文本分类
将文本文档或句子分类为预定义的类或类别, 有单标签多类别文本分类和多标签多类别文本分类。

传统机器学习方法
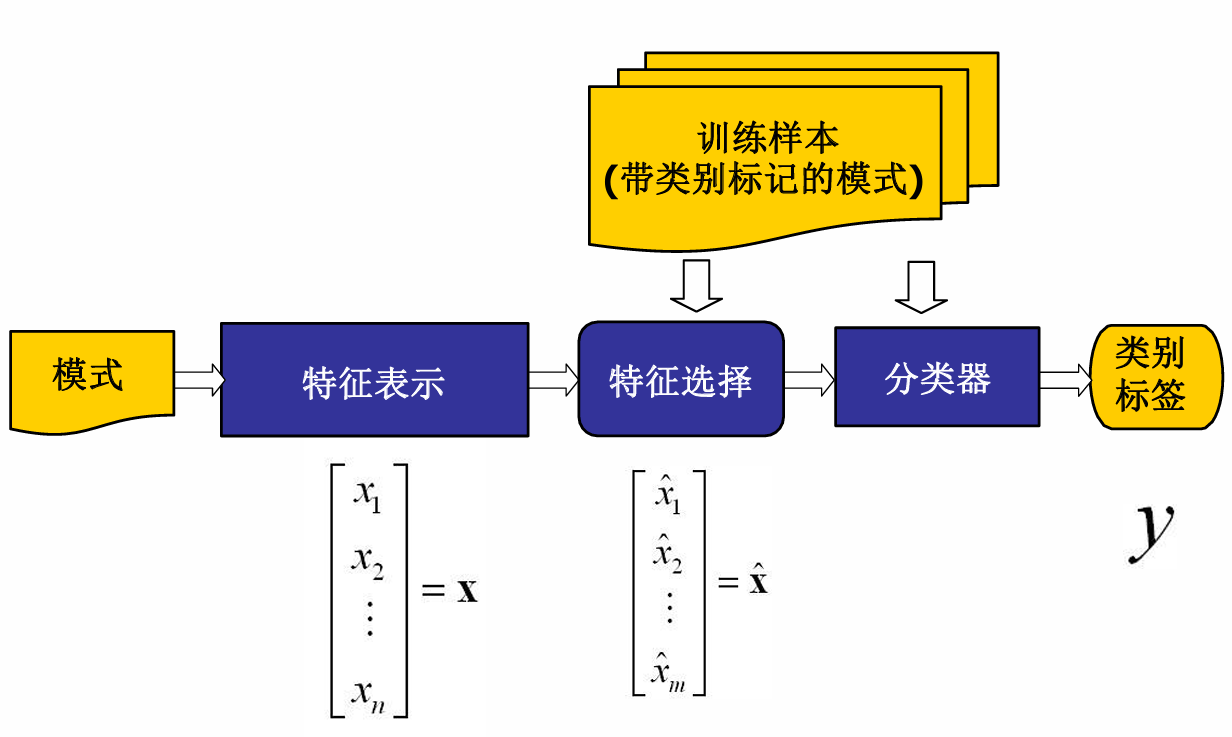
文本表示
计算机进行文本理解,必须知道文本长什么样,文本的形式化表示是反映文本内容和区分不同文本的有效途径。
向量空间模型
向量空间模型(vector space model, VSM)由G. Salton 等人于1960s末期在信息检索领域提出,核心是将文本视为特征项的集合。特征项是VSM中最小的语言单元,可以是字、词、短语等。文本则表示为特征项的集合 ( 𝑡 1 , 𝑡 2 , ... , 𝑡 𝑛 ) (𝑡_1,𝑡_2,...,𝑡_𝑛) (t1,t2,...,tn)
词语(词组或短语):若词语作为特征项,那么特征项的集合可视为一个词表。词表可从语料中统计获得,可看作一个词袋,向量空间模型被称为词袋模型(bag-of-words, BOW)

特征项权重:每个特征项在文本中的重要性不尽相同,用𝑤表示特征项𝑡的权重,相应地,文本可以表示为 ( 𝑡 1 : 𝑤 1 , 𝑡 2 : 𝑤 2 , ... , 𝑡 𝑛 : 𝑤 𝑛 ) (𝑡_1:𝑤_1,𝑡_2:𝑤_2,...,𝑡_𝑛:𝑤_𝑛) (t1:w1,t2:w2,...,tn:wn)或 ( 𝑤 1 , 𝑤 2 , ... , 𝑤 𝑛 ) (𝑤_1,𝑤_2,...,𝑤_𝑛) (w1,w2,...,wn)
如何计算特征项的权重?
