第一章:什么是GANs?从零开始理解
1.1 生动的类比:造假币与验钞的游戏
让我们用一个更加生动的类比来理解GANs:
想象两个朋友小明和小红在玩一个特殊的游戏:
小明(生成器Generator) - 造假币高手
- 职业:专业造假币师傅
- 目标:制造出连专家都分辨不出的假币
- 工具:各种高科技设备和技术
- 策略:不断改进技术,学习真币的每一个细节
小红(判别器Discriminator) - 验钞专家
- 职业:银行首席验钞师
- 目标:准确识别真币和假币
- 工具:专业的检测设备和丰富经验
- 策略:不断提升识别能力,学习假币的所有特征
游戏规则:
- 小明制造假币,混在真币中交给小红
- 小红检查每一张钞票,判断真假
- 根据小红的反馈,小明改进造假技术
- 小红根据新的假币特征,更新识别方法
- 这个过程不断重复...
最终结果: 当小明的技术炉火纯青,制造的假币连小红都无法分辨时,游戏达到平衡。此时小明已经掌握了制造"完美假币"的技术!
这就是GANs的精髓:通过对抗学习,让生成器学会创造以假乱真的数据。
1.2 AI发展的四个层次
在深入GANs之前,让我们先了解AI能力的发展层次:
第四层:创造 (Creation) 🎨
↑ 生成全新的、有意义的内容
│
第三层:理解 (Understanding) 🧠
↑ 深度理解事物的本质和关系
│
第二层:生成 (Generation) 🏭
↑ 基于已有知识生成新内容
│
第一层:识别 (Recognition) 👁️
↑ 感知和分类外部信息GANs的出现,标志着AI从"识别"向"创造"迈出了关键一步,这是AI发展史上的重要里程碑。
第二章:GANs的技术原理深度解析
2.1 数学基础:博弈论中的纳什均衡
GANs的理论基础来自博弈论中的纳什均衡概念。简单来说:
- 零和博弈:一方的收益等于另一方的损失
- 纳什均衡:每个参与者都采用最优策略,没人愿意单方面改变策略的状态
在GANs中:
- 生成器的目标:最大化判别器的错误率
- 判别器的目标:最大化识别准确率
- 纳什均衡:生成器生成的数据无法被判别器区分
2.2 核心架构详解
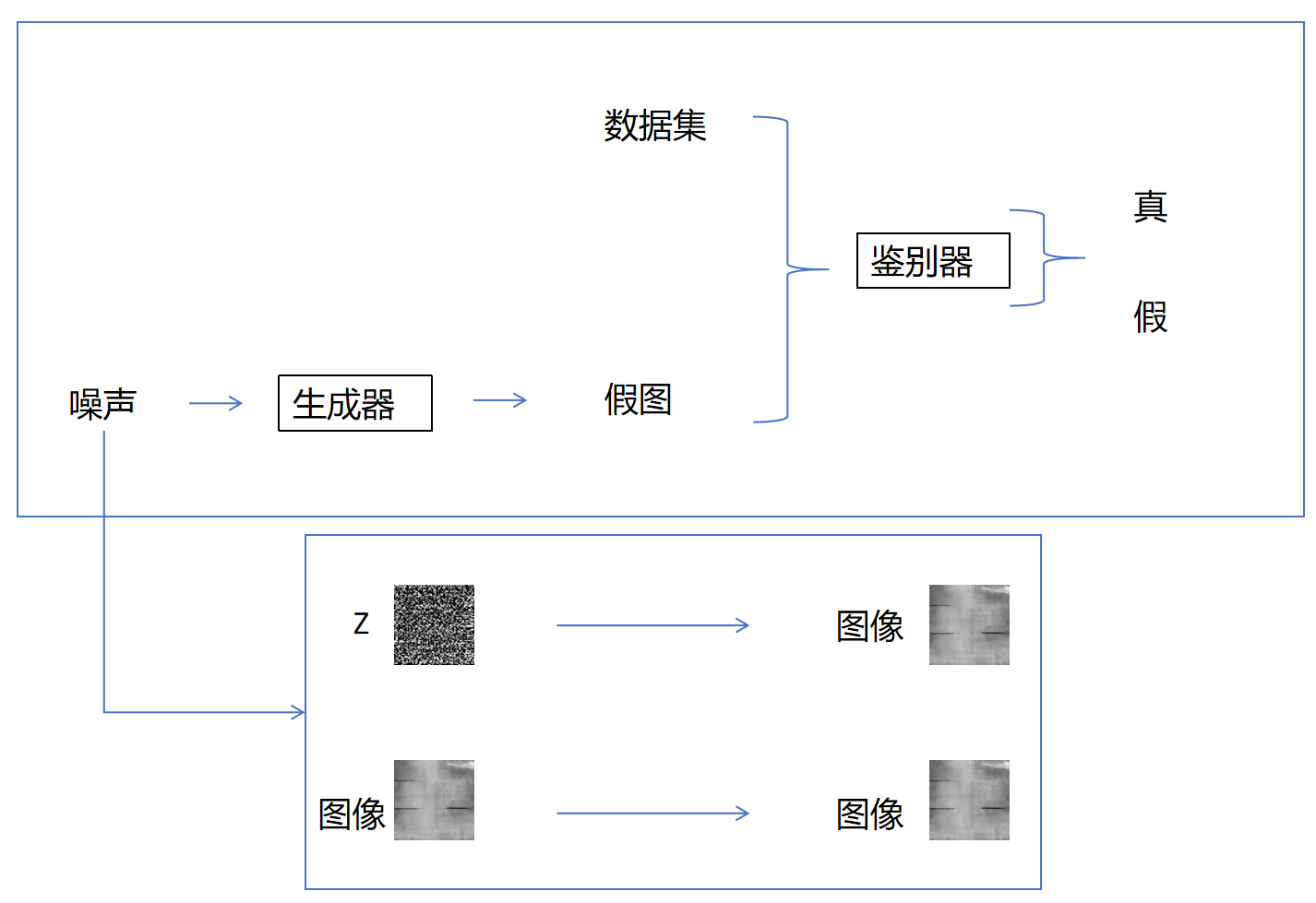
生成器(Generator)
- 输入:随机噪声向量(通常是高斯分布)
- 结构:多层神经网络(通常使用转置卷积)
- 输出:生成的数据样本
- 损失函数:希望判别器判断错误
判别器(Discriminator)
- 输入:真实数据和生成数据
- 结构:多层神经网络(通常使用卷积网络)
- 输出:输入数据为真实数据的概率
- 损失函数:希望正确区分真假数据
2.3 数学公式解读
GANs的目标函数可以表示为:
min max V(D,G) = E[log D(x)] + E[log(1-D(G(z)))]
G D看起来复杂?让我们分解一下:
E[log D(x)]:判别器正确识别真实数据的能力E[log(1-D(G(z)))]:判别器正确识别生成数据的能力min G:生成器要最小化这个函数(让判别器犯错)max D:判别器要最大化这个函数(提高准确率)
2.4 训练过程详细步骤
# 伪代码形式的训练过程
for epoch in range(num_epochs):
for batch in dataloader:
# 第一步:训练判别器
real_data = batch
fake_data = generator(random_noise)
# 判别器学习区分真假
d_loss_real = loss_function(discriminator(real_data), label_real)
d_loss_fake = loss_function(discriminator(fake_data), label_fake)
d_loss = d_loss_real + d_loss_fake
update_discriminator(d_loss)
# 第二步:训练生成器
fake_data = generator(random_noise)
# 生成器试图欺骗判别器
g_loss = loss_function(discriminator(fake_data), label_real)
update_generator(g_loss)第三章:GANs发展历程:从诞生到成熟
3.1 发展时间线
📅 2014年:GANs诞生
│ Ian Goodfellow提出基础概念
│
📅 2015年:DCGAN横空出世
│ 引入卷积神经网络,图像生成质量大幅提升
│
📅 2016年:条件生成兴起
│ CGAN、InfoGAN等让生成过程可控
