文章来源:微信公众号 萤火AI百宝箱
一次显存爆炸的血泪教训,换来的参数调优秘籍
前言
上周,团队准备用DeepSeek 32B 模型做微调,结果第一次训练就遇到了显存爆炸。各种 OOM 错误让人抓狂。
经过摸索和实践,终于摸清了 LLaMA Factory 参数配置的门道。今天把这些经验分享出来,希望能帮大家避开我踩过的坑。
LLaMA Factory 参数体系全景
LLaMA Factory 有 400+ 个配置参数,看起来很复杂,但其实可以分为三个层次:
核心层(必须配置) :决定能否跑起来
优化层(影响性能) :决定跑得好不好
高级层(锦上添花) :决定跑得有多快
按照重要性排序,核心参数只有 20 个左右,掌握这些就能应对 80% 的场景。
核心参数:决定成败的关键
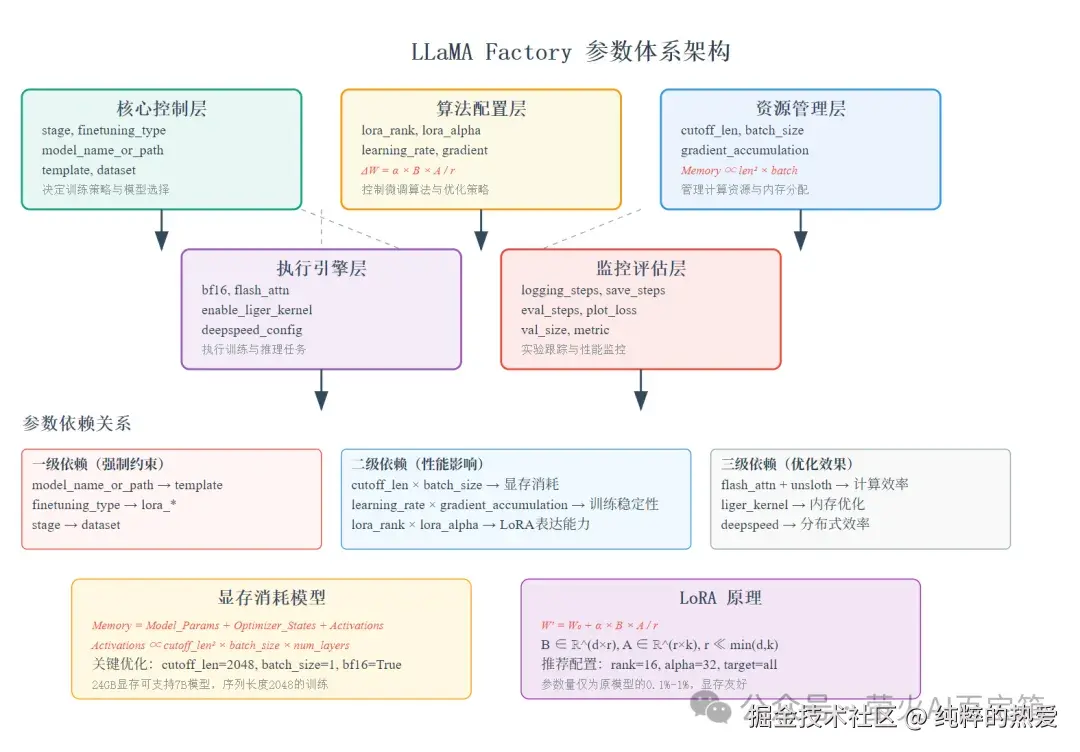
核心参数:决定成败的关键
1. 基础配置三件套
bash
# 模型和微调方法
model_name_or_path: /models/Qwen2.5-7B-Instruct
stage: sft # 监督微调
finetuning_type: lora # LoRA 方法
template: qwen # 对话模板这四个参数决定了你要训练什么模型、用什么方法训练。其中 finetuning_type: lora 是显存受限情况下的唯一选择。
2. 显存管理:生死存亡的战场
显存消耗的核心公式:
Memory ∝ cutoff_len² × batch_size × model_params
三个关键参数的调优策略:
序列长度(cutoff_len)
yaml
cutoff_len: 2048 # 基础配置,适合对话任务
cutoff_len: 4096 # 需要 4倍显存,适合长文本
cutoff_len: 8192 # 需要 16倍显存,慎用建议先用 1024 测试,确保能跑起来后再逐步增加。
批量大小组合
bash
per_device_train_batch_size: 1 # 单设备批量
gradient_accumulation_steps: 8 # 梯度累积
# 实际批量 = 1 × 8 = 8这是显存优化的黄金配置:用时间换空间,通过梯度累积实现大批量训练效果。
3. LoRA 参数:小而美的艺术
LoRA 的核心思想是用低秩矩阵近似权重更新:
ΔW = α × B × A / r
其中:
- • r (lora_rank) :决定表达能力
- • α (lora_alpha) :决定学习强度
- • B, A:可训练的低秩矩阵
python
lora_rank: 16 # 平衡性能和资源
lora_alpha: 32 # 通常设为 rank 的 2倍
lora_target: all # 应用到所有线性层
lora_dropout: 0.05 # 防过拟合rank 选择指南:
- • 简单任务(对话、翻译):rank=8-16
- • 复杂任务(推理、代码):rank=32-64
- • 专业领域:rank=64-128
优化参数:性能提升的秘密武器
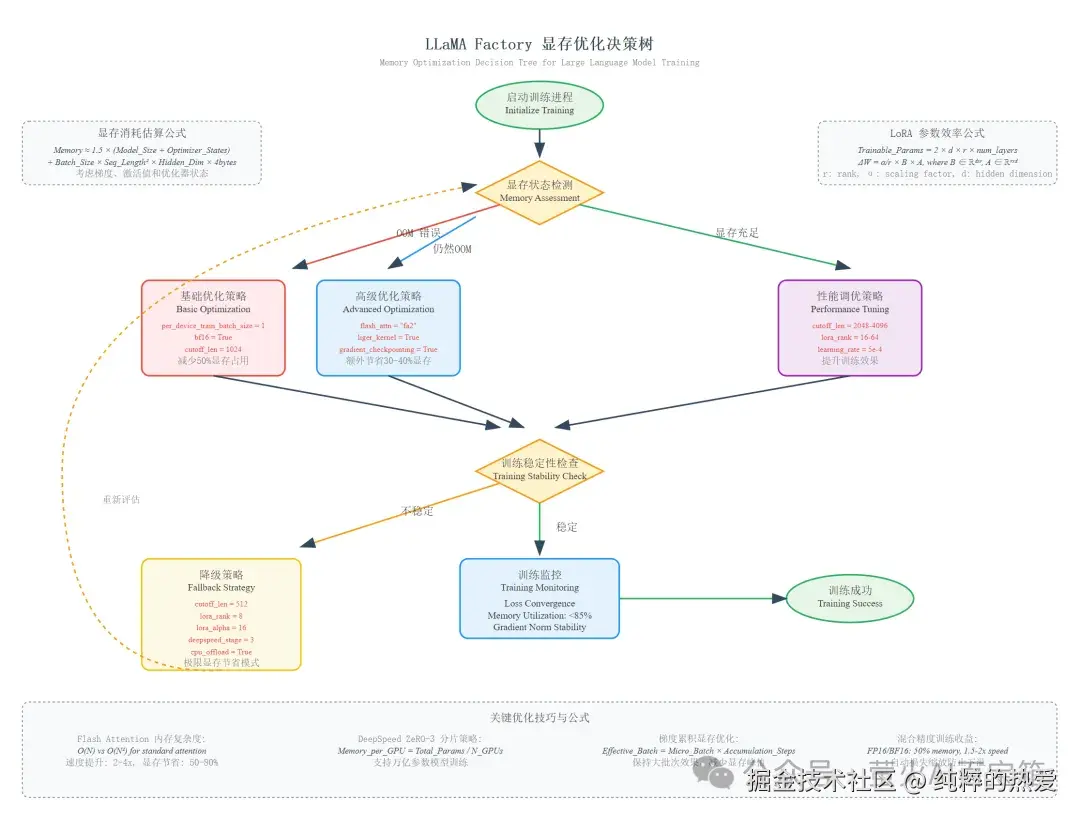
