数据库系统概论(十七)超详细讲解数据库规范化与五大范式(从函数依赖到多值依赖,再到五大范式,附带例题,表格,知识图谱对比带你一步步掌握)
- 前言
- 一、为什么需要规范化
-
- [1. 我们先想一个问题:什么样的数据库表才算好表?](#1. 我们先想一个问题:什么样的数据库表才算好表?)
- [2. 为什么会出现这些问题?](#2. 为什么会出现这些问题?)
- [3. 规范化的目标](#3. 规范化的目标)
- [4. 规范化的核心逻辑](#4. 规范化的核心逻辑)
- [5. 规范化总结](#5. 规范化总结)
- 二、函数依赖
-
- [1. 函数依赖是什么?](#1. 函数依赖是什么?)
- [2. 平凡 vs 非平凡函数依赖](#2. 平凡 vs 非平凡函数依赖)
-
- [2.1 平凡函数依赖「自己决定自己」](#2.1 平凡函数依赖「自己决定自己」)
- [2.2 非平凡函数依赖「决定新信息」](#2.2 非平凡函数依赖「决定新信息」)
- [3. 完全 vs 部分函数依赖](#3. 完全 vs 部分函数依赖)
-
- [3.1 完全函数依赖「缺一不可」](#3.1 完全函数依赖「缺一不可」)
- [3.2 部分函数依赖](#3.2 部分函数依赖)
- [4. 传递函数依赖](#4. 传递函数依赖)
- [5. 函数依赖练习题讲解](#5. 函数依赖练习题讲解)
- [6. 一张图看懂函数依赖关系](#6. 一张图看懂函数依赖关系)
- 三、什么是码?
-
- [1. 码的本质:](#1. 码的本质:)
- [2. 候选码、主码、主属性](#2. 候选码、主码、主属性)
-
- [2.1 候选码](#2.1 候选码)
- [2.2 主码](#2.2 主码)
- [2.3 主属性与非主属性](#2.3 主属性与非主属性)
- [3. 全码、外码](#3. 全码、外码)
-
- [3.1 全码](#3.1 全码)
- [3.2 外码](#3.2 外码)
- [4. 如何求候选码?](#4. 如何求候选码?)
- 总结码的分类与核心作用
- 四、什么是范式?
- 五、第二范式(2NF)
-
- [1. 先搞懂第一范式(1NF)](#1. 先搞懂第一范式(1NF))
- [2. 1NF的问题](#2. 1NF的问题)
- [3. 什么是第二范式(2NF)](#3. 什么是第二范式(2NF))
- [4. 用例子理解2NF](#4. 用例子理解2NF)
- [5. 如何让表符合2NF?](#5. 如何让表符合2NF?)
- [6. 2NF的效果和局限](#6. 2NF的效果和局限)
- 六、第三范式(3NF)
- 七、BCNF
-
- [1. BCNF的核心定义](#1. BCNF的核心定义)
- [2. BCNF的三个"必须"特点](#2. BCNF的三个“必须”特点)
- [3. 通过例子理解BCNF(从符合到不符合)](#3. 通过例子理解BCNF(从符合到不符合))
- [4. BCNF的问题与解决](#4. BCNF的问题与解决)
- [5. 3NF vs BCNF](#5. 3NF vs BCNF)
- [6. 什么时候需要用BCNF?](#6. 什么时候需要用BCNF?)
- 八、多值依赖
-
- [1. Teaching表的冗余困境](#1. Teaching表的冗余困境)
- [2. 什么是多值依赖?](#2. 什么是多值依赖?)
- [3. 多值依赖 vs 函数依赖](#3. 多值依赖 vs 函数依赖)
- [4. 平凡多值依赖 vs 非平凡多值依赖](#4. 平凡多值依赖 vs 非平凡多值依赖)
- [5. 多值依赖的特性](#5. 多值依赖的特性)
- [6. 为什么多值依赖会导致问题?](#6. 为什么多值依赖会导致问题?)
- [7. 如何解决多值依赖?](#7. 如何解决多值依赖?)
- 九、4NF
-
- [1. 4NF的定义](#1. 4NF的定义)
- [2. 对比BCNF与4NF](#2. 对比BCNF与4NF)
- [3. 案例分析:为什么Teaching表不满足4NF?](#3. 案例分析:为什么Teaching表不满足4NF?)
- [2. 分解为4NF](#2. 分解为4NF)
- [4. 例题:WSC表的分解](#4. 例题:WSC表的分解)
-
- [4.1 原表结构:WSC(W, S, C)](#4.1 原表结构:WSC(W, S, C))
- 总结(核心概念速记):
前言
- 在前几期博客中,我们探讨了 SQL 连接查询,单表查询,嵌套查询,集合查询,基于派生表的查询,数据插入,修改与删除,空值的处理,视图,数据库安全性技术等知识点。
- 从本节开始,我们将深入讲解数据库规范化与五大范式。
我的个人主页,欢迎来阅读我的其他文章
https://blog.csdn.net/2402_83322742?spm=1011.2415.3001.5343我的数据库系统概论专栏
https://blog.csdn.net/2402_83322742/category_12911520.html?spm=1001.2014.3001.5482
一、为什么需要规范化
1. 我们先想一个问题:什么样的数据库表才算好表?
- 假设你要设计一个学校教务系统的学生表,需要记录「学号、学院、院长、课程、成绩」。
如果直接把这些信息堆到一张表里(比如下面这张表),乍一看好像没问题,但用起来就会发现许多的问题:
| 学号 | 学院 | 院长 | 课程 | 成绩 |
|---|---|---|---|---|
| S1 | 信息学院 | 张明 | C1 | 95 |
| S2 | 信息学院 | 张明 | C1 | 90 |
| S3 | 信息学院 | 张明 | C1 | 88 |
| ...... | ...... | ...... | ...... | ...... |
这张表有什么毛病?
- 数据冗余到爆炸:每个学生都重复记录「信息学院」「张明」,如果学院改名或换院长,要改几千条数据,漏改一条就出错!
- 插入/删除异常:如果一个新学院刚成立,还没有学生,这张表就没法记录学院和院长(因为学号是必填的);反之,如果某个学院的学生都毕业了,删除学生数据时,学院和院长的信息也会跟着消失。
- 更新麻烦:院长名字改了,需要把所有该学院学生的记录都改一遍,工作量大且容易漏。
2. 为什么会出现这些问题?