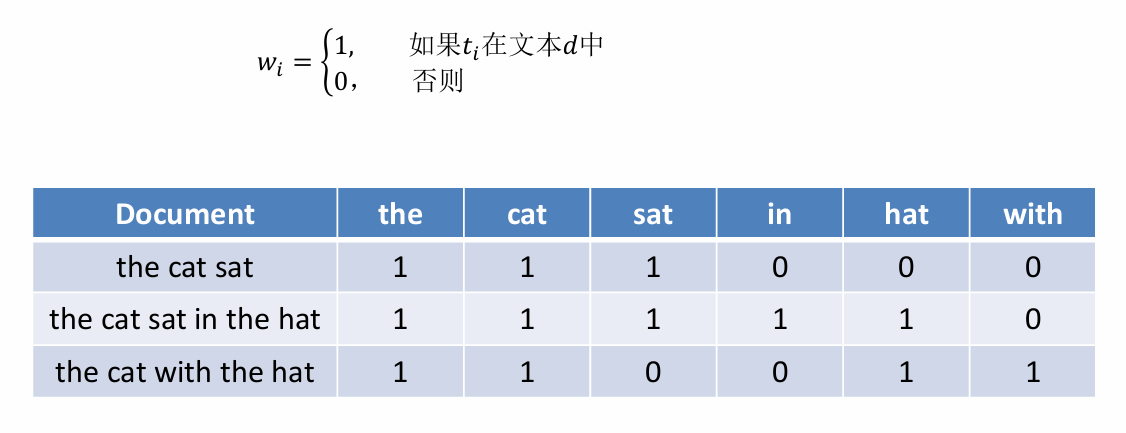
- 布尔变量(是否出现)
- 词频
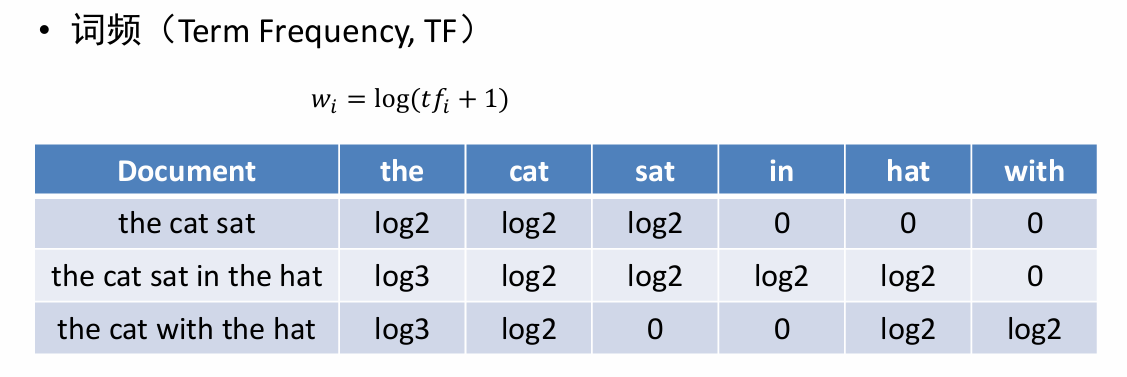
基于词频方法会有一个问题,如上图所示,像the这样子的词特征权重会比较大,但是实际上这些词在句子分析是效果甚微。 - 逆文档频率:定义为总的文档数/单词频率 ,让the这样子的词特征权重降为0.