优化参数:性能提升的秘密武器
1. 学习率调度:训练稳定的基石
bash
learning_rate: 5e-05 # LoRA 的黄金学习率
lr_scheduler_type: cosine # 余弦退火,收敛更平滑
warmup_steps: 100 # 预热防止梯度爆炸
max_grad_norm: 1.0 # 梯度裁剪学习率是最敏感的参数。过高会导致训练崩溃,过低会收敛缓慢。5e-05 是经过大量实验验证的 LoRA 最佳起点。
2. 数据处理:细节决定成败
yaml
cutoff_len: 4096 # 根据数据分布确定
train_on_prompt: false # 只在回答部分计算损失
mask_history: true # 多轮对话时屏蔽历史
packing: false # 对话任务不建议打包train_on_prompt: false 很重要,它确保模型只学习如何生成回答,而不是记忆问题。
加速优化:让训练飞起来
现代深度学习有三大加速神器,一定要开启:
bash
bf16: true # 混合精度训练
flash_attn: fa2 # FlashAttention-2
enable_liger_kernel: true # Liger 内核优化性能提升效果:
- • bf16:显存减半,速度提升 30%
- • FlashAttention-2:显存节省 50-80%,速度提升 150-300%
- • Liger Kernel:显存节省 20-40%,速度提升 10-30%
三者叠加使用,在 7B 模型上实测可以节省 60% 显存,提升 200% 训练速度。
实战DeepSeek 32B 微调
让我们得以将理论配置与实践结果相结合,深入理解一个生产级别的 32B 大模型 LoRA 微调任务的全过程。本复盘将作为一份详尽的技术参考,揭示其成功的关键所在。
基础环境:
- • DCU加速卡:K100-AI 8卡
- • Python: 3.10.12
- • LlamaFactory:0.9.2
LlamaFactory 微调DeepSeek 32B 的训练参数
scss
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path deepseek-ai/DeepSeek-R1-Distill-Qwen-32B \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template deepseek3 \
--flash_attn auto \
--dataset_dir data \
--dataset alpaca_zh_demo \
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 5.0 \
--max_samples 1000 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 32 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 1 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to none \
