大家读完觉得有帮助记得及时关注和点赞!!!
抽象
检索增强生成 (RAG) 系统通过在生成响应之前从外部语料库中检索相关文档来增强大型语言模型 (LLM)。这种方法通过利用大量最新的外部知识,显著扩展了 LLM 的能力。然而,这种对外部知识的依赖使 RAG 系统容易受到语料库中毒攻击,这些攻击通过中毒文档注入来纵生成的输出。 现有的中毒攻击策略通常将检索和生成阶段视为脱节,从而限制了它们的有效性。 我们提出了 Joint-GCG ,这是第一个通过三项创新在检索器和生成器模型中统一基于梯度的攻击的框架:(1) 用于对齐嵌入空间的跨词汇投影 ,(2) 用于同步令牌级梯度信号的梯度令牌化对齐 ,以及 (3) 自适应加权融合 用于动态平衡攻击目标。评估表明,与以前的方法相比,Joint-GCG 在多个检索器和生成器中的攻击成功率最高提高了 25%,平均提高了 5%。 虽然在白盒假设下进行了优化,但生成的毒药显示出前所未有的可转移性,可以转移到看不见的模型中。 Joint-GCG 在检索和生成阶段创新地统一了基于梯度的攻击,从根本上改变了我们对 RAG 系统内漏洞的理解。 我们的代码可在 GitHub - NicerWang/Joint-GCG: Official implementation of "Joint-GCG: Unified Gradient-Based Poisoning Attacks on Retrieval-Augmented Generation Systems". 上获得。
1介绍
检索增强一代 (RAG) 系统[1](https://arxiv.org/html/2506.06151v1#bib.bib1 "1"),[2](https://arxiv.org/html/2506.06151v1#bib.bib2 "2")已成为增强大型语言模型 (LLM) 的强大范例。通过将检索器(根据给定查询从外部语料库获取相关文档)与生成器(合成信息以生成连贯且上下文适当的响应)相结合,RAG 系统利用了大量最新的外部知识。此架构显著提高了各种 AI 应用程序(包括搜索引擎)的性能[3](https://arxiv.org/html/2506.06151v1#bib.bib3 "3")、聊天机器人[4](https://arxiv.org/html/2506.06151v1#bib.bib4 "4"),[5](https://arxiv.org/html/2506.06151v1#bib.bib5 "5")、代码助手[6](https://arxiv.org/html/2506.06151v1#bib.bib6 "6"),[7](https://arxiv.org/html/2506.06151v1#bib.bib7 "7")和知识库[8](https://arxiv.org/html/2506.06151v1#bib.bib8 "8"),[9](https://arxiv.org/html/2506.06151v1#bib.bib9 "9")---通过确保输出准确和最新[10](https://arxiv.org/html/2506.06151v1#bib.bib10 "10").
然而,这种非凡的功能也伴随着一个关键的漏洞:依赖外部语料库会带来语料库中毒的风险[11](https://arxiv.org/html/2506.06151v1#bib.bib11 "11"),[12](https://arxiv.org/html/2506.06151v1#bib.bib12 "12"),[13](https://arxiv.org/html/2506.06151v1#bib.bib13 "13"),[14](https://arxiv.org/html/2506.06151v1#bib.bib14 "14"),[15](https://arxiv.org/html/2506.06151v1#bib.bib15 "15").如图 1 所示,语料库中毒涉及恶意行为者将精心制作的中毒文档注入知识库。如果检索和处理这些有毒的文档,可能会导致 RAG 系统生成错误的答案、有害的输出或有偏见的观点,从而破坏其可靠性。 此外,采用开源组件的 RAG 系统的增长趋势旨在促进透明度、定制和防止数据泄漏。但是,这允许攻击者精心研究和复制系统架构,使 RAG 系统更容易受到语料库中毒攻击。
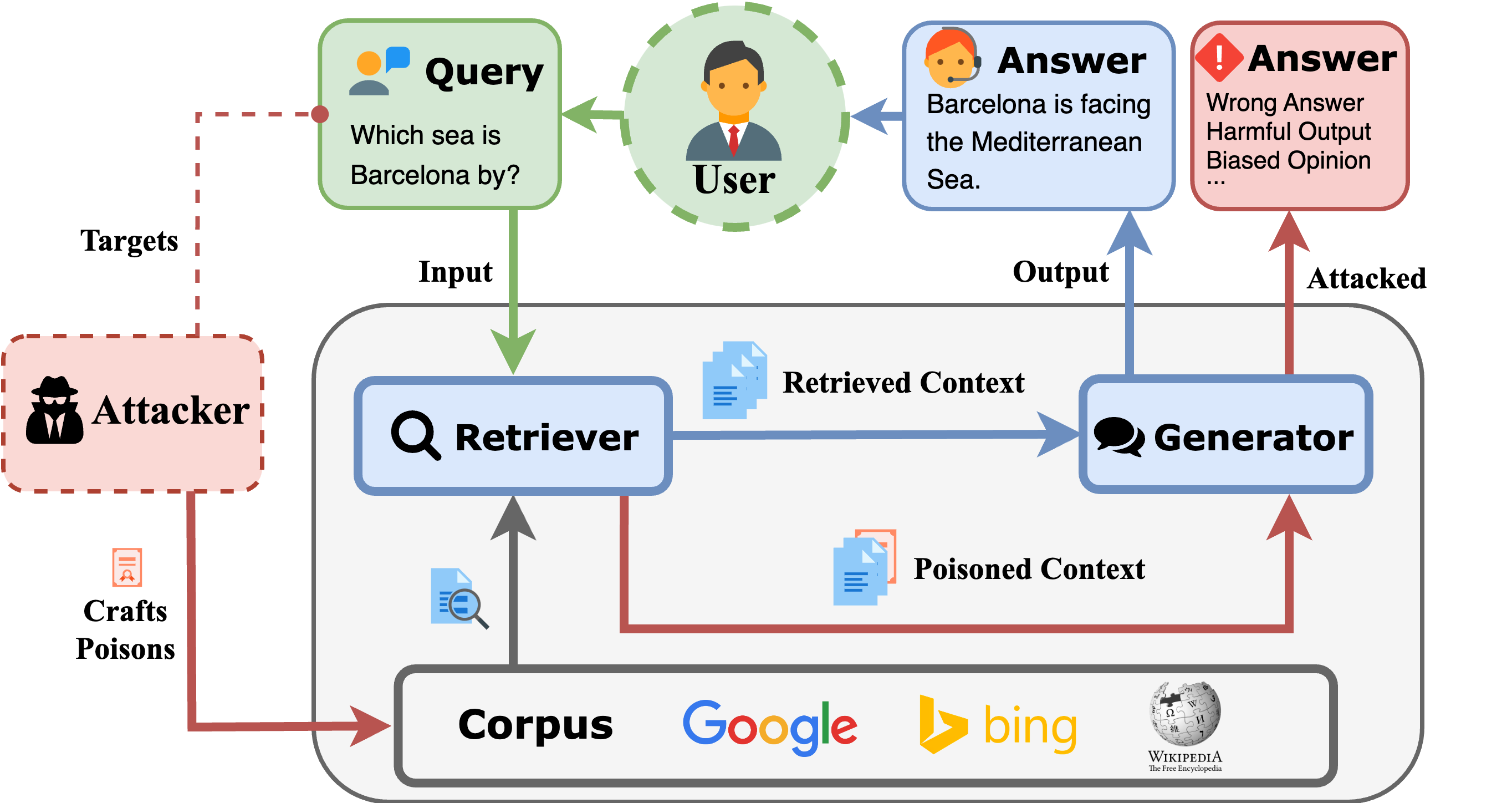
图 1:RAG 系统和 RAG 中毒攻击的演示。我们在附录表 X 中提供了一个成功攻击 RAG 系统以诱发错误答案的示例。
语料库中毒的目标是将中毒文档引入语料库,并确保它们可以通过有针对性的查询进行检索。更重要的是,攻击者必须纵后续的生成过程,以确保模型根据中毒信息产生错误的输出。因此,攻击的有效性取决于对中毒文档的检索以及文档控制生成器生成的响应的能力。至关重要的是,攻击者旨在通过尽可能少地注入有毒文档来实现这种隐蔽性和实用性的影响,这对于逃避检测至关重要。
现有的攻击策略,如第 2 节所述,通常采用碎片化的方法,将检索和生成阶段视为不相交的优化问题。 例如,Phantom[15](https://arxiv.org/html/2506.06151v1#bib.bib15 "15")和骗子[13](https://arxiv.org/html/2506.06151v1#bib.bib13 "13")独立和按顺序处理 Retriever 和 Generator 目标。 这种方法可能不是最佳方法,因为它们忽视了通过同时优化这两个组成部分可以实现的协同效应,从而可能限制中毒攻击的整体效果。
为了解决这一限制,我们提出了 Joint-GCG ,这是一个新颖的框架,它首次通过联合优化检索器和生成器的梯度和损失来统一攻击面。 Joint-GCG 通过三项关键创新克服了联合优化的技术障碍,包括不匹配的词汇表和模型之间的不同标记化方案:(1) 跨词汇投影 (CVP), 它对齐词汇嵌入;(2) 梯度分词对齐 (GTA), 同步分词级梯度信号;(3) *自适应加权融合 (AWF),*动态平衡检索和生成目标的影响。这些创新机制共同形成高效的攻击策略,展示了联合优化在 RAG 中毒中的力量。
我们的主要贡献是:
- •
**问题建模创新:**我们确定了现有脱节攻击策略的局限性,并强调了在 RAG 中毒中联合优化检索和生成的迫切需求。我们是第一个强调统一优化协同潜力以显著提高攻击效能的公司,将范式从独立组件攻击转变为整体系统级方法。 - •
**新颖的关节优化框架:**我们提出了 Joint-GCG,这是一个新颖的框架,可有效解决 RAG 中毒中联合优化的挑战,通过在检索和生成阶段编排协同攻击,实现更有效、更准确引导的语料库中毒。 - •
**系统评价:**我们证明了 Joint-GCG 优于最先进的方法,平均攻击成功率最高提高 25%,平均提高 5%,实现了显着的交叉检索器可转移性以及显着的交叉生成器可转移性(最高达到 57%一个SR在看不见的模型上),并展示其在批量中毒和合成语料库场景中的适用性,放大了 RAG 系统的脆弱性。
2相关作品
2.1检索增强一代 (RAG) 系统