- 上面的问题,本质是表中数据之间的「依赖关系」没设计好。
什么是「数据依赖 」?简单说就是:一个数据的值决定了另一个数据的值 。
比如:
- 学号 → 学院(一个学号只能属于一个学院)
- 学院 → 院长(一个学院只有一个正职院长)
- 学号+课程 → 成绩(一个学生选一门课只能有一个成绩)
但在最初的表中,「院长」依赖于「学院」 ,而「学院」又依赖于「学号」。
- 这种多层依赖导致:
| 学号 | 学院 | 院长 | 课程 | 成绩 |
|---|---|---|---|---|
| S1 | 信息学院 | 张明 | C1 | 95 |
| S2 | 信息学院 | 张明 | C1 | 90 |
| S3 | 信息学院 | 张明 | C1 | 88 |
| ...... | ...... | ...... | ...... | ...... |
- 只要号和课程 存在,学院和院长就必须存在(插入异常);
- 只要学号删除,学院和院长可能跟着消失(删除异常);
- 学院或院长的修改需要波及所有相关学号(更新异常)。
3. 规范化的目标
规范化的目标 :通过拆分表,消除不合理的数据依赖,让每张表只干一件事,避免冗余和异常。
比如上面的例子,把原来的「大杂烩表」拆成三张表:
| 学号 | 学院 | 院长 | 课程 | 成绩 |
|---|---|---|---|---|
| S1 | 信息学院 | 张明 | C1 | 95 |
| S2 | 信息学院 | 张明 | C1 | 90 |
| S3 | 信息学院 | 张明 | C1 | 88 |
| ...... | ...... | ...... | ...... | ...... |
- 学生表(学号,学院)------ 只记录学生属于哪个学院,学号唯一决定学院;
| 学号 | 学院 |
|---|---|
| S1 | 信息学院 |
| S2 | 信息学院 |
| S3 | 信息学院 |
| ...... | ...... |
- 学院表(学院,院长)------ 只记录学院和对应的院长,学院唯一决定院长;
| 学院 | 院长 |
|---|---|
| 信息学院 | 张明 |
| ...... | ...... |
- 成绩表(学号,课程,成绩)------ 只记录学生选课的成绩,学号+课程唯一决定成绩。
| 学号 | 课程 | 成绩 |
|---|---|---|
| S1 | C1 | 95 |
| S2 | C1 | 90 |
| S3 | C1 | 88 |
| ...... | ...... | ...... |
这样拆分后:
- 数据冗余减少:院长名字只在学院表中出现一次;
- 插入/删除正常:新学院没学生也能记录,学生毕业不影响学院信息;
- 更新方便:改院长名字只需改学院表中的一条记录。
4. 规范化的核心逻辑
- 发现问题:观察表是否存在「数据冗余、插入/删除异常、更新麻烦」;
- 分析原因:检查数据之间的依赖关系是否「层级混乱」(比如间接依赖导致连锁反应);
- 应用规则:通过「范式」(1NF、2NF、3NF等)逐步拆分表,让每张表满足特定的依赖规则(比如「每个非主键字段只依赖于主键」)。
5. 规范化总结
想象一下,如果没有规范化:
-
数据库会像一团乱麻,修改一个小数据可能引发连锁错误;
-
数据冗余浪费存储空间,还可能导致「脏数据」(比如同个学院名有多个版本);
-
插入和删除操作会受到不必要的限制(比如必须先有学生才能记录学院)。
-
而规范化就像给数据库「分房间」,每个房间(表)只放一类相关的数据,数据之间的依赖关系清晰简单。
-
这样数据库才能又快又准地处理数据,这也是关系型数据库设计的核心思想之一。
二、函数依赖
1. 函数依赖是什么?
类比场景:就像「身份证号→姓名」,一个身份证号只能对应一个人,知道身份证号就能确定姓名。
定义 :在表中,如果属性组 X 的值确定后,属性 Y 的值也被唯一确定,就称 X 函数决定 Y (记作 X→Y)。
函数依赖的特点:
- 唯一性:X 相同则 Y 必须相同(如学号相同,学院必须相同)。
- 语义决定:依赖关系由业务规则决定(如"不允许重名"时,姓名→学号才成立)。
反例 :
下表中 Sno=S1 对应两个不同的 Sname,违背 Sno→Sname函数依赖:
| Sno | Sname | Ssex |
|---|---|---|
| S1 | 张三 | 男 |
| S1 | 李四 | 女 |
2. 平凡 vs 非平凡函数依赖
2.1 平凡函数依赖「自己决定自己」
场景 :在组合键(如「学号+课程号」)中,部分属性决定自身。
例子:
- (学号,课程号)→ 学号
- (学号,课程号)→ 课程号
特点:Y 是 X 的一部分,无实际意义,所有表都默认存在。
2.2 非平凡函数依赖「决定新信息」
场景 :组合键决定其他独立属性。
例子:
- (学号,课程号)→ 成绩(成绩是新信息,不在组合键中)
特点 :需要重点关注,是数据库设计的核心。
3. 完全 vs 部分函数依赖
3.1 完全函数依赖「缺一不可」
定义 :组合键 X 的所有属性必须同时存在,才能决定 Y (缺少任何一个都不行)。
例子:
- (学号,课程号)→ 成绩
✅ 单独学号无法决定成绩(一个学生多门课成绩不同)
✅ 单独课程号无法决定成绩(一门课多个学生成绩不同)
标记 :X → F \overset{F}{\rightarrow} →F Y
3.2 部分函数依赖
定义 :组合键 X 中的某个单属性就能决定 Y ,其他属性多余。
例子:
- (学号,课程号)→ 学院
❌ 单独学号就能决定学院(课程号无关)
标记 :X → P \overset{P}{\rightarrow} →P Y
危害 :导致数据冗余(如一个学生选多门课,学院重复记录)。
4. 传递函数依赖
定义 :若 X→Y 且 Y→Z ,但 Y 不能反推 X ,则 X 传递决定 Z 。
例子:
- 学号→学院,学院→院长
✅ 学号→院长(通过学院间接决定)
❌ 学院不能反推学号(一个学院有多个学生)
标记 :X → T \overset{T}{\rightarrow} →T Z
危害:更新异常(如院长离职,需修改所有该学院学生的记录)。
5. 函数依赖练习题讲解
关键符号注释
- → F \overset{F}{\rightarrow} →F:完全函数依赖
例:组合键 (A,B) 必须全用上才能得到 C - → P \overset{P}{\rightarrow} →P:部分函数依赖
例:组合键 (A,B) 中,A 单独就能得到 C,B 多余 - → T \overset{T}{\rightarrow} →T:传递函数依赖
例:A 决定 B,B 决定 C,但 B 不能决定 A,所以 A 传递决定 C
练习1:职工关系
题目描述:
给定职工关系表如下,分析其中的函数依赖
| 职工号 | 职工名 | 年龄 | 性别 | 单位号 | 单位名 |
|---|---|---|---|---|---|
| E1 | ZHAO | 20 | F | D3 | CCC |
| E2 | QIAN | 25 | M | D1 | AAA |
函数依赖:
- 职工号→职工名/年龄/性别/单位号(职工号唯一)
- 单位号→单位名(单位不重名)
- 职工号 → T \overset{T}{\rightarrow} →T 单位名(通过单位号传递)
练习2:工程管理关系
题目描述:
给定工程管理关系表如下,分析其中的函数依赖
| 工程号 | 材料号 | 数量 | 开工日期 | 完工日期 | 价格 |
|---|---|---|---|---|---|
| P1 | I1 | 4 | 200510 | 200608 | 250 |
| P1 | I2 | 6 | 200510 | 200608 | 300 |
函数依赖:
- (工程号,材料号) → F \overset{F}{\rightarrow} →F 数量(完全依赖,缺一不可)
- 工程号→开工日期/完工日期(部分依赖,单独工程号决定)
- 材料号→价格(单独材料号决定,与工程无关)
6. 一张图看懂函数依赖关系
| 分类 | 类型 | 核心定义 | 典型例子 | 记忆技巧 |
|---|---|---|---|---|
| 按内容有无意义 | 平凡函数依赖 | Y 是 X 的一部分(自己决定自己的一部分) | (学号, 课程号) → 学号 (A,B) → A | "多余的依赖",默认存在,不用管 |
| 非平凡函数依赖 | Y 不是 X 的一部分(决定了新的信息) | (学号, 课程号) → 成绩 (A,B) → C | "有用的依赖",重点关注 | |
| ---------------- | ---------------- | -------------------------------------------- | -------------------------------------------- | ---------------------------------- |
| 按依赖强度 | 完全函数依赖 | X 的所有属性必须同时存在,才能决定 Y(缺一不可) | (学号, 课程号) → F \overset{F}{\rightarrow} →F 成绩 | "全靠组合键,少一个都不行" |
| 部分函数依赖 | X 中的某个单属性就能决定 Y(其他属性多余) | (学号, 课程号) → P \overset{P}{\rightarrow} →P 学院 | "部分属性就够了,其他是摆设" | |
| ---------------- | ---------------- | -------------------------------------------- | -------------------------------------------- | ---------------------------------- |
| 按传递性 | 传递函数依赖 | X 先决定 Y,Y 再决定 Z(Y 不能反推 X) | 学号 → 学院 → 院长 → 学号 → T \overset{T}{\rightarrow} →T 院长 | "拐个弯才能决定,中间有跳板" |
三、什么是码?
1. 码的本质:
在数据库中,码 就像"身份证号",用来唯一标识一条数据记录。
比如:
- 一个班级里,每个学生有唯一的"学号",学号就是区分学生的"码"。
- 一张成绩单里,可能需要"学号+课程号"组合起来,才能唯一确定某个人的某门课成绩,这个组合就是"码"。
2. 候选码、主码、主属性
2.1 候选码
-
定义 :能唯一标识一条记录的最小属性或属性组合。
- "最小"意味着去掉任何一个属性,就无法唯一标识记录了。
-
例子:
- 职工表 (见下表)中,"职工号"唯一(E1、E2...不重复),因此职工号是候选码。
职工号 职工名 年龄 性别 单位号 单位名 E1 ZHAO 20 F D3 CCC - 工程表 中,单独"工程号"或"材料号"都有重复(如P1对应I1、I2等),但工程号+材料号组合唯一 ,因此工程号+材料号是候选码。
工程号 材料号 数量 开工日期 完工日期 价格 P1 I1 4 200510 200608 250
2.2 主码
-
定义:从多个候选码中选一个作为"主负责人",用来代表该表的记录。
-
特点 :
- 每个表必须有且仅有一个主码。
- 主码的值不能重复、不能为空(就像学号不能重复,也不能没有学号)。
-
例子 :
职工号 职工名 年龄 性别 单位号 单位名 E1 ZHAO 20 F D3 CCC - 职工表中候选码只有"职工号",因此主码就是职工号。
- 如果一个表有多个候选码(如学生表中"学号"和"身份证号"都是候选码),选其中一个作为主码即可。
2.3 主属性与非主属性
-
主属性 :包含在任何一个候选码中的属性 。
职工号 职工名 年龄 性别 单位号 单位名 E1 ZHAO 20 F D3 CCC - 例如职工表中"职工号"是候选码,因此"职工号"是主属性。
- 工程表中"工程号"和"材料号"都是候选码的一部分,因此都是主属性。
-
非主属性 :不包含在任何候选码中的属性 。
- 例如职工表中的"职工名""年龄"等,不能用来唯一标识记录,因此是非主属性。
3. 全码、外码
3.1 全码
-
定义 :当整个属性组(所有列)共同构成候选码时,称为全码。
-
场景:表中没有任何单个或部分属性能唯一标识记录,必须用所有属性组合。
-
例子 :
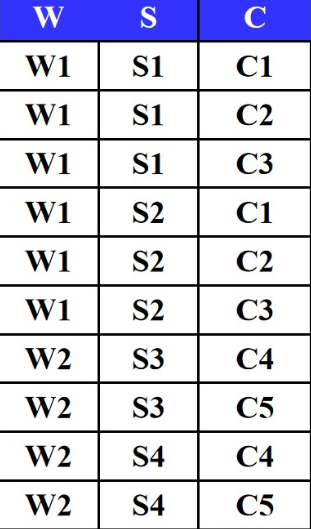
- 关系模式WSC(仓库W,保管员S,商品C)
- 语义:每个仓库的每个保管员保管所有商品(如W1仓库的S1保管员保管C1、C2、C3)。
- 分析:
- 单独"W"无法唯一标识记录(W1对应多个S和C)。
- "W+S"也无法唯一标识(W1+S1对应多个C)。
- 必须用W+S+C三者组合 才能唯一确定一条记录,因此全码是W+S+C。
- 关系模式WSC(仓库W,保管员S,商品C)
3.2 外码
-
定义 :当前表中的某个属性(或属性组)不是本表的码 ,但是另一个表的主码,称为外码。
-
作用:用于建立表之间的关联(如职工表和单位表通过"单位号"关联)。
-
例子:
职工号 职工名 年龄 性别 单位号 单位名 E1 ZHAO 20 F D3 CCC - 职工表中的"单位号"(D3、D1等)不是职工表的码(职工表的码是职工号),但它是"单位表"的主码(假设单位表用单位号唯一标识),因此单位号是职工表的外码。
4. 如何求候选码?