--output_dir saves/DeepSeek-R1-32B-Distill/lora/train_2025-06-20-14-28-39 \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--lora_rank 16 \
--lora_alpha 32 \
--lora_dropout 0 \
--lora_target all \
--deepspeed cache/ds_z3_config.json🚀 海光DCU实战项目来了!助您轻松驾驭大模型与HPC开发 🚀
为帮助开发者更便捷在海光DCU上进行大模型(训练、微调、推理)及科学计算,我依托海光DCU开发者社区 ,精心打造了一个开箱即用的实战项目 ------ "dcu-in-action" !
旨在为您提供:
- • 🔧 直接上手的代码示例与实践指南
- • ⚡ 加速您在海光DCU上的开发与部署流程
欢迎各位开发者:
- • 访问项目GitHub仓库,深入体验、参与贡献,共同完善: github.com/FlyAIBox/dc...
- • 如果项目对您有帮助,请我们点亮一个宝贵的 Star 🌟
首先,我们回顾一下本次任务的核心战略配置。
| 类别 | 关键参数 | 设定值 | 战略意义 |
|---|---|---|---|
| 基础框架 | model_name |
DeepSeek-R1-32B-Distill |
选用一个强大的 32B 级别模型作为基础。 |
finetuning_type |
lora |
采用 LoRA 微调,在效果与资源间取得最佳平衡。 | |
| 资源与精度 | compute_type |
bf16 |
使用 bfloat16 混合精度,将显存占用减半。 |
ds_stage |
3 |
核心技术:启用 DeepSpeed ZeRO Stage 3,将模型、梯度、优化器全部分片,突破单卡显存瓶颈。 | |
| 训练稳定性 | learning_rate |
5e-5 |
采用 LoRA 的黄金学习率。 |
lr_scheduler_type |
cosine |
使用余弦调度器,平滑学习率,稳定收敛。 | |
batch_size |
1 |
显存控制:单卡批处理设为 1,最大限度降低激活值显存。 | |
gradient_accumulation_steps |
32 |
稳定保障 :与 batch_size=1 配合,实现大批量训练效果。 |
|
| LoRA 配置 | lora_rank |
16 |
均衡的秩大小,兼顾学习容量与资源消耗。 |
lora_alpha |
32 |
遵循 alpha = 2 * rank 的最佳实践。 |
战略总结 : 整个配置的核心思想非常明确------以 DeepSpeed Stage 3 为基石,通过 LoRA 对 32B 大模型进行高效、轻量的监督微调,同时运用 BF16、小批量和梯度累积等手段,将资源消耗控制在可用范围之内。
训练日志为我们提供了静态配置在实际执行中的有力证据。