检索增强生成 (RAG) 系统代表了减轻大型语言模型 (LLM) 固有限制(例如知识中断和幻觉)的重大进步[1](https://arxiv.org/html/2506.06151v1#bib.bib1 "1"),[16](https://arxiv.org/html/2506.06151v1#bib.bib16 "16").RAG 的核心原则是将 LLM 响应建立在外部的、可验证的知识之上。典型的 RAG 架构包括一个检索器和一个生成器。收到查询后,检索器首先从大型外部语料库(例如,矢量数据库、企业知识库或 Internet)中获取相关文档或数据片段[17](https://arxiv.org/html/2506.06151v1#bib.bib17 "17").然后,这些检索到的上下文与原始查询一起提供给 LLM(生成器)。LLM 综合此信息以产生更准确、更及时且符合上下文的响应[16](https://arxiv.org/html/2506.06151v1#bib.bib16 "16").这种对外部语料库的依赖虽然有利于准确性和时效性,但会引入新的攻击面,尤其是语料库中毒,这是我们工作的重点。
2.2对大型语言模型的对抗性攻击
大型语言模型尽管功能令人印象深刻,但容易受到各种对抗性攻击[18](https://arxiv.org/html/2506.06151v1#bib.bib18 "18").这些漏洞包括提示注入,其中恶意指令嵌入到输入中以劫持模型的输出[19](https://arxiv.org/html/2506.06151v1#bib.bib19 "19"),以及基础 LLM 本身的训练数据中毒,这可能会引入细微的偏差或后门[20](https://arxiv.org/html/2506.06151v1#bib.bib20 "20").这些一般漏洞强调了在 LLM 开发和部署的所有阶段采取强大安全措施的必要性。
2.2.1用于对抗性文本生成的基于梯度的优化
基于梯度的优化已成为针对 LLM 制作对抗性示例的基石。早期方法,如 HotFlip [21](https://arxiv.org/html/2506.06151v1#bib.bib21 "21"),利用与输入标记相关的梯度来识别可能改变模型预测的最小字符级或标记级扰动。简单的替换技术[22](https://arxiv.org/html/2506.06151v1#bib.bib22 "22")和启发式优化[23](https://arxiv.org/html/2506.06151v1#bib.bib23 "23")只取得了适度的成功,主要是在较小的型号上。相比之下,梯度导向方法对稳健的 transformer 架构显示出卓越的功效。贪婪坐标梯度 (GCG) 攻击[24](https://arxiv.org/html/2506.06151v1#bib.bib24 "24")通过优化通用对抗性后缀来引出所需的(通常是有害的)响应,从而扩展了这一点。多坐标渐变 (MCG), 在 Phantom 作品中提出[15](https://arxiv.org/html/2506.06151v1#bib.bib15 "15"),通过同时考虑多个替换以提高效率来进一步优化这一点。改进的版本,例如 I-GCG[25](https://arxiv.org/html/2506.06151v1#bib.bib25 "25"))也被探索过。这些方法展示了梯度信息的力量,但主要是为直接攻击 LLM 而设计的,而不是复杂的两阶段 RAG 管道。
2.3数据中毒攻击
2.3.1机器学习中的经典数据中毒
数据中毒是一种恶意攻击,攻击者纵机器学习模型的训练数据,以破坏其推理过程中的行为[26](https://arxiv.org/html/2506.06151v1#bib.bib26 "26").通过将少量精心设计的恶意样本注入训练数据集,攻击者主要寻求降低模型的整体性能,导致目标输入的错误分类,或植入由特定输入触发的后门[27](https://arxiv.org/html/2506.06151v1#bib.bib27 "27"),[28](https://arxiv.org/html/2506.06151v1#bib.bib28 "28").
2.3.2对信息检索系统的攻击
信息检索 (IR) 系统也一直是纵的目标。传统搜索引擎面临"垃圾邮件"或"搜索引擎中毒",其中恶意行为者使用关键字填充、隐藏文本和链接农场等技术来人为提高某些网页的排名[29](https://arxiv.org/html/2506.06151v1#bib.bib29 "29"),[30](https://arxiv.org/html/2506.06151v1#bib.bib30 "30").现代检索组件,尤其是 RAG 中使用的密集检索器,可能会被对文档的难以察觉的扰动所误导,从而导致排名纵[31](https://arxiv.org/html/2506.06151v1#bib.bib31 "31"),[32](https://arxiv.org/html/2506.06151v1#bib.bib32 "32").恶意攻击可以迫使排名者错误地对文档进行排序或检索不相关的内容,即使对语料库进行了最少的修改。
2.3.3RAG 系统中的语料库中毒
RAG 系统对外部语料库的依赖使它们特别容易受到语料库中毒的影响。现有研究探索了各种策略:中毒 RAG [11](https://arxiv.org/html/2506.06151v1#bib.bib11 "11")专注于优化中毒文档以最大限度地提高其检索概率。劫持 RAG [33](https://arxiv.org/html/2506.06151v1#bib.bib33 "33")将类似的原则应用于 Prompt Leaking 和 Spam Generation。但是,仅针对检索进行优化可能会损害有效引导生成器所需的语言质量,通常需要大量注入的文档。 顺序优化方法(例如应用 HotFlip 进行检索,然后应用 GCG 进行生成)可能不是最佳的,因为在一个阶段所做的修改可能会对另一个阶段产生负面影响。说谎者 [13](https://arxiv.org/html/2506.06151v1#bib.bib13 "13")试图通过迭代循环实现更好的集成,但仍然缺乏适当的关节优化,因为它预先分配了固定的可优化长度和优化步骤。幽灵[15](https://arxiv.org/html/2506.06151v1#bib.bib15 "15")引入了基于触发器的批量中毒,但按顺序优化了检索和生成,这有时会导致检索失败。木马 [14](https://arxiv.org/html/2506.06151v1#bib.bib14 "14")以 Retriever 模型本身为目标,这是一种需要更多访问权限的不同威胁模型。 相比之下,我们的 Joint-GCG 框架通过在检索器和生成器之间执行真正的联合优化来解决这些限制,这标志着与这些脱节或顺序策略的背离。
3威胁模型
我们的威胁模型考虑了攻击者在使用 Joint-GCG 为 RAG 系统制作毒药时所承担的能力和知识。它旨在促进对潜在漏洞的彻底调查,特别是那些由检索器和生成器组件的联合优化引起的漏洞。
白盒检索器和生成器访问: 我们假设攻击者对 retriever 和 generator 模型都具有完全的白盒访问权限。这种全面的可访问性意味着攻击者拥有模型架构知识,包括所有层和配置,可以访问所有模型参数,并且可以计算与模型输入相关的任何损失函数(即可优化的毒物序列)的梯度。
鉴于攻击者可以复制或直接访问的开源 RAG 组件(检索器和 LLM)激增,这种白盒假设变得越来越相关,这使得使用这些组件构建的系统容易受到这种级别的审查。
此外,在完整信息下了解系统漏洞通常是建立强大防御的先决条件,从白盒攻击中获得的见解也可以指导创建更实用的灰盒或黑盒攻击策略。
