main page :https://city-super.github.io/anysplat/
arxiv :https://arxiv.org/pdf/2505.23716
基于mvs的重建方法目前主要集中于3r系列,这是纯数据驱动的方法,然而只能得到稠密点云,但是显然我们更关注3DGS,3r-based连通GS的pipeline之前也有很多,像早期24年的instansplat,以及后续的splatt3r、noposplat都是对此问题的尝试,然而效果都不是很稳定,anysplat是在浙大flare之后的工作。
另外,个人觉得anysplat起码有两个highlight,第一,CVPR2025的best paper是VGGT,这足以说明其效果以及影响,anysplat在3r-based连通GS的pipeline(transformer+高斯球属性预测头)基础上,对vggt做了蒸馏,这大大提升了此pipeline的效果,消融实验可见。第二,anysplat使用八叉树做了高斯球的压缩,这不仅使得其视图扩展性增强,更使推理加速化,因为以往pipeline中是一个pixel-wise的GS模型。本文是对这篇文章的详细记录,感谢各位作者们的精彩构思以及great work!
1.简介
3D基础模型Vggt、Dust3r、Fast3r的最新进展改变了我们看待从2D图像重建3D场景问题的方式。通过在几秒钟内将密集的点云从单个视图推断为数千个视图,这些方法简化甚至消除了传统的多阶段重建管道,使3D场景重建在更广泛的应用中更容易访问。

如图1,AnySplat是一种面向无约束、无位姿标注多视角图像的前馈式新视角合成网络。该网络采用几何变换器将输入图像编码为高维特征,继而解码为高斯参数与相机位姿 。**为提升效率,我们创新性地引入可微分体素化模块,将像素级高斯基元合并为体素级高斯体,在保持渲染质量的同时减少30-70%冗余基元。****针对现实场景中3D标注噪声问题,我们设计了新型自监督知识蒸馏框架,从预训练的VGGT骨干网络提取相机与几何先验作为外部监督。**这使得AnySplat无需任何三维运动恢复结构(SfM)或多视图立体(MVS)监督,仅依赖未标定图像即可完成训练,为规模化无约束拍摄提供了可能。 我们在九个多样化大规模数据集上训练AnySplat,使模型接触广泛的几何与外观变化。实验表明,该方法在未见数据集上展现出卓越的零样本泛化能力:相较当前最优的前馈式与优化基方法,AnySplat能实现更优质的新视角合成效果、更一致的几何结构、更精确的位姿估计以及更快的推理速度。
我们的核心贡献包括:
前馈式重建与渲染:模型可直接处理未标定的多视角输入,同步预测3D高斯基元及其相机内外参数,其重建质量不仅超越现有前馈方法,在复杂场景下甚至优于基于优化的传统流程。
高效自监督知识蒸馏:通过创新的端到端训练框架,从预训练VGGT模型中提取几何先验,无需任何3D标注即可实现高保真渲染与强化的多视角一致性,在8-16块GPU上训练时间短于1天。
可微分体素导向的高斯剪枝:定制化的体素化策略可剔除30%-70%的高斯基元而不损渲染质量,形成统一的计算高效模型,从容应对稀疏与密集拍摄场景。
1*.Generalizable 3D Reconstruction 现状(可跳过)
最近提出的几种通用三维重建方法大致可分为两类:需要已知相机参数的位姿感知方法(pose-aware ) ,以及同时推断几何和相机位姿的位姿无关方法(pose-free )。
pose-aware Generalizable model:
这类方法能够从已标定的图像及其对应位姿快速重建三维模型。这些方法主要分为三种技术路线:
1)基于3D高斯泼溅的技术pixelsplat、Mvsplat、Mvsplat360、Freesplat、Depthsplat,直接预测3D高斯基元作为场景表示;
2)基于神经网络的框架Quark、Lvsm:A large view synthesis model with minimal 3d inductive bias,使用神经网络推断新视角图像的外观而无需任何3D表示;
3)新兴的LRM架构系列Lrm: Large reconstruction model for single image to 3d、Gs-lrm: Large recon-struction model for 3d gaussian splatting。尽管这些位姿感知重建方法显著减少了优化时间,并提升了稀疏视角条件下的性能,但由于需要准确的图像位姿作为输入,其广泛应用仍然受限。
pose-free Generalizable model:
位姿无关通用方法仅依赖图像作为输入,其中大多数方法在重建三维模型的同时预测图像位姿。在这些方法中,DUSt3R40及其扩展MASt3R19使用单一的大规模模型替代传统的多阶段流程,联合预测深度并将其融合为密集场景。包括CUT3R39、VGGT38和Fast3R47在内的最新方法,通过级联Transformer模块在一次前向传播中联合推断相机位姿、点轨迹和场景几何,在精度和运行时间上都取得了显著提升。尽管这些方法展现了高效扩展三维资产重建的潜力,但它们普遍存在纹理表征不足和多视角错位问题,这严重影响了它们的新视角合成性能。
2.method
2.1问题设定