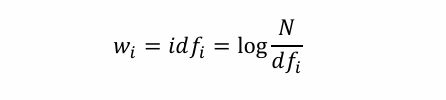
- TF-IDF=tfi * idfi,tfi是词频,idfi是逆文档频率,这是目前最好的一个方法。
特征选择
文档频率
一个特征的文档频率 是指在文档集中含有该特征的文档数目,假设 DF值低于某个域值的词条是低频词,它们不含或含有较少的类别信息, 将这样的词条从原始特征空间中除去,不但能够降低特征空间的维数,而且还有可能提高分类的精度。因此出现文档数多的特征词被保留的可能性大。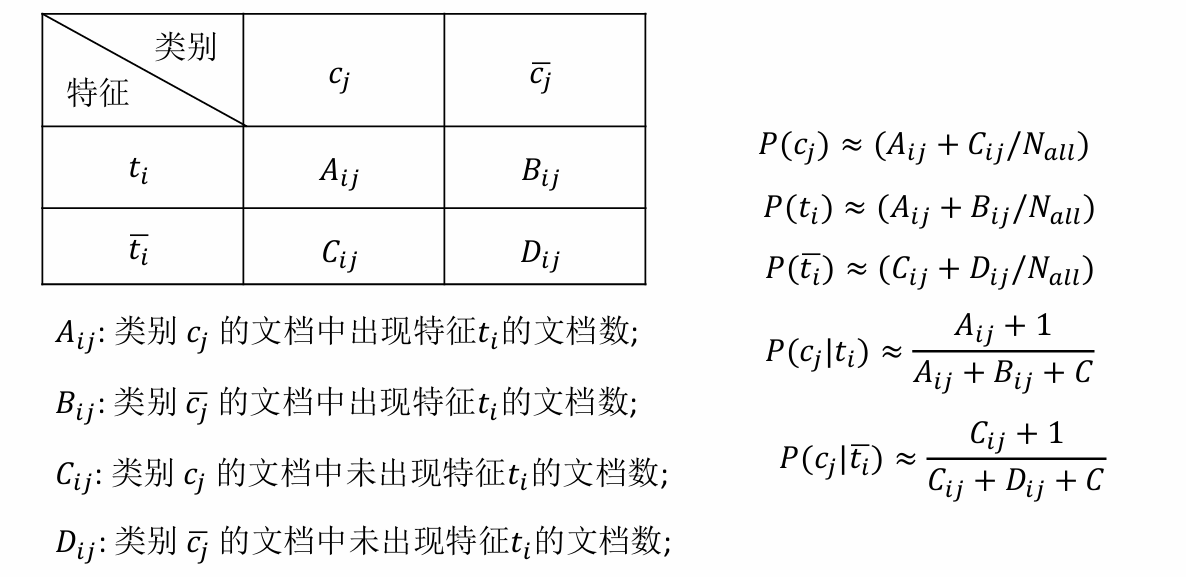
下面的两个条件概率表示在有了ti这个特征之后属于cj类别的概率,+1和+C是防止为0的变换(C表示类别的数量),即进行平滑处理。
互信息
互信息是关于两个随机变量互相依赖程度的一种度量
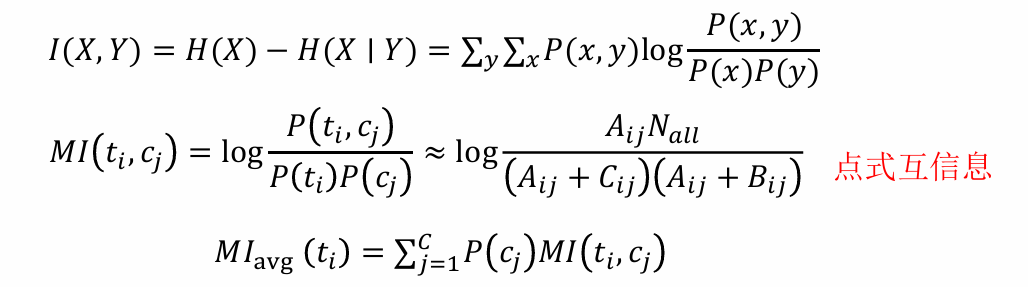
信息增益(IG)
IG衡量特征能够为分类系统带来多少信息
