文章目录
-
- [3.1 MPI_Bcast广播](#3.1 MPI_Bcast广播)
- [3.2 MPI_Scatter, MPI_Gather, and MPI_Allgather](#3.2 MPI_Scatter, MPI_Gather, and MPI_Allgather)
-
- [3.2.1 MPI_Scatter](#3.2.1 MPI_Scatter)
- [3.2.2 MPI_Gather](#3.2.2 MPI_Gather)
- [3.2.3 MPI_Allgather](#3.2.3 MPI_Allgather)
集体通信指的是一个涉及 communicator 里面所有进程的一个方法。关于集体通信需要记住的一点是它在进程间引入了同步点的概念。这意味着所有的进程在执行代码的时候必须首先 都 到达一个同步点才能继续执行后面的代码。MPI 有一个特殊的函数来做同步进程的这个操作:
cpp
MPI_Barrier(MPI_Comm comm)这个方法会构建一个屏障,任何进程都没法跨越屏障,直到所有的进程都到达屏障。这边有一个示意图。假设水平的轴代表的是程序的执行,小圆圈代表不同的进程。
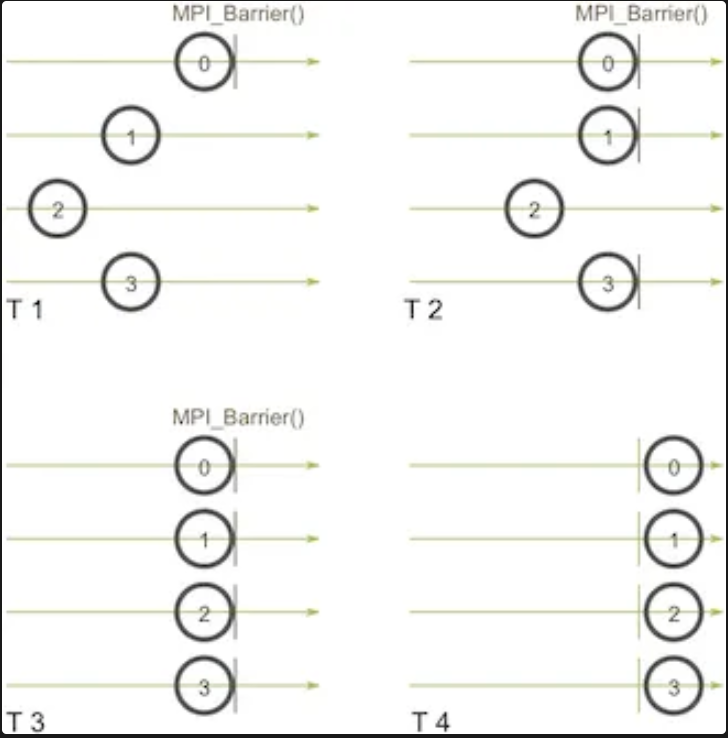
这里四个时间内不同进程的执行逻辑是:进程0在时间点 (T 1) 首先调用 MPI_Barrier。然后进程0就一直等在屏障之前,之后进程1和进程3在 (T 2) 时间点到达屏障。当进程2最终在时间点 (T 3) 到达屏障的时候,其他的进程就可以在 (T 4) 时间点再次开始运行。MPI_Barrier 在很多时候很有用。其中一个用途是用来同步一个程序,使得分布式代码中的某一部分可以被精确的计时。
注意:在 MPI 中,所有的集体通信 (如
MPI_Bcast、MPI_Gather、MPI_Scatter等)都是同步的 ,也就是说:必须让所有相关进程都参与到同一次集体通信中,否则有一个进程掉队,其他进程就会一直等待,导致死锁。
3.1 MPI_Bcast广播
广播 (broadcast) 是标准的集体通信技术之一。一个广播发生的时候,一个进程会把同样一份数据传递给一个 communicator 里的所有其他进程。广播的主要用途之一是把用户输入传递给一个分布式程序,或者把一些配置参数传递给所有的进程。它的函数签名:
cpp
MPI_Bcast(void *buffer, int count, MPI_Datatype datatype,
int root, // 广播的根进程的rank值(进程号)
MPI_Comm comm)当根节点(在我们的例子是节点0)调用 MPI_Bcast 函数的时候,buffer 变量里的值会被发送到其他的节点上。当其他的节点调用 MPI_Bcast 的时候,buffer 变量会被赋值成从根节点接受到的数据。我们可以使用MPI_Send和 MPI_Recv来实现广播,代码很简单如下:
cpp
void my_bcast(void* data, int count, MPI_Datatype datatype, int root,
MPI_Comm communicator) {
int world_rank;
MPI_Comm_rank(communicator, &world_rank);
int world_size;
MPI_Comm_size(communicator, &world_size);
if (world_rank == root) {
// If we are the root process, send our data to everyone
int i;
for (i = 0; i < world_size; i++) {
if (i != world_rank) {
MPI_Send(data, count, datatype, i, 0, communicator);
}
}
} else {
// If we are a receiver process, receive the data from the root
MPI_Recv(data, count, datatype, root, 0, communicator,
MPI_STATUS_IGNORE);
}