2.2pipeline
我们的流程是:首先将一组未标定的多视角图像编码为高维特征表示,随后将这些特征解码为3D高斯参数及其对应的相机位姿。为应对密集视角下逐像素高斯基元数量线性增长的问题,我们引入了可微分体素化模块------该模块通过将基元聚类至体素空间,在保持梯度平滑传播的同时显著降低了计算开销。

2.2.1.Geometry Transformer
我们follow了VGGT的transformer,如下图,即对于训练集中的任意图片 ,先将划分为边长p=14的
,先将划分为边长p=14的 个patches,然后将每个patch使用DINOv2编码成为长度为d=1024的token,也就是说每个图片本身都对应这样一个token序列:
个patches,然后将每个patch使用DINOv2编码成为长度为d=1024的token,也就是说每个图片本身都对应这样一个token序列: ,另外,对每张图的token序列前面还会添加
,另外,对每张图的token序列前面还会添加
 ,并且,对于训练集中第一张图片,还会额外添加一列位置编码。
,并且,对于训练集中第一张图片,还会额外添加一列位置编码。
以上是每一个图片的处理方法,也就是它对应一组tokens ,最后,把训练集中所有N张图片的tokens拼接起来,送入L层的交替注意力Transformer中进行处理:
,最后,把训练集中所有N张图片的tokens拼接起来,送入L层的交替注意力Transformer中进行处理:
(1)帧内注意力:处理形状为 的token
的token
(2)全局注意力:联合处理所有视图的 token
token
VGGT狂徒:

张量图

2.2.2.decode
利用per-pixel的深度信息实现per-pixel的高斯球信息,注意,encoder层是同一个,但是针对不同性质的输出,decoder层是各自不一样的。
1.pose估计
在transformer中 会输入到相机解码器FC中进行处理------该解码器包含四层自注意力模块和线性投影头,最终输出各相机参数pi。依照先前研究惯例,我们将首个相机位姿设为恒等变换,其余所有位姿均在该共享局部坐标系中表示。
会输入到相机解码器FC中进行处理------该解码器包含四层自注意力模块和线性投影头,最终输出各相机参数pi。依照先前研究惯例,我们将首个相机位姿设为恒等变换,其余所有位姿均在该共享局部坐标系中表示。
2.Pixel-wise Gaussian Parameter
我们使用DPT解码器来预测高斯球参数**,首先,使用pose+深度 来估计高斯球的中心**,这是一个不错的设计,所以:
(1)预测深度
depth head  输入图像tokens
输入图像tokens ,输出像素级的深度图
,输出像素级的深度图 以及置信度图
以及置信度图 ,
,
(2)预测高斯球中心
然后根据前面预测的相机pose,反投影计算得到高斯球的中心位置 ,当然所有高斯球的坐标系都在第一帧图像对应的坐标系下。
,当然所有高斯球的坐标系都在第一帧图像对应的坐标系下。
(3)其他参数
高斯球解码器通过两种featurs相加然后送进一个CNN回归器 得出,一个是DPT的feature
得出,一个是DPT的feature 另外一个是浅层CNN提取的外观特征
另外一个是浅层CNN提取的外观特征 ,最后得到:
,最后得到:

*****DPT的相关介绍:

2.2.3Differentiable Voxelization
通过3r based方法对于per-pixle depth的预测,目前大部分3r based-splat方法实现了per-pixle gaussian的预测。 实际上,图片高分辨率再加上视图数量的增加,计算成本非常高,所以很多方法在计算效率上来说就已经很难从稀疏视角重建扩展到稠密视角**。**
而本文的做法是,使用八叉树来压缩per-pixle gaussian的信息,这样得变per-pixle使成了per-voxel,大幅度减少计算成本增加了可扩展性**(一句话说就是融合了体素内的所有高斯球变成了一个'融合高斯球')****。具体来说,先用八叉树分隔per-pixle的高斯球中心,然后对于每一个voxel内的高斯球赋予一个额外的可学习的权重attribute,最后,对体素内的所有高斯球属性来个加权平均,这就得到了该体素的高斯属性,达到压缩的目的。具体做法如下:**
基于Scaffold-gs作者构建了一个可微体素模块,也就是把G个高斯球中心聚类到S个size为的体素中:

为了保持体素化可微,每个高斯也会预测一个置信度Cg。我们通过softmax将这些scores转换为体素内的权重,换句话说,也就是每个高斯球在所属voxel内所有高斯球中占的权重:

