一、什么是时间序列聚类?
如果把数据比作一本书,那么时间序列(Time Series)就是一本按时间顺序记录事件的日记。它可能是股票每天的价格波动、某台机器的温度曲线、一个城市的空气质量变化,甚至是人的心电信号。时间序列聚类,就是要帮这些"日记"找到志同道合的伙伴------那些经历相似、变化趋势类似的"故事"。
举个简单的例子:
-
一家健身房记录了上百名会员的心率曲线。
-
有的人曲线平稳(轻运动爱好者),有的人曲线起伏大(高强度训练者)。
-
通过时间序列聚类,我们可以自动把这些心率曲线分成几类,从而为不同人群定制运动方案。
这就是时间序列聚类的魔力:不需要预先告诉算法类别,它就能根据时间变化的形态,把相似的放一起。
二、为什么要关心时间序列聚类?
1. 时间是数据的灵魂
普通的聚类方法(比如K-means)更像是拍一张"静态照片"------只看当前的特征值。而时间序列聚类更像是看"动态电影"------考虑数据的变化轨迹、节奏、周期性等信息。这意味着它能识别那些静态上差不多,但趋势完全不同的对象。
2. 应用领域极广
-
金融领域:找出走势相似的股票、基金,辅助投资策略。
-
医疗健康:分析病人的心电图(ECG)、脑电图(EEG)等,发现潜在疾病亚型。
-
工业运维:通过传感器数据识别设备的健康状态,提前发现异常模式。
-
气象分析:聚类不同地区的温度、降水曲线,揭示气候分区特征。
-
电力系统:分析负荷曲线,做负荷预测与分组调度。
3. 不止是"分组"
很多人以为聚类就是为了分组,但在时间序列中,聚类还可以:
-
发现隐藏模式
-
数据压缩与表示
-
异常检测(离群曲线往往是异常信号)
-
特征工程(把聚类标签作为新的特征输入到后续模型中)
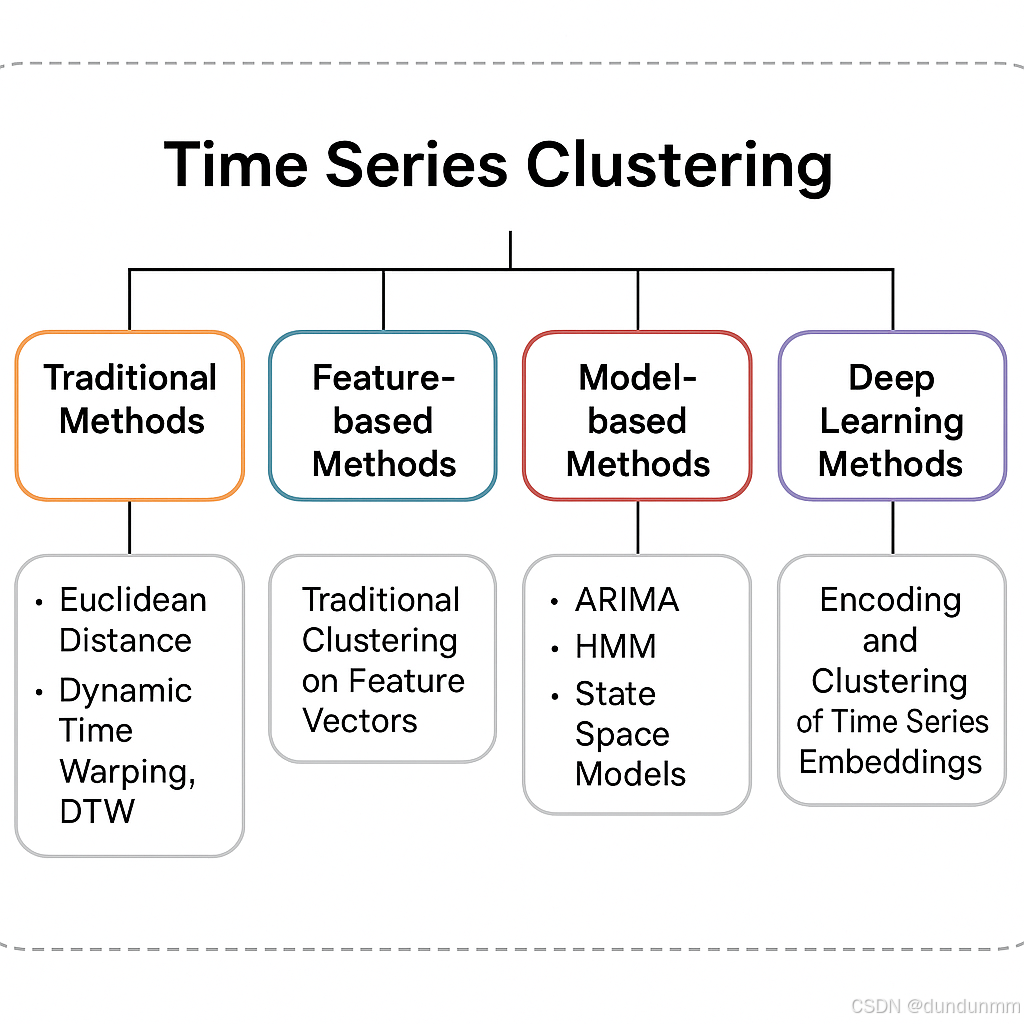
三、时间序列聚类的三大路线
时间序列聚类的方法并不是单一的,它有多条"路线",就像旅游时你可以选择直飞、转机、或者自驾,目的地相同但过程不同。
1. 基于原始数据的聚类
这类方法直接在时间序列的原始形态上计算相似度。
-
欧几里得距离(Euclidean Distance):简单直接,对长度一致且对齐的序列适用。
-
动态时间规整(Dynamic Time Warping, DTW):可以"拉伸"时间轴来匹配曲线,解决了速度不同但形态相似的问题(就像两个人跑同一条路线,一个快一个慢,也能判断他们路线相似)。
-
编辑距离(Edit Distance on Real Sequence, EDR):类似文本编辑距离,允许插入、删除和替换操作。
优点 :保留了所有原始信息。
缺点:计算量大,对噪声敏感。
2. 基于特征的聚类
这类方法会先把时间序列转成一组特征(比如平均值、波动幅度、周期特征、小波系数等),再用传统聚类方法分组。
-
统计特征:均值、方差、最大值、最小值、峰度、偏度。
-
频域特征:傅里叶变换后的频谱能量分布。
-
小波特征:多尺度分解得到的系数。
-
形状特征:趋势斜率、波峰波谷位置。
优点 :速度快,适合大规模数据。
缺点:特征提取过程可能丢失局部模式信息。
3. 基于模型的聚类