}根节点把数据传递给所有其他的节点,其他的节点接收根节点的数据。但是这里的效率很低,因为每次并不是一下就完成了所有的进程发送和接收。只是使用了进程0的一次次的传递数据。这里有一些优化算法,如:基于树的沟通算法。
3.2 MPI_Scatter, MPI_Gather, and MPI_Allgather
3.2.1 MPI_Scatter
MPI_Scatter是一个类似MPI_Bcast的集体通信机制。它会会设计一个指定的根进程,根进程会将数据发送到 communicator 里面的所有进程,但是给每个进程发送的是一个数组的一部分数据 。
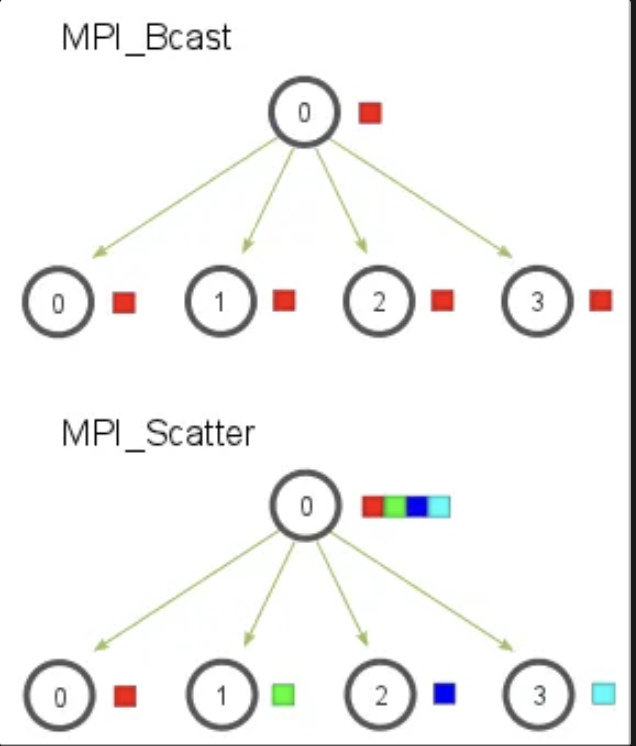
MPI_Bcast 在根进程上接收一个单独的数据元素,复制给其他进程。
MPI_Scatter 接收一个数组,并把元素按进程的秩分发出去。尽管根进程(进程0)拥有整个数组的所有元素,MPI_Scatter 还是会把正确的属于进程0的元素放到这个进程的接收缓存中。
cpp
int MPI_Scatter(
const void *sendbuf, // 发送缓存(存储要发送的数据的起始地址)
int sendcount, // 发送数据的数量(每个进程接收的元素个数)
MPI_Datatype sendtype, // 发送数据的类型(如 MPI_INT, MPI_FLOAT 等)
void *recvbuf, // 接收缓存(存储接收到的数据的起始地址)
int recvcount, // 接收数据的数量(每个进程接收的元素个数)
MPI_Datatype recvtype, // 接收数据的类型(如 MPI_INT, MPI_FLOAT 等)
int root, // 根进程(发送数据的源进程)
MPI_Comm comm) // 通信器(指定通信域,如 MPI_COMM_WORLD)3.2.2 MPI_Gather
顾名思义这里的MPI_Gather是和MPI_Scatter 相反的。它是从多个进程里面收集数据到一个进程上面,这个机制对很多平行算法很有用,比如并行的排序和搜索。如图:
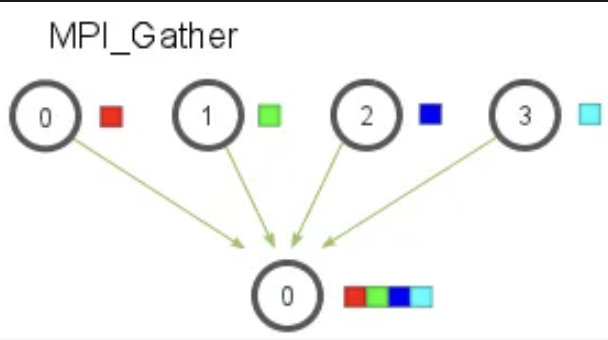
元素是根据接收到的进程的秩排序的。函数签名如下:
cpp
int MPI_Gather(
const void *sendbuf, // 发送缓冲区(存储要发送的数据的起始地址)
int sendcount, // 发送数据的数量(每个进程发送的数据元素个数)
MPI_Datatype sendtype, // 发送数据的类型(如 MPI_INT, MPI_FLOAT 等)
void *recvbuf, // 接收缓冲区(存储接收到的数据的起始地址,只有 root 进程需要设置)
int recvcount, // 接收数据的数量(从每个进程接收的数据元素个数)
MPI_Datatype recvtype, // 接收数据的类型(如 MPI_INT, MPI_FLOAT 等)
int root, // 根进程(用于收集数据的目标进程)
MPI_Comm comm // 通信器(指定通信域,如 MPI_COMM_WORLD)
);只有根进程需要一个有效的接收缓存。所有其他的调用进程可以传递NULL给recvbuf。另外,别忘记*recvcount*参数是从每个进程接收到的数据数量,而不是所有进程的数据总量之和。
范例:用
Scatter和Gather计算平均数
首先生成一个随机数的数组,scatter给不同进程,每个进程的到相同多数量的随机数,每个进程计算各自的avg,然后最后求总的avg。
cpp
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <mpi.h>
#include <assert.h>
// Creates an array of random numbers. Each number has a value from 0 - 1
float *create_rand_nums(int num_elements) {
float *rand_nums = (float *)malloc(sizeof(float) * num_elements);
assert(rand_nums != NULL);
int i;
for (i = 0; i < num_elements; i++) {