最后,所有的voxel都会集成高斯球的综合属性,也就是将任意的per-pixel的高斯球属性(比如颜色、不透明度)聚合到voxel内,通过下式:
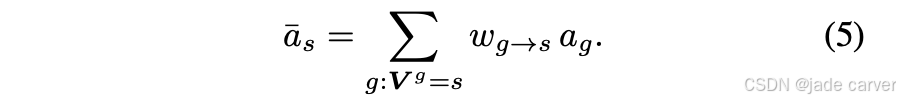
综上,我们管道的输出由每个体素Vs ∈ {1,...,S}的高斯属性 参数化。我们可以使用可微的高斯光栅化17,50有效地渲染我们的模型预测的高斯。
参数化。我们可以使用可微的高斯光栅化17,50有效地渲染我们的模型预测的高斯。
2.3训练与推理
2.3.1.geometry consistency loss
同步预测深度图与相机位姿会引入多视角对齐聚合的隐式歧义:当将单图像预测提升至3D空间时,这些不一致性会表现为重建点云中的分层伪影(layered sheets)(重影)。这类伪影在原始点云中可能不易察觉,但在渲染视图中会显著暴露。比如colmap中计算错误的3D点,在稀疏点云中可能肉眼看着不明显,但是送进GS里面重建出来就会发现有"重影"。
为解决该问题,我们提出几何一致性损失 (geometry consistency loss),通过强制对齐高斯渲染深度与深度head预测的值的一致性来消除分层伪影,重建连贯的表面几何结构。

这里写的太那啥了 ,我来补充一下吧!(可以跳过)
(1*)什么叫同步预测深度图与相机位姿会引入多视角对齐聚合的隐式歧义?
我们不得不提到传统的三角测量,根据已有图片恢复3D场景:
首先需要根据图片特征来求解相机pose,也就是:

然后接着恢复3D点,这里就需要计算深度:

可以看到,这个问题一开始就是一个分阶段迭代优化的过程,也就是一个阶段求解pose然后再求解深度,最后联合优化。
前面提到,我们在使用数据驱动方法预测相机pose与深度,并且这是直接用数据驱动的方式来end-to-end得到,这个问题的设置是这样的:

实际上这还是和前面的公式一样,只不过这里是显式优化深度,而上面优化3D点时就带有深度,但是这里如果同时计算深度D和相机pose R,当他们带有扰动时,这个等式同样会成立,换句话说会产生误差抵消,结果就是优化不充分,明明误差很接近0,但是误差藏在解出的值里面,紧接着,产生错误的解,比如,标准解是(D*,R*),但是因为误差抵消,(,
)满足方程,(
,
)也满足,这样就是一组2D(只对应一个3D点)点解出了两个3D点,常见的情况就是出现重影。
(2)单图像预测提升至3D空间
讲人话就是本文使用DPT特征+CNN特征从2D图像编码中预测了深度,结合相机参数将2D点升维到3D。
2.3.2 vggt distillation loss
在没有新视角监督信号的情况下,模型容易对上下文视角过拟合,以规避多视角变化带来的干扰。这会导致泛化性能下降,引发深度与相机位姿预测失败。为解决该问题,我们利用预训练的vggt模型蒸馏相机参数与场景几何先验(深度) 以稳定训练。也就是说,上面的一致性loss中深度head的预测值是经过vggt蒸馏的。

这种蒸馏损失显著提高了训练稳定性,并有助于避免收敛到不良的局部最小值。
2.3.3训练办法
AnySplat采用完全自监督 的训练方式,无需任何3D真值标注。具体而言,给定一组无位姿标注且未标定的多视角图像 作为输入,首先生成预测的相机内参和外参,随后利用这些参数完成以下流程:
作为输入,首先生成预测的相机内参和外参,随后利用这些参数完成以下流程:
-
高斯基元投影:将3D高斯基元的位置映射至图像平面
-
可微分渲染 :通过溅射渲染(splatting)生成合成视图

最终的loss为:

这是NVS任务 ,训练过程仅使用上下文视角(不含新视角监督),AnySplat凭借以下两大核心优势仍能实现卓越的新视角渲染效果:
-
先验蒸馏机制:从预训练vggt提取几何与位姿约束
-
强场景建模能力:通过各向异性3D高斯实现精细场景表达
3. Experiments
follow CUT3R 39 and DUST3R,使用了9个公开数据集:
Hy-persim 32, ARKitScenes 2, BlendedMVS 48, Scan-Net++ 51, CO3D-v2 30, Objaverse 6, Unreal4K 36,WildRGBD 43, and DL3DV 21,将模型暴露在广泛的几何和外观变化中,增强泛化性。在16个NVIDIA A800 GPUs上面训练大约一天。
3.1NVS
在稀疏视图和密集视图设置下,根据两个zero-shot NVS数据集:Deep-Blending和VRNeRF ,对以前的方法进行定量评估。
如表2和图3,在稀疏视角的前提下,与最近的前馈方法(如NoPoSplat 49和Flare 55)相比,AnySplat在这两个数据集实现了改进的渲染性能。有两个主要原因:1)AnySplat在一组多样化的数据集中进行了训练,并结合了随机输入视图的分离策略,这有助于其卓越的zero-shot推广;2)它实现了更准确的geometry和pose估计,由于渲染质量在很大程度上与姿势准确性有关,这导致了更好的视觉效果。此外,随着输入视图数量的增加,我们的方法展示了更快的推理时间,这对现实世界的应用来说是很大的。


