一、《YOLOv3:AnIncrementalImprovement》
1.1、基本信息
-
标题:YOLOv3: An Incremental Improvement
-
作者:Joseph Redmon, Ali Farhadi
-
机构:华盛顿大学(University of Washington)
-
发表时间:2018年
-
代码地址 :Joseph Redmon - Survival Strategies for the Robot Rebellion
论文地址:

我们对YOLO进行了一些更新!我们做了一些小的设计更改来使其更好。我们还训练了这个新的网络,非常不错。它比上次稍大,但更加准确。不过它依然很快,请放心。在320x320的情况下,YOLOv3在28.2 mAP中以22毫秒的速度运行,准确性与SSD相当,但快了三倍。当我们查看老旧的5IOUmAP检测指标时,YOLOv3表现得相当不错。在Titan X上实现了579AP50,而RetinaNet在198毫秒内实现了575AP50,性能相似,但快了3.8倍。像往常一样,所有代码可以在Joseph Redmon - Survival Strategies for the Robot Rebellion上找到。
1.2、主要内容
核心改进:
结合残差网络(ResNet)思想,提出新的主干网络 Darknet-53(53层卷积),兼顾速度与性能。
采用 多尺度预测(3种尺度),融合浅层细粒度特征与深层语义特征,提升小目标检测能力。
使用 维度聚类生成锚框(9个聚类,分3个尺度),通过逻辑回归预测目标存在概率。
性能表现:
速度:在Titan X GPU上,320×320分辨率下仅需22毫秒,比RetinaNet快3.8倍。
精度:AP50指标达57.9,与RetinaNet(57.5)相当,但速度显著占优。
局限性:高IOU阈值(如AP75)下性能较弱,边界框精确定位能力不足。
失败尝试:
线性激活替代sigmoid导致mAP下降。
Focal Loss未提升性能(可能与YOLOv3的独立目标性预测机制冲突)。
双IOU阈值训练策略效果不佳。
1.3、作用影响
技术贡献:
推动实时目标检测的实用化,平衡速度与精度,适用于嵌入式设备和实时系统。
Darknet-53成为高效主干网络设计的参考,影响后续轻量化模型(如YOLOv4、YOLOv5)。
行业影响:
广泛应用于安防监控、自动驾驶、工业检测等对实时性要求高的场景。
引发对目标检测评估指标的反思(如AP50 vs. COCO复杂指标)。
1.4、对未来展望

那么,其他那些为视觉研究提供大量资金的人是军方,他们从来没有做过任何可怕的事情,比如用新技术杀死很多人,哦等等.....我对大多数使用计算机视觉的人充满希望,他们只是用它做快乐、好的事情,比如在国家公园里计算斑马的数量,或者跟踪它们的猫在家里游荡。但是计算机视觉已经在被用于有问题的用途,作为研究人员,我们有责任至少考虑我们的工作可能造成的伤害,并考虑减少它的方式。我们欠世界这么多。