rand_nums[i] = (rand() / (float)RAND_MAX);
}
return rand_nums;
}
// Computes the average of an array of numbers
float compute_avg(float *array, int num_elements) {
float sum = 0.f;
for (int i = 0; i < num_elements; i++) {
sum += array[i];
}
return sum / num_elements;
}
int main(int argc, char** argv) {
if (argc != 2) {
fprintf(stderr, "Usage: avg num_elements_per_proc\n");
exit(1);
}
int num_elements_per_proc = atoi(argv[1]);
// Seed the random number generator to get different results each time
srand(time(NULL));
MPI_Init(NULL, NULL);
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// Create a random array of elements on the root process. Its total
// size will be the number of elements per process times the number
// of processes
float *rand_nums = NULL;
if (world_rank == 0) {
rand_nums = create_rand_nums(num_elements_per_proc * world_size);
}
// For each process, create a buffer that will hold a subset of the entire array
float *sub_rand_nums = (float *)malloc(sizeof(float) * num_elements_per_proc);
assert(sub_rand_nums != NULL);
// Scatter the random numbers from the root process to all processes in the MPI world
MPI_Scatter(rand_nums, num_elements_per_proc, MPI_FLOAT, sub_rand_nums,
num_elements_per_proc, MPI_FLOAT, 0, MPI_COMM_WORLD);
// Compute the average of your subset
float sub_avg = compute_avg(sub_rand_nums, num_elements_per_proc);
// Gather all partial averages down to the root process
float *sub_avgs = NULL;
if (world_rank == 0) {
sub_avgs = (float *)malloc(sizeof(float) * world_size);
assert(sub_avgs != NULL);
}
MPI_Gather(&sub_avg, 1, MPI_FLOAT, sub_avgs, 1, MPI_FLOAT, 0, MPI_COMM_WORLD);
// Now that we have all of the partial averages on the root, compute the
// total average of all numbers. Since we are assuming each process computed
// an average across an equal amount of elements, this computation will
// produce the correct answer.