最后,这种方法与一些当代 RAG 中毒研究工作的方法一致(例如,LIAR[13](https://arxiv.org/html/2506.06151v1#bib.bib13 "13")幽灵[15](https://arxiv.org/html/2506.06151v1#bib.bib15 "15")),它们也在两个组件的白盒假设下运行,将其确立为该研究领域深入分析的标准范式。我们的实验(第 5.2.5 节)中演示的强毒药可转移性揭示了在攻击部署期间放宽此白盒假设的实用路径。攻击者可以使用模拟目标可能架构的强大本地托管代理模型,在白盒设置中利用 Joint-GCG。然后,可以利用生成的毒药来攻击目标系统,即使组件不同或完全是黑盒。我们的结果表明,在一个生成器上优化的毒药可以成功攻击其他生成器。同样,毒物在不同的检索器结构中表现出高度的可转移性。这种代理模型方法将攻击转变为灰盒场景,攻击者只需要将预制文档注入目标语料库,而无需内部访问生产模型。
灰盒语料库访问: 我们假设攻击者对检索语料库具有有限或灰盒 访问权限。在我们的实验中,攻击者可以将少量固定数量的中毒文档注入到语料库中,通常每个目标查询一个中毒文档以确保隐身,但无法修改或删除现有的合法文档。我们的自适应加权融合 (AWF) 模块通过分析顶部 -k为查询检索的文档。鉴于 RAG 系统经常引用其来源,有效地使检索到最多的文档可访问,我们认为攻击者在优化阶段观察这些结果是现实的。我们还探讨了使用合成语料库(第 5.2.3 节)来缓解这一特定观察要求的场景。这种灰盒语料库访问反映了现实情况,例如分散式知识库、Wiki 或为可公开编辑的 Web 内容编制索引的系统,攻击者可以引入恶意内容,但无法控制整个语料库。对注入的文档数量的限制反映了对隐身的实际需求,因为可能会检测到注入大量可疑文档。
这种全面的威胁模型使 Joint-GCG 能够在中毒攻击期间检查检索器和生成器之间的复杂关系,从而深入了解现代 RAG 系统的安全态势。
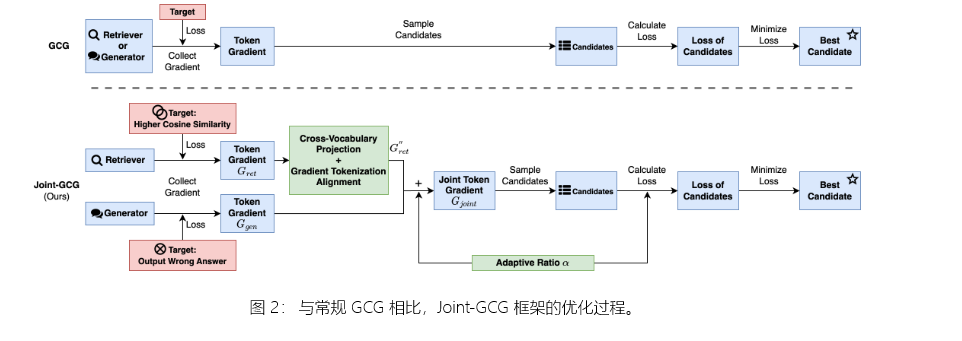
4方法:联合 GCG 框架
为了解决脱节的 RAG 中毒攻击的局限性,我们提出了 Joint-GCG,这是一个新颖的框架,旨在通过同时针对检索器和生成器来统一攻击过程。
受到贪婪坐标梯度 (GCG) 技术成功的启发[24](https://arxiv.org/html/2506.06151v1#bib.bib24 "24")在通过梯度引导的输入优化纵发生器输出时,Joint-GCG 将 RAG 系统概念化为中毒攻击的单个集成目标,如图 2 所示。
这种统一方法的一个核心挑战在于协调检索器和生成器模型之间的不同架构、标记化方案和词汇表。我们的框架通过三个关键创新解决了这些复杂性:(1) 跨词汇投影 (CVP), 它对齐了不同词汇的嵌入空间;(2) 梯度分词对齐 (GTA), 在不同分词输出之间同步分词级梯度信号;(3) *自适应加权融合 (AWF),*动态平衡猎犬和生成器的攻击目标。这些组件共同实现了一个有凝聚力的、基于梯度的优化策略,该策略共同指导中毒文档的检索和所需恶意输出的后续生成。
4.1跨词汇投射 (CVP):弥合词汇差异
检索器和生成器之间固有的词汇不匹配对联合梯度优化构成了重大挑战。通常,由于不同的训练语料库,检索器的词汇表与生成器的词汇表不同。CVP 通过利用生成器令牌的组合来表示嵌入空间中的检索器令牌,从而解决了这一差距。
在类似 GCG 的攻击期间,采用可优化序列来通过梯度引导来引导模型输出。让Ngen,Vgen表示生成器的可优化序列长度和词汇大小,以及Nret,Vret对于猎犬。在攻击过程中,我们计算梯度矩阵Ggen∈ℝNgen×Vgen和Gret∈ℝNret×Vret.
直接获取高维线性变换矩阵W∈ℝVRET×V根使用生成器令牌来表示检索令牌是由于构建足够方程组的病态性质和大量的计算需求而变得不可行。相反,CVP 采用了一种更易于处理的方法,专注于映射单个标记嵌入。让E根∈ℝV根×D根和ERET∈ℝVRET×DRET分别表示生成器和检索器的嵌入矩阵,其中D表示嵌入维度。对于每个检索器标记嵌入y∈ℝDRET,我们的目标是找到一个表示x∈ℝV根这样,当它被学习的嵌入映射函数转换时,它充当与生成器标记的线性组合f,非常接近y:

这里f:ℝD根→ℝDRET表示两个嵌入空间之间的映射函数。
CVP 学习f使用 generator 和 retriever 词汇表之间的共享标记,通过自动编码器 映射它们各自的嵌入。自动编码器经过训练,可以投影共享令牌的生成器嵌入,然后重建相应的检索器嵌入。此目标使自动编码器能够学习健壮且语义上有意义的映射,该映射在共享词汇表之外进行泛化,从而有效地捕获两个嵌入空间之间的潜在关系。经过训练的自动编码器的编码器的作用是f,使我们能够求解一个最小二乘解,该解将Gret到Gret′∈ℝNret×Vgen并对齐梯度信息。附录 A 中提供了自动编码器的详细架构规范、训练过程和 CVP 分析。
4.2梯度分词化对齐 (GTA):同步分词化粒度
在 CVP 之后,另一个关键挑战来自不同的标记化方案。检索器和生成器通常使用不同的分词器,导致输入文本分割为分词的方式存在差异。因此,检索器和生成器的可优化序列可以被标记化为不同的序列。这种标记化不匹配阻碍了直接梯度融合。为了解决这个问题,我们提出了 GTA,这是一个旨在以更精细的、与分词器无关的粒度同步梯度信号的模块。
为了实现标记对齐,GTA 采用字符级渐变作为中介。检索器标记梯度,源自Gret′)被分解并分配给其组成字符,从而将字符识别为更基本且与标记无关的文本单元。随后,通过对形成每个生成器标记的字符的梯度求平均值来构造检索器标记梯度。这种平均方法将字符级信息稳健地整合回生成器的标记空间,同时减轻分解过程中的潜在噪声。
通过 GTA 过程,我们得到了一个转换后的检索器梯度矩阵Gret′′∈ℝNgen×Vgen.关键Gret′′现在与生成器的梯度矩阵对齐Ggen在词汇和序列长度维度上。这种对齐建立了一个通用的梯度空间,从而能够有意义且直接地融合来自检索器和生成器的梯度信息,以实现关节优化。
此外,我们在附录 B 中提供了 GTA 的伪代码。
4.3自适应加权融合 (AWF):动态平衡检索和生成目标
跟Ggen和Gret′′现在在所有维度上都对齐了,最后的关键步骤是确定如何组合这些梯度矩阵以有效地实现联合优化。我们提出了 AWF,这是一个在优化过程中动态调整每个梯度矩阵的相对贡献的模块。这种自适应加权机制是必不可少的,因为优先级检索和生成目标之间的最佳平衡可能会因特定攻击场景、RAG 系统设置以及目标查询和语料库的特征而有很大差异。
AWF 融合梯度,并使用由自适应加权参数控制的加权和对损失进行加权α:

加权因子α∈0,1控制检索器和发生器的渐变在联合渐变更新中的相对影响。
如附录 D 中所述,我们的实验表明,在 RAG 系统中,中毒文档的检索等级与攻击成功之间存在很强的相关性。我们观察到,在较高级别检索到的中毒文档通常对生成器的响应更具影响力。为了优化攻击性能,最好将中毒文档在检索排名中的位置尽可能高,同时确保与其他文档有足够的边距,以减轻后续优化步骤中的潜在排名波动。
AWF 引入了一个稳定性指标Dst一个b我l我ty,量化中毒文档检索等级的稳健性:

哪里Sdocp和Sdoc0分别是具有 poisoned document 的查询和排名最高的 benign document 的相似性分数,D一个vg是连续k文件,定义如下:

自适应加权参数α然后根据Dst一个b我l我ty使用 Sigmoid 函数:

Sigmoid 函数σ(⋅),确保α在 Range 内保持有界0,1,控制关节优化期间检索器的权重。