步骤:
- 找唯一标识的属性/组合:看哪些列或列组合能唯一确定一行数据。
- 验证最小性:去掉其中一个属性,看是否还能唯一标识(能的话就不是最小组合)。
实例1:职工表
| 职工号 | 职工名 | 年龄 | 性别 | 单位号 | 单位名 |
|---|---|---|---|---|---|
| E1 | ZHAO | 20 | F | D3 | CCC |
- 列:职工号、职工名、年龄、性别、单位号、单位名
- 唯一列:职工号(无重复)
- 结论:候选码=职工号
实例2:工程表
| 工程号 | 材料号 | 数量 | 开工日期 | 完工日期 | 价格 |
|---|---|---|---|---|---|
| P1 | I1 | 4 | 200510 | 200608 | 250 |
| P1 | I2 | 6 | 200510 | 200608 | 300 |
- 列:工程号、材料号、数量、开工日期、完工日期、价格
- 单独列:工程号(重复,如P1出现多次),材料号(重复,如I1出现多次)
- 组合列:工程号+材料号(唯一,每个组合对应唯一一行)
- 结论:候选码=工程号+材料号
实例3:WSC表
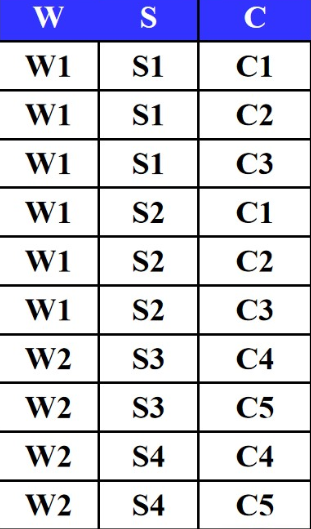
- 列:W(仓库)、S(保管员)、C(商品)
- 单独列:W、S、C均重复(如W1对应多个S和C)
- 两列组合:W+S(对应多个C),W+C(对应多个S),S+C(对应多个W)
- 三列组合:W+S+C(唯一)
- 结论:全码=W+S+C
总结码的分类与核心作用
| 类型 | 定义 | 例子(职工表) |
|---|---|---|
| 候选码 | 能唯一标识记录的最小属性/组合 | 职工号 |
| 主码 | 从候选码中选一个作为代表 | 职工号(唯一候选码,直接选) |
| 主属性 | 包含在候选码中的属性 | 职工号 |
| 全码 | 所有属性共同构成候选码 | WSC表中的W+S+C |
| 外码 | 本表中非码属性,但是另一个表的主码 | 单位号(对应单位表的主码) |
四、什么是范式?
为什么需要范式?
假设你设计了一张"学生选课表",记录学生、课程和成绩,但发现:
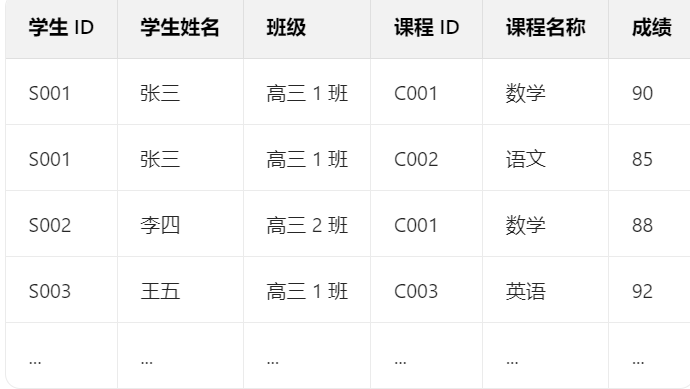
- 数据冗余:同一个学生的姓名、班级重复出现多次。
- 插入异常:如果一个学生还没选课,就无法记录他的姓名和班级。
- 更新麻烦:修改学生班级时,需要更新所有相关行,容易漏改。
- 删除风险:删除某门课的所有记录,可能连学生信息也一起删掉了。
范式就是一套规则,用来规范表格设计,解决上述问题。
核心思路:通过"分表"(模式分解),让表格更"纯净",减少冗余和异常。
五、第二范式(2NF)
1. 先搞懂第一范式(1NF)
1NF是关系型数据库的最低门槛,它只有一个要求:
-
表中每个字段(属性)必须是最小单元,不能再拆分 。
✅ 正确示例(职工表):
职工ID 姓名 年龄 001 张三 25 (每个字段都是"不可分割"的数据,比如"姓名"不能拆成"姓"和"名"存放在同一列) ❌ 错误示例(科目余额表):
科目 余额(元/角) 现金 100/5 ("余额"拆成了"元"和"角",违反1NF,不能称为合法的关系表)
2. 1NF的问题
即便满足1NF,表结构仍可能有问题。比如:
学生选课表(S-L-C)(仅满足1NF):
| 学号(Sno) | 学院(School) | 宿舍(Sloc) | 课程号(Cno) | 成绩(Grade) |
|---|---|---|---|---|
| S1 | 信息学院 | 2号楼 | C3 | 89 |
| S2 | 信息学院 | 2号楼 | C2 | 97 |
| S3 | 计算机学院 | 3号楼 | C1 | 86 |
看起来没问题,但藏着3个大坑:
- 数据冗余:同一个学院的学生,"学院"和"宿舍"反复重复(如信息学院重复多次)。
- 插入异常:如果一个学生还没选课(Cno为空),就无法插入这条记录(因为"学号+课程号"是主键,不能有空)。
- 删除异常:如果删除某门课程的所有记录,可能连学生的学院和宿舍信息也一起删掉了。
3. 什么是第二范式(2NF)
2NF的核心规则:
- 前提:必须先满足1NF。
- 规则 :表中非主属性(不是主键的字段)必须完全依赖于主键,不能只依赖主键的"一部分"。
回顾完全依赖与部分依赖
- 主键(候选码):能唯一标识一条记录的字段或字段组合(比如"学号+课程号")。
- 完全依赖 :非主属性必须依赖于整个主键 ,缺一不可。
例:成绩(Grade)必须由"学号+课程号"共同决定(一个学生选不同课程有不同成绩)。 - 部分依赖 :非主属性只依赖于主键的一部分 。
例:学院(School)只依赖于"学号"(一个学生属于一个学院,和课程无关),这就是"部分依赖"(依赖主键中的"学号",而非整个"学号+课程号")。
4. 用例子理解2NF
表结构:
| 学号(Sno) | 学院(School) | 宿舍(Sloc) | 课程号(Cno) | 成绩(Grade) |
|---|---|---|---|---|
| S1 | 信息学院 | 2号楼 | C3 | 89 |
| S2 | 信息学院 | 2号楼 | C2 | 97 |
| S3 | 计算机学院 | 3号楼 | C1 | 86 |
- 主键:(学号,课程号)(Sno, Cno)
- 非主属性:学院(School)、宿舍(Sloc)、成绩(Grade)
函数依赖关系:
- 成绩完全依赖主键:
(学号, 课程号) → 成绩(必须两个字段一起才能确定成绩)。 - 学院部分依赖主键:
学号 → 学院(只用学号就能确定学院,课程号多余)。 - 宿舍通过学院传递依赖学号:
学号 → 学院 → 宿舍(本质还是部分依赖主键中的学号)。
结论 :存在非主属性(学院、宿舍)对主键的部分依赖 ,所以 S-L-C表只满足1NF,不满足2NF。
5. 如何让表符合2NF?