│
📅 2017年:WGAN革命
│ 解决训练不稳定问题,引入Wasserstein距离
│
📅 2018年:StyleGAN震撼登场
│ 生成超高质量人脸图像,引入风格控制
│
📅 2019-2021年:应用爆发期
│ 各种应用场景涌现,商业化加速
│
📅 2022年至今:多模态时代
│ 文本到图像、图像到视频等跨模态生成3.2 重要里程碑事件
2016年:第一次"欺骗"专家
- 生成的艺术作品在拍卖会上售出数万美元
- 人们开始意识到AI创造力的潜力
2018年:DeepFake现象
- GANs被用于生成假视频
- 引发社会对AI伦理的广泛讨论
2019年:StyleGAN的惊艳表现
- 生成的人脸照片几乎无法区分真假
- "这个人不存在"网站走红网络
2021年:商业化浪潮
- 各大科技公司推出基于GANs的产品
- 从学术研究走向实际应用
第四章:GANs家族大全:百花齐放的变体
4.1 经典基础变体
DCGAN (Deep Convolutional GAN)
🔑 关键创新:引入卷积神经网络
💡 核心优势:
- 生成图像质量大幅提升
- 训练更加稳定
- 奠定了后续发展基础
🎯 适用场景:图像生成的入门首选WGAN (Wasserstein GAN)
🔑 关键创新:使用Wasserstein距离替代JS散度
💡 核心优势:
- 解决梯度消失问题
- 训练过程更稳定
- 提供更好的收敛指标
🎯 适用场景:对训练稳定性要求高的项目4.2 条件生成系列
CGAN (Conditional GAN)
🔑 关键创新:引入条件信息
💡 工作原理:
生成器:噪声 + 条件 → 特定类型的图像
判别器:图像 + 条件 → 真假判断
🎯 实际应用:
- 指定生成特定数字(0-9)
- 控制生成图像的类别
- 根据文本描述生成图像Pix2Pix
🔑 关键创新:图像到图像的精确翻译
💡 典型应用:
- 素描 → 彩色照片
- 卫星图 → 地图
- 黑白照片 → 彩色照片
- 白天场景 → 夜晚场景
🎯 特点:需要配对的训练数据CycleGAN
🔑 关键创新:无需配对数据的图像转换
💡 循环一致性:
A → B → A = A (马 → 斑马 → 马 = 马)
🎯 经典应用:
- 照片 ↔ 画作风格
- 夏天 ↔ 冬天场景
- 马 ↔ 斑马
- 苹果 ↔ 橙子4.3 高质量生成系列
StyleGAN系列
🔑 StyleGAN (2019):
- 引入风格控制机制
- 生成超高质量人脸图像
🔑 StyleGAN2 (2020):
- 改进生成质量
- 减少artifacts(伪影)
🔑 StyleGAN3 (2021):
- 实现平移和旋转不变性
- 更好的几何一致性BigGAN
🔑 关键创新:大规模、高分辨率生成
💡 技术特点:
- 使用更大的网络
- 改进的训练技巧
- 支持多类别生成
🎯 成果:在ImageNet上生成512×512高质量图像4.4 特殊应用变体
SeqGAN
🔑 目标:文本序列生成
💡 创新点:
- 将生成器建模为强化学习中的策略
- 使用策略梯度训练
- 解决离散数据生成难题
🎯 应用:诗歌生成、对话系统、音乐创作3D-GAN
🔑 目标:三维物体生成
💡 技术路线:
- 体素表示 → 3D卷积
- 点云表示 → 图神经网络
- 网格表示 → 几何深度学习
🎯 应用:游戏资产生成、3D建模、虚拟现实第五章:GANs的超能力:令人惊叹的应用世界
5.1 视觉艺术与创意
艺术创作革命
🎨 名画风格迁移
输入:你的自拍照
输出:梵高风格的艺术肖像
🖼️ 艺术品生成
- Obvious艺术团体的AI画作以43万美元成交
- AI成为艺术家的创作伙伴
🎭 虚拟角色设计
- 游戏角色自动生成
- 动漫人物创作
- 虚拟偶像设计实际案例分析
案例1:Adobe的Sensei AI
- 功能:智能图像编辑和创作
- 技术:基于StyleGAN的人像编辑
- 影响:让普通用户也能进行专业级图像处理
案例2:英伟达的GauGAN
- 功能:从简单涂鸦生成逼真风景
- 技术:基于语义分割的图像生成
- 应用:建筑设计、游戏开发、艺术创作
5.2 娱乐与媒体产业
影视制作
🎬 特效制作
- 自动生成背景场景
- 创造不存在的演员
- 年龄变化效果
📺 内容增强
- 老电影修复和上色
- 低分辨率视频增强
- 缺失场景补全
🎮 游戏开发
- 程序化地图生成
- NPC角色自动创建
- 材质纹理生成DeepFake技术的双面性
正面应用:
- 电影中已逝演员的"复活"
- 多语言配音中的口型同步
- 历史人物的虚拟重现
负面风险:
- 虚假新闻和谣言传播
- 身份冒充和诈骗
- 隐私和肖像权侵犯
应对措施:
- 深度检测技术发展
- 法律法规的完善
- 平台监管机制
5.3 医疗健康领域
医学影像增强
🔬 影像质量提升
- CT扫描图像去噪
- MRI图像超分辨率重建
- X光片质量增强
🧬 数据增强
- 生成稀有疾病样本
- 平衡数据集分布
- 保护患者隐私的同时共享数据
💊 药物研发
- 分子结构生成
- 药物-靶点相互作用预测
- 新药候选物设计具体应用案例
案例:GE Healthcare的深度学习平台
- 使用GANs生成高质量医学图像
- 帮助训练更准确的诊断AI
- 在数据稀缺的罕见疾病诊断中发挥重要作用
5.4 时尚与电商
虚拟试衣与设计
👗 虚拟试衣
- 生成穿着效果图
- 不同身材的适配展示
- 颜色和款式的实时变换
🎨 服装设计
- 基于趋势数据生成新款式
- 个性化定制设计
- 面料图案生成
📸 产品展示
- 模特图像生成
- 场景背景替换
- 多角度产品展示成功案例
案例:Zalando的虚拟试衣技术
- 使用GANs生成顾客穿着不同服装的效果
- 显著提高在线购物的用户体验
- 减少退货率,提升销售转化
5.5 教育与培训
个性化内容生成
📚 教材制作
- 根据学生水平生成习题
- 个性化插图和图表
- 多样化的教学案例
🎯 技能训练
- 生成训练场景
- 模拟危险环境
- 创造练习材料
🌍 历史重现
- 古代场景复原
- 历史人物重现
- 文化遗产数字化第六章:如何评价GANs?不只是"看起来像不像"
6.1 传统评估指标
IS (Inception Score)
💡 基本思想:好的生成图像应该:
1. 清晰度高(容易被分类)
2. 多样性好(类别分布均匀)
📊 计算方法:
IS = exp(E[KL(p(y|x) || p(y))])
🎯 优点:计算简单,直观易懂
⚠️ 缺点:
- 依赖于预训练的分类器
- 无法检测过拟合
- 对某些图像类型不适用FID (Fréchet Inception Distance)
💡 基本思想:
比较真实图像和生成图像在特征空间中的分布距离
📊 计算过程:
1. 使用预训练网络提取特征
2. 假设特征服从多元高斯分布
3. 计算两个分布的Fréchet距离
🎯 优点:
- 更稳定和可靠
- 能检测多样性问题
- 广泛被学术界接受6.2 新兴评估方法
LPIPS (Learned Perceptual Image Patch Similarity)
💡 核心理念:使用深度网络学习人类视觉感知
🎯 应用场景:图像编辑质量评估
📈 优势:更符合人类主观感受人类评估研究
👥 众包评估
- Amazon Mechanical Turk等平台
- 大规模人类标注
- 统计显著性检验
🧠 专家评估
- 领域专家判断
- 详细评估标准
- 定性分析报告6.3 评估的挑战与思考
多维度质量
- 视觉质量 vs 多样性
- 语义一致性 vs 创新性
- 技术指标 vs 用户体验
应用相关性
- 不同应用场景需要不同评估标准
- 通用指标的局限性
- 任务特定评估的重要性
第七章:GANs的挑战与解决方案
7.1 训练稳定性问题
模式崩溃 (Mode Collapse)
❌ 问题表现:
- 生成器只学会生成有限几种样本
- 缺乏多样性,重复性高
- 无法覆盖真实数据的所有模式
🔍 根本原因:
- 生成器找到"欺骗"判别器的捷径
- 优化过程陷入局部最优
- 判别器过于强大或过于弱小
💡 解决方案:
1. Unrolled GANs:展开优化步骤
2. WGAN:改进损失函数
3. Spectral Normalization:控制判别器能力
4. Progressive Growing:渐进式训练梯度消失和爆炸
❌ 梯度消失:
判别器过于完美 → 梯度接近0 → 生成器无法学习
❌ 梯度爆炸:
不稳定的训练动态 → 梯度过大 → 训练发散
💡 解决策略:
- 梯度裁剪 (Gradient Clipping)
- 批量归一化 (Batch Normalization)
- 学习率调度 (Learning Rate Scheduling)
- 渐进式训练 (Progressive Training)7.2 训练技巧集锦
网络架构设计
🏗️ 生成器设计原则:
- 使用转置卷积进行上采样
- 避免全连接层(除了第一层)
- 使用批量归一化和ReLU激活
- 输出层使用Tanh激活函数
🔍 判别器设计原则:
- 使用卷积层进行下采样
- 使用LeakyReLU激活函数
- 最后一层不使用批量归一化
- 使用Dropout防止过拟合训练策略优化
⚖️ 平衡训练:
- 判别器训练k次,生成器训练1次
- 动态调整训练频率
- 监控训练平衡指标
🎯 学习率策略:
- 生成器和判别器使用不同学习率