二、YOLOV3
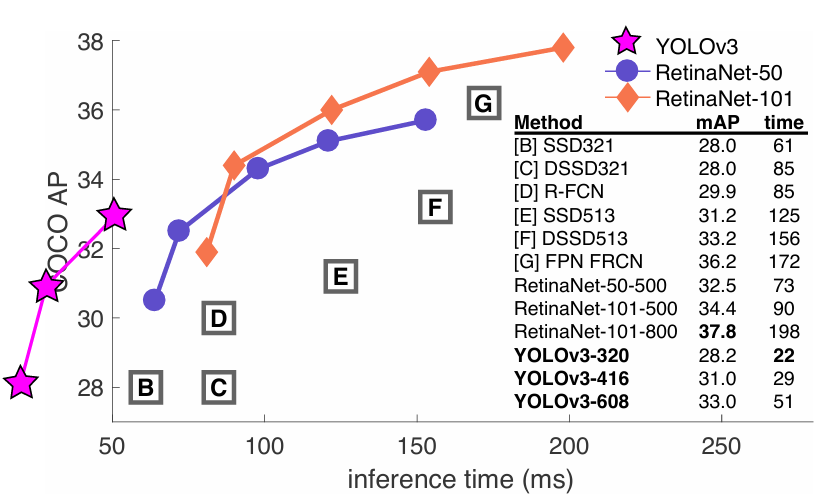
下图中可以看到,2018年测试性能的数据集变成了COCO数据集,可以看到 YOLOV3的速度是非常快的,但是它的mAP并不是非常的高(mAP50 95)。
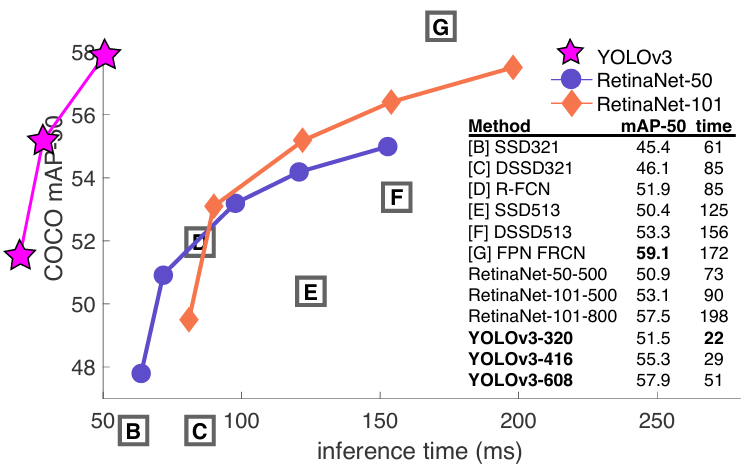
下图中可以看到,当IOU=0.5的时候,即mAP-50时,可以看到YOLOV3的速 度不仅快的,而且还非常准。
2.1、输入处理(Input)
YOLOV3在输入上没做任何的变化。
2.2、骨干网络(Backbone)
修改骨干网络为darknet53
YOLOv3的Backbone在YOLOv2的基础上设计了Darknet-53结构。 Darknet-53结构引入了ResNet的残差思想,类似于ResNet。
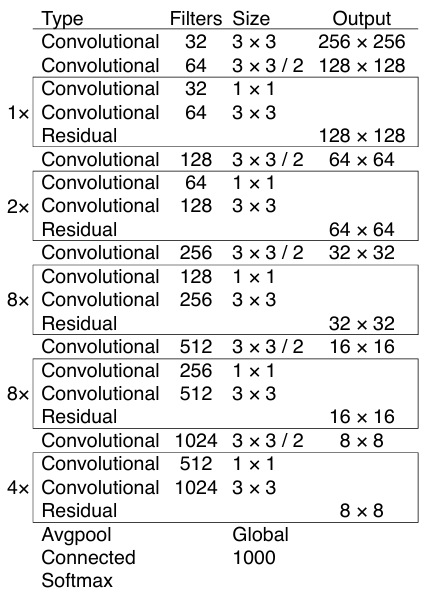
同时,darknet53网络并没有池化层(池化层指的是下采样的池化,并不是 全局平均池化)。
2.3、Neck结构
YOLOv3引入了FPN的思想,以支持后面的Head侧采用多尺度来对不同size 的目标进行检测,越精细的grid cell就可以检测出越精细的目标物体。 YOLOv3设置了三个不同的尺寸,分别是19×19,38×38和76×76,他们之间 的比例为1:2:4。
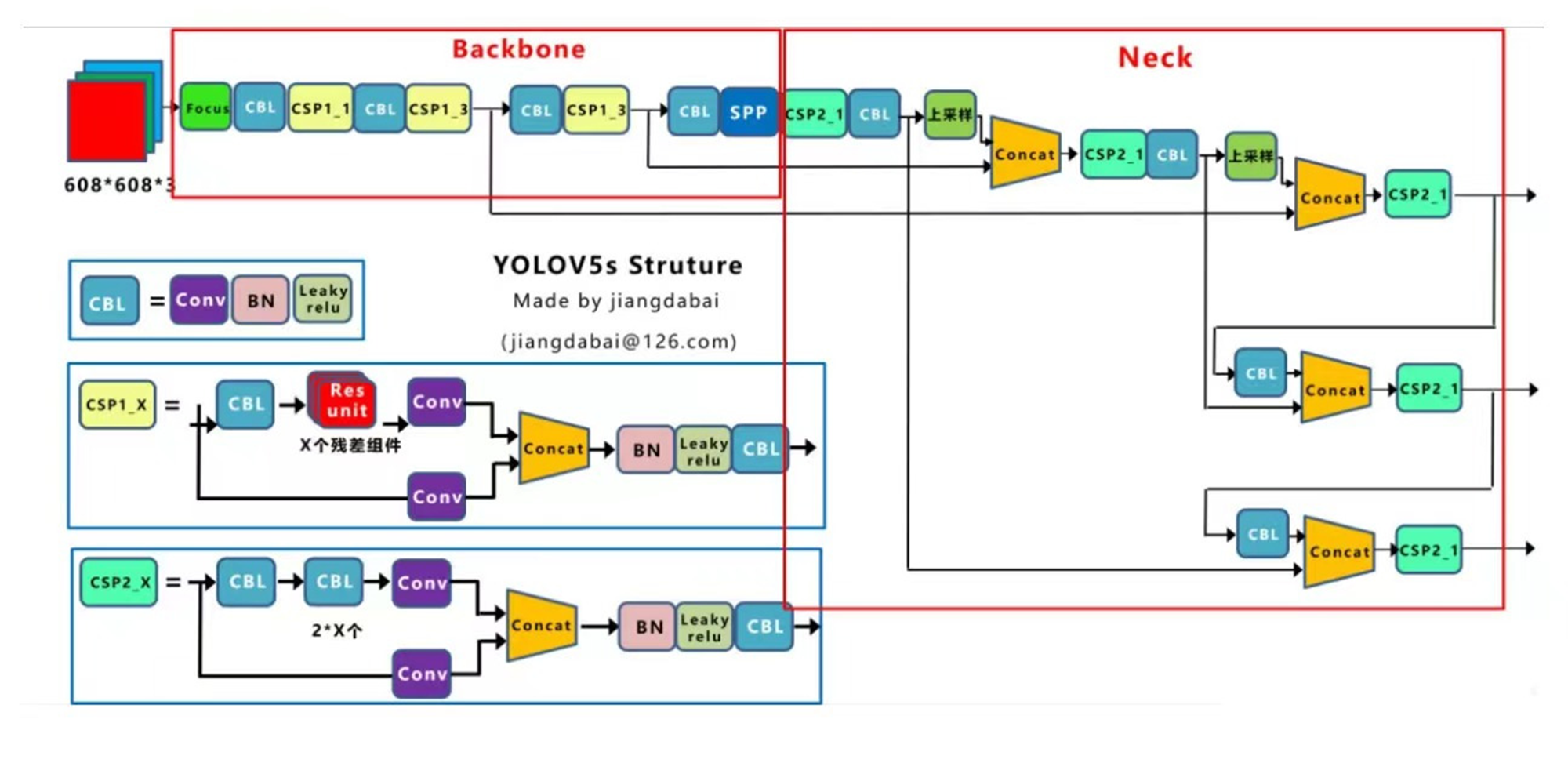
其中,在Neck结构CBL*5中,5层CBL分别是:1x1,3x3,1x1,3x3,1x1 的卷积。
在Neck结构CBL中,是1x1的卷积。 输入时608,
经过Backbone的第一个Res8之后,得到的特征张量缩放比为 8:608/8=76,即76x76x256。
经过Backbone的第二个Res8之后,得到的特征张量缩放比为16: 608/1638,即38x38x512。
Concat是在通道上进行相加。
Neck结构的基础上顺势而为融合了3个尺度,在多个尺度的融合特征图上分 别独立做检测,19x19的检测大尺寸物体,38x38的检测中尺寸物体, 76x76的检测小尺寸物体。
2.4、 检测头(Head)
255是与Anchor Box有关的,那么在YOLOV3中,Anchor Box的尺寸也是有 聚类算法产生的,经过聚类算法,有9个尺寸的Anchor Box,分别为: (10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90), (156x198),(373x326),YOLOV3会在三个预测特征层上进行预测,所以每 个预测特征层都有3个Anchor Box(按照先后顺序排好的,3个为一组,也 就是每个预测特征层有3个Anchor Box)。
