目录
[2.OLAP 优化](#2.OLAP 优化)
[4.SQL 优先接口](#4.SQL 优先接口)
[1. SchemaonRead结构](#1. SchemaonRead结构)
[2. 多模态数据支持](#2. 多模态数据支持)
[3. 低成本存储](#3. 低成本存储)
[4. 计算存储解耦](#4. 计算存储解耦)
[1. 事务层](#1. 事务层)
[2. 统一元数据](#2. 统一元数据)
[3. 多引擎支持](#3. 多引擎支持)
[1. 存储成本减少](#1. 存储成本减少)
[2. 实时分析的工程简化](#2. 实时分析的工程简化)
[3. AI与BI的管道融合](#3. AI与BI的管道融合)
[4. 云原生生态的成熟](#4. 云原生生态的成熟)
[1. 存储层统一](#1. 存储层统一)
[2. 元数据治理先行](#2. 元数据治理先行)
[3. 计算引擎升级](#3. 计算引擎升级)
[4. 渐进式架构演进](#4. 渐进式架构演进)
从数据仓库的严谨高效,到数据湖的开放灵活,再到如今融合创新的湖仓一体(Lakehouse),这一演进充分体现了企业对数据价值密度提升的迫切需求。数据仓库擅长处理结构化数据,查询快、质量高,数据湖能低成本存储任何原始数据,而湖仓一体既能低成本存储海量原始数据,又能高效挖掘数据价值。
但并不是所有的企业都要湖仓一体,根据每个企业的数据量、使用方法等选择适合业务需求的才是最好的。今天这篇文章就带你深入解析它们的技术原理与落地路径,让你明白数据仓库、数据湖、湖仓一体是如何让数据从"存得下"转向"用得好"。
一、数据仓库
数据仓库(Data Warehouse)是面向主题的、集成的、非易失的、随时间变化的数据集合,用于支持管理决策。其概念可追溯到上世纪80年代,随着企业数据量增长和决策需求的提升而逐渐发展起来。其核心特征包括:
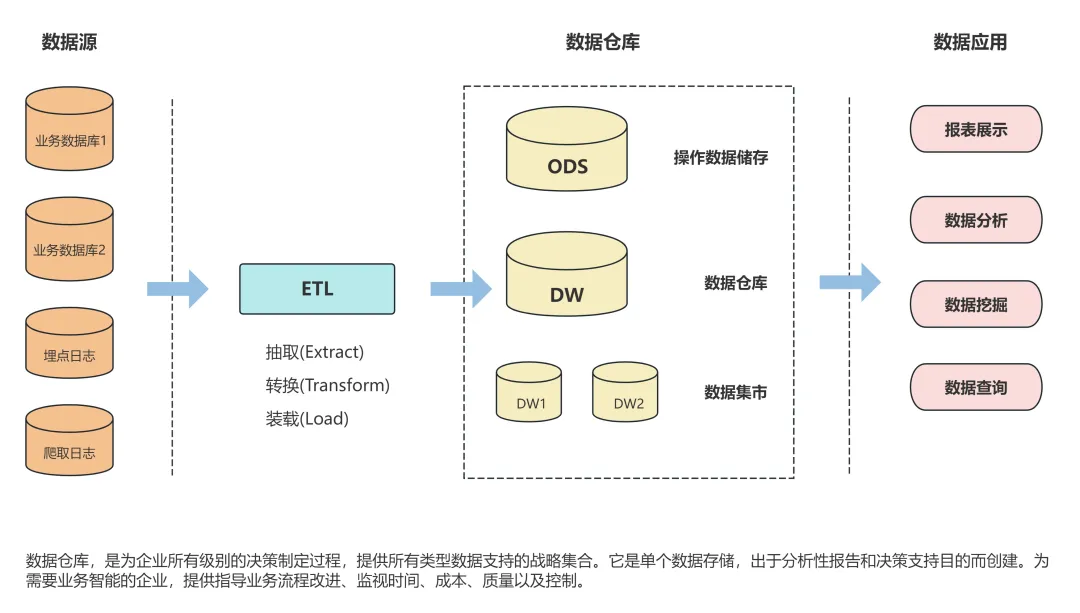
1.结构化数据为主
具有强 Schema 约束,数据在加载前必须经过清洗、转换等 ETL 过程。这意味着数据在进入数据仓库之前,需要按照既定的结构和规则进行整理,以确保数据的一致性和准确性。
2.OLAP 优化
采用列式存储,这种存储方式对于特定查询,尤其是涉及大量数据的聚合查询,能够显著提高效率。同时,通过预聚合技术,提前对数据进行汇总计算,减少查询时的计算量。在数据模型方面,多采用星型或雪花模型,以优化数据的存储和查询性能。