- TTUR (Two-Timescale Update Rule)
- 自适应学习率调整
🔧 数据增强:
- 对真实数据进行随机变换
- 防止判别器过拟合
- 提高生成器的泛化能力7.3 最新研究进展
自注意力机制
🔍 SAGAN (Self-Attention GAN):
- 捕获长距离依赖关系
- 改善全局结构一致性
- 特别适用于复杂场景生成
💡 核心思想:
每个像素可以"关注"图像中的任何其他像素
而不仅仅是邻近区域谱归一化技术
🎯 目标:控制判别器的Lipschitz常数
📊 方法:对权重矩阵进行谱归一化
✅ 效果:
- 训练更稳定
- 避免梯度爆炸
- 提高生成质量第八章:动手实践:你的第一个GAN项目
8.1 环境搭建
基础环境
# Python环境设置
conda create -n gan_learning python=3.8
conda activate gan_learning
# 安装核心依赖
pip install torch torchvision
pip install matplotlib numpy
pip install tensorboard # 可视化工具
pip install tqdm # 进度条推荐硬件配置
💻 基础配置:
- CPU: Intel i5 或 AMD Ryzen 5 以上
- RAM: 16GB 以上
- GPU: GTX 1060 6GB 或更好
🚀 推荐配置:
- CPU: Intel i7 或 AMD Ryzen 7 以上
- RAM: 32GB 以上
- GPU: RTX 3070 8GB 或更好
☁️ 云端方案:
- Google Colab Pro
- AWS EC2 GPU实例
- 阿里云ECS GPU实例8.2 第一个项目:MNIST数字生成
完整代码框架
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
# 超参数设置
BATCH_SIZE = 128
LEARNING_RATE = 0.0002
NUM_EPOCHS = 100
NOISE_DIM = 100
IMAGE_SIZE = 28 * 28
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]) # 归一化到[-1, 1]
])
# 数据加载
dataset = torchvision.datasets.MNIST(
root='./data',
train=True,
download=True,
transform=transform
)
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
# 生成器网络
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
# 输入层:噪声向量
nn.Linear(NOISE_DIM, 256),
nn.ReLU(True),
# 隐藏层1
nn.Linear(256, 512),
nn.ReLU(True),
# 隐藏层2
nn.Linear(512, 1024),
nn.ReLU(True),
# 输出层:生成图像
nn.Linear(1024, IMAGE_SIZE),
nn.Tanh() # 输出范围[-1, 1]
)
def forward(self, x):
return self.model(x)
# 判别器网络
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
# 输入层:图像
nn.Linear(IMAGE_SIZE, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
# 隐藏层1
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
# 隐藏层2
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
# 输出层:真假概率
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x)
# 初始化网络
generator = Generator().to(device)
discriminator = Discriminator().to(device)
# 损失函数和优化器
criterion = nn.BCELoss()