特征 𝑇 𝑖 𝑇_𝑖 Ti对训练数据集C的信息增益定义为集合C的经验熵H©与特征 𝑇 𝑖 𝑇_𝑖 Ti给定条件下C的经验条件熵 H ( C ∣ 𝑇 𝑖 ) H(C|𝑇_𝑖) H(C∣Ti)之差,即 I G ( C , T i ) = H ( C ) − H ( C ∣ T i ) IG(C,T_i)=H(C)-H(C|T_i) IG(C,Ti)=H(C)−H(C∣Ti)
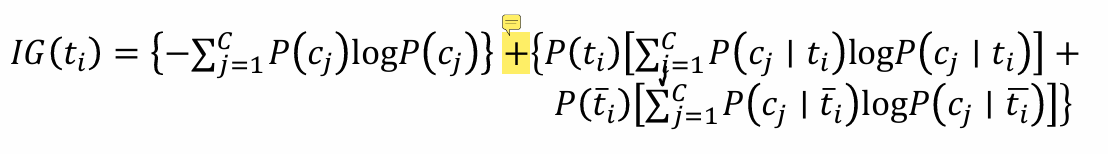
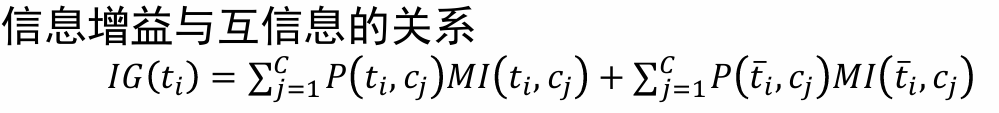
分类器设计
监督学习:训练数据是人工标注的,用参数进行建模(构建目标函数),常见的监督学习模型有朴素贝叶斯、线性判别函数、支持向量机等等。
贝叶斯理论:
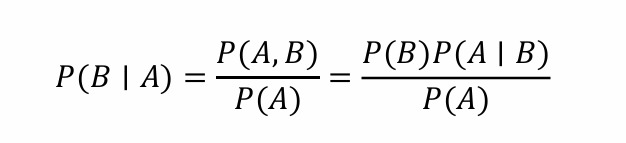
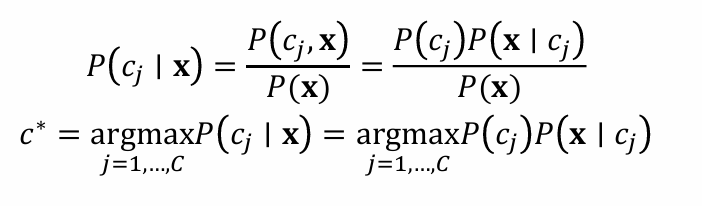
朴素贝叶斯假设:假设所有特征在给定类别的情况下是相互独立的,这意味着每个特征对分类结果的影响是独立的,与其他特征无关。