3.强一致性保障
许多数据仓库系统支持 ACID 事务,如 Teradata、Snowflake 等,避免数据错误和不一致性对决策产生影响。推荐业内IT人员都在用的数仓搭建辅助平台FineDataLink,支持ETL/ELT两种开发方式,像是关系型数据库、NoSQL、API接口等多种数据源,都能用它来处理。对口径不统一或者质量低的数据,可以用FineDataLink来定时抽取并转化,完成对数据的快速处理工作,保障数据的一致性和完整性。
4.SQL 优先接口
通过 SQL 进行复杂分析查询,由于数据仓库基于关系模型,SQL 语言能够很好地与之适配,相关人员可运用熟悉的查询语句,快速检索、统计、分析数据及生成各类报表。
二、数据湖
数据湖(Data Lake)是以原生格式存储任意规模原始数据的存储库,在大数据时代得到广泛关注和应用。其核心特征包括:
1. SchemaonRead结构
写入时无强Schema约束,数据可以以原始的格式直接存入数据湖,在读取数据时再定义结构。这种方式最大限度地保留了数据的原始性和灵活性,适用于数据格式不确定或需要进行探索性分析的场景。
2. 多模态数据支持
能够存储结构化、半结构化(如JSON、XML)、非结构化(如文本、图像)等多种类型的数据,使企业可以将各种来源、各种格式的数据集中存储,为后续的综合分析提供可能。
3. 低成本存储
通常基于HDFS或对象存储(如S3、ADLS),这些存储方式具有高扩展性和低成本的优势。企业可以根据数据量的增长,灵活扩展存储容量,而无需担心高昂的存储成本。
4. 计算存储解耦
可以使用Spark、Presto等计算引擎独立进行伸缩。不同的计算引擎可以根据数据处理的需求进行选择和配置,提高了计算资源的利用效率。
三、数据仓库与数据湖的核心痛点
尽管数据仓库和数据湖各自具有独特的优势,但它们也存在一些局限性,这些局限性在实际应用中逐渐显现出来。

1.数据仓库的局限性
(1)扩展成本高:数据仓库的扩展通常需要增加硬件资源或购买更多的许可证,这导致扩展成本较高。
(2)半结构化支持弱:数据仓库主要处理结构化数据,对半结构化和非结构化数据的支持能力较弱,难以满足企业对多种类型数据的处理需求。
2.数据湖的局限性
(1)数据治理难:数据湖的灵活性虽然带来了便利,但也导致数据治理难度增加。当缺乏有效的元数据管理时,数据湖难以检索和理解。据2024年Anaconda的调研显示,67%的企业在数据湖项目中遭遇了数据治理挑战。