if (world_rank == 0) {
float avg = compute_avg(sub_avgs, world_size);
printf("Avg of all elements is %f\n", avg);
// Compute the average across the original data for comparison
float original_data_avg = compute_avg(rand_nums, num_elements_per_proc * world_size);
printf("Avg computed across original data is %f\n", original_data_avg);
}
// Clean up
if (world_rank == 0) {
free(rand_nums);
free(sub_avgs);
}
free(sub_rand_nums);
MPI_Barrier(MPI_COMM_WORLD);
MPI_Finalize();
return 0;
}
/******************************************************************
(base) joker@joker-2 4.2 Collective % mpic++ avg_scatter_gather.cc -o avg_scatter_gather
(base) joker@joker-2 4.2 Collective % mpirun -np 4 ./avg_scatter_gather 2
Avg of all elements is 0.444133
Avg computed across original data is 0.444133
*******************************************************************/3.2.3 MPI_Allgather
前面出现了一对多,多对一,一对一等的通信模式,那么MPI_Allgather就是多对多。准确来说是收集所有进程的数据然后发到所有进程上,不涉及根进程了,所以可以看到函数签名里面少了int root。
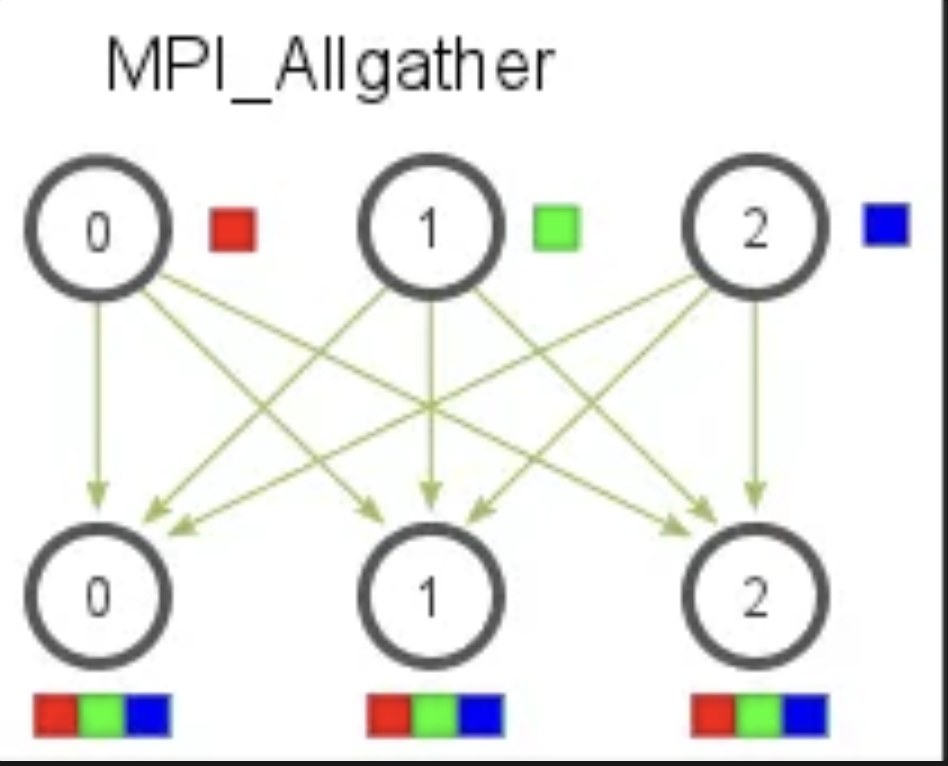
cpp
int MPI_Allgather(
const void *sendbuf, // 发送缓冲区(存储要发送的数据的起始地址)
int sendcount, // 发送数据的数量(每个进程发送的数据元素个数)
MPI_Datatype sendtype, // 发送数据的类型(如 MPI_INT, MPI_FLOAT 等)
void *recvbuf, // 接收缓冲区(存储接收到的数据的起始地址)
int recvcount, // 每个进程接收的数据数量
MPI_Datatype recvtype, // 接收数据的类型(如 MPI_INT, MPI_FLOAT 等)
MPI_Comm comm // 通信器(指定通信域,如 MPI_COMM_WORLD)
);对上一个计算平均数的代码修改,将最后输出的每个线程都是全局平均值。代码如下:
cpp
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <mpi.h>
#include <assert.h>
// Creates an array of random numbers. Each number has a value from 0 - 1
float *create_rand_nums(int num_elements) {
float *rand_nums = (float *)malloc(sizeof(float) * num_elements);
assert(rand_nums != NULL);
int i;
for (i = 0; i < num_elements; i++) {
rand_nums[i] = (rand() / (float)RAND_MAX);
}
return rand_nums;
}
// Computes the average of an array of numbers
float compute_avg(float *array, int num_elements) {
float sum = 0.f;
for (int i = 0; i < num_elements; i++) {
sum += array[i];
}
return sum / num_elements;
}
int main(int argc, char** argv) {
if (argc != 2) {
fprintf(stderr, "Usage: avg num_elements_per_proc\n");
exit(1);
}
int num_elements_per_proc = atoi(argv[1]);
// Seed the random number generator to get different results each time
srand(time(NULL));
