上篇文章【论文品鉴 DeepSeek V3 最新论文 之 DeepEP】 介绍了分布式并行策略中的EP,简单的提到了其他几种并行策略,但碍于精力和篇幅限制决定将内容分几期,本期首先介绍DP,但并不是因为DP简单,相反DP的水也很深,例如:"DP到底同步的是什么数据?怎么同步的?","AllReduce/Ring-AllReduce是什么?","ZeRO1、2、3又都是什么?" 等各种问题,会结合PyTorch代码,尽量做到详细由浅入深。
单机单卡
在深入分布式并行策略前,先回顾一下单机单卡的训练模式:

CPU加载数据,并将数据分成batch批次CPU将batch批次数据传给GPUGPU进行前向传播计算得到lossGPU再通过反向传播通过loss得到梯度GPU再通过梯度更新参数
伪代码:
python
model = Model(xx) # 1. 模型初始化
optmizer = Optimizer(xx) # 2. 优化器初始化
output = model(input) # 3. 模型计算
loss = loss_function(output, target) # 4. loss计算
loss.backward() # 5. 反向传播计算梯度
optimizer.step() # 6. 优化器更新参数 DP
就像 多线程编程 一样,可以通过引入 多个GPU 来提高训练效率,这就引出了最基础的 单机多卡 DP,即 Data Parallel 数据并行。

CPU加载数据,并将数据拆分,分给不同的GPUGPU0将模型复制到 其他所有GPU- 每块
GPU独立的进行前向传播和反向传播得到梯度 - 其余所有
GPU把梯度传给GPU0 GPU0汇总全部梯度进行全局平均计算GPU0通过全局平均的梯度更新自己的模型GPU0再把最新的模型同步到其他GPU
DP的PyTorch伪代码,相比于单机单卡,大部分都没有变化,只是把模型换了DataParallel模型,在PyTorch中通过nn.DataParallel(module, device_ids) 实现:
python
model = Model(xx) # 1. 模型初始化(没变化)
model_new = torch.nn.DataParallel(model, device_ids=[0,1,2]) # 1.1 启用DP (新增)
optmizer = Optimizer(xx) # 2. 优化器初始化(不变)
output = model_new(input) # 3. 模型计算,替换使用DP(变更)
loss = loss_function(output, target) # 4. loss计算(不变)
loss.backward() # 5. 反向传播计算梯度(不变)
optimizer.step() # 6. 优化器更新参数 (不变)可见DP使用上非常简单,通过nn.DataParallel套上之前的模型即可。
但是DP存在 2个 比较严重的问题:
- 数据传输量较大:不考虑
CPU将input数据拆分传输给每块GPU,单独看GPU间的数据传递;对于GPU0它需要把整个模型的参数广播到其他所有GPU,假设有 N N N块GPU,那么就需要传输 ( N − 1 ) ∗ w (N-1)*w (N−1)∗w参数,同时GPU0也需要从其他所有GPU上Reduce所有梯度,那么就要传输 ( N − 1 ) ∗ g (N-1)*g (N−1)∗g,所以对于GPU0来说要传输 ( N − 1 ) ∗ ( w + g ) (N-1)*(w +g) (N−1)∗(w+g)的数据,同理对于其他GPU来说,要传输与来自GPU0的参数,与传出自己那份梯度。所以整体上个说,GPU数量多 N N N越大,传输的数据量就越多。 GPU0的压力太大:它要收集梯度、更新参数、同步参数,计算和通信压力都很大
接下来看一下更高级用法 DDP
DDP
DDP 即 Distributed Data Parallel,多机多卡的分布式数据并行。

与 DP 最主要的区别就是,解决了 DP 的 主节点瓶颈,实现了真正的 分布式通信。
而精髓就是 Ring-AllReduce,下面介绍它是如何实现 梯度累计 的:
- 假设梯度目前都是单独存在于不同GPU上,而目标是将三个GPU的梯度进行累计,也就是得到下图中三个梯度的和,
a0+a1+a2与b0+b1+b2和c0+c1+c2