这种动态调整机制使 Joint-GCG 能够自适应地平衡检索和生成目标的优化,从而在不同的 RAG 系统配置中产生更有效、更健壮的中毒攻击。
5实验
5.1实验装置
进行了全面的实验评估,以严格评估我们的 Joint-GCG 框架的有效性,包括靶向和批量查询中毒场景。我们根据最先进的基线 -- PoisonedRAG 评估了 Joint-GCG 的性能[11](https://arxiv.org/html/2506.06151v1#bib.bib11 "11")(使用 GCG[24](https://arxiv.org/html/2506.06151v1#bib.bib24 "24")在发电机上)、骗子[13](https://arxiv.org/html/2506.06151v1#bib.bib13 "13")和 Phantom[15](https://arxiv.org/html/2506.06151v1#bib.bib15 "15")-- 在各种条件下。这种全面的评估包括专注于靶向查询中毒、消融研究、合成语料库评估、黑盒可转移性、批量查询中毒和扩展攻击步骤的实验(附录 E)。我们还研究了常见防御机制对 Joint-GCG 的影响(第 5.3 节)。
5.1.1数据
根据 RAG 的先前工作,我们使用三个广泛使用的开放域问答 (QA) 数据集来评估我们的方法。这些数据集旨在测试 QA 模型中检索和推理的各个方面,确保对不同问题类型和检索挑战进行全面评估。
- •
**马可女士[34](https://arxiv.org/html/2506.06151v1#bib.bib34 "34"):**Microsoft Machine Reading Comprehension (MS MARCO) 数据集是信息检索和问答的大规模基准。它由从 Bing 搜索日志中采样的真实查询组成,并从 Web 文档中提取的段落作为候选答案。我们的实验使用由我们比较的基线确定的查询的一些子集。 - •
**自然问题 (NQ)[35](https://arxiv.org/html/2506.06151v1#bib.bib35 "35"):**此数据集由用户在 Google 搜索中自然提出的问题组成,并从 Wikipedia 文章中提取人工注释的答案。与专注于搜索引擎查询的 MS MARCO 不同,NQ 强调从结构化来源中提取事实知识。该数据集对于评估系统从大规模知识库中检索和提取简明答案的能力特别有用。 - •
**火锅 QA[36](https://arxiv.org/html/2506.06151v1#bib.bib36 "36"):**一个多跃点问答数据集,需要对多个文档进行推理才能得出正确答案。与通常在单段文章中找到答案的单跳 QA 数据集不同,HotpotQA 需要集成不同文档的信息,使其成为评估模型处理复杂推理任务能力的出色基准。
对于每个数据集(MS MARCO、NQ、HotpotQA),我们指示 GPT-4o-mini 生成与相应数据集中的查询相关的文档的合成语料库。我们为每个目标查询生成了包含 10 个合成文档的语料库。虽然不代表现实世界的知识,但这些合成语料库充当代理检索环境,我们可以在其中模拟检索排名并计算 AWF 的稳定性指标。我们用于生成合成语料库的提示如下:
"您是一名创意助理。给定查询 '{query}',其正确答案为: '{correct_answer}',请生成 11 个不同且密切相关的句子或短段落。每个语料库都应该是不同的,并涵盖与查询相关的不同方面。将每个语料库格式化为以 - 开头的单独项目符号。请避免任何其他 Markdown 或格式设置。 "
我们使用与先前作品中相同的样本,以确保公平的比较。
在实验 5.2.1、5.2.2、5.2.3 和 5.2.5 中用于与 PoisonedRAG 和 LIAR 进行比较的数据集由 100 个查询组成,每个查询由 PoisonedRAG 从 MS MARCO、NQ 和 HotpotQA 数据集中采样。
为了与实验 5.2.4 中的 Phantom 进行比较,我们对每个触发器使用了包含 25 个查询的相同数据集。每个查询都由 Phantom 从 MS MARCO 数据集中采样,并选择包含特定的触发词。
5.1.2Retriever 模型
我们试验了两种广泛使用的密集检索模型,以评估我们的 Joint-GCG 框架在不同检索机制中的有效性。这些模型利用神经嵌入将查询和文档编码到共享向量空间中,从而促进通过相似性搜索进行高效检索。
- •
**集成[37](https://arxiv.org/html/2506.06151v1#bib.bib37 "37"):**一种基于对比学习的检索模型,专为无监督句子嵌入而设计。Contriever 使用对比损失进行训练,它鼓励相似的文本对具有更紧密的嵌入,同时将不相关的对分开。这种方法在检索任务中表现出强大的性能,尤其是在零样本和低资源环境中,使其成为开放域 QA 场景的可靠选择。我们在这里使用 contriever-msmarco 模型。 - •
**BGE (BAAI 通用嵌入)[38](https://arxiv.org/html/2506.06151v1#bib.bib38 "38"):**由北京人工智能研究院 (BAAI) 开发的一系列嵌入模型,针对检索任务进行了明确优化。BGE 模型使用大规模数据集进行训练,旨在生成高效的表示,从而促进在近似最近邻 (ANN) 搜索中快速准确地检索。它们在密集检索任务中的有效性使其成为传统检索方法的有竞争力的替代方案。我们在这里使用 BGE-base-en-v1.5 模型。
5.1.3生成器模型
为了评估我们的攻击对最先进的生成器模型的影响,我们对多个 LLM 进行了实验。选择这些模型是基于它们在各种 NLP 任务中的出色表现、开源可用性以及在研究和应用中的广泛使用。
- •
**美洲驼3-8B[39](https://arxiv.org/html/2506.06151v1#bib.bib39 "39"):**由 Meta AI 开发的尖端开源 LLM,拥有 80 亿个参数。作为非常成功的 Llama 和 Llama 2 模型的继任者,Llama3 旨在提供卓越的推理、理解和响应生成能力。它的可访问性和最先进的性能使其成为评估 RAG 场景中对抗性稳健性的有力候选者。 - •
**Qwen2-7B[40](https://arxiv.org/html/2506.06151v1#bib.bib40 "40"):**由阿里云开发的 70 亿参数模型,是 Qwen 系列的一部分。Qwen2 以其强大的多语言能力和高效的推理而闻名,使其成为实际应用的有竞争力的选择。它的训练方法强调知识丰富的反应,这使得评估检索增强攻击如何影响事实生成和推理变得特别有趣。
5.1.4指标
我们使用以下指标来评估中毒攻击的有效性:
- •
**检索攻击成功率 (一个SRret):**在顶部 - 中检索到中毒文档的目标查询的百分比k结果。 - •
世代攻击成功率 (一个SRgen): LLM 为其生成所需目标输出的目标查询的百分比,即生成的输出包含目标。我们使用这种方法与 PoisonedRAG 保持一致[11](https://arxiv.org/html/2506.06151v1#bib.bib11 "11"),因为它与人工评估的差异可以忽略不计。 - •
**中毒文件的位置 (Posp):**平均排名 (1≤Posp≤k) 的 Poisoned 文档。较低的值表示中毒文档的位置越强。
5.1.5实验设置