解决思路 :把有部分依赖的字段拆到另一个表,确保每个表的非主属性都完全依赖主键。
拆分后的两张表:
表1:学生选课表(SC)------ 专注成绩
| 学号(Sno) | 课程号(Cno) | 成绩(Grade) |
|---|---|---|
| S1 | C3 | 89 |
| S2 | C2 | 97 |
- 主键:(学号,课程号)
- 非主属性:成绩(完全依赖主键,符合2NF)。
表2:学生学院表(S-L)------ 专注学院和宿舍
| 学号(Sno) | 学院(School) | 宿舍(Sloc) |
|---|---|---|
| S1 | 信息学院 | 2号楼 |
| S3 | 计算机学院 | 3号楼 |
- 主键:学号(单个字段为主键)
- 非主属性:学院、宿舍(完全依赖学号,符合2NF)。
6. 2NF的效果和局限
拆分后的好处:
- 数据冗余减少:学院和宿舍信息只存一次,不再随课程重复。
- 插入/删除更灵活:学生没选课时,可先在S-L表插入学号、学院等信息;删除课程不影响学生基本信息。
但2NF不是终点:
- S-L表中仍存在"传递依赖":
学号 → 学院 → 宿舍(宿舍依赖学院,学院依赖学号),这会导致新的冗余(如学院搬迁,所有该学院学生的宿舍都要修改)。 - 后续需要3NF进一步优化
六、第三范式(3NF)
2NF解决了「部分函数依赖」的问题 ,但可能还存在「传递函数依赖」的问题,而 3NF就是用来解决这个问题的。
1. 什么是3NF?
一句话总结 :
如果一个表满足 2NF ,并且 非主属性之间不能有「传递依赖」 ,那它就属于 3NF。
关键概念:
- 传递依赖 :如果 A → B ,B → C ,且 B 不能反过来决定 A ,那么 C 就通过 B 传递依赖于 A 。
(比如:"学生学号 → 学院 → 学院地址","学院地址"就传递依赖于"学生学号")
2. 为什么需要3NF?
假设我们有一个满足 2NF 的表 S-L(Sno, School, Sloc) (学生学号,学院,学院地址):
| Sno | School | Sloc |
|---|---|---|
| S1 | 信息学院 | 教学楼2 |
| S2 | 信息学院 | 教学楼2 |
| S3 | 计算机学院 | 教学楼3 |
这个表存在什么问题?
- 数据冗余 :同一个学院的地址重复出现(比如"信息学院"的地址重复多次)。
- 更新麻烦:如果信息学院搬了新地址,需要修改所有相关行,漏改就会数据不一致。
- 插入/删除异常 :
- 插入:如果新成立一个学院但还没有学生,无法插入学院和地址(因为学号是主键,不能为空)。
- 删除:如果删除某个学院的所有学生,学院和地址信息也会被删掉。
问题的根源:传递函数依赖
- 表中的函数依赖关系:
- Sno → School(学号决定学院)
- School → Sloc(学院决定地址)
- 因此:Sno → School → Sloc ,即 Sloc(地址)通过 School(学院)传递依赖于 Sno(学号)。
- 这违反了 3NF 的要求(非主属性不能传递依赖于主键)。
3. 如何让表满足3NF?
解决方法:把有传递依赖的表拆分成两张表,消除传递依赖。
拆分后的两张表:
-
学生-学院表 S-D(Sno, School)
Sno School S1 信息学院 S2 信息学院 S3 计算机学院 - 主键:Sno
- 依赖关系:Sno → School(直接依赖,无传递)
-
学院-地址表 D-L(School, Sloc)
School Sloc 信息学院 教学楼2 计算机学院 教学楼3 - 主键:School
- 依赖关系:School → Sloc(直接依赖,无传递)
拆分后的好处:
- 数据冗余减少:学院地址只在 D-L 表中存一次。
- 更新方便:修改学院地址时,只需改 D-L 表中的一行。
- 插入/删除正常 :
- 可以先插入学院和地址(即使没有学生)到 D-L 表。
- 删除学生时,不影响学院和地址信息。
4. 总结:
- 3NF是2NF的升级版 :
- 先满足 1NF (属性不可拆分),再满足 2NF (消除部分依赖),最后满足 3NF(消除传递依赖)。
- 核心原则 :
- 非主属性必须直接依赖于主键,不能通过其他非主属性间接依赖。
- 不足 :
- 3NF 不能完全消除所有问题(比如多值依赖,需要更高的范式如 BCNF),但对大多数业务场景已足够。
5. 对比1NF→2NF→3NF:
| 范式 | 解决的问题 | 举例(学生相关表) |
|---|---|---|
| 1NF | 属性不可拆分 | 把"姓名+电话"拆成独立字段 |
| 2NF | 消除部分依赖 | 把"学生-课程-学院"拆成学生课程表和学生学院表 |
| 3NF | 消除传递依赖 | 把"学生-学院-地址"拆成学生学院表和学院地址表 |
一句话记忆:
- 1NF:字段不能再分;
- 2NF:主键能完全决定所有非主属性;
- 3NF:非主属性之间不能"接力决定"。
七、BCNF
1. BCNF的核心定义
BCNF是比3NF更严格的数据库设计规范 ,它的核心要求就一句话:
每个能"决定"其他属性的属性或属性组(决定因素),都必须包含码(主键或候选键) 。
用大白话来讲就是:
如果属性X能唯一确定属性Y(即X→Y),那么X必须是"老大"(码),不能是"小弟"(非码属性)。
2. BCNF的三个"必须"特点
| 特点 | 3NF | BCNF |
|---|---|---|
| 非主属性依赖 | 消除了对码的部分依赖和传递依赖 | 同样满足 |
| 主属性依赖 | 可能存在主属性对码的部分/传递依赖 | 必须消除主属性对码的部分/传递依赖 |
| 决定因素要求 | 允许非码的决定因素存在 | 禁止非码的决定因素存在 |
关键区别:
- 3NF只约束"非主属性",而BCNF同时约束"主属性"和"决定因素"。
- 可以说,BCNF是3NF的"加强版",解决了3NF可能残留的依赖问题。
