摘要 :大型语言模型在特定领域任务中的性能需要进行微调,这在计算上代价高昂,在技术上具有挑战性。 本文重点介绍使用软提示进行参数有效的微调,这是一种有前景的方法,通过学习一小部分参数,使预训练模型适应下游任务。 我们提出了一种新的输入依赖软提示技术,该技术具有自注意力机制(ID-SPAM),可以根据输入标记生成软提示,并关注不同重要性的不同标记。 我们的方法简单高效,保持了可训练参数的数量较小。 我们展示了所提出的方法与各种任务上最先进的技术相比的优点,并展示了改进的零样本领域迁移能力。Huggingface链接:Paper page,论文链接:2506.05629
研究背景和目的
研究背景
随着自然语言处理(NLP)领域的快速发展,大型语言模型(LLMs)如BERT、GPT等在多种任务中展现出了卓越的性能。然而,这些模型在特定领域任务中的表现往往受限,因为它们主要是在通用语料库上进行预训练的。为了使LLMs适应特定领域的任务,通常需要进行微调(fine-tuning)。然而,传统的微调方法需要更新整个模型的参数,这在计算上代价高昂,尤其是在处理大规模模型时。此外,针对每个新任务都进行全模型微调也不现实,因为这需要大量的计算资源和时间。
为了解决这个问题,研究人员开始探索参数高效的微调方法。软提示(soft prompting)作为一种有前景的方法,通过学习一小部分参数(即软提示),使预训练模型能够适应下游任务,而无需更新整个模型的参数。这种方法在保持模型性能的同时,显著降低了计算成本。然而,现有的软提示方法大多忽略了输入文本的具体内容,导致生成的软提示缺乏针对性,无法充分利用输入信息。
研究目的
本研究旨在提出一种新的输入依赖软提示技术,通过利用自注意力机制,使软提示能够根据输入文本的具体内容动态生成,并关注不同重要性的不同标记。具体而言,本研究的目的包括:
-
开发一种输入依赖的软提示技术:提出一种新的方法,即输入依赖软提示与自注意力机制(ID-SPAM),使软提示能够根据输入文本的具体内容动态生成,从而提高软提示的针对性和有效性。
-
验证ID-SPAM的有效性:在多个NLP任务上验证ID-SPAM的性能,包括情感分析、自然语言推理、问答等,以证明其相对于现有技术的优越性。
-
探索ID-SPAM的零样本领域迁移能力:研究ID-SPAM在零样本设置下的领域迁移能力,即在一个领域上训练的模型能否直接应用于另一个领域,而无需进行额外的微调。
-
分析ID-SPAM的效率和可扩展性:评估ID-SPAM在计算效率和可扩展性方面的表现,以确保其在实际应用中的可行性。
研究方法
ID-SPAM技术概述
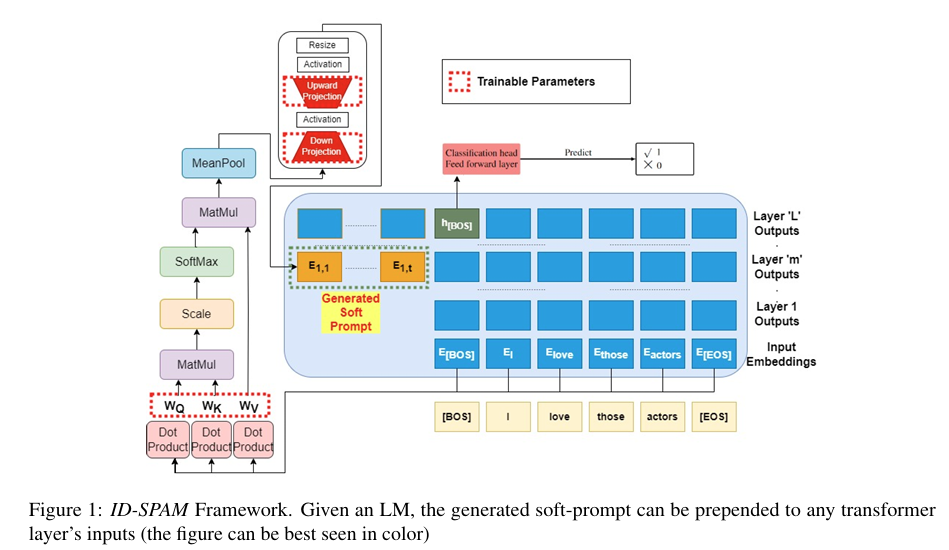
ID-SPAM是一种输入依赖的软提示技术,它利用自注意力机制根据输入文本的具体内容动态生成软提示。具体而言,ID-SPAM通过以下步骤实现:
-
输入嵌入:将输入文本转换为嵌入向量,作为模型的输入。
-
自注意力机制:应用自注意力机制对输入嵌入进行处理,以捕捉输入文本中不同标记之间的依赖关系。这一步骤是ID-SPAM的核心,它使模型能够关注不同重要性的不同标记。
-
软提示生成:基于自注意力机制的输出,生成一个与输入文本相关的软提示。这个软提示是一个向量,它将被添加到模型的输入中,以指导模型更好地适应下游任务。
-
模型微调:在下游任务上微调模型,只更新软提示的参数,而保持预训练模型的参数不变。
实验设置
为了验证ID-SPAM的有效性,我们在多个NLP任务上进行了实验,包括GLUE基准测试中的六个任务(SST-2、MRPC、MNLI、QNLI、RTE、QQP)以及SuperGLUE基准测试中的四个任务(CB、COPA、MultiRC、BoolQ)。我们使用了RoBERTa-BASE和RoBERTa-LARGE作为预训练模型,并与其他几种参数高效的微调方法进行了比较,包括Prompt Tuning、P-Tuning、SMoP、LPT、DEPT和LoRA。
在实验中,我们遵循了标准的微调设置,使用交叉熵损失函数和Adam优化器进行训练。我们报告了每个任务上的准确率或平均准确率和宏F1分数,并对结果进行了多次运行的平均处理,以减少随机性的影响。