(2)分析性能受限:数据湖的存储方式虽然适合存储大量原始数据,但在进行复杂分析查询时,其性能可能不如数据仓库。例如,数据湖在处理大规模数据时可能会出现查询延迟较高的问题,影响数据分析的效率。
四、湖仓一体是什么
湖仓一体(Lakehouse)是在开放存储格式(Delta Lake/Iceberg/Hudi)基础上,融合数据仓库管理能力与数据湖灵活性的新架构。这一技术实现了以下三重突破:
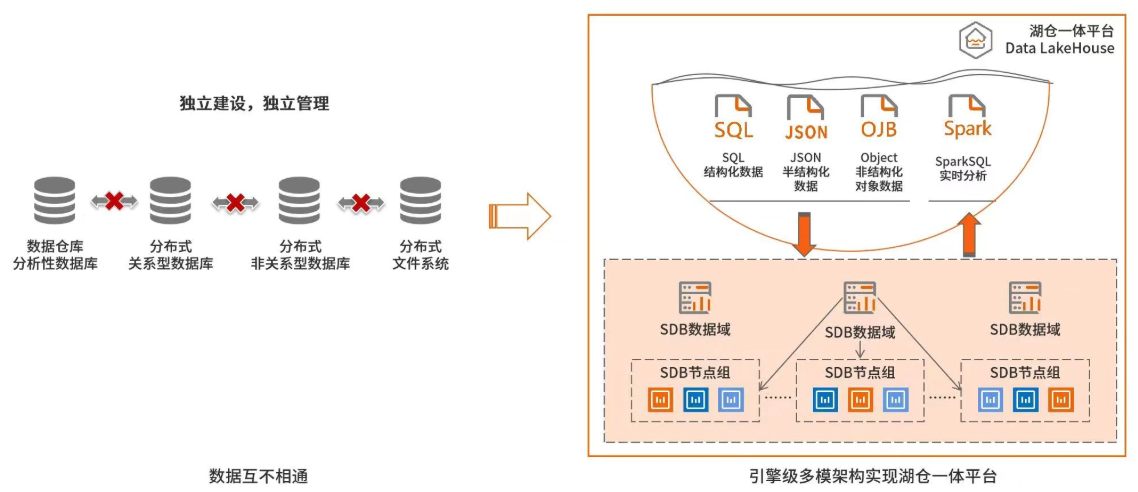
1. 事务层
通过Delta Lake等框架实现ACID事务,解决数据湖的脏读问题。例如在数据写入时,Delta Lake可以保证原子性,即要么整个写入操作成功,要么全部失败,不会出现部分数据写入成功而导致数据不一致的情况。

2. 统一元数据
如Apache Iceberg的隐藏分区、模式演化,实现无痛数据结构变更。统一元数据管理能够提供全局的数据目录,无论数据存储在何处,使用何种计算引擎,用户都能通过统一的API进行快速检索、理解与访问数据。
3. 多引擎支持
同一份数据支持SQL查询、流处理、机器学习。例如,FineBI、PowerBI等BI工具可以直接查询湖仓中的数据,生成可视化报表;Flink、Spark Structured Streaming等流计算框架能够对实时流入的数据进行实时处理;PyTorch、TensorFlow等ML框架可以直接对接湖仓中的数据进行模型训练。
五、湖仓一体的优势
湖仓一体架构的出现,是大数据架构演进的必然结果。它不仅解决了数据仓库和数据湖的局限性,还带来了以下多重优势:
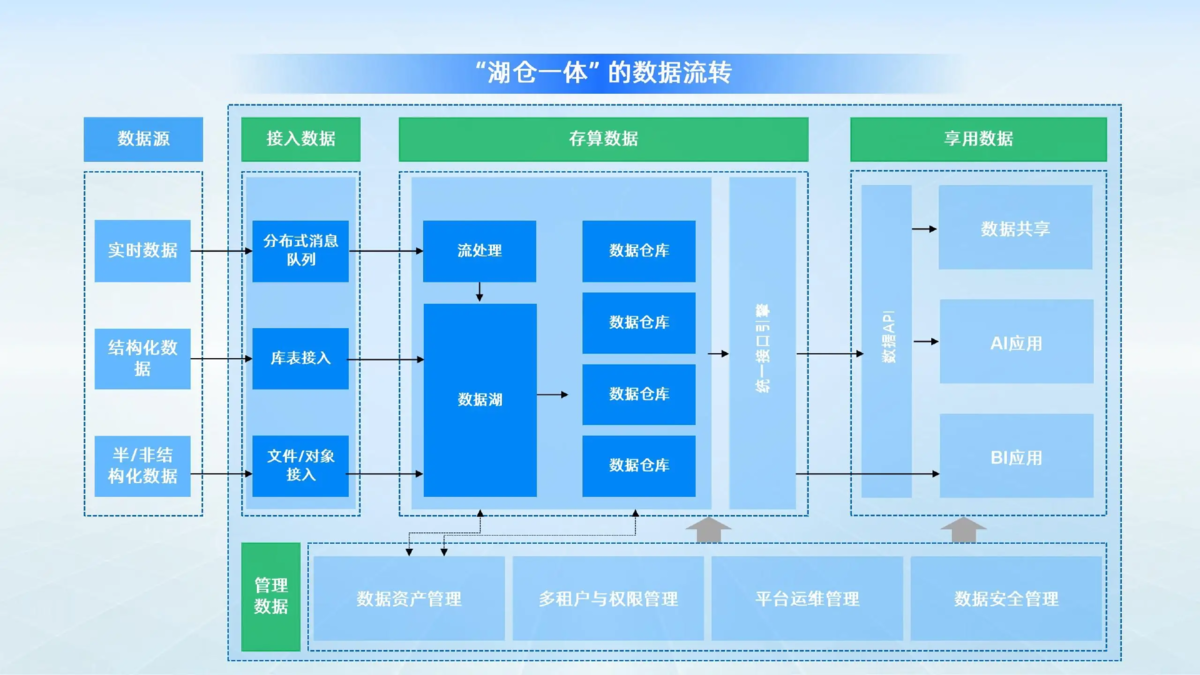
1. 存储成本减少
对比传统数仓,存算分离架构使存储成本大大下降,计算资源弹性伸缩。企业可以根据数据存储和计算的实际需求,灵活调整存储和计算资源,避免资源浪费,降低总体成本。
2. 实时分析的工程简化
消除Lambda架构复杂度,实现流批一体处理。在传统的Lambda架构中,需要分别构建实时处理和离线处理两套系统,而湖仓一体架构可以将原始数据直接进行实时流处理,处理后的数据存储在统一的存储层,既可以用于实时看板的展示,也可以进行离线分析,简化了工程实现。
3. AI与BI的管道融合