g_optimizer = optim.Adam(generator.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))
d_optimizer = optim.Adam(discriminator.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))
# 训练过程
def train_gan():
generator.train()
discriminator.train()
for epoch in range(NUM_EPOCHS):
for i, (real_images, _) in enumerate(dataloader):
batch_size = real_images.size(0)
real_images = real_images.view(batch_size, -1).to(device)
# 创建标签
real_labels = torch.ones(batch_size, 1).to(device)
fake_labels = torch.zeros(batch_size, 1).to(device)
# ================训练判别器================
# 清零梯度
d_optimizer.zero_grad()
# 真实图像
real_outputs = discriminator(real_images)
d_loss_real = criterion(real_outputs, real_labels)
# 生成假图像
noise = torch.randn(batch_size, NOISE_DIM).to(device)
fake_images = generator(noise)
fake_outputs = discriminator(fake_images.detach())
d_loss_fake = criterion(fake_outputs, fake_labels)
# 总的判别器损失
d_loss = d_loss_real + d_loss_fake
d_loss.backward()
d_optimizer.step()
# ================训练生成器================
g_optimizer.zero_grad()
# 生成器希望判别器认为假图像是真的
fake_outputs = discriminator(fake_images)
g_loss = criterion(fake_outputs, real_labels)
g_loss.backward()
g_optimizer.step()
# 打印训练信息
if i % 100 == 0:
print(f'Epoch [{epoch}/{NUM_EPOCHS}], '
f'Step [{i}/{len(dataloader)}], '
f'D Loss: {d_loss.item():.4f}, '
f'G Loss: {g_loss.item():.4f}')
# 每个epoch结束后生成样本图像
if epoch % 10 == 0:
generate_and_save_images(epoch)
# 生成并保存图像
def generate_and_save_images(epoch):
generator.eval()
with torch.no_grad():
noise = torch.randn(16, NOISE_DIM).to(device)
fake_images = generator(noise)
fake_images = fake_images.view(-1, 1, 28, 28)
fake_images = fake_images.cpu()
# 创建网格显示
fig, axes = plt.subplots(4, 4, figsize=(8, 8))
for i, ax in enumerate(axes.flat):
ax.imshow(fake_images[i].squeeze(), cmap='gray')
ax.axis('off')
plt.suptitle(f'Generated Images - Epoch {epoch}')
plt.tight_layout()
plt.savefig(f'generated_images_epoch_{epoch}.png')
plt.show()
generator.train()
# 开始训练
if __name__ == "__main__":
print("开始训练GAN...")