- 首先第一阶段:
GPU0将a0发送给GPU1去求和a0+a1,GPU1将b1发送给GPU2去求和b1+b2,GPU2将c2发送给GPU0去求和c0+c2

- 然后,继续累加,将
GPU0上的c0+c2发送给GPU1去求c0+c1+c2,GPU1将a0+a1发送给GPU2去求a0+a1+a2,将GPU2将b1+b2发送给GPU0去求b0+b1+b2

- 此时第一阶段完成,通过
Scatter-Reduce将参数分发后集合,分别得到了各个参数梯度累计结果

- 之后的第二节阶段,通过
All-Gather将各个参数的梯度进行传播,使得每个GPU上都得到了完整的梯度结果 - 首先,
GPU0将完整的b0+b1+b2传递给GPU1,同理GPU1和GPU2也传递完整的梯度

- 最后,再将剩余的梯度进行传递
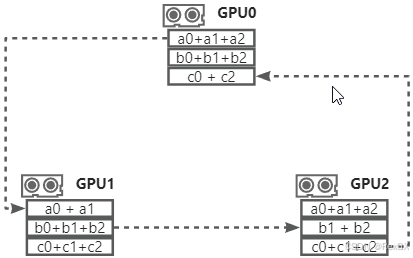
- 最终每个设备得到了所有参数的完整梯度累计

在 DDP 的Ring-AllReduce 中还有一个细节:如果每个参数都这么Ring着进行信息梯度累计,那么通信压力太大了;
所以设计了桶,通过将参数分桶聚合,也就是一个桶中维护了多个参数,当整个桶中的所有梯度都计算完毕后,再以桶维度进行Ring的梯度累计,这样降低了通信压力,提高了训练效率。
DDP的落地,相较于DP会复杂很多,首先简单理解几个概念:
world:代表着DDP集群中的那些卡的rank:world中,每张卡的唯一标识nccl、gloo:都是通信库,也就是那些分布式原语的实现,现在普遍都用老黄家的NCCL,搭配RMDA食用效率更高
接下来看一下DDP的PyTorch伪代码:
python
# 首先需要在每张卡,也就是进程单位设置一下,可以理解为在"组网" (新增)
import torch
import torch.distributed as dist
dist.init_process_group(
backend = "nccl", # 使用NCCL通信
rank = xx, # 这张卡的标识
world_size = xx # 所有卡的数量
)
torch.cuda.set_device(rank) # 绑定这个进程的GPU
# 然后是模型定义(变化)
model = Model(xx).cuda(rank)
model_ddp = nn.parallel.DistributedDataParallel(mode, device_ids=[rank]) # 相较于DP,这里用DDP来包装模型
# 优化器(没变)
optimizer = Optimizer(xx)
# 分布式数据加载(新增)
train_sampler = torch.utils.data.distributed.DsitributedSampler(
dataset,
num_replicas = world_size,
rank = rank
)
dataloader = DataLoader(
dataset,
batch_size = per_gpu_batch_size,
sampler = train_sampler
)
# 训练(不变)
output = model_ddp(input)
loss = loss_function(output, target)
loss.backward()
optimizer.step()
# 训练后结束"组网"
dist.destroy_process_group()
# 使用torchrun启动DDP
torchrun train.py # torchrun是pytorch官方DDP的最佳实践,就别用其他的了FSDP
不论是DP还是DDP的数据并行,都有一个核心问题:模型在每个GPU上都存储一份,如果模型特别大,单卡显存不足的话就无法训练。
这就引入了 FSDP(fully sharded data parallel)核心思想是:把模型的参数、梯度、优化器状态 分片存储,显著降低显存占用。
分片机制:
- 参数分片:把模型的参数切分到所有GPU上,每个GPU仅存储部分参数
- 前向传播:通过
AllGather收集完整参数 -> 计算 -> 丢弃 非本地分片(不在显存中存储,仅仅是计算用) - 反向传播:通过
AllGather收集参数 -> 计算梯度 -> 再通过reduce-scatter同步梯度分片 - 优化器状态:每个GPU仅维护与其参数分片对应的优化器状态
但这时候就会有疑问了:把模型分片存储,这还算DP吗,这不成了MP么?
确实,FSDP融合DP和MP两种思想,但核心仍然是DP,因为它仍然是在 数据维度 进行并行(不同GPU处理不同数据),并且每个GPU都独立的完整前向+反向传播;这是用DP的思想,去解决DP单卡显存瓶颈的问题。
"FSDP is DP with model sharding, not MP. It extends DP beyond single-device memory limits."
------ PyTorch Distributed Team, Meta AI
下面展示FSDP的FULLY_SHARD策略,也就是对标ZeRO-3的训练流程:
- 通过
FULLY_SHARD策略,将参数、梯度、优化器状态进行了分片

