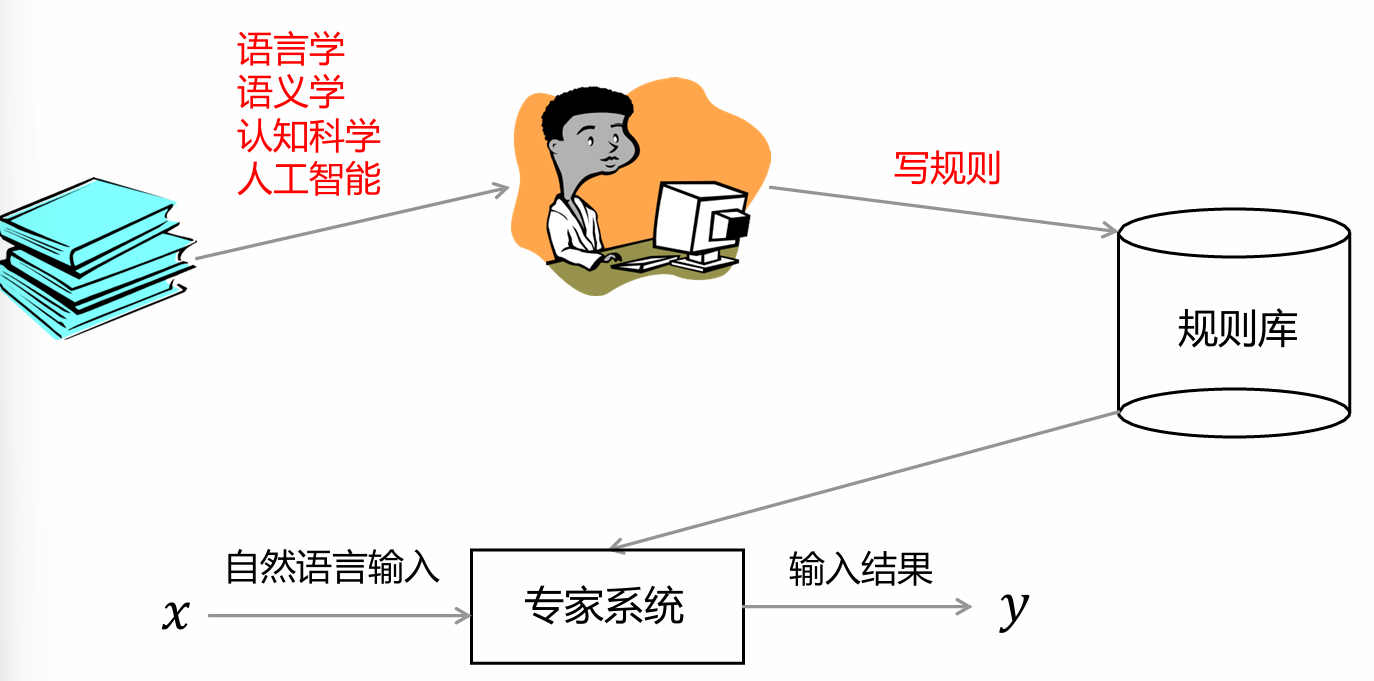
基于规则的自然语言处理
规则方法
以规则形式表示语言知识,强调人对语言知识的理性整理(知识工程------词典-主谓宾规则)
形态还原(针对英语、德语、法语等)
构词特点:
- 曲折变化:词尾和词形变化,词性不变。如study, studied, studied, studying
- 派生变化:加前缀和后缀,词性发生变化。如friend, friendly, friendship,...
- 复合变化:多个单词以某种方式组合成一个词。
还原时分两种情况,一种是变化有规律的通用规则,一种是变化无规律的个性规则。如went → \rightarrow → go就是典型的不规则动词还原举例。
中文分词
分词是指根据某个分词规范,把一个"字"串划分成"词"串。一个词可能有多个语素,这会在分词时带来困难。
切分歧义
- 交集型歧义:ABC切分成AB/C或A/BC
- 组合型歧义:AB切分成AB或A/B
- 混合型歧义:交集型歧义和组合型歧义嵌套和交叉而成(既有交集型歧义又有组合型歧义)
伪歧义与真歧义
伪歧义字段指在任何情况下只有一种切分,根据歧义字段本身就能消歧。
真歧义字段指在不同的情况下有多种切分,要根据歧义字段的上下文来消歧。
分词方法
正向最大匹配(FMM)或逆向最大匹配(RMM):从左至右(FMM)或从右至左(RMM),取最长的词
双向最大匹配:分别采用FMM和RMM进行分词,能发现交集型歧义("幼儿园/地/节目"和"幼儿/园地/节目"),如果结果一致,则认为成功;否则,采用消歧规则进行消歧。
正向最大、逆向最小匹配:正向采用FMM,逆向采用最短词,能发现组合型歧义("他/骑/在/马上"和"他/骑/在/马/上")。
逐词遍历匹配:在全句中取最长的词,去掉之,对剩下字符串重复该过程。
设立切分标志:收集词首字和词尾字,先把句子分成较小单位,再用某些方法切分。
全切分:可能的切分,选择最可能的切分(用统计方式,概率化各种切分)
歧义字段消歧方法
利用歧义字串、前驱字串和后继字串的句法、语义和语用信息。
分词带来的问题