train_gan()
print("训练完成!")8.3 进阶项目:人脸生成DCGAN
关键改进点
# DCGAN生成器(卷积版本)
class DCGenerator(nn.Module):
def __init__(self, noise_dim=100, num_channels=3):
super(DCGenerator, self).__init__()
self.main = nn.Sequential(
# 输入:噪声向量
nn.ConvTranspose2d(noise_dim, 512, 4, 1, 0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 第一层:4x4 -> 8x8
nn.ConvTranspose2d(512, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 第二层:8x8 -> 16x16
nn.ConvTranspose2d(256, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(True),
# 第三层:16x16 -> 32x32
nn.ConvTranspose2d(128, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
# 输出层:32x32 -> 64x64
nn.ConvTranspose2d(64, num_channels, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, input):
return self.main(input)
# DCGAN判别器
class DCDiscriminator(nn.Module):
def __init__(self, num_channels=3):
super(DCDiscriminator, self).__init__()
self.main = nn.Sequential(
# 输入:64x64图像
nn.Conv2d(num_channels, 64, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 第一层:64x64 -> 32x32
nn.Conv2d(64, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
# 第二层:32x32 -> 16x16
nn.Conv2d(128, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
# 第三层:16x16 -> 8x8
nn.Conv2d(256, 512, 4, 2, 1, bias=False),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2, inplace=True),
# 输出层:8x8 -> 1x1
nn.Conv2d(512, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input).view(-1, 1).squeeze(1)8.4 训练监控与调试
损失函数可视化
import matplotlib.pyplot as plt
from collections import defaultdict
# 训练历史记录
training_history = defaultdict(list)
def plot_training_progress():
"""绘制训练进度"""
epochs = range(1, len(training_history['g_loss']) + 1)
plt.figure(figsize=(12, 4))
# 损失函数图
plt.subplot(1, 2, 1)
plt.plot(epochs, training_history['g_loss'], label='Generator Loss')
plt.plot(epochs, training_history['d_loss'], label='Discriminator Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.title('Training Loss')
# 判别器准确率图
plt.subplot(1, 2, 2)
plt.plot(epochs, training_history['d_acc'], label='Discriminator Accuracy')
plt.axhline(y=0.5, color='r', linestyle='--', label='Random Guess')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Discriminator Accuracy')
plt.tight_layout()
plt.show()
# 生成质量评估
def evaluate_generation_quality(generator, num_samples=1000):
"""评估生成质量"""
generator.eval()
with torch.no_grad():
# 生成样本
noise = torch.randn(num_samples, NOISE_DIM).to(device)
fake_images = generator(noise)
# 计算统计信息
mean_pixel = fake_images.mean().item()
std_pixel = fake_images.std().item()
print(f"生成图像统计信息:")
print(f" 像素均值: {mean_pixel:.4f}")
print(f" 像素标准差: {std_pixel:.4f}")
