前言
最近想开一个关于强化学习专栏,因为DeepSeek-R1很火,但本人对于LLM连门都没入。因此,只是记录一些类似的读书笔记,内容不深,大多数只是一些概念的东西,数学公式也不会太多,还望读者多多指教。本次阅读书籍为:马克西姆的《深度强化学习实践》。
限于篇幅原因,请读者首先看下历史文章:
1、交叉熵方法流程图

如上图所示:模型输入为观察 s s s,而模型直接输出策略的概率分布 π ( a ∣ s ) \pi(a|s) π(a∣s),在得到概率分布后,然后从该分布中随机采样一个动作即可。
2、交叉熵算法
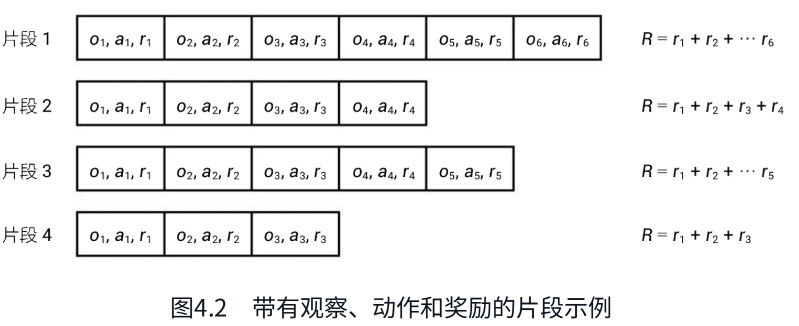
简单介绍下训练交叉熵算法的流程:如上图所示,
1、首先智能体在环境中生成N个片段;
2、设置一个奖励边界:比如总奖励的70%;
3、根据奖励边界过滤掉不满足的片段;
4、用剩下的精英片段来训练模型。
这里可以拿监督学习训练做下类比:上述4步完成后相当于1个epoch,而每个精英片段相当于iteration。然后不断增加epoch来更新模型。
3、CartPole实践
python
#!/usr/bin/env python3
import numpy as np
import gymnasium as gym
from dataclasses import dataclass
import typing as tt
from torch.utils.tensorboard.writer import SummaryWriter
import torch
import torch.nn as nn
import torch.optim as optim
HIDDEN_SIZE = 128
BATCH_SIZE = 16
PERCENTILE = 70
# -----------定义一个网络 --------------- #
class Net(nn.Module):
def __init__(self, obs_size: int, hidden_size: int, n_actions: int):
super(Net, self).__init__()
self.net = nn.Sequential(
nn.Linear(obs_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, n_actions)
)
def forward(self, x: torch.Tensor):
return self.net(x)
@dataclass
class EpisodeStep:
observation: np.ndarray
action: int
@dataclass
class Episode:
reward: float
steps: tt.List[EpisodeStep]
# 组合batch操作
def iterate_batches(env: gym.Env, net: Net, batch_size: int) -> tt.Generator[tt.List[Episode], None, None]:
batch = []
episode_reward = 0.0
episode_steps = []
obs, _ = env.reset()
sm = nn.Softmax(dim=1)
while True:
obs_v = torch.tensor(obs, dtype=torch.float32)
act_probs_v = sm(net(obs_v.unsqueeze(0)))
act_probs = act_probs_v.data.numpy()[0]
action = np.random.choice(len(act_probs), p=act_probs)
next_obs, reward, is_done, is_trunc, _ = env.step(action)
episode_reward += float(reward)
step = EpisodeStep(observation=obs, action=action)
episode_steps.append(step)
if is_done or is_trunc:
e = Episode(reward=episode_reward, steps=episode_steps)
batch.append(e)
episode_reward = 0.0
episode_steps = []
next_obs, _ = env.reset()
# ------------------------------------------- # 迭代器
if len(batch) == batch_size:
yield batch
batch = []
obs = next_obs
# 核心:给定一个奖励边界和batch,用来筛选出"精英"片段 #
def filter_batch(batch: tt.List[Episode], percentile: float) -> \
tt.Tuple[torch.FloatTensor, torch.LongTensor, float, float]:
rewards = list(map(lambda s: s.reward, batch))
reward_bound = float(np.percentile(rewards, percentile))
reward_mean = float(np.mean(rewards))
train_obs: tt.List[np.ndarray] = []
train_act: tt.List[int] = []
for episode in batch:
if episode.reward < reward_bound:
continue
train_obs.extend(map(lambda step: step.observation, episode.steps))
train_act.extend(map(lambda step: step.action, episode.steps))
train_obs_v = torch.FloatTensor(np.vstack(train_obs))
train_act_v = torch.LongTensor(train_act)
return train_obs_v, train_act_v, reward_bound, reward_mean
if __name__ == "__main__":
env = gym.make("CartPole-v1")
assert env.observation_space.shape is not None
obs_size = env.observation_space.shape[0]
assert isinstance(env.action_space, gym.spaces.Discrete)
n_actions = int(env.action_space.n)
net = Net(obs_size, HIDDEN_SIZE, n_actions)
print(net)
objective = nn.CrossEntropyLoss()
optimizer = optim.Adam(params=net.parameters(), lr=0.01)
writer = SummaryWriter(comment="-cartpole")
for iter_no, batch in enumerate(iterate_batches(env, net, BATCH_SIZE)):
obs_v, acts_v, reward_b, reward_m = filter_batch(batch, PERCENTILE)
optimizer.zero_grad()
action_scores_v = net(obs_v)
loss_v = objective(action_scores_v, acts_v)
loss_v.backward()
optimizer.step()
print("%d: loss=%.3f, reward_mean=%.1f, rw_bound=%.1f" % (
iter_no, loss_v.item(), reward_m, reward_b))
writer.add_scalar("loss", loss_v.item(), iter_no)
writer.add_scalar("reward_bound", reward_b, iter_no)
writer.add_scalar("reward_mean", reward_m, iter_no)
if reward_m > 475:
print("Solved!")
break
writer.close()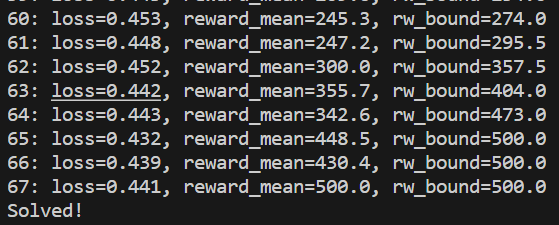
如上图所示:当奖励超过475时候,就得到了一个玩平衡木不错的智能体了。
总结
在本文中,我们简单介绍了交叉熵方法具体的训练流程,以及如何用交叉熵算法来实现CartPole智能体。下篇介绍Bellman方程,敬请期待。