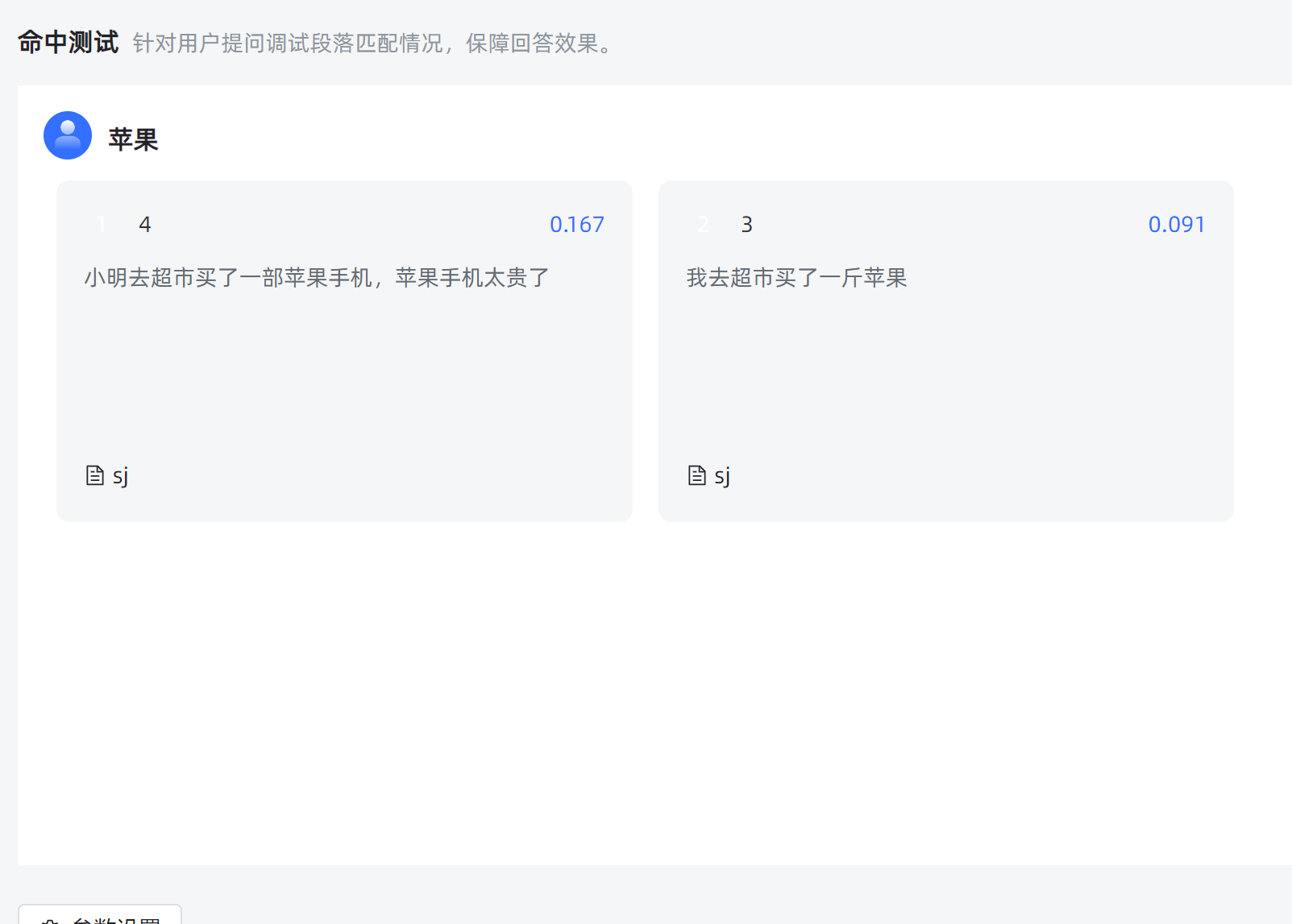
有客户深度使用全文检索模式检索分段,反馈一些专有名词无法被检索到(例如把"小米手机"分成了"小米"和"手机"两个词,对检索结果造成较大干扰),而 MaxKB 的分词器采用流行的 jieba 库,确认了一个临时解决方案。
1、定义自定义字典
cat /opt/my_dic.txt
小米手机 1000 n
苹果手机 1000 n字典组成:{词语}空格{词频}空格{词性}
示例:
小米手机 1000 n
小米手机:自定义词语
1000 :词频,越大优先级越高