# 检查是否有异常值
min_val, max_val = fake_images.min().item(), fake_images.max().item()
print(f" 像素范围: [{min_val:.4f}, {max_val:.4f}]")
generator.train()8.5 常见问题与解决方案
问题诊断清单
❌ 生成器损失不下降:
✅ 检查学习率是否过小
✅ 确认网络架构是否合理
✅ 验证数据预处理是否正确
❌ 判别器过强(损失接近0):
✅ 降低判别器学习率
✅ 减少判别器训练频率
✅ 增加噪声或Dropout
❌ 模式崩溃(生成图像单一):
✅ 尝试不同的损失函数
✅ 调整网络容量比例
✅ 使用Spectral Normalization
❌ 训练不稳定:
✅ 使用梯度裁剪
✅ 降低学习率
✅ 增加批量大小第九章:学习资源与进阶路径
9.1 经典论文必读清单
入门级论文(难度:⭐⭐)
📄 1. Generative Adversarial Networks (Goodfellow et al., 2014)
🎯 必读理由:GANs的奠基之作
📝 学习要点:基本概念、理论基础、数学推导
📄 2. Unsupervised Representation Learning with DCGANs (Radford et al., 2016)
🎯 必读理由:第一个成功的卷积GAN
📝 学习要点:网络架构设计、训练技巧进阶级论文(难度:⭐⭐⭐)
📄 3. Improved Training of Wasserstein GANs (Gulrajani et al., 2017)
🎯 必读理由:解决训练稳定性问题
📝 学习要点:Wasserstein距离、梯度惩罚
📄 4. Progressive Growing of GANs (Karras et al., 2018)
🎯 必读理由:高分辨率图像生成突破
📝 学习要点:渐进式训练、稳定性技巧
📄 5. A Style-Based Generator Architecture (Karras et al., 2019)
🎯 必读理由:StyleGAN的创新架构
📝 学习要点:风格控制、解耦表示专业级论文(难度:⭐⭐⭐⭐)
📄 6. Analyzing and Improving the Image Quality of StyleGAN (Karras et al., 2020)
🎯 必读理由:StyleGAN2的重要改进
📝 学习要点:质量提升技术、架构优化
📄 7. Self-Attention GANs (Zhang et al., 2019)
🎯 必读理由:注意力机制在GANs中的应用
📝 学习要点:长距离依赖、全局结构9.2 在线课程与教程
🎓 Coursera - Deep Learning Specialization (吴恩达)
📚 包含GANs专门课程
🎯 适合:有机器学习基础的学习者
⏱️ 时长:约4-6周
📺 YouTube - Two Minute Papers
🎯 GANs最新研究成果解读
🌟 特点:简洁明了,跟上前沿
💻 Fast.ai - Practical Deep Learning
🎯 偏重实践应用
🛠️ 大量代码示例和项目9.3 实践项目建议
初级项目(1-2周)
🎯 项目1:手写数字生成
📋 技术栈:PyTorch + MNIST
🎯 学习目标:理解基本概念
📊 评估指标:视觉质量、IS分数
🎯 项目2:简单图像风格转换
📋 技术栈:CycleGAN + 小数据集
🎯 学习目标:无监督学习
📊 评估指标:风格一致性中级项目(3-4周)
🎯 项目3:人脸属性编辑
📋 技术栈:StyleGAN + CelebA
🎯 学习目标:条件生成、属性控制
📊 评估指标:属性准确率、视觉质量
🎯 项目4:艺术作品生成
📋 技术栈:DCGAN + 艺术作品数据集
🎯 学习目标:创意应用
📊 评估指标:艺术性评分、原创性高级项目(4-8周)
🎯 项目5:视频生成
📋 技术栈:3D CNN + 时序GAN
🎯 学习目标:时序建模
📊 评估指标:时间一致性、质量
🎯 项目6:多模态生成
📋 技术栈:文本+图像GANs
🎯 学习目标:跨模态学习
📊 评估指标:语义一致性9.4 开源工具与框架
深度学习框架
🔥 PyTorch
✅ 优点:动态图、易调试、社区活跃
📚 GANs资源:pytorch-gan、torchgan
🎯 推荐指数:⭐⭐⭐⭐⭐
🧠 TensorFlow
✅ 优点:生产环境友好、工具齐全
📚 GANs资源:tensorflow-gan、tf.keras
🎯 推荐指数:⭐⭐⭐⭐
⚡ JAX
✅ 优点:函数式编程、高性能
📚 GANs资源:flax、haiku
🎯 推荐指数:⭐⭐⭐专门的GANs库
🛠️ PyTorch-GAN
📦 包含20+种GANs实现
🎯 特点:代码清晰、易于学习
🛠️ TensorFlow-GAN (TF-GAN)
📦 Google官方GANs库
🎯 特点:功能全面、性能优化
🛠️ StyleGAN官方实现
📦 NVIDIA官方代码
🎯 特点:最权威、性能最佳9.5 社区与交流平台
学术社区
🏛️ arXiv.org
📄 最新研究论文
🔍 搜索关键词:Generative Adversarial
🤝 Papers With Code
📊 论文+代码+排行榜
🎯 跟踪SOTA模型
📚 Google Scholar
📈 论文引用分析
👥 关注重要研究者开发者社区
💬 Reddit - r/MachineLearning
🗣️ 学术讨论、经验分享
❓ 新手问题解答
🐦 Twitter
👨🔬 关注研究者和实验室
📢 第一时间获取新进展
💻 GitHub
⭐ Star优质项目
🤝 参与开源贡献中文社区
📱 知乎 - 机器学习话题
📝 深度技术文章
💡 实践经验分享
🔗 CSDN博客
📖 技术教程丰富
🎯 适合中文用户
👥 微信群/QQ群
💬 即时交流讨论
🤝 组建学习小组第十章:GANs的未来展望
10.1 技术发展趋势
更大更强的模型
🚀 规模化趋势:
- 参数量:百万 → 十亿 → 千亿