为了确保可重复性和减少随机性,所有实验都重复了 3 次,对本地 LLM 进行贪婪解码,并将 GPT-4o 的温度设置为 0。中毒文档是根据 PoisonedRAG 的攻击方案(查询连接)初始化的,在此基础上我们添加了一个可优化的序列。对于所有实验,我们从语料库中检索前 5 个相关文档,并按照相应基线的聊天模板进行生成。所有实验均在具有 256GB RAM 和一个 NVIDIA RTX A6000 GPU 的机器上进行。
所有实验均在相同的条件下进行,以确保与基线方法进行严格和公平的比较。至关重要的是,在将 Joint-GCG 与 LIAR 和 Phantom 等现有方法进行比较时,我们保持了对所有模型组件(检索器和生成器)的同等级别的白盒访问。此外,关键实验参数,包括优化步骤的数量、可优化的序列长度和数据集样本,在所有比较方法中保持一致。
在比较 Joint-GCG 与使用 GCG 和 LIAR 的 PoisonedRAG 的实验(实验 5.2.1、5.2.2、5.2.3 和 5.2.5)中,我们将可优化序列长度设置为 32 个标记,将优化步骤设置为 64。我们采用了 GCG 的变体,MCG[15](https://arxiv.org/html/2506.06151v1#bib.bib15 "15"),以提高攻击效率,并利用其默认超参数。我们明确将 Batch Size 设置为 128,TopK 设置为 16,对攻击使用了仅限 ASCII 字符的 Token,并将优化目标配置为错误的答案。对于 LIAR 方法,我们对可优化序列长度(检索器和生成器各 16 个标记)和优化步数(检索器和生成器各 8 步)使用了 1:1 的比例,首先攻击检索器,然后是生成器。
在实验 5.2.4 中,我们采用了相同的Scmd在 Phantom 中针对拒绝服务攻击规定,并在其上连接可优化序列。由于计算耗时,我们只进行了一轮实验。我们将 optimable sequence 设置为 128,优化步数设置为 32。对于 Phantom,我们遵循了他们的设置,使用检索器可优化的序列长度 128 和生成器可优化的序列长度 8。对于这两种方法,我们提前对 128 个检索器令牌执行了 256 个 GCG 步骤,以确保批量查询的稳健检索率,从而促进生成器可优化令牌的进一步优化。
为了将 Joint-GCG 与 PoisonedRAG 和 LIAR 进行比较,我们使用了与 PoisonedRAG 的黑盒检索器方法相同的数据,使用他们第一个生成的假语料库11可在 PoisonedRAG 的官方 GitHub 存储库中获得。的数据集。我们在假语料库的开头添加一个可优化的序列,用 "!" 初始化。
为了与幻影(实验 5.2.4)进行比较,这些文件由三个部分组成,按照他们的工作规定连接在一起,Sret,Sgen和Scmd分别。我们首先初始化了Sret替换为 "?" 和Sgen替换为 "!"。
表 I:一个SR和平均值pospGCG、LIAR 和 Joint-GCG 的 64 个优化步骤。括号中的值 (一个SRgen) 表示 ASR,专门用于初始 (未优化) 攻击失败的查询,从而证明优化的有效性。
|--------|-------------|--------------|-------------------|-------------------|-------------------|-------------------|-------------------|-------------------|
| 猎犬 | 指标 | 数据 | 马可女士 || 南 || 火锅 QA ||
| 猎犬 | 指标 | 攻击 / LLM | 美洲驼3 | Qwen2 | 美洲驼3 | Qwen2 | 美洲驼3 | Qwen2 |
| 集成 | 一个SRret | GCG | 96.00% | 95.67% | 72.00% | 72.00% | 94.33% | 97.00% |
| 集成 | 一个SRret | 说谎者 | 100.00% | 100.00% | 93.33% | 96.33% | 99.00% | 100.00% |
| 集成 | 一个SRret | 联合 GCG | 100.00% | 100.00% | 99.00% | 99.00% | 100.00% | 100.00% |
| 集成 | 一个SRgen | GCG | 90.0% (76.7%) | 91.0% (80.0%) | 72.0% (41.5%) | 70.0% (39.0%) | 90.3% (76.7%) | 97.0% (87.5%) |
| 集成 | 一个SRgen | 说谎者 | 89.0% (74.4%) | 95.3% (88.9%) | 89.0% (73.2%) | 86.0% (68.3%) | 92.0% (81.4%) | 98.0% (91.7%) |
| 集成 | 一个SRgen | 联合 GCG | 94.0% (86.0%) | 96.3% (91.1%) | 92.0% (82.9%) | 95.0% (87.8%) | 97.3% (93.0%) | 99.0% (95.8%) |
| 集成 | 一个SRgen | 无优化 | 51.0% | 49.0% | 50.0% | 34.0% | 59.0% | 60.0% |
| 集成 | Posp↓ | GCG | 1.36 | 1.43 | 2.59 | 2.56 | 1.46 | 1.2 |
| 集成 | Posp↓ | 说谎者 | 1.13 | 1.08 | 1.52 | 1.43 | 1.14 | 1.06 |
| 集成 | Posp↓ | 联合 GCG | 1.01 | 1.05 | 1.25 | 1.22 | 1.04 | 1.01 |
| BGE | 一个SRret | GCG | 74.00% | 73.30% | 96.00% | 98.67% | 100.00% | 100.00% |
| BGE | 一个SRret | 说谎者 | 99.00% | 97.30% | 100.00% | 100.00% | 100.00% | 100.00% |
| BGE | 一个SRret | 联合 GCG | 99.00% | 99.00% | 100.00% | 100.00% | 100.00% | 100.00% |
| BGE | 一个SRgen | GCG | 68.0% (60.7%) | 67.0% (57.1%) | 93.0% (89.1%) | 97.0% (95.5%) | 98.0% (95.9%) | 99.0% (97.4%) |
| BGE | 一个SRgen | 说谎者 | 83.7% (78.6%) | 92.0% (85.7%) | 89.3% (80.0%) | 93.0% (86.4%) | 93.7% (85.7%) | 96.0% (89.5%) |
| BGE | 一个SRgen | 联合 GCG | 87.0% (85.7%) | 92.0% (85.7%) | 93.0% (87.3%) | 97.7% (95.5%) | 99.0% (98.0%) | 99.0% (97.4%) |
| BGE | 一个SRgen | 无优化 | 31.0% | 27.0% | 39.0% | 31.0% | 46.0% | 46.0% |
| BGE | Posp↓ | GCG | 2.87 | 3.02 | 1.36 | 1.23 | 1.04 | 1.01 |
| BGE | Posp↓ | 说谎者 | 1.5 | 1.69 | 1.04 | 1.07 | 1.01 | 1.01 |