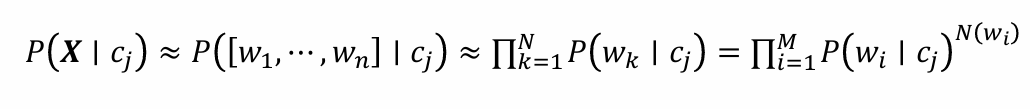
朴素贝叶斯分类模型中的参数估计:采用最大似然估计
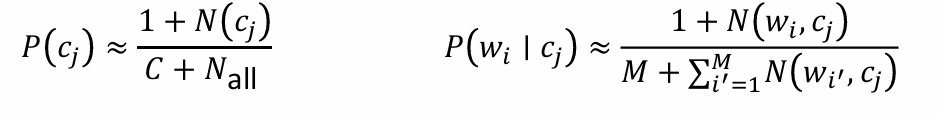
线性判别函数
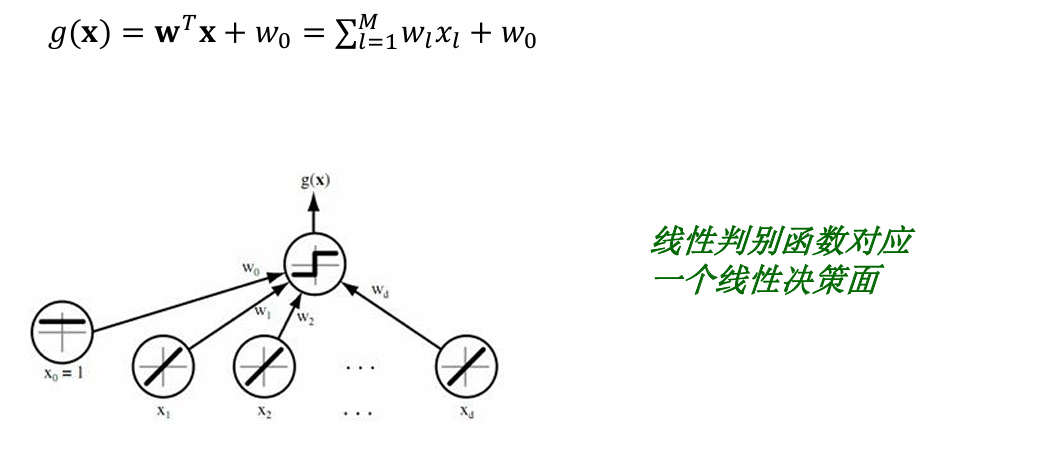
线性判别函数需要考虑两个方面:一个是考虑哪个分类面更优,一个是考虑选择哪个学习准则。常见的线性判别函数的学习准则有感知器准则、最小均方差、交叉熵等。
文本分类性能评估
假设一个文本分类任务共有M个类别,类别名称分别为 𝐶 1 , ... , 𝐶 𝑀 𝐶_1,...,𝐶_𝑀 C1,...,CM。
在完成分类任务以后,对于每一类都可以统计出真正例、真负例、假正例和假负例四种情形的样本数目。
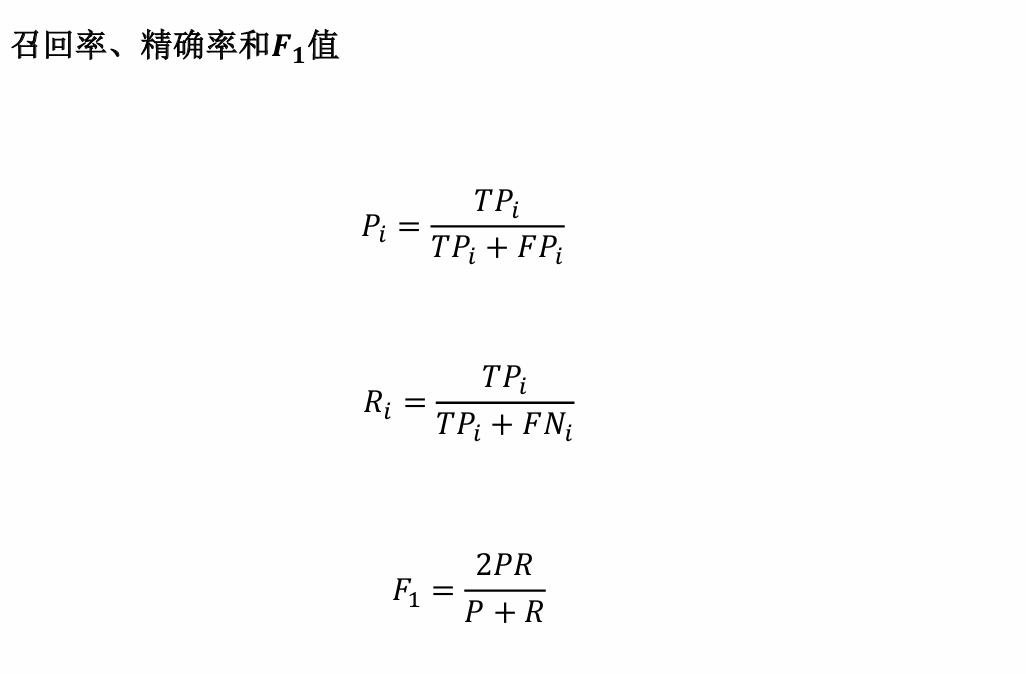
- 真正例 (True Positive, TP):模型正确预测为正例(即模型预测属于该类,真实标签属于该类)。
- 真负例 (True Negative, TN): 模型正确预测为负例(即模型预测不属该类,真实标签不属该类)。