这类方法假设每条时间序列由某种生成机制产生,通过拟合模型获取参数,再对参数聚类。
-
ARIMA模型:用自回归和移动平均拟合序列。
-
隐马尔可夫模型(HMM):捕捉序列的隐含状态转换模式。
-
状态空间模型:建模动态系统的观测值与状态。
优点 :能解释生成机制,适合有明显规律的序列。
缺点:建模过程复杂,需要假设模型类型。
4. 深度学习驱动的聚类
近年来,深度学习为时间序列聚类带来了新的可能:
-
RNN/LSTM/GRU自编码器:学习序列的低维表示,再在表示空间中聚类。
-
卷积神经网络(CNN):提取局部时间模式。
-
时序Transformer:捕捉长程依赖关系。
-
对比学习(Contrastive Learning):通过增强对比训练得到更稳健的序列表示。
优点 :能处理复杂、非线性模式,适应性强。
缺点:需要较多数据和计算资源,可解释性较弱。
四、时间序列聚类的关键步骤
无论用哪条路线,时间序列聚类通常遵循以下步骤:
-
数据预处理
-
缺失值填补(插值、前向填充等)
-
去噪(滤波、平滑)
-
标准化(Z-score、Min-Max)
-
对齐(处理起止时间不一致)
-
-
相似度度量
-
根据场景选择距离度量(Euclidean、DTW、相关系数等)
-
计算两两相似度矩阵
-
-
聚类算法选择
-
K-means/K-medoids
-
层次聚类(Hierarchical Clustering)
-
DBSCAN(适合发现不规则簇)
-
谱聚类(Spectral Clustering)
-
-
结果评估
-
内部指标:轮廓系数(Silhouette)、DB指数
-
外部指标(有标签时):ARI、NMI
-
可视化:t-SNE、UMAP降维
-
五、案例:用DTW做股票走势聚类
假设我们有50只股票的近一年日收盘价曲线,目标是找出走势相似的股票组。
-
预处理:
- 对每日收盘价做Z-score标准化,消除价格量级差异。
-
相似度计算:
- 用DTW距离度量每两只股票的走势相似度。
-
聚类:
- 采用K-medoids聚类,将股票分成5组。
-
结果分析:
- 发现A组股票都是周期性波动的消费股,B组是科技股的稳步上涨走势。
这个过程可以辅助投资组合优化,也能为量化策略提供参考。
六、挑战与发展方向
时间序列聚类虽好,但也有不少挑战:
-
高维性与长序列:长时间序列的计算成本高,存储压力大。
-
多变量时序:很多场景下,不止一个传感器或变量。
-
噪声与异常值:现实数据常有缺失、漂移、突变。
-
可解释性:特别是深度学习方法,难以解释聚类原因。
未来的发展趋势包括:
-
可解释的深度聚类模型
-
增量式聚类(实时流数据处理)
-
多模态时序聚类(结合视频、图像、传感器多源信息)
-
自动化特征提取与距离选择
七、总结
时间序列聚类是让"数据的时间故事"找到同类的艺术与科学。它兼具数学的严谨性和现实应用的广泛性,既能服务科研探索,也能直接创造商业价值。无论是原始形态直接比较 ,还是特征提取与建模 ,甚至用深度神经网络做智能聚类,核心都是理解时间背后的模式。
用一句形象的话来说:
普通聚类看的是"你今天长得像谁",
时间序列聚类看的是"你这一路走来,像谁"。