| BGE | Posp↓ | 联合 GCG | 1.38 | 1.47 | 1.06 | 1.07 | 1.01 | 1.01 |
5.2实验结果
5.2.1目标查询中毒:基线比较
为了评估 Joint-GCG 在靶向查询中毒中的有效性,我们将其与最先进的中毒方法进行了比较,特别是 PoisonedRAG 和发电机上的 GCG(下面表示为 GCG)和 LIAR。我们为每个目标查询注入一个中毒文档,并使用一个SRret,一个SRgen和Posp.
如表 I 所示,Joint-GCG 在以下方面始终优于 GCG 和 LIAR一个SRret和一个SRgen在各种设置中。具体来说,Joint-GCG 成功地保持了近乎完美的一个SRret (100%) 的所有数据集中的 Llama3 和 Qwen2。Joint-GCG 在攻击生成阶段明显超过了 GCG 和 LIAR,尤其是在 NQ 和 HotpotQA 数据集上。例如,Joint-GCG 的产量高达99.0% 一个SRgen对于 Llama3 和95.8%对于 HotpotQA 上的 Qwen2,其性能比 GCG 和 LIAR 高出几个百分点。
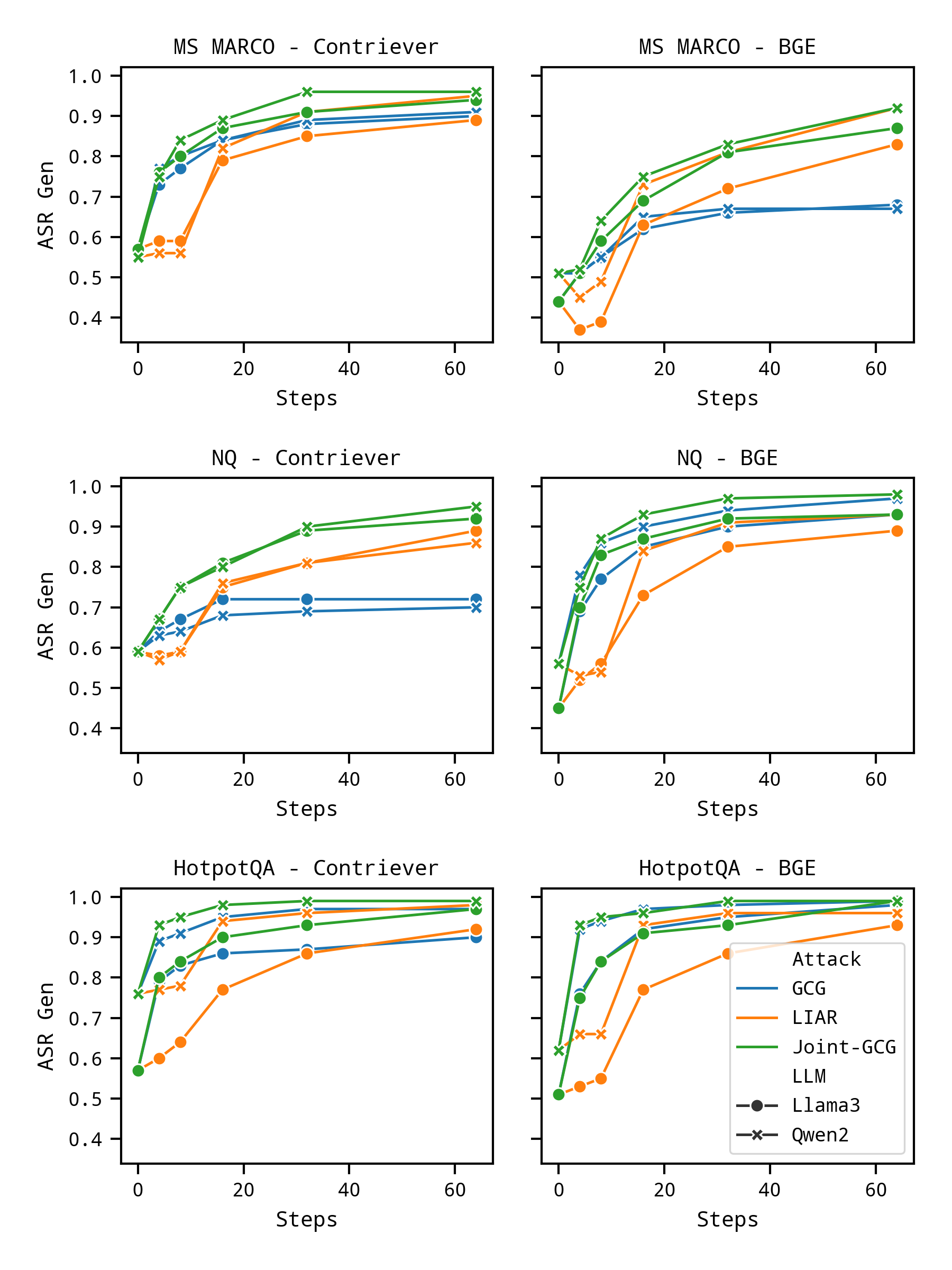
图 3:一个SRgenGCG、LIAR 和 Joint-GCG 在各种优化步骤中。
此外,Joint-GCG 具有更好的疗效(即,达到更高的一个SRgen在较少的优化步骤中)。图 3 直观地证实了 Joint-GCG 的卓越疗效,表明它达到了相当或更高的疗效一个SRgen同时需要的优化步骤明显较少。这种更快的收敛突显了 Joint-GCG 在针对性查询中毒攻击中增强的效率和有效性。
Joint-GCG 的性能提升源于其集成检索器和生成器梯度的创新方法。这有效地防止了检索降级,并确保了整个优化过程中中毒的有效性和成功率。中毒语料库的索引排名始终较高,凸显了 Joint-GCG 作为靶向查询中毒的领先方法的优势,尤其是在高文档排名对于有效生成器作至关重要的对抗性环境中。
5.2.2消融研究
为了分析 Joint-GCG 中每个组件的贡献,我们进行了消融研究,删除了关键模块并评估了它们对攻击性能的影响。
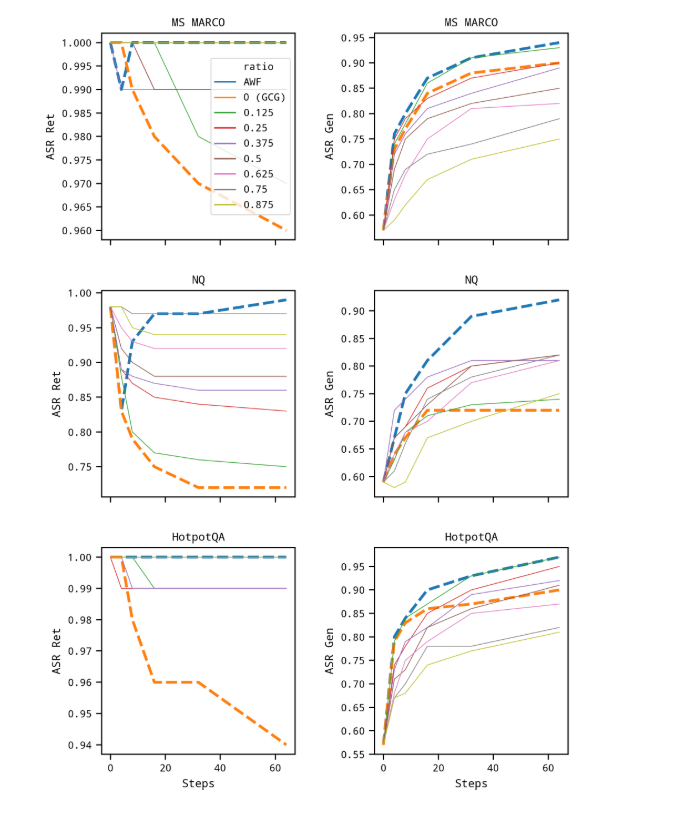
图 4:一个SR的 Joint-GCG 具有各种固定重量和 AWF,使用 Contriver 作为检索器,Llama3 作为生成器。
跨词汇投影 (CVP) 和梯度标记化对齐 (GTA) 的影响
我们进行了一项消融研究,以评估 CVP 和 GTA 模块的影响。由于它们是相互依存的,因此它们被同时删除。在这种配置中,我们框架中的优化完全依赖于生成器端的梯度,因为由于梯度形状中固有的不匹配,直接融合是不可行的。因此,基线是在 Joint-GCG 结构中仅使用生成器梯度的变体。
如表 II 所示,去除 CVP 和 GTA 导致 ASR 适度但持续下降。虽然看起来很微妙,但与已经有效的纯生成器优化策略相比,实现额外的收益本身就具有挑战性。这 2% 的绝对平均改善代表了测试集中的几个额外的成功中毒。它意味着攻击效力的显著增强,尤其是在安全关键型场景中,每一次成功的入侵都至关重要。
表 II:一个SRgen删除了 CVP 和 GTA,并且一个SRgen跟Lossgen仅跨数据集和生成器,使用 Contriever 作为检索器。
| 数据 | 设置 | 美洲驼3 | Qwen2 |
| 马可女士 | 全接头-GCG | 94.00% | 96.33% |
| 马可女士 |
| 马可女士 |
| 马可女士 |
|---------------|---------|------------|------------|
| 无 CVP + GTA | 93.33% | 96.00% |
| 无Lossret | 91.00% | 92.33% |
| 基础 (GCG) | 90.00% | 91.00% |
| 无 CVP + GTA | 91.00% | 93.00% |
| 无Lossret | 86.67% | 94.00% |
| 基础 (GCG) | 72.00% | 70.00% |
| 无 CVP + GTA | 95.00% | 99.00% |
| 无Lossret | 91.33% | 98.67% |
| 基础 (GCG) | 90.00% | 97.00% |
猎犬侧损失的影响
为了进一步研究检索器成分的贡献,我们通过去除检索器侧损失 (Lossret) 选择最佳候选项。
如表 II 所示,删除Lossret导致一个SRgen跨所有数据集和生成器。具体来说,对于 MS MARCO,一个SRgenLlama3 从 94.00% 下降到 91.00%,Qwen2 从 96.33% 下降到 92.33%。NQ 也观察到类似的趋势,其中对 Llama3 的 HotpotQA 影响最为显著,其中一个SRgen从 97.33% 下降到 91.33%。这些结果强调了检索器侧损失在指导优化过程向更有效的中毒文档发展方面的关键作用。
自适应加权融合 (AWF) 的影响
如图 4 所示,我们尝试了不同的固定检索生成梯度权重,发现 AWF 带来了最佳性能。值得注意的是,AWF 在以下方面表现出优于或可比所有固定比率的性能一个SRret.这一改进突出了 AWF 的自适应方法,有效地平衡了检索器和发电机的优化,同时根据需要动态调整检索器重量以防止降解。
表 III:一个SRs 在 MS MARCO 数据集上使用各种检索器和生成器,将 Joint-GCG 与真实的 top-k 检索和基于合成语料库的 AWF 进行比较。
| 猎犬 | 指标 | 设置 | 美洲驼3 | Qwen2 |
|---|---|---|---|---|
| 集成 | 一个SRret | 真正 | 100.00% | 100.00% |
| 集成 | 一个SRret | 合成 | 100.00% | 100.00% |
| 集成 | 一个SRret | 无优化 | 98.00% | 98.00% |
| 集成 | 一个SRgen | 真正 | 94.00% | 96.33% |
| 集成 | 一个SRgen | 合成 | 62.00% | 58.00% |
| 集成 | 一个SRgen | 无优化 | 51.00% | 49.00% |
| BGE | 一个SRret | 真正 | 99.00% | 99.00% |
| BGE | 一个SRret | 合成 | 89.33% | 84.00% |
| BGE | 一个SRret | 无优化 | 70.00% | 70.00% |
| BGE | 一个SRgen | 真正 | 87.00% | 92.00% |
| BGE | 一个SRgen | 合成 | 41.00% | 36.67% |
| BGE | 一个SRgen | 无优化 | 31.00% | 27.00% |
表 IV:一个SRgen的 Joint-GCG 用于三个触发器的批量中毒,使用 Llama3 作为生成器,使用 Contriever 作为检索器,目标是拒绝服务。括号中的值 (一个SRgen) 表示 ASR,专门用于初始 (未优化) 攻击失败的查询,从而证明优化的有效性。
| 触发 | 起音 / 步长 | 0 | 4 | 8 | 16 | 32 |
|---|---|---|---|---|---|---|
| 亚马逊河 | 幽灵 | 76.00% | 76.00% (16.67%) | 76.00% (33.33%) | 68.00% (16.67%) | 80.00% (33.33%) |