- 假正例 (False Positive, FP):模型错误预测为正例(即模型预测属于该类,真实标签不属该类)。
- 假负例 (False Negative, FN):模型错误预测为负例(即模型预测不属该类,真实标签属于该类)。

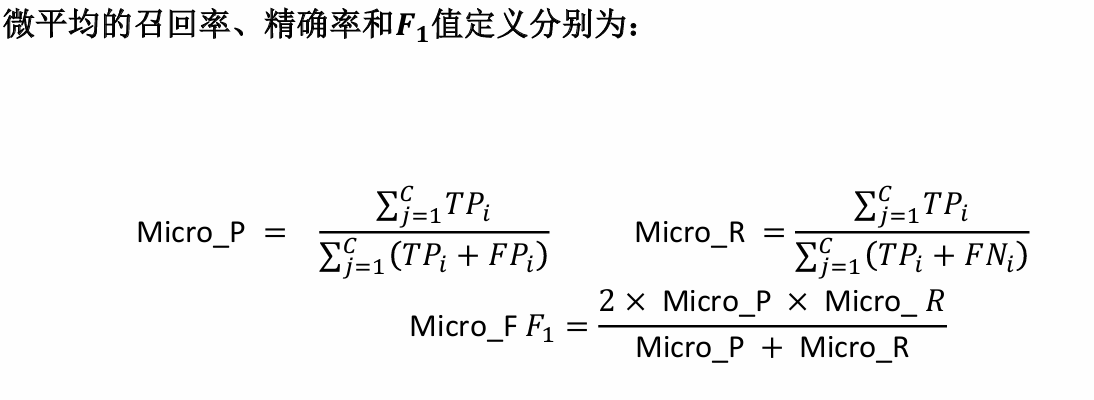
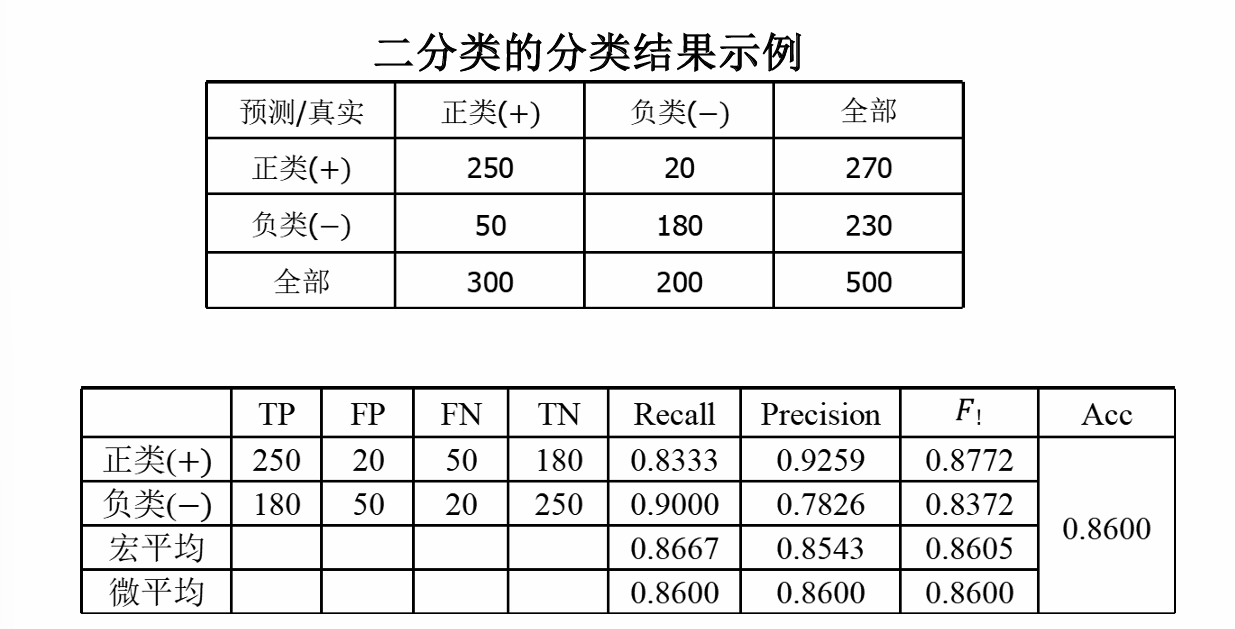
其中需要稍微解释一下的是图中宏平均和微平均的计算方法,宏平均是先计算每个类别的指标(如Recall、Precision、F1 Score),然后对这些指标求算术平均值。它平等对待每个类别,不考虑类别样本数量的差异,所以宏平均只需要将正类和负类的各自指标值做一个平均即可。
但是微平均考虑了样本数量的差异性,汇总所有类别的TP、FP、FN,然后用这些总和来计算整体的指标。它更关注样本数量多的类别,因为样本多的类别对总的TP、FP、FN贡献更大。