组成词的字的信息丢失,错误的分词影响后续的工作,不同分词规范的分词造成分词结果不一致(判断哪个对需要人工check)
词性标注
为句子中的词标上预定义类别集合中的类(词性),目标是为后续的句法/语义分析提供必要的信息。在词性标注中,一个很大的挑战是兼类词,即一个词具有两个或者两个以上的词性,英文的Brown语料库中,10.4%的词是兼类词。
命名实体分类
命名实体分类可以分为三大类也可以分为七大类:
- 3大类-- 实体类、时间类、数字类
- 7大类-- 人名、地名、机构名、时间、日期、货币量、百分数
基于规则的命名实体识别,由专家总结实体词表,利用词表进行匹配,速度快但是覆盖率有限,且需要人力总结,适合垂直领域,如医疗、金融、法律等。
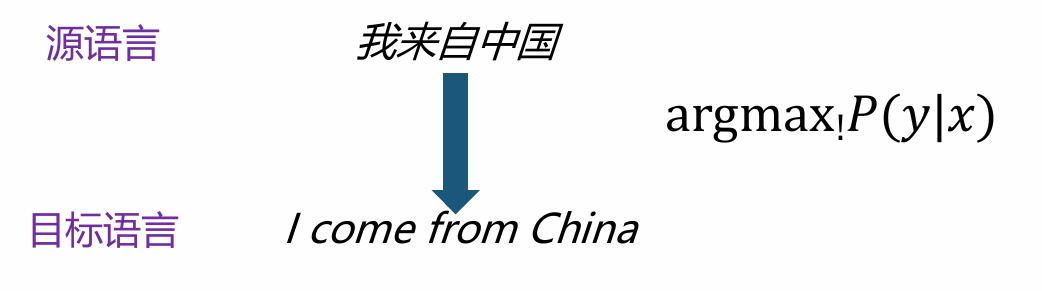
机器翻译
机器翻译(Machine Translation)是一个将源语言的句子x翻译成目标语言句子y(译文)的任务。
规则翻译遵循以下几个步骤:
- 分析:将源语言句子解析成一种深层的结构表示,如前文所说的分词就是这一部分的内容
- 转换:将源语言句子的深层结构表示转换成目标语言的深层结构表示
- 生成:根据目标语言的深层结构表示生成对应的目标语言句子
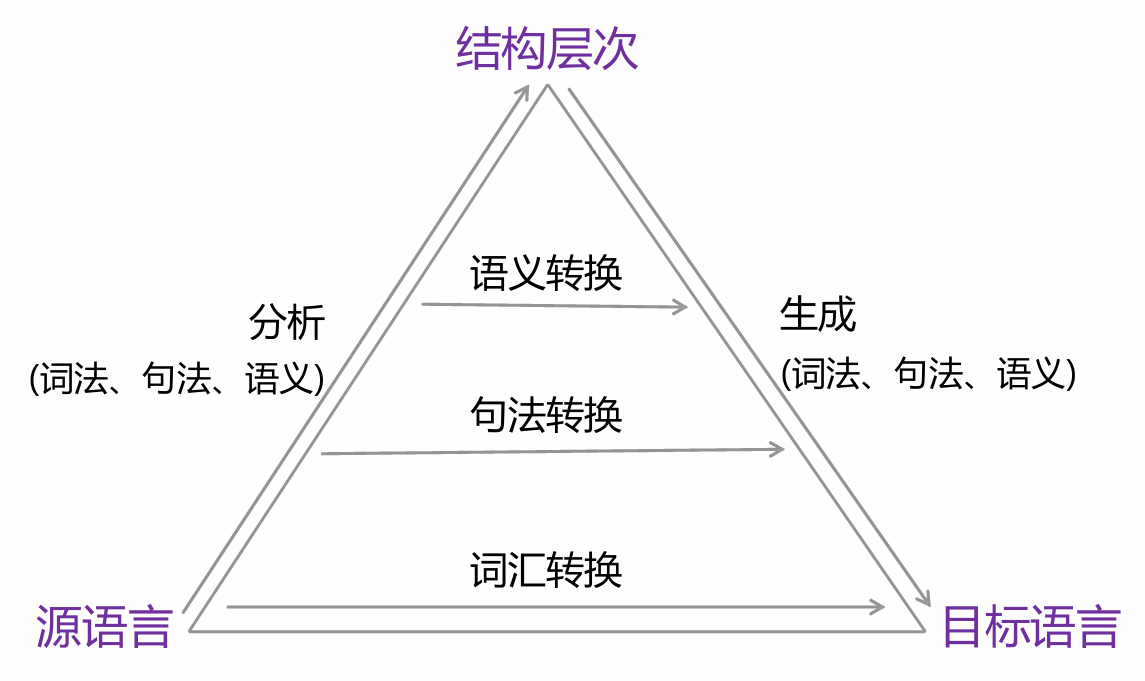
在词汇层次,根据词汇转换规则进行转换,句法分析时则递归地利用一组"树-树"的转换规则,把源语言的句法树转换成目标语言的句法树,从目标语言的句法树生成目标语言句子。
基于中间语言(INTERLINGUA)的翻译 指对源语言进行分析,得到一个独立于源语言和目标语言的、基于概念的中间语言表示,然后从这个中间语言表示生成目标语言。对于n种语言之间的翻译(多语翻译)-- 转换翻译需要n(n-1)个模块,而中间语言翻译只需要2n个模块,但是中间语言翻译加大了语言分析的难度(大量的消歧),因此需要考虑对机器翻译来说,这样的分析是否必要。

- 优点:在多语翻译时可以降低模块的数量
- 缺点:质量得不到保证
规则方法的问题
- 规则质量依赖于语言学家的知识和经验,获取成本高
- 规则之间容易发生冲突
- 大规模规则系统维护难度大