n :词性。名词 (n)、专有名词 (nz)、动词 (v)、形容词 (a)、副词 (d)2、将自定义字典文件拷贝到容器中
docker cp /opt/my_dic.txt maxkb:/opt/maxkb/app/apps/common/util/3、split_model.py 引入自定义字典
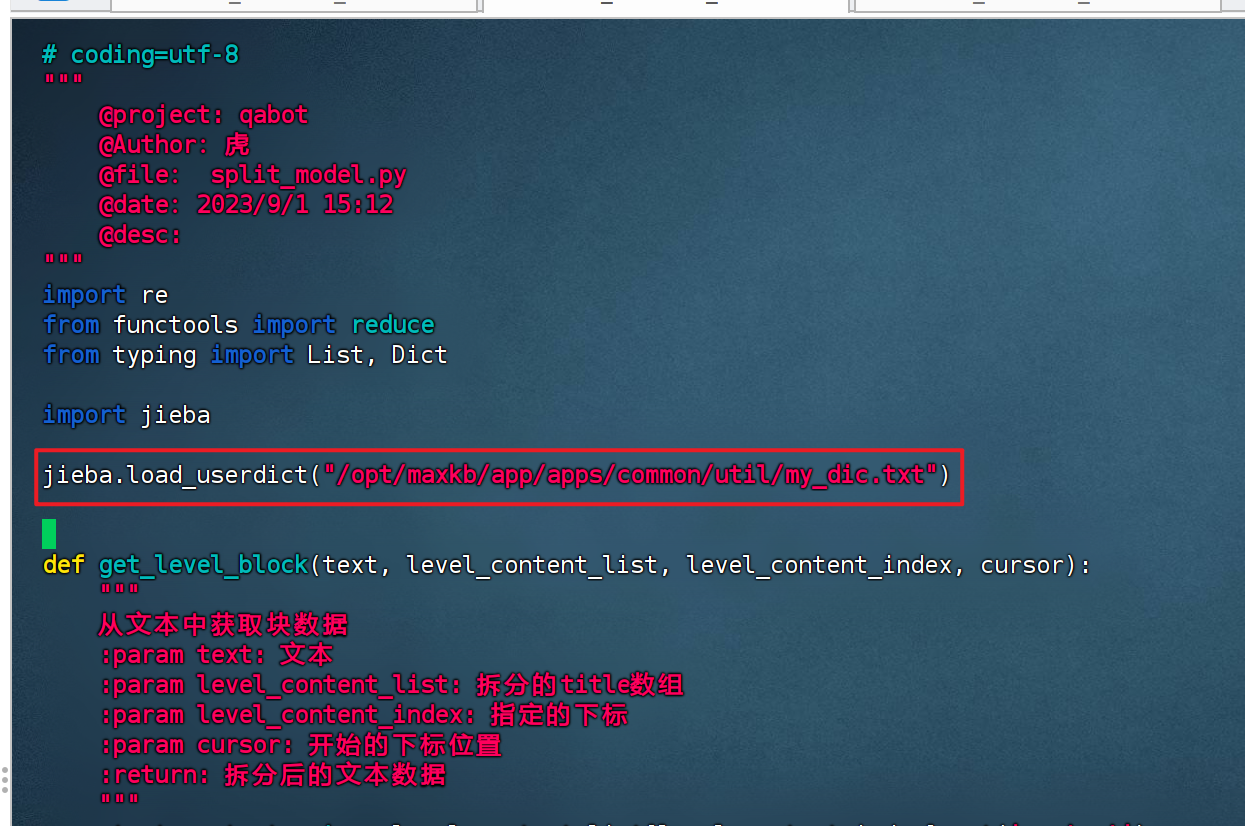
jieba.load_userdict('/opt/maxkb/app/apps/common/util/my_dic.txt')4、测试验证
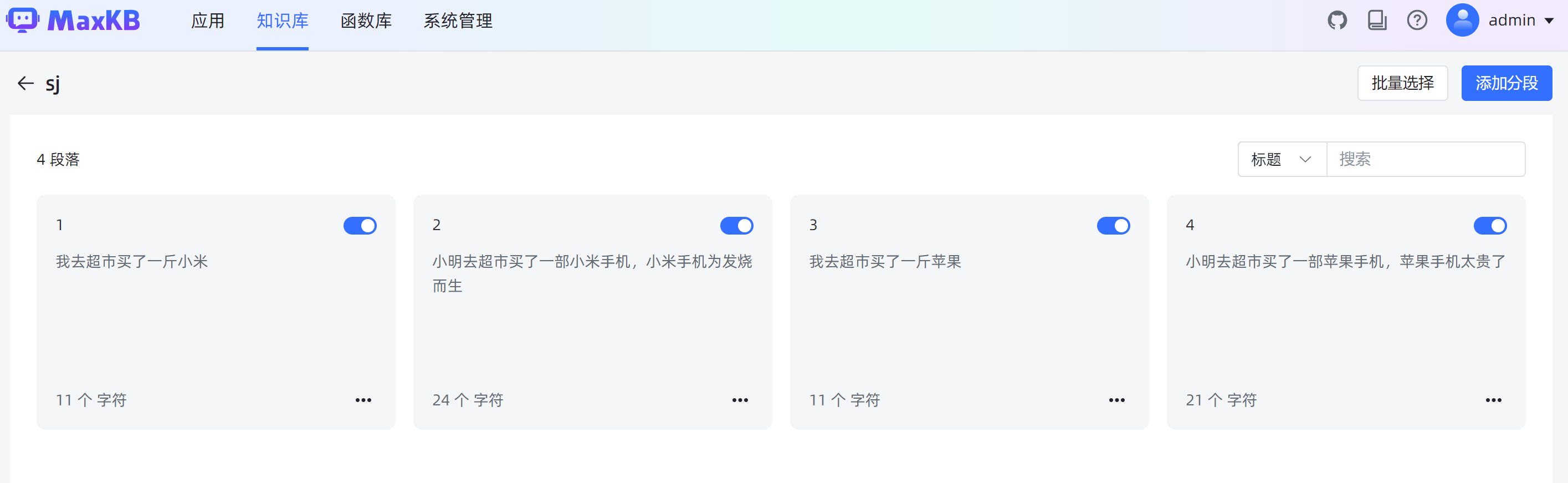
分段情况:
检索结果