- 训练数据:千张 → 百万张 → 十亿张
- 计算资源:单GPU → 多GPU → 分布式训练
💡 技术突破点:
- 更高效的架构设计
- 分布式训练优化
- 内存和计算效率提升多模态融合
🎯 发展方向:
文本 → 图像 → 视频 → 3D模型 → 虚拟世界
🔮 未来应用:
- 从一段文字生成完整电影
- 从草图生成3D可交互场景
- 跨感官的内容转换(视觉→听觉)可控性增强
🎛️ 精确控制:
- 细粒度属性编辑
- 语义层面的操作
- 用户意图理解
🎨 创意辅助:
- AI成为创作伙伴
- 人机协同创作
- 个性化内容生成10.2 新兴应用领域
科学研究辅助
🔬 分子设计:
- 新药分子结构生成
- 材料特性预测和设计
- 蛋白质结构预测
🌌 科学可视化:
- 天体物理现象模拟
- 微观世界可视化
- 复杂数据的直观展示教育革命
📚 个性化教学:
- 根据学生特点生成教材
- 自适应练习题生成
- 沉浸式历史场景重现
🎮 互动学习:
- 虚拟实验室构建
- 角色扮演式历史学习
- 语言学习场景生成心理健康支持
💭 情感计算:
- 情绪状态可视化
- 治疗性内容生成
- 个性化冥想场景
🤖 虚拟治疗师:
- 24/7心理支持
- 隐私保护的咨询
- 个性化治疗方案10.3 技术挑战与突破方向
理论基础完善
📐 数学理论:
- 收敛性证明
- 生成质量的理论界限
- 最优传输理论应用
🔍 可解释性:
- 理解生成过程
- 控制机制解析
- 失败案例分析计算效率优化
⚡ 推理加速:
- 模型压缩技术
- 量化和剪枝
- 神经架构搜索
💾 资源优化:
- 内存高效训练
- 边缘设备部署
- 云端协同计算伦理与安全
🛡️ 安全防护:
- 深度检测技术
- 水印和溯源
- 恶意使用检测
⚖️ 伦理框架:
- 使用规范制定
- 版权保护机制
- 隐私保护技术10.4 社会影响与思考
创作产业变革
🎨 艺术创作:
💫 积极影响:
- 降低创作门槛
- 激发创意灵感
- 个性化艺术体验
⚠️ 挑战与思考:
- 艺术的价值定义
- 创作者的角色转变
- 版权和署名问题
🎬 影视制作:
💫 积极影响:
- 降低制作成本
- 实现不可能的场景
- 个性化内容推荐
⚠️ 挑战与思考:
- 真实性的边界
- 演员权益保护
- 内容审核难度教育与知识传播
📚 教育民主化:
💫 机会:
- 优质教育资源普及
- 个性化学习体验
- 跨语言知识传播
⚠️ 挑战:
- 信息真实性验证
- 教育质量保证
- 数字鸿沟问题就业与经济影响
💼 就业结构变化:
📈 新增岗位:
- AI内容创作师
- 虚拟世界设计师
- AI伦理专家
📉 受冲击岗位:
- 传统设计师
- 基础内容创作者
- 部分技术岗位
🔄 转型需求:
- 技能升级培训
- 人机协作模式
- 创新思维培养10.5 个人发展建议
技术能力建设
🎯 核心技能:
✅ 深度学习基础
✅ 编程实践能力
✅ 数学理论功底
✅ 项目管理经验
🔄 持续学习:
📖 跟踪前沿论文
💻 参与开源项目
🤝 建立技术网络
🎯 专业领域深耕跨学科知识
🌈 知识广度:
🎨 艺术与设计
📊 商业与市场
⚖️ 法律与伦理
🧠 心理与认知
💡 创新思维:
🔍 问题发现能力
💭 跨界思考习惯
🚀 实验验证精神
🤝 团队协作技能职业发展路径
🛤️ 研究方向:
🎓 学术研究员
🏢 企业研发工程师
💼 AI产品经理
🎨 创意技术专家
📈 成长建议:
1. 选择感兴趣的细分领域
2. 建立个人技术品牌
3. 参与社区贡献
4. 培养商业思维
5. 关注伦理责任结语:踏上AI创造力的征程
回望GANs的发展历程,从2014年那个酒吧夜晚的灵光一现,到今天已经能够生成以假乱真的图像、视频甚至虚拟世界,这段旅程充满了惊喜和突破。
GANs不仅仅是一项技术,更是人工智能向"创造力"迈进的重要里程碑。它让我们看到了AI的无限可能:
🎨 在艺术领域,AI成为了创作者的得力助手,帮助人们实现天马行空的想象。
🔬 在科学研究中,GANs加速了新药发现、材料设计等关键领域的进展。
🎓 在教育领域,个性化的学习内容让每个人都能获得最适合的教育体验。
🌍 在社会生活中,虚拟与现实的边界日益模糊,我们正在进入一个全新的时代。
对初学者的寄语
如果你是刚刚踏入这个领域的新手,请记住:
-
保持好奇心:GANs的世界充满了待探索的奥秘,每一个新发现都可能改变世界。
-
动手实践:理论知识固然重要,但只有通过实际编码和实验,你才能真正理解GANs的魅力。
-
持续学习:这个领域发展迅速,新的技术和应用层出不穷,保持学习的热情至关重要。
-
关注伦理:强大的技术带来强大的责任,在追求技术突破的同时,也要思考如何让AI更好地服务人类。
-
建立网络:加入社区,与同行交流,分享经验,共同成长。
对未来的展望
展望未来,GANs的发展将继续加速:
- 技术突破:更强大的模型、更高效的训练方法、更精确的控制机制
- 应用拓展:从2D图像到3D世界,从静态内容到动态交互
- 社会影响:重塑创意产业,变革教育模式,影响社会结构
我们正站在一个激动人心的时代节点上。GANs为我们打开了通往AI创造力的大门,而这扇门后的世界还有无穷的可能等待我们去探索。
无论你是研究者、工程师、艺术家,还是对技术充满好奇的爱好者,GANs都为你提供了一个展现创造力的舞台。在这里,你可以让AI学会画画、写诗、作曲,甚至创造出前所未有的艺术形式。
最后的邀请
现在,是时候开始你的GANs学习之旅了!
- 选择一个简单的项目开始(比如MNIST数字生成)
- 动手写出你的第一行GAN代码
- 观察训练过程中的奇妙变化
- 分享你的成果和心得体会
- 不断挑战更复杂的项目
记住,每一个伟大的创新都始于好奇心和第一次尝试。今天的你,可能就是明天GANs领域的创新者!
🚀 准备好了吗?让我们一起踏上这场探索AI创造力的奇妙之旅!
"The best way to predict the future is to create it."
"预测未来的最好方法就是创造未来。"
愿每一位踏入GANs世界的探索者,都能在这片充满可能的土地上,种下属于自己的创新种子,见证AI与人类创造力的完美融合!