- 在
前向传播中,由于每个GPU都只有部分参数,所以当走到缺失那部分参数的时候,依赖其他GPU将参数传进来,执行完毕后就丢弃;通过这种方式,使得即使每个GPU只保存部分参数,但依然可以完成整个前向传播

- 当得到output开始计算
梯度时,每个GPU完整自己那部分的梯度计算,在此过程中如果本地没有相对应的参数,也依然需要从其他GPU传过来;当完成梯度计算后,再把梯度发送给负责更新这部分参数的优化器分片的GPU,由它进行本地参数更新;这样就完成了一次前向+反向传播

再来看看FSDP的PyTorch伪代码:
python
# "组网",也就是设置分布式环境方式和DDP没有区别(不变)
import torch.distributed as dist
from torch.distrbuted.fsdp import FullyShardDataParallel as FSDP
def setup(rank, world_size):
dis.init_process_group("nccl", rank=rank, world_size=world_size)
torch.cuda.set_device(rank)
# 使用FSDP包装模型,同时设置分片策略(新增)
from torch.distributed.fsdp.wrap import size_based_auto_wrap_policy
model = Model(xx)
model_fsdp = FSDP(mode,
auto_wrap_policy=size_based_auto_wrap_policy, # 按层大小自动分片
mixed_precision=True, # 启用混合精度
device_id=rank,
sharding_strategy=torch.distributed.ShardingStrategy.FULLY_SHARD # 相当于ZeRO-3
)
# 数据加载和分布式采样,和DDP没有区别(不变)
from torch.utils.data.distributed import DistributedSampler
dataset = datasets(xx)
sampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank)
dataloader == torch.utils.data.DataLoader(datase4t, batch_size=64, sampler=sampler)
# 训练和DP、DDP没有区别(不变)
for epoch in range(epochs):
sampler.set_epoch(epoch)
for batch in dataloader:
data, target = batck[0].to(rank), batch[1].to(rank) # H2D
optimizer.zero_grad()
output = model_fsdp(mode) # 使用fsdp包装的model进行前向传播
loss = loss(output, target)
loss.backward()
optimizer.step()ZeRO1/2/3
ZeRO 是微软家 DeepSpeed 中的核心技术,思想和 FSDP 是相同,二者都是 通过分片消除模型冗余存储,扩大分布式并行训练能力 ,只不过 FSDP 是 PyTorch 的官方实现版。
ZeRO(Zero Redundancy Optimizer)有三种策略:
ZeRO-1:只分片 优化器状态ZeRO-2:分片 梯度 和 优化器状态 ,对应了FSDP的SHARD_GRAD_OP策略ZeRO-3:分片 参数 、梯度 和 优化器状态 ,对应了FSDP的FULLY_SHARD策略
虽然 ZeRO 因为深度集成在 DeepSpeed 中,还可以利用上 DeepSpeed 的其他特性,但从生态偏好上讲,个人更推荐使用 PyTorch官方的 FSDP。