在密集视图设置(超过32个视图)中,AnySplat继续优于基于优化的方法,如3DGS 17和Mip-Splatting 52(具有VGGT初始化),如表3和图3所示。这些基于优化的方法往往会过度适应训练视图,通常会导致新视图中的伪影。相比之下,我们的方法重建了更精细、更干净的几何形状,并且,AnySplat实现的重建时间要快一个数量级。


AnySplat还可以通过可选的优化后步骤实现进一步的改进。如图5和表5所示,我们在Matrixcity数据集20上发现即使有200个输入,只需再训练1000个iterations(花费不到两分钟)就能获得更好的结果,3000个iterations可以获得更好的结果。


3.2 相对位姿估计与多视角几何一致性
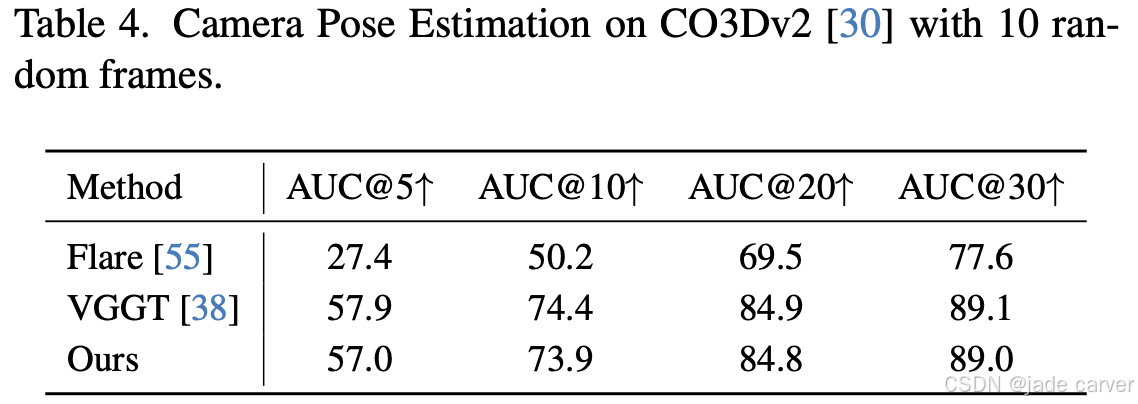
我们在CO3Dv2数据集上采用前馈式推理设置进行评估(随机选取10帧作为输入),并与VGGT和Flare进行性能对比(如表4所示)。本方法在保持接近VGGT位姿精度的同时(牺牲微量位姿准确性以换取更好的多视角一致性),显著优于Flare算法。
我们还在Hypersim数据集上对比了训练初期与末期两种深度图的一致性,尽管VGGT38在单目深度预测中表现优异,但由于缺乏显式3D几何约束且对低置信度区域(特别是物体边界)敏感,其跨视角一致性较差。相比之下,AnySplat通过3D渲染监督显著提升了多视角一致性,图6中比较了GS渲染深度与DPT预测深度的差异,随着训练轮数增加差异越来越小。

3.3消融实验
可以看到没有蒸馏loss效果下降了很多!

再看看下面这张图,描述了pixel-wise与voxel-wise的差别

4.Conclusion
通过整合轻量化渲染头与几何一致性增强模块,结合自监督渲染代理与知识蒸馏技术,为三维基础模型的潜力释放与规模化应用提供了创新解决方案。实验表明,该模型在稀疏和密集多视角重建任务中,针对无约束、未标定的输入数据均表现出强劲竞争力。其高效训练特性(所需时间和算力极低)可实现秒级推理,实时生成三维高斯泼溅重建结果与高保真渲染。
存在的挑战:
特殊场景伪影
- 天空区域、镜面高光及薄结构仍存在重建瑕疵
- 基于重建的渲染损失在动态场景/光照变化下稳定性不足
计算-分辨率权衡
- 高斯基元数量随输入分辨率及体素粒度增长而激增
- 超高分辨率或多视角输入时性能下降显著