阶段一:初始化与环境确认 (15:34:01 - 15:34:48)
- • DeepSpeed 激活 : 日志明确显示
[INFO] Detected DeepSpeed ZeRO-3: activating zero.init() for this model。这证实了 ZeRO-3 是本次微调得以运行的底层技术支撑。 - • LoRA 效率验证 : 日志计算出
trainable params: 134,217,728 || all params: 32,898,094,080 || trainable%: 0.4080。这具体地量化了 LoRA 的高效性:我们仅用约 0.4% 的可训练参数,就实现了对 329 亿参数模型的有效微调。 - • 梯度检查点启用 : 日志显示
[INFO] Gradient checkpointing enabled。这证实了默认启用的梯度检查点技术,这是另一项重要的"时间换空间"的显存优化策略。
阶段二:训练执行与收敛分析 (15:34:53 - 16:25:36)
-
• 分布式规模确认 : 日志显示
Instantaneous batch size per device = 1、Gradient Accumulation steps = 32和Total train batch size (w. parallel, distributed & accumulation) = 256。我们可以由此推断出本次训练使用的 GPU 数量为256 / (1 * 32) = 8卡。 -
• 训练步数分析 : 日志显示
Total optimization steps = 15。这表明整个训练过程共进行了 15 次参数更新。 -
• 关键成功标志------Loss 稳定下降: 这是证明配置有效的最直接证据
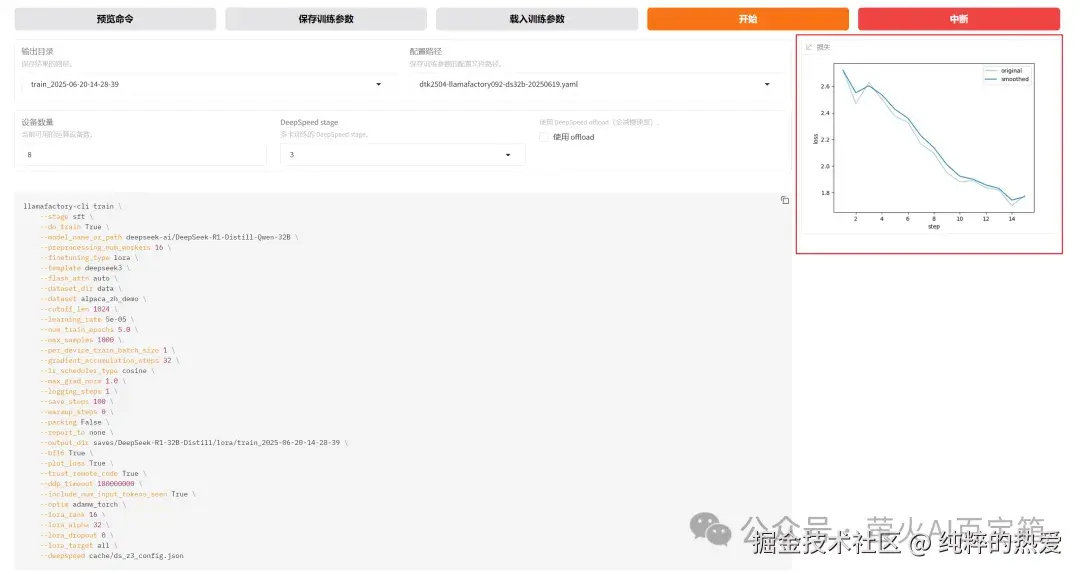
null Loss 稳定下降: 这是证明配置有效的最直接证据
。日志清晰地记录了损失函数的变化:
-
- • 初始
loss:2.7224(at epoch 0.26) - • 中间
loss:2.1653(at epoch 1.79) - • 最终
loss:1.7814(at epoch 3.84) 这个平滑且显著的下降曲线,无可辩驳地证明了**当前参数组合(学习率、批量大小、优化器等)是正确且高效的,**模型正在稳定地学习和收敛。
- • 初始
-
• 学习率调度验证 : 日志中
learning_rate从4.9454e-05平滑地衰减至0.0000e+00,完美符合cosine调度器的预期行为。
阶段三:收尾与最终状态 (16:26:07 - 16:27:06)
- • 训练完成 : 日志显示
Training completed.,并成功保存了最终的模型检查点 (checkpoint-15)。 - • 验证集缺失确认 : 日志警告
No metric eval_loss to plot。这与配置文件中val_size: 0的设定完全一致,表明本次运行并未设置验证集,属预期行为。
DCU系列
DCU基本介绍DCU大模型微调
DCU大模型推理
为什么这次微调是成功的?