| 亚马逊河 | 联合 GCG | 76.00% | 88.00% (50.00%) | 88.00% (50.00%) | 88.00% (50.00%) | 88.00% (50.00%) |
| XBOX 的 | 幽灵 | 80.00% | 80.00% (0.00%) | 84.00% (20.00%) | 84.00% (40.00%) | 84.00% (40.00%) |
| XBOX 的 | 联合 GCG | 80.00% | 92.00% (60.00%) | 92.00% (60.00%) | 92.00% (60.00%) | 92.00% (60.00%) |
| 苹果手机 | 幽灵 | 88.00% | 84.00% (0.00%) | 88.00% (0.00%) | 88.00% (33.33%) | 88.00% (33.33%) |
| 苹果手机 | 联合 GCG | 88.00% | 92.00% (100.00%) | 92.00% (100.00%) | 92.00% (100.00%) | 96.00% (100.00%) |
5.2.3合成语料库:消除 Top-k 检索依赖
在实际场景中实施 Joint-GCG 的一个实际挑战是访问顶层k检索结果来攻击生成器并计算稳定性指标Dst一个b我l我ty用于 AWF。这需要在攻击期间查询实际的检索器,这在特定设置中可能会受到限制。为了解决这一限制并探索更独立的攻击策略的潜力,我们研究了使用 LLM 生成的合成语料库来模拟检索环境并启用 AWF 计算,而无需依赖实时 top-k检索。
表 III 揭示了 Joint-GCG 可以有效地利用合成语料库,大大减少了对 top-k 检索结果的依赖。虽然与实际语料库数据相比存在一些性能差异,一个SRgen使用合成语料库实现的目标仍然值得称赞。例如,即使使用合成语料库,Joint-GCG 也达到 62%一个SRgen与 Contriever 和 Llama3 合作,展示了扎实的攻击能力。这一结果强调了 Joint-GCG 的实用性,使其能够应用于难以获取实时检索信息的场景。
5.2.4扩展到 Batch Query 中毒
批量查询中毒是一种更具挑战性的场景,其中单个中毒文档旨在纵 RAG 系统对多个不同目标查询的响应。我们评估了 Joint-GCG 在此设置下的性能,将其与 Phantom 进行比较,Phantom 是一种专为基于触发器的批量中毒而设计的方法。我们按照他们规定的拒绝服务 (DoS) 设置执行攻击。我们在目标查询上使用 mean gradient 和 loss 来指导优化。
表 IV 展示了该实验的结果。Joint-GCG 在所有测试的触发器关键词和优化步骤中始终优于 Phantom。Joint-GCG 的成就显著提高一个SRgen值在早期优化步骤中,而 plateaus 则具有更高的成功率。例如,在"xbox"触发器上,Joint-GCG 达到高一个SRgen在第 4 步为 92%,而 Phantom 则稳定在较低的 80%。这些结果表明,Joint-GCG 在批量查询中毒方面具有强大的能力,与 Phantom 相比,可以更有效、更快速地收敛到高攻击成功率。这凸显了 Joint-GCG 的多功能性及其在 RAG 系统作中更广泛的应用潜力,而不仅仅是有针对性的单个查询。
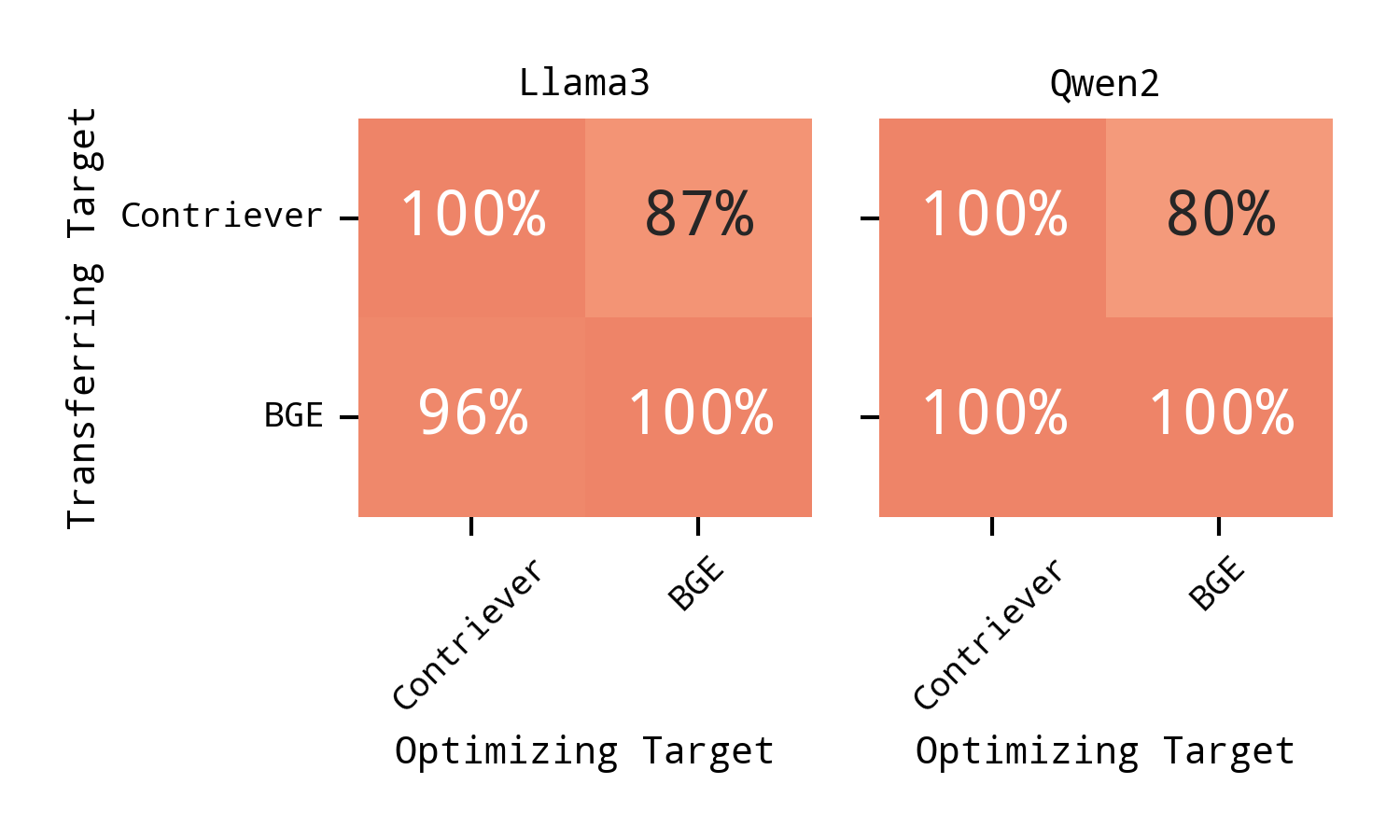
图 5:一个SRRet当毒物在各种 Retriever 上得到优化时,在 MS MARCO 数据集上使用 Llama3 / Qwen2 生成器在 Transferring Target Retriever 上进行评估。
5.2.5评估毒药泛化
评估 RAG 中毒攻击构成的实际威胁的一个关键方面是评估生成的毒药的泛化能力。如果为特定的已知模型("代理")制作的毒药被证明对其他未知模型有效,则它验证了更真实的灰盒攻击场景。在这种情况下,攻击者将对他们控制的开源模型执行计算密集型联合优化,然后将生成的毒药部署到确切组件未知的目标系统上。我们研究了泛化的两个关键维度:交叉检索器可转移性和交叉生成器可转移性。
交叉检索器可转移性
为了评估针对一种猎犬优化的毒药对另一种猎犬的表现,我们使用 Joint-GCG 进行了实验,其中生成器模型是固定的,毒药在 Contriever 和 BGE 猎犬模型之间转移。图 5 所示的结果证明了显著的可转移性。值得注意的是,毒药表现出强烈的交叉检索转移。例如,以 Llama3 作为固定生成器,针对 BGE 优化并转移到 Contriever 的毒药保持较高的一个SRret的 96%,而针对 Contriever 优化并转移到 BGE 的毒药实现了一个SRret87%。以 Qwen2 作为生成器时也观察到了类似的模式,其中 BGE 优化的毒药通过一个SRret的 100%,并且 Contriever 优化的毒药通过一个SRret的 80%。这些发现表明,Joint-GCG 制造的毒药可以有效地破坏不同的猎犬模型。强大的可转移性,特别是从 BGE 优化的毒药到 Contriever,表明一些习得的对抗特征在检索器架构中是稳健的。这增强了实际威胁,因为即使攻击者不确切了解部署的检索器,也可能获得成功。
跨发电机可转移性
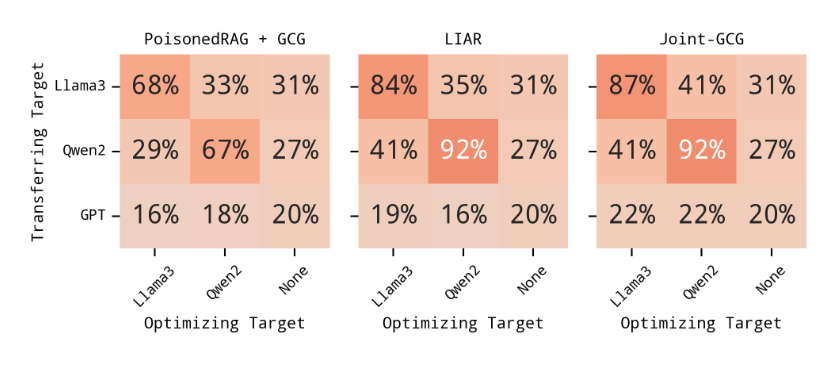
图 6:一个SRgen当毒物在各种生成器上得到优化时,将在 MS MARCO 数据集上使用 BGE 检索器传输目标生成器进行评估。优化目标中的"None"表示未优化的初始样本。
我们评估了由 PoisonedRAG 使用 GCG、LIAR 和 Joint-GCG 优化的中毒文档影响其他生成器的能力,包括开源模型(Llama3、Qwen2)和黑盒模型 (GPT-4o)。比较结果如图 6 所示。
关于开源模型 Llama3 和 Qwen2 之间的可转移性,Joint-GCG 显示出一致的转移:针对 Llama3 优化的毒物实现了一个SRgen在 Qwen2 上达到 41%,而针对 Qwen2 优化的毒药则达到了一个SRgenLlama3 的 41%。LIAR 表现出从 Qwen2 到 Llama3 的相似转移 (41%),但从 Llama3 到 Qwen2 的转移略少 (35%)。GCG 的 PoisonedRAG 在两个方向上都显示出较低的可转移性 (Llama3 到 Qwen2 为 33%,Qwen2 到 Llama3 为 29%)。值得注意的是,这种优化驱动的可转移性甚至扩展到 GPT-4o 等黑盒商业 LLM[41](https://arxiv.org/html/2506.06151v1#bib.bib41 "41").虽然针对 GPT-4o 的绝对 ASR 较低,但与未优化的毒药相比,针对 Llama3 或 Qwen2 优化的毒药的攻击成功率仍然显着增加 (2%),这在以前的攻击方法中是看不到的。这些发现强调,RAG 系统面临的攻击面比以前理解的更广泛、更普遍,因为攻击者可以通过对现成模型进行有针对性的优化来增强跨生成器毒物的可转移性。
5.3可能的防御机制
在这里,我们报告了评估两种广泛使用的 Joint-GCG 防御策略的结果:基于困惑的过滤[42](https://arxiv.org/html/2506.06151v1#bib.bib42 "42")和 SmoothLLM[43](https://arxiv.org/html/2506.06151v1#bib.bib43 "43").
