TL;DR
- 场景:面向 PDF/图文混排与知识库检索的实际业务,探索 DeepSeek-OCR 的研究与落地路径。
- 结论:以"视觉压缩→结构化→检索/记忆"的三段式为主线,兼顾大模型与蒸馏小模型,按场景选型。
- 产出:研究议题清单、应用 Demo 方向、工程风险清单与错误速查卡。

版本矩阵
| 项目/方向 | 已验证 | 说明 |
|---|---|---|
| 上下文光学压缩→长记忆原型 | 否/规划中 | 基于"旧信息模糊压缩+新信息清晰保留"的分层记忆;需验证解压策略与任务收益曲线。 |
| 跨模态信息抽取(图表/公式→结构化) | 部分/可复现 | 以图文页面直接输出表格/关键信息;对曲线/示意图语义需专门 loss 或后处理。 |
| 行业专科模型(医疗/法律 OCR-VL) | 否/规划中 | 在通用模型上做领域微调与版式先验;评估小样本与合规需求。 |
| 蒸馏与小模型部署(≤0.5B) | 否/规划中 | 目标:在边缘设备维持 2--3× 压缩率与接近精度;需多任务蒸馏管线。 |
| PDF 智能助手 Demo(Python+LLM) | 部分/可复现 | 流程:PDF→Markdown→摘要/问答;适合教程与短视频演示。 |
| 多模态文档检索(以图搜文/以文搜图) | 部分/可复现 | 用文本/视觉 token 做统一 embedding;评估召回与相关度重排。 |
| 光学压缩的理论评估(信息量/注意力可视化) | 否/研究议题 | 信息论度量与注意力热力图分析;形成方法学报告。 |

新型任务与潜在研究方向
无限长上下文的记忆机制
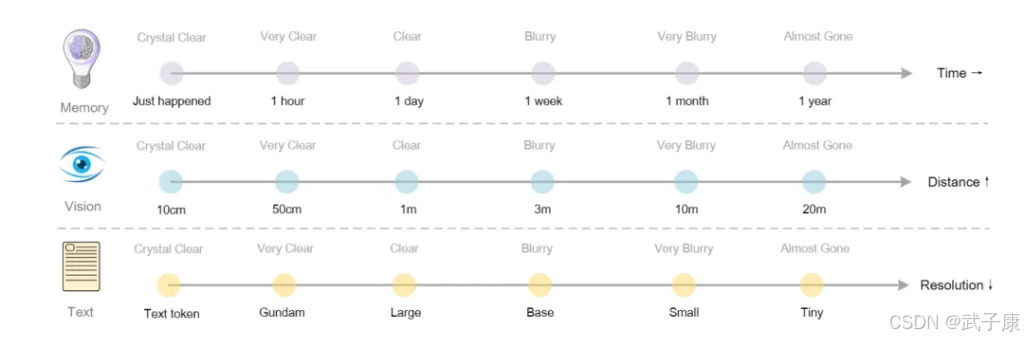
DeepSeek-OCR提出的上下文光学压缩为扩展LLM记忆提供了新思路。未来研究可以基于此探索"无限上下文"模型:模拟人类记忆,将旧对话压缩成模糊图像存储,新的信息用清晰图像保留,模型动态决定何时解压细读。这涉及构建分层记忆模块、研究压缩级别与任务性能的关系,可能催生出类人记忆的对话系统架构。
跨模态信息抽取
利用DeepSeek-OCR的能力,可以研究图文混合信息抽取任务。例如给模型输入一份年报的图表页面,直接让它输出结构化的数据表。或者读取化学实验报告,提取试剂和结果。这需要模型进一步理解视觉中的非文字元素(图表曲线、示意图形状)并关联到文本描述。目前DeepSeek-OCR已经展现了一定潜力,未来可以在此基础上加入专门loss或后处理,提高对复杂文档的"读懂"程度,实现从"识字"到"读懂"。
更大规模与专业领域模型
3B参数的DeepSeek-OCR已经性能惊艳,但深度学习的一般规律是模型更大效果可能更好。未来可研究更大参数的视觉压缩模型,比如30亿、100亿参数甚至稀疏Mixture of Experts进一步扩充。此外,针对特定领域(医疗、法律)的文档,训练专门的OCR-VL模型也是方向。例如"医疗OCR大模型"可融合同位素图像、心电图曲线的解析能力;"法律文档OCR大模型"则对版面和行文格式有特殊优化。这些领域模型可以在DeepSeek-OCR基础上微调得到,用较少资源达到专业级表现。
模型压缩与蒸馏
反过来,对于应用受限于算力的情况,可以研究如何将DeepSeek-OCR的能力蒸馏到小模型上。例如训练一个5亿参数的Tiny版OCR模型,保证压缩能力比传统OCR高2-3倍且精度接近,从而能在边缘设备部署。这涉及知识蒸馏、多任务训练等技术,平衡模型大小和性能,是很有价值的工程研究课题。
视觉压缩的理论探索
从更基础的角度看,DeepSeek-OCR引出了一个有趣的科学问题:视觉表示为何能如此高效地编码语言? 未来研究可从信息论角度量化视觉token的信息量,或者分析模型attention层的权重看看它如何在图像空间定位文字。甚至可以探索不同的"光学压缩"方式,比如用更紧致的视觉字体渲染文本、用颜色/深度等额外通道嵌入信息等,看是否进一步提升压缩率。这样的研究将深化我们对多模态表示的理解。
创新应用点子
几行代码打造PDF智能助手