注意:在二分类问题中,准确率 (Accuracy) 等于微平均 Recall、微平均 Precision 和微平均 F1 Score。
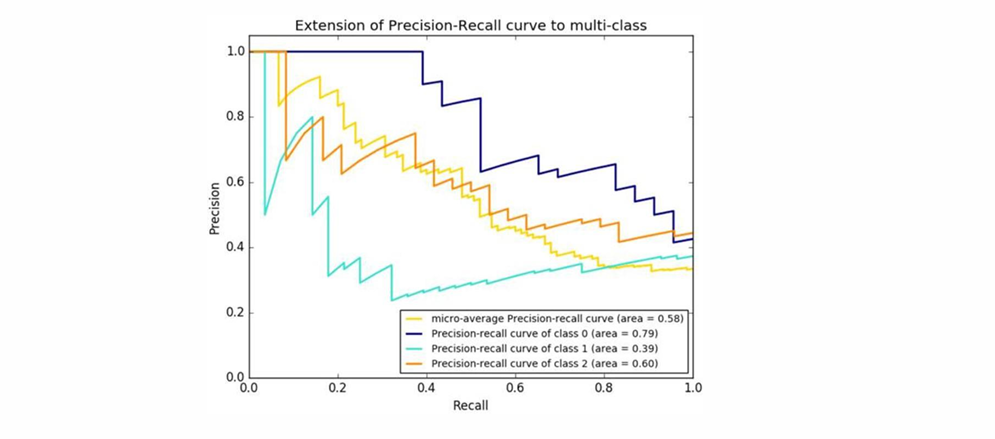
P-R曲线
通过调整分类器的阈值,将按输出排序的样本序列分割为两部分,大于阈值的预测为正类,小于阈值的预测为负类,从而得到不同的召回率和精确率。如设置阈值为0时,召回率为1;设置阈值为1时,则召回率为0。以召回率作为横轴、精确率作为纵轴,可以绘制出精确率-召回率(precision-recall, PR)曲线。
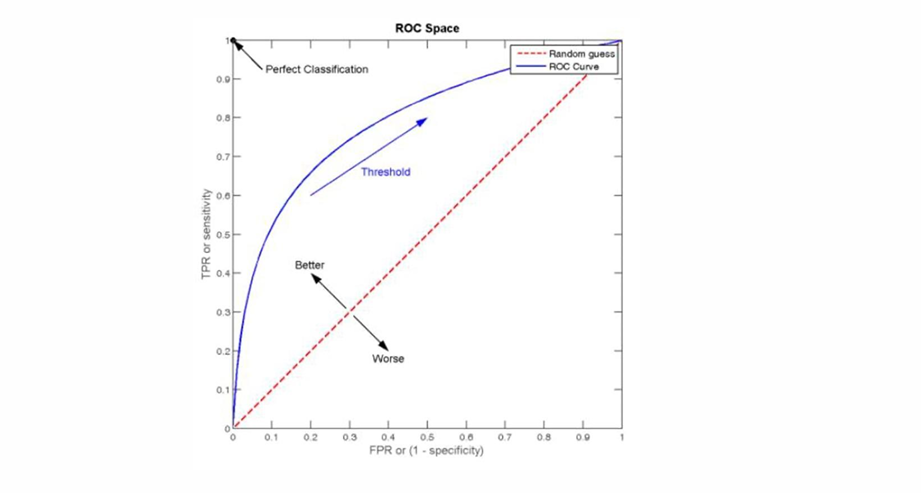
ROC曲线
以假正率(false positive rate)作为横坐标,以真正率(true positive rate)(即召回率)作为纵坐标,绘制出的曲线称为ROC(receiver operating characteristic)曲线。ROC曲线下的面积称为AUC(area under ROC curve),AUC曲线越靠近左上方越好。AUC值越大,说明分类器性能越好。