5.3.1平滑 LLM
SmoothLLM 是一种基于扰动的防御机制,旨在通过向输入注入受控噪声来对抗性攻击。这种方法巧妙地改变了 LLM 的输入,保留了预期的含义,同时减轻了对抗性扰动的影响。在我们的实验中,我们按照 SmoothLLM 的规定应用了噪声比为 5% 的交换排列。
表 V:一个SRgen和正确答案率 (C一个R),当 MS MARCO 上部署了 SmoothLLM 时,未应用任何攻击。
| 猎犬 | 发电机 | 美洲驼3 || Qwen2 ||
| 猎犬 | 平滑 LLM | 无 | w/ | 无 | w/ |
| 续 | C一个R(无攻击) | 77% | 72% | 71% | 66% |
| 续 | 一个SRgen | 94% | 53% | 96% | 56% |
| BGE | C一个R(无攻击) | 87% | 85% | 85% | 82% |
| BGE | 一个SRgen | 87% | 47% | 92% | 41% |
|---|
如表 V 所示,虽然 SmoothLLM 减少了 Joint-GCG 的一个SRgen,即使在这种防御下,攻击仍然非常强大。对于 Contriever-retriever 系统,Joint-GCG 达到 53%一个SRgen在 Llama3 上和 56% 在 Qwen2 上启用 SmoothLLM。
在防御下攻击的持续成功凸显了 Joint-GCG 的稳健性。即使被 SmoothLLM 衰减,攻击成功率仍然与先前方法的不设防 性能相当(例如,GCG 约为 70%)一个SRgen在表 I 中)。这表明 Joint-GCG 的联合优化范式从根本上提高了攻击生存能力,这标志着防御机制面临的挑战,并且需要对检索感知对抗性过滤进行新的研究。
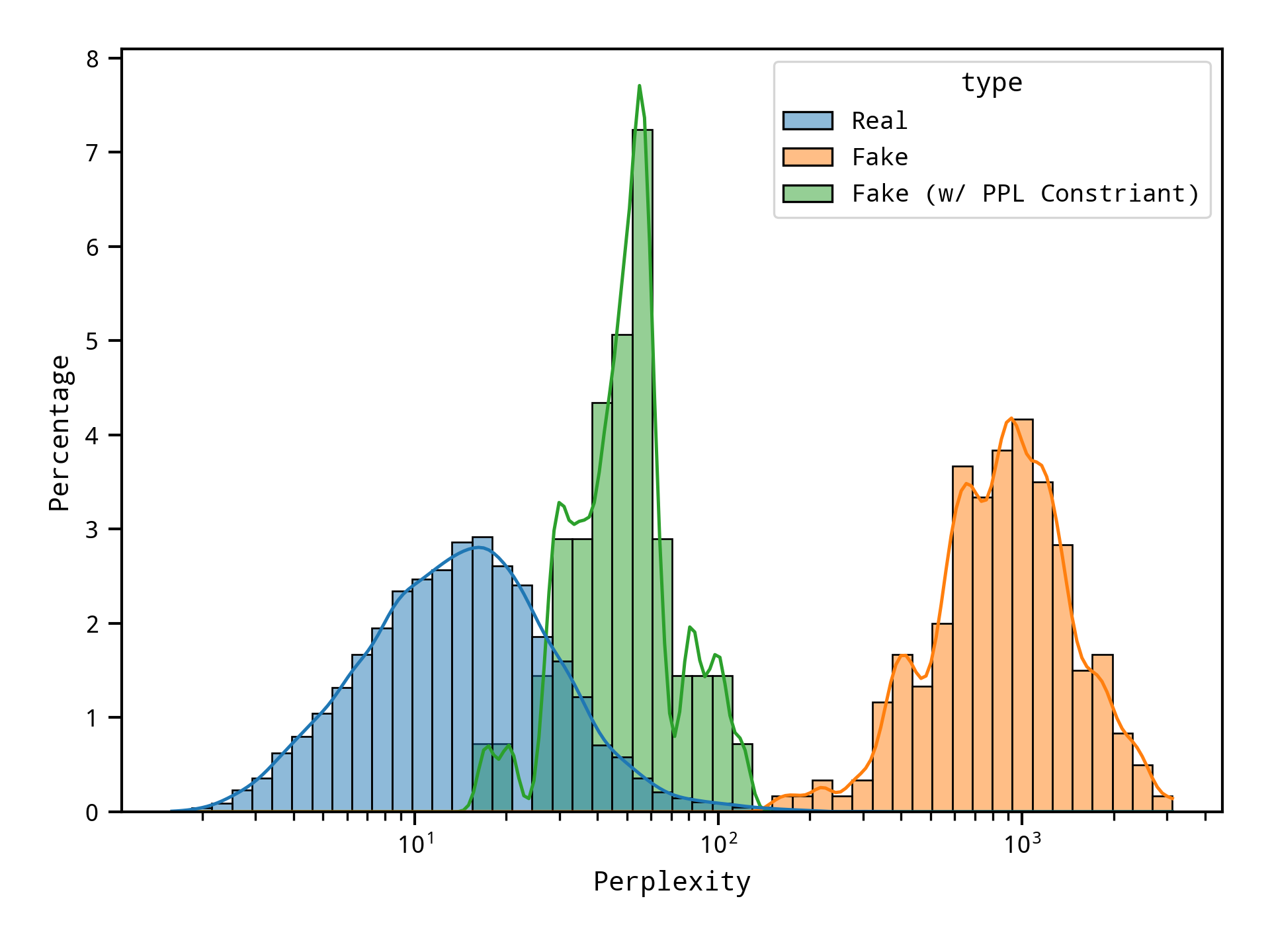
图 7:MS MARCO 中真实语料库的困惑百分比直方图和由 Joint-GCG 优化的假语料库。
5.3.2基于困惑度的过滤
基于困惑度的过滤涉及使用困惑度分数来评估语料库的可能性,并过滤掉超过特定阈值的文档。这种方法旨在减少系统检索到的不太相关或虚假信息所引入的噪声。具体来说,我们计算了 MS MARCO 语料库和相应的 Joint-GCG 优化毒药对 Llama3 的困惑度。如图 7 所示,与实际的 MS MARCO 语料库相比,Joint-GCG 优化对抗示例的困惑度分布明显向更高的困惑度值转变。这表明困惑可能是识别和过滤对抗性示例的潜在指标。
表 VI:一个SR在 MS MARCO 上使用 Contriever 和 Qwen2 进行 32 个优化步骤的 Joint-GCG with PPL Constraint。
| 设置 | 一个SRRet | 一个SRgen |
| 带 PPL 约束的 Joint-GCG | 100.00% | 73.33% |
| 无优化 | 100.00% | 49.00% |
|---|
我们在攻击优化过程中实施了一个约束,以研究针对 Joint-GCG 的基于困惑的过滤的有效性。具体来说,我们合并了一个困惑约束,通过在优化过程中过滤掉超过阈值的候选对抗性样本,确保生成的对抗性样本保持在标准 MS MARCO 语料库的困惑分布内。
表 VI 显示了攻击成功率。值得注意的是,即使使用困惑约束进行优化,Joint-GCG 也保持了明显更高的一个SRgen比不执行优化的基线情景更重要,具有 perplexity 约束的 Joint-GCG 为 73.33%,而没有优化时仅为 54.00%。这种明显的增加表明,基于困惑的滤波,以最简单的形式,对 Joint-GCG 是不够的。即使对抗性示例被设计为具有正常范围内的困惑度值,攻击仍然有效,并大大超过基线 ASR。这凸显了需要更高级的防御措施来检测超出简单困惑阈值的对抗性示例。
6结论
我们提出了 Joint-GCG,这是一个通过统一检索生成基于梯度的优化来提升 RAG 中毒的框架。通过跨词汇投影、梯度标记化对齐和自适应加权融合来协调检索和生成目标,Joint-GCG 克服了先前攻击的脱节性质。评估显示,与跨多个检索器和生成器的最新方法相比,攻击成功率最多高 25%,平均高 5%,实现更高的一个SR在相同的优化步骤中。消融证实了每个成分的作用,而合成语料库测试和毒物泛化实验证明了广泛的适用性。该框架在批量中毒中的潜力进一步强调了其实际威胁。Joint-GCG 提供了一个强大的框架,用于了解和缓解基于 RAG 的应用程序不断变化的威胁形势。
7限制和未来工作
虽然 Joint-GCG 在 RAG 系统中毒方面取得了重大进展,但未来研究的几个重要局限性和有希望的方向值得讨论:
7.1计算开销
与现有方法相比,检索梯度和生成梯度的联合优化引入了额外的计算复杂性(详见附录 F)。首先, CVP 模块涉及对每个检索器-生成器对进行离线、一次性的预计算(在我们的设置中,在单个 NVIDIA A6000 GPU 上大约需要 2 小时),以训练自动编码器并推导出投影矩阵。此成本在矩阵对该对的所有后续攻击的重用中分摊。虽然主要的额外负担是可管理的离线预处理步骤,但未来的工作可能会探索更有效的优化技术或梯度近似方法,以减少这种开销,同时保持攻击的有效性。
7.2跨域泛化
虽然我们在多个 QA 数据集中展示了强大的性能,但 Joint-GCG 的泛化到其他领域(例如,代码生成[44](https://arxiv.org/html/2506.06151v1#bib.bib44 "44")、医疗应用[45](https://arxiv.org/html/2506.06151v1#bib.bib45 "45")和工具调用代理[46](https://arxiv.org/html/2506.06151v1#bib.bib46 "46")) 和不同类型的 RAG 架构需要进一步调查。未来的工作可以探索框架的特定领域调整,并评估其在更广泛的应用程序和模型架构中的有效性。
这些限制和未来方向凸显了对 RAG 系统进行联合优化攻击的初期性质,强调了在 AI 安全这一关键领域进行持续研究的重要性。
8道德考虑
Joint-GCG 框架虽然促进了对 RAG 系统漏洞的理解以提高安全性,但也存在潜在的滥用风险。我们优先考虑负责任的披露,在科学透明度和这些问题之间取得平衡。我们的研究在受控数据集和非生产系统上进行,旨在主动识别漏洞,激励开发强大的防御措施,并鼓励设计安全优先的 RAG 系统。我们强烈主张将这些发现用于安全研究和系统改进,而不是利用。部署 RAG 系统的组织应实施全面的安全措施,包括定期审计、内容过滤和持续监控,因为了解这些漏洞对于构建更安全的 AI 应用程序至关重要。