利用DeepSeek-OCR,可以做一个演示项目:只需几行Python代码,就能让计算机"读懂"PDF。比如读取一个PDF,模型转成Markdown后,再调用GPT模型对Markdown内容进行总结、问答。这可拍成短视频或写成教程,在技术社区展示如何快速构建一个看PDF回答问题的AI助手,吸引很多有文档处理需求的开发者关注。
AI学习笔记整理
开发一款应用,学生上课手写的笔记拍照上传,DeepSeek-OCR识别出文字和公式,再自动转换成整洁的Markdown笔记甚至推送到知识管理系统。这比单纯OCR更有吸引力,因为还能保持版面结构和公式格式。演示视频可以对比"原始手写混乱" vs "AI整理后的笔记",效果将很具冲击力。
知识库光学压缩
面向企业知识库或维基百科这样的海量文本库,尝试用DeepSeek-OCR批量把文字转成高压缩图像嵌入存储,然后查询时即时解码。可以做个POC项目演示:比如用DeepSeek-OCR压缩整本《西游记》成若干张图片(模拟存储在"AI大脑"中),查询某章节时再让模型解码出原文回答问题。此创意视频会非常抓人眼球,突出"图像存文本"的逆天操作。
多模态文档搜索
结合DeepSeek-OCR和向量数据库,构建支持图文内容检索的系统。具体而言,用DeepSeek-OCR将每页文档转成文本embedding(或者直接用DeepEncoder输出的视觉token向量),存入向量库;查询时,无论用户输入文字还是上传一张含文字的截图,都转换成embedding比对,找出相关文档段落。因为模型对图文都一视同仁,这种搜索将比传统OCR+NLP方案更统一。可以写篇博客或拍视频展示如何实现一个支持以图搜文、以文搜图的智能检索,引发对多模态检索的讨论。
游戏式科普视频
"假如让AI只看图书不看字,会发生什么?"------这可以是一个有趣的视频主题。通过介绍DeepSeek-OCR,把复杂技术用类比方式解释给大众:比如把一本书拍成照片喂给模型,看它能复述多少内容,类比人过目不忘的能力。通过这种游戏实验,让更多人了解到AI的新奇潜力,也让DeepSeek-OCR的概念走出纯工程圈,引发广泛关注。
暂时小结
总而言之,DeepSeek-OCR的出现为OCR和NLP领域注入了一剂"脑洞大开"的新理念。在后续研究中,我们有望看到视觉与语言、更紧密结合的模型不断涌现。对于开发者而言,这既是一个强大的新工具,也开启了许多令人兴奋的创意可能。从提升AI的记忆力到打造聪明的文档助手,DeepSeek-OCR的爆火只是起点,未来围绕它的探索和应用或将引领又一波技术浪潮
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| PDF 转 Markdown 丢结构/表格错列 | 版式复杂、列检测失败 | 抽样比对原页与解析结果;统计表格召回 | 增加版面分析与表格线检测;引入版式先验与后处理合并单元格 |
| 图表数值还原不准 | 曲线/坐标轴未被语义化 | 针对图表页做专用评测集 | 训练/微调图表解析子模块;加规则化后处理(轴刻度对齐、异常值夹取) |
| 长记忆问答前后矛盾 | 压缩/解压策略不稳定 | 记录窗口与命中段落;回放注意力权重 | 引入"再检索再解码"两段式;关键段落强提示与一致性约束 |
| 以图搜文召回低 | 视觉与文本 embedding 语义不对齐 | 检查跨模态对齐损失与难例 | 做对比学习蒸馏、难例挖掘;添加重排器(cross-encoder) |
| 边缘设备推理超时/炸显存 | 模型过大或算子不友好 | 采集端到端延时与算子火焰图 | 量化+蒸馏;替换高耗算子;分辨率/序列长度自适应裁剪 |
| 数学/公式识别错漏 | 公式 token 化不稳 | 专项集回归;误差热区定位 | 加 LaTeX 约束生成与词表;二段式公式校对器 |
| 合规/隐私风险 | 文档含敏感信息 | 审计样本库与访问轨迹 | 敏感词与水印检测;最小化存储与可控解码;权限隔离 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接