参考文献:https://blog.csdn.net/qq363685855/article/details/148512248
之前分享过LLM之RAG实战(五十五)| 阿里开源新模型,Qwen3-Embedding与Qwen3 Reranker强势来袭!。本文将分享如何使用ollama来部署这些模型。
一、首先,需要安装Ollama
打开官网下载:https://ollama.com/download
根据自己的操作系统下载对应的版本即可。正常来说,是可以安装成功的。下面介绍一下特殊情况或者其他安装方式。
a)对于Mac电脑,也可以通过Homebrew进行安装
brew install ollamab)对linux服务器,有时候不能连接外网,因此需要离线安装,可以参考文献:https://blog.csdn.net/m0_71142057/article/details/143186418。
核心点是可以copy文章的install.sh然后下载ollama离线文件,并把他们放到同一个目录下,执行运行install.sh即可,如下图所示:
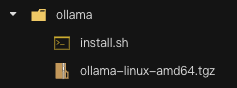
可以通过命令lscpu来查看操作系统版本,我是x86_64。
chmod +x ./install.sh./install.sh二、下载Qwen3-Embedding模型
ollama run dengcao/Qwen3-Embedding-0.6B:F16下面列出Qwen3-Embedding和Qwen3-Reranker各个版本的Ollama安装命令。
Qwen3-Embedding-0.6B系列:
ollama run dengcao/Qwen3-Embedding-0.6B:Q8_0ollama run dengcao/Qwen3-Embedding-0.6B:F16Qwen3-Embedding-4B系列:
ollama run dengcao/Qwen3-Embedding-4B:Q4_K_Mollama run dengcao/Qwen3-Embedding-4B:Q5_K_Mollama run dengcao/Qwen3-Embedding-4B:Q8_0ollama run dengcao/Qwen3-Embedding-8B:F16Qwen3-Embedding-8B系列:
ollama run dengcao/Qwen3-Embedding-8B:Q4_K_Mollama run dengcao/Qwen3-Embedding-8B:Q5_K_Mollama run dengcao/Qwen3-Embedding-8B:Q8_0Qwen3-Reranker-0.6B系列:
ollama run dengcao/Qwen3-Reranker-0.6B:Q8_0ollama run dengcao/Qwen3-Reranker-0.6B:F16Qwen3-Reranker-4B系列:
ollama run dengcao/Qwen3-Reranker-4B:Q4_K_Mollama run dengcao/Qwen3-Reranker-4B:Q5_K_Mollama run dengcao/Qwen3-Reranker-4B:Q8_0Qwen3-Reranker-8B系列:
ollama run dengcao/Qwen3-Reranker-8B:Q3_K_Mollama run dengcao/Qwen3-Reranker-8B:Q4_K_Mollama run dengcao/Qwen3-Reranker-8B:Q5_K_Mollama run dengcao/Qwen3-Reranker-8B:Q8_0ollama run dengcao/Qwen3-Reranker-8B:F16关于量化版本的说明:
-
q8_0:与浮点数16几乎无法区分。资源使用率高,速度慢。不建议大多数用户使用。
-
q6_k:将Q8_K用于所有张量。
-
q5_k_m:将 Q6_K 用于一半的 attention.wv 和 feed_forward.w2 张量,否则Q5_K。
-
q5_0: 原始量化方法,5位。精度更高,资源使用率更高,推理速度更慢。
-
q4_k_m:将 Q6_K 用于一半的 attention.wv 和 feed_forward.w2 张量,否则Q4_Kq4_0:原始量化方法,4 位。
-
q3_k_m:将 Q4_K 用于 attention.wv、attention.wo 和 feed_forward.w2 张量,否则Q3_K
-
q2_k:将 Q4_K 用于 attention.vw 和 feed_forward.w2 张量,Q2_K用于其他张量。
根据经验,建议使用 Q5_K_M,因为它保留了模型的大部分性能。或者,如果要节省一些内存,可以使用 Q4_K_M。