)=k} x_i // 批次均值
11. s_k = s_k + n_k // 更新计数器
12. μ_k = μ_k + (n_k/s_k)(v_k - μ_k) // 更新中心
13. 返回 {μ_k}三、模型评估
1. 内部评估指标
-
轮廓系数(Silhouette Coefficient) :
s ( i ) = b ( i ) − a ( i ) max { a ( i ) , b ( i ) } s(i) = \frac{b(i) - a(i)}{\max\{a(i), b(i)\}} s(i)=max{a(i),b(i)}b(i)−a(i)其中 a ( i ) a(i) a(i) 是样本 i i i 到同簇其他点的平均距离, b ( i ) b(i) b(i) 是到最近其他簇的平均距离。
-
戴维斯-布尔丁指数(Davies-Bouldin Index) :
D B = 1 K ∑ k = 1 K max j ≠ k ( σ k + σ j d ( μ k , μ j ) ) DB = \frac{1}{K}\sum_{k=1}^K \max_{j \neq k} \left( \frac{\sigma_k + \sigma_j}{d(\mu_k,\mu_j)} \right) DB=K1k=1∑Kj=kmax(d(μk,μj)σk+σj)值越小表示聚类效果越好
2. 收敛性判断
- 相对中心移动量 :
Δ = 1 K ∑ k = 1 K ∥ μ k ( t ) − μ k ( t − 1 ) ∥ 2 < ϵ \Delta = \frac{1}{K}\sum_{k=1}^K \|\mu_k^{(t)} - \mu_k^{(t-1)}\|^2 < \epsilon Δ=K1k=1∑K∥μk(t)−μk(t−1)∥2<ϵ
通常 ϵ = 10 − 5 \epsilon = 10^{-5} ϵ=10−5
3. 超参数调优
| 参数 | 推荐值 | 影响 |
|---|---|---|
| 批大小 (b) | 50 × K 50 \times K 50×K | 过小→不稳定;过大→速度慢 |
| 最大迭代次数 | 100-500 | 根据收敛曲线调整 |
| 初始化方法 | K-Means++ | 显著改善聚类质量 |
四、应用案例
1. 图像处理 - 颜色量化
任务 :将24位真彩图压缩为256色
流程:
- 将像素RGB值作为特征点( d = 3 d=3 d=3)
- 使用Mini-Batch K-Means( K = 256 K=256 K=256, b = 10 4 b=10^4 b=104)
- 将每个像素映射到最近聚类中心
优势:处理100MP图像仅需10秒(传统K-Means需10分钟)
2. 用户分群 - 电商推荐
场景 :为5000万用户分群
特征 :RFM(最近购买Recency、频率Frequency、金额Monetary)
实现:
- 聚类数 K = 8 K=8 K=8
- 批大小 b = 50 , 000 b=50,000 b=50,000
- 结果:识别出"高价值流失用户"群体,推送定向优惠券
效果:转化率提升22%
3. 异常检测 - 网络安全
方法:
- 网络流量特征聚类(IP包数、流量大小、连接频率)
- 定义远离所有聚类中心的样本为异常
优势:实时处理10Gb/s流量数据
五、面试题及答案
1. Q:为什么Mini-Batch K-Means比传统K-Means快?
A :计算复杂度从 O ( T ⋅ n ⋅ K ⋅ d ) O(T·n·K·d) O(T⋅n⋅K⋅d) 降为 O ( T ⋅ b ⋅ K ⋅ d ) O(T·b·K·d) O(T⋅b⋅K⋅d),其中 b ≪ n b \ll n b≪n。内存仅需加载小批量数据,减少I/O开销。
2. Q:如何选择批大小b?
A :经验公式 b = 50 × K b = 50 \times K b=50×K:
- K = 10 K=10 K=10 → b ≈ 500 b≈500 b≈500
- K = 100 K=100 K=100 → b ≈ 5000 b≈5000 b≈5000
需权衡:过小导致更新噪声大,过大失去加速意义。
3. Q:学习率 η t = 1 / ( s k + 1 ) \eta_t = 1/(s_k+1) ηt=1/(sk+1) 的设计原理?
A :这是倒数衰减策略:
- 早期 s k s_k sk 小 → η t \eta_t ηt 大 → 快速逼近中心
- 后期 s k s_k sk 大 → η t \eta_t ηt 小 → 精细调整
类似随机梯度下降(SGD)的学习率衰减。
4. Q:何时不适合使用Mini-Batch版本?
A:三种情况:
- 数据量小( n < 10 , 000 n<10,000 n<10,000)时加速不明显
- 需要精确簇边界(如医学诊断)
- 数据分布极度不均衡(小批量可能漏掉稀有类)
六、相关论文
-
奠基性论文 :
Sculley, D. (2010). Web-Scale K-Means Clustering . Proceedings of the 19th International Conference on World Wide Web.
贡献:首次提出Mini-Batch K-Means,在Google新闻数据上实现10倍加速 -
理论分析 :
Bottou, L., & Bengio, Y. (1995). Convergence Properties of the K-Means Algorithms . Advances in Neural Information Processing Systems.
贡献:证明随机梯度下降在K-Means中的收敛性 -
工业优化 :
Newling, J., & Fleuret, F. (2016). Fast K-Means with Accurate Bounds . ICML.
贡献:提出改进的中心更新边界,减少迭代次数30%
七、优缺点对比
| 优点 | 缺点 |
|---|---|
| 计算高效:比传统K-Means快3-10倍 | 解质量略低:WCSS通常高3-5% |
| 内存友好:可处理超大规模数据(>10^9样本) | 对批大小敏感:需调参 |
| 在线学习:支持流式数据逐步更新 | 收敛不稳定:不同运行结果可能差异2-3% |
| 易并行化:batch间相互独立 | 中心初始化敏感:同传统K-Means |
| 实用性强:Spark MLlib等平台原生支持 | 理论保证弱:只能收敛到局部最优 |
总结
Mini-Batch K-Means 通过随机小批量更新策略,在保持可接受聚类质量的前提下,大幅提升计算效率。其核心价值在于:
- 大规模数据处理:轻松应对百万级以上数据集
- 资源效率:内存消耗低,适合受限环境
- 实用便捷:参数少易实现,主流库均有支持
最佳实践:
- 初始化用K-Means++改善质量
- 批大小设置为 b = 50 × K b = 50 \times K b=50×K
- 多次运行取最佳结果
- 结合肘部法(Elbow Method)选择K值
在工业界大规模聚类任务中,Mini-Batch K-Means已成为首选算法,在Spark MLlib、Scikit-learn等库中广泛实现。