| 特征图层 | 特征图大小 | Anchor Box尺寸(修正后) | Anchor Box数量 |
|---|---|---|---|
| 特征图层1(大目标) | 13x13 | (116x90),(156x198),(373x326) | 13x13x3 |
| 特征图层2(中目标) | 26x26 | (30x61),(62x45),(59x119) | 26x26x3 |
| 特征图层3(小目标) | 52x52 | (10x13),(16x30),(33x23) | 52x52x3 |
那么COCO数据集有80类,3x(4+1+80)就得到255了。
三、正负样本分配
3.1、正样本分配原则
与GT BOX的IOU最大的Anchor Box最为正样本。 如果一个Anchor Box与GT BOX的IOU不是最大的,但是又大于某个阈值, 那么就丢掉,既不是正样本又不是负样本。
3.2、负样本分配原则
除去正样本和丢弃的样本剩下的就是负样本。 如果某个Anchor Box不是正样本,那么它就没有定位损失和类别损失, 只有置信度损失。
其实我们可以看出来,这种正负样本分配的方式时有问题的,他会导致正负 样本数量失衡,从而影响训练结果,所以在几年前人们用YOLOV3的时候, 他们选择正样本的方式是:只要某个grid cell中的Anchor Box和GT BOX的 IOU大于某个阈值就视为正样本,这样正样本的数量就更多了。
四、损失函数
原文中没有详细的给出,这里根据源码给出:
YOLOV3的损失函数也包括三部分:定位损失、置信度损失、类别损失。
其中定位损失与YOLOV2是完全一致的。
但是置信度损失、类别损失采用了逻辑回归的策略,正常情况下,要实现多 分类是由Softmax+多元交叉熵组成,但是在YOLOV2中,采用的是 Softmax+回归的思想,这本身就很奇怪了,但是YOLOV3更为震撼,它用了 Softmax+二元交叉熵来解决该问题。
损失函数用了多个独立的用于多标签分类的Logistic分类器,取消了类别之 间的互斥(即one-hot),可以使网络更加灵活。YOLOv2使用Softmax+回 归器,认为一个检测框只属于一个类别,每个检测框分配到概率最大的类 别。但实际场景中一个检测框可能含有多个物体或者有重叠的类别标签。 Logistic分类器主要用到Sigmoid函数,可以将输入约束在0到1的范围内,当 一张图像经过特征提取后的某一检测框类别置信度经过sigmoid函数约束后 如果大于设定的阈值,就表示该检测框负责的物体属于该类别。
4.1、置信度损失

4.2、分类损失