MPI_Init(NULL, NULL);
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// Create a random array of elements on the root process. Its total
// size will be the number of elements per process times the number
// of processes
float *rand_nums = NULL;
if (world_rank == 0) {
rand_nums = create_rand_nums(num_elements_per_proc * world_size);
}
// For each process, create a buffer that will hold a subset of the entire array
float *sub_rand_nums = (float *)malloc(sizeof(float) * num_elements_per_proc);
assert(sub_rand_nums != NULL);
// Scatter the random numbers from the root process to all processes in the MPI world
MPI_Scatter(rand_nums, num_elements_per_proc, MPI_FLOAT, sub_rand_nums,
num_elements_per_proc, MPI_FLOAT, 0, MPI_COMM_WORLD);
// Compute the average of your subset
float sub_avg = compute_avg(sub_rand_nums, num_elements_per_proc);
// Gather all partial averages down to the root process
float *sub_avgs = (float*)malloc(sizeof(float) * num_elements_per_proc);
assert(sub_avgs != NULL);
MPI_Allgather(&sub_avg, 1, MPI_FLOAT, sub_avgs, 1, MPI_FLOAT, MPI_COMM_WORLD);
// Now that we have all of the partial averages on the root, compute the
// total average of all numbers. Since we are assuming each process computed
// an average across an equal amount of elements, this computation will
// produce the correct answer.
float avg = compute_avg(sub_avgs, world_size);
printf("Avg of all elements from proc is %f\n", avg);
// Compute the average across the original data for comparison
// float original_data_avg = compute_avg(rand_nums, num_elements_per_proc * world_size);
// printf("Avg computed across original data is %f\n", original_data_avg);
// Clean up
if (world_rank == 0) {
free(rand_nums);
free(sub_avgs);
}
free(sub_rand_nums);
MPI_Barrier(MPI_COMM_WORLD);
MPI_Finalize();
return 0;
}
/******************************************************************
(base) joker@joker-2 4.2 Collective % mpic++ avg_allgather.cc -o avg_allgather
(base) joker@joker-2 4.2 Collective % mpirun -np 4 ./avg_allgather 3
Avg of all elements from proc is 0.579840
Avg of all elements from proc is 0.579840
Avg of all elements from proc is 0.579840
Avg of all elements from proc is 0.579840
*******************************************************************/