3. 通过例子理解BCNF(从符合到不符合)
例子1:Course表(符合BCNF)
Course(Cno, Cname, Ccredit, Cpno)| Cno | Cname | Ccredit | Cpno |
|---|---|---|---|
| C001 | 数据库基础 | 3 | NULL |
| C002 | 数据结构 | 4 | C001 |
| C003 | 操作系统 | 3 | C002 |
| C004 | 计算机网络 | 3 | C001 |
| C005 | 软件工程 | 4 | C003 |
- 码:Cno(课程号)
- 函数依赖 :
Cno→Cname(课程号决定课程名)
Cno→Ccredit(课程号决定学分)
Cno→Cpno(课程号决定先修课) - 分析 :
所有决定因素都是码(Cno),满足"决定者必须是老大",所以 Course∈BCNF。
例子2:Student表(符合BCNF)
Student(Sno, Sname, Ssex, Sbirthdate, Smajor)| Sno | Sname | Ssex | Sbirthdate | Smajor |
|---|---|---|---|---|
| S1 | 张三 | 男 | 2003-05-12 | 信息管理与信息系统 |
| S2 | 李四 | 女 | 2004-02-28 | 数据科学与大数据技术 |
| S3 | 王五 | 男 | 2003-11-03 | 计算机科学与技术 |
| S4 | 赵六 | 女 | 2004-08-15 | 软件工程 |
| S5 | 陈七 | 男 | 2003-07-09 | 信息安全 |
- 业务规则 :学生不重名,所以 候选码有两个:Sno和Sname。
- 函数依赖 :
Sno→Sname, Ssex,...(学号决定其他属性)
Sname→Sno, Ssex,...(姓名决定其他属性) - 分析 :
无论用Sno还是Sname作为决定因素,它们都是码,因此 Student∈BCNF。
例子3:STJ表(不符合BCNF)
STJ(S, T, J) (学生,教师,课程)| S | T | J |
|---|---|---|
| 001 | T1 | 操作系统 |
| 001 | T2 | 微机原理 |
| 001 | T3 | 数据结构 |
| 002 | T4 | 操作系统 |
| 003 | T1 | 操作系统 |
| 004 | T1 | 操作系统 |
| ...... | ...... | ...... |
- 业务规则 :
- 每个教师只教一门课(T→J)
- 每门课可由多个教师授课
- 学生选课后,教师和课程相互确定(S+J→T,S+T→J)
- 候选码:(S,J) 和 (S,T)(两个属性组合才能唯一确定一条记录)
- 函数依赖 :
- (S,J)→T(学生+课程决定教师)
- (S,T)→J(学生+教师决定课程)
- T→J(教师决定课程,重点!)
- 问题 :
- 决定因素T(教师)不是码(码是S+J或S+T),但T→J成立。
- 这违反了BCNF的规则:非码的T居然能决定J!
- 结论 :STJ∉BCNF,但STJ∈3NF(因为非主属性不存在传递依赖)。
4. BCNF的问题与解决
STJ表的问题(不符合BCNF的后果)
- 数据冗余:教师T1教课程J1,若有100个学生选T1的课,J1会重复100次。
- 更新麻烦:若T1改教J2,需修改所有相关记录,否则数据不一致。
- 插入/删除异常:新教师还没学生选课时,无法插入其授课信息。
解决方法:分解成两个BCNF表
-
ST表(学生-教师)
ST(S, T) (候选码:(S,T)) 函数依赖:(S,T)→ 无其他属性(直接依赖码) -
TJ表(教师-课程)
TJ(T, J) (候选码:T) 函数依赖:T→J(决定因素T是码,符合BCNF)
- 结果 :
- 每个表的决定因素都是码,ST∈BCNF,TJ∈BCNF。
- 数据冗余和异常问题消失。
5. 3NF vs BCNF
- 3NF:只保证"非主属性不依赖非码",但允许"主属性依赖非码"。
- BCNF:进一步要求"所有决定因素必须是码",彻底消除主属性和非主属性对非码的依赖。
关系:
- 所有BCNF表都属于3NF,但3NF表不一定属于BCNF。
- BCNF是函数依赖范围内"最彻底"的规范化,能最大程度避免数据问题。
6. 什么时候需要用BCNF?
- 当你的表中存在"主属性依赖非码属性"时(如STJ中的T→J),就需要用BCNF规范来分解表。
- 大部分业务场景中,3NF已足够,但在高并发、数据敏感的系统(如金融、医疗)中,常需进一步优化到BCNF。
八、多值依赖
1. Teaching表的冗余困境
假设我们有一张 课程-教员-参考书表(Teaching),记录每门课程的授课老师和使用的参考书:
| 课程(C) | 教员(T) | 参考书(B) |
|---|---|---|
| 物理 | 李勇 | 普通物理学 |
| 物理 | 李勇 | 光学原理 |
| 物理 | 李勇 | 物理习题集 |
| 物理 | 王军 | 普通物理学 |
| 物理 | 王军 | 光学原理 |
| 物理 | 王军 | 物理习题集 |
| 数学 | 李勇 | 数学分析 |
| ... | ... | ... |
这张表看起来符合BCNF,却有大问题:
- 数据爆炸式冗余 :
- 物理课有2个老师,3本参考书,导致 2×3=6条记录,每增加一个老师或参考书,记录数就会相乘增长。
- 更新麻烦 :
- 若物理课新增一本参考书,需要为每个老师单独新增一条记录(如李勇+王军都要关联新书)。
- 插入/删除限制 :
- 新增老师时,必须同时关联所有参考书;删除某本参考书时,可能误删其他老师的关联记录。
为什么BCNF解决不了这个问题?
因为这里的问题不是函数依赖(如"课程→教员"不成立,一门课有多个教员),而是 多值依赖(Multiple-Valued Dependency)。
2. 什么是多值依赖?