特征工程与报表开发共享数据底座,缩短数据价值链条。在湖仓一体架构下,可以利用数据湖中的原始数据进行特征工程,为AI模型训练提供数据支持;同时,可以使用相同的数据进行报表开发,为企业的业务决策提供支持,实现了数据的高效利用。
4. 云原生生态的成熟
三大云厂商均推出了相关解决方案:
(1)AWS:Redshift Spectrum + S3 + Glue,其中S3提供存储,Glue进行元数据管理,Redshift Spectrum用于查询分析。
(2)Azure:Synapse Analytics + ADLS,ADLS作为存储,Synapse Analytics整合了数据集成、数据 warehousing和大数据分析功能。
(3)GCP:BigLake + BigQuery,BigLake提供统一的存储和元数据管理,BigQuery进行数据分析。
六、如何向湖仓一体进行迁移
对于企业来说,向湖仓一体架构迁移是一个逐步推进的过程。以下是一些实践建议:
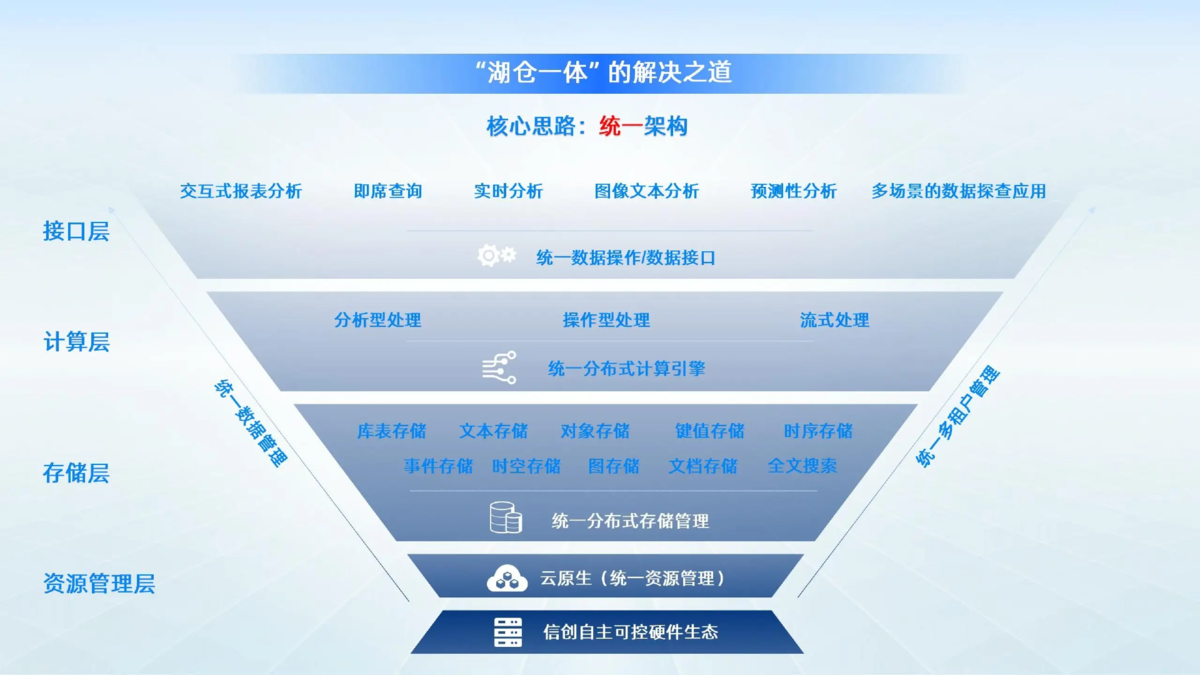
1. 存储层统一
将历史数仓数据卸载到对象存储,转换为Delta/Iceberg格式。对象存储具有低成本、高扩展性的优势,而Delta/Iceberg格式能够支持事务和数据管理功能,为湖仓一体架构奠定基础。
2. 元数据治理先行
建立统一数据目录,如AWS Glue Data Catalog。通过统一的数据目录,对数据进行分类、描述和管理,方便数据的查找和使用,提高数据的可发现性和可理解性。
3. 计算引擎升级
采用支持湖仓的引擎,如Spark 3.x + Photon, Trino。这些引擎能够更好地与湖仓一体架构协同工作,发挥其性能优势,满足不同类型的数据处理需求。
4. 渐进式架构演进
从传统数据仓库开始,先通过数仓连接外部表查询数据湖中的数据,逐渐过渡到以数据湖为主导,数据仓库作为加速层,最终实现统一的湖仓平台。

结语
最好的架构不是技术最超前的架构,而是能最大化数据流动效率的架构。
当数据规模突破PB级时,架构选择直接决定企业数据能力的天花板。**但并不是所有的企业都要湖仓一体,因为每个企业都有自己的数据特性,数据量、使用方法等方面都存在差异。**湖仓一体不是终极答案,而是当前技术条件下,实现成本、效率、灵活性三角平衡的一种解法。
企业在选择架构时,应结合自身实际需求进行评估,以实现数据的最大化流动效率,推动企业数据能力的持续提升。