研究结果
性能比较
实验结果表明,ID-SPAM在多个NLP任务上均取得了显著的性能提升。与现有的参数高效微调方法相比,ID-SPAM在大多数任务上都表现出了更好的性能。特别是在使用RoBERTa-LARGE作为预训练模型时,ID-SPAM在GLUE和SuperGLUE基准测试中的平均性能均超过了其他方法。
具体而言,在GLUE基准测试中,ID-SPAM在六个任务中的四个任务上取得了最佳性能,并且在平均任务性能上也优于其他方法。在SuperGLUE基准测试中,ID-SPAM同样在多个任务上表现出色,证明了其广泛的适用性和有效性。
零样本领域迁移能力
我们还探索了ID-SPAM在零样本设置下的领域迁移能力。实验结果表明,ID-SPAM在零样本设置下也表现出了良好的领域迁移能力。具体而言,在一个领域上训练的ID-SPAM模型能够直接应用于另一个领域,而无需进行额外的微调,并且仍然能够取得不错的性能。
这一结果表明,ID-SPAM生成的软提示具有一定的通用性,能够捕捉到不同领域之间的共性特征。这为ID-SPAM在实际应用中的广泛适用性提供了有力支持。
效率和可扩展性分析
在效率和可扩展性方面,ID-SPAM同样表现出了优势。与LoRA等需要引入额外低秩矩阵的方法相比,ID-SPAM只增加了少量的可训练参数(即软提示的参数),因此具有更高的计算效率。此外,由于ID-SPAM的软提示是基于输入文本动态生成的,因此它更容易适应不同规模和复杂度的任务。
我们还分析了ID-SPAM在不同预训练模型上的表现。实验结果表明,ID-SPAM在使用不同规模的预训练模型时均能够取得稳定的性能提升。这表明ID-SPAM具有良好的可扩展性,能够适应不同规模和复杂度的预训练模型。
研究局限
尽管ID-SPAM在多个方面表现出了优越性,但它仍然存在一些局限性:
-
计算资源限制:由于我们受到计算资源的限制,无法使用更大规模的预训练模型(如Llama-3.1-70B和Mixtral8x22B)进行实验。因此,我们无法确定ID-SPAM在这些更大规模模型上的性能表现。
-
软提示插入层的选择:目前,我们手动选择了将软提示插入到Transformer模型的哪一层。这一选择可能对最终性能产生影响,但目前还没有自动选择最佳插入层的方法。
-
对特定任务的适应性:虽然ID-SPAM在多个NLP任务上表现出了良好的性能,但它可能并不适用于所有类型的任务。特别是对于那些需要高度专业化知识的任务,ID-SPAM可能需要进一步的调整和优化。
未来研究方向
基于当前研究的成果和局限性,我们提出以下未来研究方向:
-
探索更大规模的预训练模型:未来研究可以探索ID-SPAM在更大规模的预训练模型上的性能表现。通过使用更大规模的模型,我们可以进一步验证ID-SPAM的扩展性和有效性。
-
自动选择软提示插入层:开发一种自动选择软提示插入层的方法,以提高ID-SPAM的灵活性和适应性。这可以通过分析模型在不同层上的注意力分布或性能表现来实现。
-
针对特定任务的优化:针对特定类型的任务(如高度专业化的领域任务),对ID-SPAM进行进一步的优化和调整。这可能包括设计更复杂的软提示生成机制或引入额外的任务特定信息。
-
多模态扩展:探索将ID-SPAM扩展到多模态场景中的可能性。通过结合视觉、音频等多种模态的信息,我们可以进一步丰富软提示的生成过程,并提高模型在多模态任务上的性能。
-
可解释性研究:研究ID-SPAM生成软提示的可解释性,以更好地理解模型是如何根据输入文本生成软提示的。这有助于我们进一步优化ID-SPAM的性能,并提高其在实际应用中的可信度。
结论
本研究提出了一种新的输入依赖软提示技术------ID-SPAM,它利用自注意力机制根据输入文本的具体内容动态生成软提示。实验结果表明,ID-SPAM在多个NLP任务上均取得了显著的性能提升,并展示了良好的零样本领域迁移能力。此外,ID-SPAM还具有计算效率高、可扩展性强等优点。尽管ID-SPAM仍存在一些局限性,但通过未来的研究和发展,我们有理由相信它将在NLP领域发挥重要作用。