定义 :
当表中存在三个属性 X、Y、Z,且满足:
- 给定一个 X 值,对应的 Y 值与 Z 值无关,即 Y 和 Z 各自独立地"多对多"依赖于 X 。
这种依赖关系称为 多值依赖 ,记作 X →→ Y(读作"X多值决定Y")。
举个例子:
- X=课程(C) ,Y=教员(T) ,Z=参考书(B)
| 课程(C) | 教员(T) | 参考书(B) |
|---|---|---|
| 物理 | 李勇 | 普通物理学 |
| 物理 | 李勇 | 光学原理 |
| 物理 | 李勇 | 物理习题集 |
| 物理 | 王军 | 普通物理学 |
| 物理 | 王军 | 光学原理 |
| 物理 | 王军 | 物理习题集 |
| 数学 | 李勇 | 数学分析 |
- 对于课程"物理"(X=物理):
- 教员集合 {李勇, 王军} 只与课程有关,与参考书无关(不管用什么书,教员都是这两人)。
- 参考书集合 {普通物理学, 光学原理, 物理习题集} 也只与课程有关,与教员无关(不管谁来教,书都是这几本)。
- 因此:C →→ T 且 C →→ B(课程多值决定教员和参考书)。
3. 多值依赖 vs 函数依赖
| 类型 | 依赖关系 | 例子(Teaching表) |
|---|---|---|
| 函数依赖 | X → Y(X唯一决定Y) | 若"课程→学分",则一门课只有一个学分 |
| 多值依赖 | X →→ Y(X决定一组Y值) | 一门课可以有多个教员,且与参考书无关 |
核心区别:
- 函数依赖是"一对一"或"一对多",多值依赖是"一对多对多"(Y和Z互相独立)。
- 多值依赖中,Y的取值只与X有关,与Z无关;反之亦然。
4. 平凡多值依赖 vs 非平凡多值依赖
- 平凡多值依赖 :若 Y是X的子集 (Y⊆X),或 Y∪X=U (Y和X包含所有属性),则依赖无实际意义。
- 例:表中若有"学生S→→课程 C"(课程是学生的属性),属于平凡依赖。
| S | C |
|---|---|
| S1 | 数学 |
| S1 | 英语 |
| S2 | 数学 |
| S2 | 英语 |
- 非平凡多值依赖:Y既不是X的子集,也不包含所有其他属性。
| 课程(C) | 教员(T) | 参考书(B) |
|---|---|---|
| 物理 | 李勇 | 普通物理学 |
| 物理 | 李勇 | 光学原理 |
| 物理 | 李勇 | 物理习题集 |
| 物理 | 王军 | 普通物理学 |
| 物理 | 王军 | 光学原理 |
| 物理 | 王军 | 物理习题集 |
| 数学 | 李勇 | 数学分析 |
- Teaching表中的 C→→T 和 C→→B 均为非平凡多值依赖(T和B都不是C的子集,且还有其他属性)。
5. 多值依赖的特性
- 对称性 :若 X→→Y ,则 X→→Z (Z是除X、Y外的属性)。
- Teaching表中,C→→T成立,则C→→B必然成立(Z=B)。
| 课程(C) | 教员(T) | 参考书(B) |
|---|---|---|
| 物理 | 李勇 | 普通物理学 |
| 物理 | 李勇 | 光学原理 |
| 物理 | 李勇 | 物理习题集 |
| 物理 | 王军 | 普通物理学 |
| 物理 | 王军 | 光学原理 |
| 物理 | 王军 | 物理习题集 |
| 数学 | 李勇 | 数学分析 |
-
传递性 :若 X→→Y 且 Y→→Z ,则 X→→Z-Y。
- (较复杂,可暂不深究,记住多值依赖可传递即可)
-
函数依赖是多值依赖的特例 :若 X→Y ,则必然有 X→→Y。
- 例:"学号→姓名"是函数依赖,也是平凡多值依赖(Y⊆X吗?不,这里Y是姓名,X是学号,所以是特殊的多值依赖)。
6. 为什么多值依赖会导致问题?
Teaching表的问题根源在于:
- 教员和参考书之间没有直接关系,它们的组合(如"李勇+普通物理学"、"王军+光学原理")是"多余的",仅因课程关联而被迫存在。
- 这种"无关属性的强行组合"导致数据冗余,而BCNF无法处理这种依赖(BCNF只约束函数依赖)。
7. 如何解决多值依赖?
步骤 :将存在非平凡多值依赖的表分解为两张表,消除依赖。
Teaching表分解后:
-
课程-教员表(C-T)
课程(C) 教员(T) 物理 李勇 物理 王军 - 依赖:C→→T(多值依赖存在,但表中仅两列,属于平凡多值依赖,无冗余)。
-
课程-参考书表(C-B)
课程(C) 参考书(B) 物理 普通物理学 物理 光学原理 - 依赖:C→→B(同理,平凡多值依赖)。
效果:
- 记录数从6条减少到2+3=5条(实际业务中数据量越大,优化越明显)。
- 新增教员或参考书时,只需在对应表中单独操作,无需交叉组合。
九、4NF
1. 4NF的定义
关系模式R满足:所有非平凡多值依赖的"决定因素"X都必须包含码,则R∈4NF。
- 码:能唯一确定一条记录的属性或属性组(如"学号"是学生表的码)。
- 核心要求:不允许存在"非平凡且非函数依赖的多值依赖"。
2. 对比BCNF与4NF
| 范式 | 处理对象 | 要求 |
|---|---|---|
| BCNF | 函数依赖 | 所有非平凡函数依赖的决定因素是码 |
| 4NF | 多值依赖 | 所有非平凡多值依赖的决定因素是码 |
- 关系:4NF是BCNF的"升级版",先满足BCNF,再处理多值依赖。
3. 案例分析:为什么Teaching表不满足4NF?
-
数据示例 :
C(课程) T(教师) B(教材) 物理 李勇 普通物理学 物理 李勇 光学原理 物理 王军 普通物理学 物理 王军 光学原理 -
问题 :
- 存在非平凡多值依赖:C→→T 和 C→→B(T和B独立,且C不是码)。
- 码:(C, T, B)(三者组合唯一,但单个C无法确定记录)。
- 结论:Teaching∈BCNF(无不良函数依赖),但∉4NF(存在非平凡多值依赖且决定因素无码)。
2. 分解为4NF
-
CT表(C, T):
C(课程) T(教师) 物理 李勇 物理 王军 数学 李勇 - 多值依赖:C→→T(平凡,因C∪T={C,T}=表属性),允许存在。
- 码:(C, T)(但决定因素C虽非码,依赖是平凡的,符合4NF)。
-
CB表(C, B):
C(课程) B(教材) 物理 普通物理学 物理 光学原理 数学 数学分析 - 多值依赖:C→→B(平凡,因C∪B={C,B}=表属性),允许存在。
- 结论:CT和CB均∈4NF,消除了多值依赖带来的冗余。
4. 例题:WSC表的分解
4.1 原表结构:WSC(W, S, C)
| W | S | C |
|---|---|---|
| W1 | S1 | C1 |
| W1 | S1 | C2 |
| W1 | S2 | C1 |
| W1 | S2 | C2 |
| W2 | S3 | C3 |
| W2 | S3 | C4 |
| W2 | S4 | C3 |
| W2 | S4 | C4 |
- 含义:W(仓库)、S(保管员)、C(商品),一个仓库有多个保管员和商品,且保管员与商品无关。
- 问题 :
- 非平凡多值依赖:W→→S 和 W→→C(W不是码,码是(W, S, C))。
- 分解:拆分为WS(W, S)和WC(W, C),每个表中的多值依赖变为平凡(如W→→S在WS表中是平凡的),满足4NF。
总结(核心概念速记):
核心概念速记
数据库规范化 = 数据依赖分析 + 范式分层约束 + 模式分解实践
-
规范化目标:
- 消除数据冗余、插入/删除异常、更新异常 ,通过模式分解让表结构更"纯净"。
- 核心逻辑:发现依赖层级混乱 → 应用范式规则 → 逐步拆分表。
-
数据依赖体系:
- 函数依赖 :X→Y(X唯一决定Y),分为平凡/非平凡、完全/部分、传递三类。
- 多值依赖:X→→Y(X决定一组独立的Y值,与其他属性无关)。
-
范式阶梯(从低到高):
范式 核心规则 解决的问题 1NF 属性不可拆分(最低要求) 字段原子性 2NF 非主属性完全依赖主键(消除部分依赖) 部分依赖导致的冗余 3NF 非主属性无传递依赖(消除传递依赖) 传递依赖导致的冗余 BCNF 所有决定因素包含码(强化3NF,约束主属性依赖) 主属性对非码的依赖 4NF 非平凡多值依赖的决定因素包含码(处理多值依赖) 多值依赖导致的爆炸式冗余
规范化关键对比
| 问题类型 | 依赖类型 | 解决范式 | 典型分解案例 |
|---|---|---|---|
| 字段可拆分 | --- | 1NF | 拆"姓名+电话"为独立字段 |
| 部分依赖 | 非主属性依赖主键部分属性 | 2NF | 学生选课表拆分为SC(成绩)和S-L(学院) |
| 传递依赖 | 非主属性→非主属性→码 | 3NF | 学生学院表拆分为S-D(学生-学院)和D-L(学院-地址) |
| 主属性依赖非码 | 主属性→非码属性 | BCNF | STJ表拆分为ST(学生-教师)和TJ(教师-课程) |
| 多值依赖冗余 | 非平凡多值依赖 | 4NF | Teaching表拆分为CT(课程-教师)和CB(课程-教材) |
知识图谱
数据库规范化与五大范式
├─ 规范化基础
│ ├─ 问题驱动:冗余/异常 → 依赖分析
│ ├─ 函数依赖:平凡/非平凡、完全/部分、传递
│ └─ 码体系:候选码/主码/全码/外码
├─ 范式阶梯
│ ├─ 1NF:属性原子性
│ ├─ 2NF:消除部分依赖
│ ├─ 3NF:消除传递依赖
│ ├─ BCNF:强化决定因素约束
│ └─ 4NF:处理多值依赖
├─ 核心操作
│ ├─ 模式分解:垂直拆分(按依赖类型)
│ └─ 依赖验证:通过函数依赖图/多值依赖表
└─ 典型场景
├─ 学生管理:从1NF到3NF的逐步优化
├─ 课程教学:BCNF与4NF的多表分解
└─ 多对多关系:通过全码/外码建立关联 重点提炼
-
函数依赖核心判断:
- 完全依赖:组合键缺一不可(如学号+课程号→成绩)。
- 传递依赖:中间有"跳板"属性(如学号→学院→院长)。
-
范式升级关键点:
- 2NF vs 3NF:前者处理部分依赖,后者处理传递依赖。
- BCNF vs 3NF:前者约束所有决定因素(含主属性),后者仅约束非主属性。
- 4NF独特点:专门解决多值依赖导致的"属性独立组合冗余"。
-
分解原则:
- 保持函数依赖:分解后原依赖关系不丢失。
- 无损连接:分解后的表通过自然连接可还原原表数据。
-
应用建议:
- 一般业务达到3NF即可满足需求。
- 高并发或数据敏感系统(如金融、电商)需考虑BCNF/4NF。
依赖类型与范式对应表
| 依赖类型 | 是否允许存在(各范式) | 处理方式 |
|---|---|---|
| 平凡函数依赖 | 所有范式均允许 | 无需处理 |
| 非平凡函数依赖 | 需决定因素是码(BCNF+) | 分解表使决定因素包含码 |
| 部分函数依赖 | 1NF允许,2NF+禁止 | 拆分表消除对主键部分依赖 |
| 传递函数依赖 | 1NF/2NF允许,3NF+禁止 | 拆分表打断传递链 |
| 非平凡多值依赖 | BCNF允许,4NF禁止 | 拆分表使多值依赖平凡化 |
技术演进脉络
表设计演进 ------ 大杂烩表(1NF) → 消除部分依赖(2NF) → 消除传递依赖(3NF)
↓ ↓ ↓
↓ ├─ 强化主属性约束(BCNF) → 处理多值依赖(4NF)
↓ ↓
应用场景 ------ 简单业务 → 复杂业务(含多对多关系) → 高并发/高冗余场景 经典例题速解
例题 :判断关系模式R(A,B,C,D),若函数依赖为A→B, B→C,码为A,属于第几范式?
分析:
- 非主属性C通过B传递依赖于A(A→B→C),存在传递依赖。
- 结论:满足2NF(非主属性完全依赖A),但不满足3NF(存在传递依赖),故R∈2NF。
以上就是这篇博客的全部内容,下一篇我们将继续探索更多精彩内容。
我的个人主页,欢迎来阅读我的其他文章
https://blog.csdn.net/2402_83322742?spm=1011.2415.3001.5343我的数据库系统概论专栏
https://blog.csdn.net/2402_83322742/category_12911520.html?spm=1001.2014.3001.5482
|--------------------|
| 非常感谢您的阅读,喜欢的话记得三连哦 |