此次微调的成功,并非依赖于某个单一的"神奇参数",而是一套完整且自洽的系统性工程的胜利。日志为我们揭示了这套工程在实践中是如何协同工作的:
-
- 战略层面 :
LoRA+DeepSpeed Stage 3的组合拳,从根本上解决了"不可能三角"------在有限资源下微调巨大模型。
- 战略层面 :
-
- 战术层面 :
BF16精度、batch_size=1的极端设置、gradient_accumulation的补偿、以及稳健的cosine学习率策略,共同保证了这台庞大的"机器"能够稳定、高效地运转。
- 战术层面 :
-
- 结果层面 : 持续下降的
loss曲线是对上述所有策略有效性的最终裁定。
- 结果层面 : 持续下降的
生产启示:
这份经过日志验证的配置,是一份极佳的多卡环境 LoRA 微调模板。它告诉我们,面对大模型微调的挑战,思路应是:
-
- 用分布式策略(DeepSpeed)解决基础容量问题。
-
- 用参数高效方法(LoRA)降低训练复杂度。
-
- 用显存优化技术(量化、梯度累积等)在可用资源内腾挪空间。
-
- 用成熟的训练策略(学习率、调度器)保证过程稳定。
唯一的补充建议是,在正式的生产任务中,应设置验证集 (val_size > 0) 。这能帮助我们监控过拟合,并找到模型在验证集上表现最佳的那个 checkpoint,从而实现真正的"生产就绪"。
踩坑经验总结
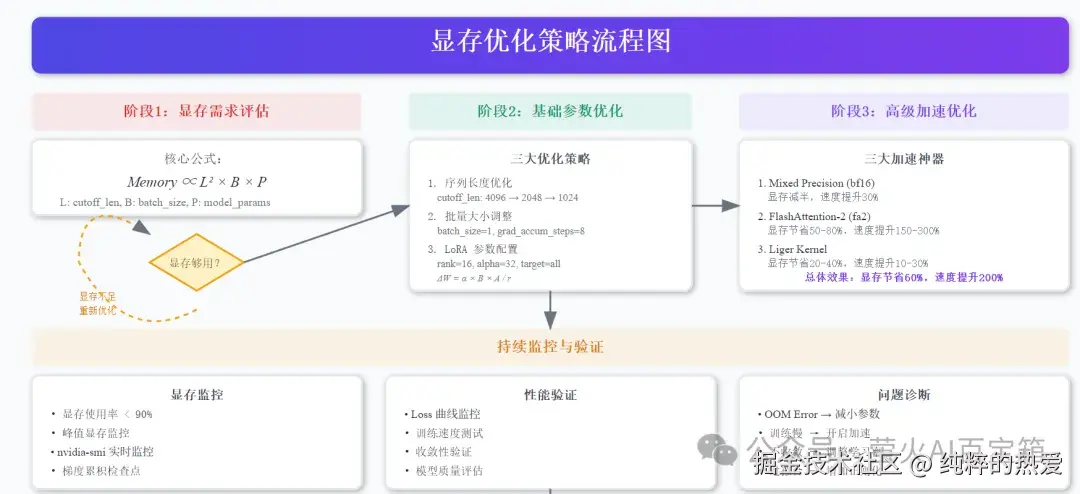
踩坑经验总结
常见错误 1:显存不够
症状 :CUDA out of memory
解决:
-
- 减小
cutoff_len(优先)
- 减小
-
- 设置
per_device_train_batch_size: 1
- 设置
-
- 开启
bf16: true
- 开启
常见错误 2:训练不收敛
症状 :Loss 不下降或震荡
解决:
-
- 降低学习率至
1e-05
- 降低学习率至
-
- 增加
warmup_steps
- 增加
-
- 检查数据质量
常见错误 3:过拟合
症状 :训练 Loss 下降但验证 Loss 上升
解决:
-
- 增加
lora_dropout: 0.1
- 增加
-
- 减少训练轮数
-
- 增加数据量
调优方法论
基于大量实验,总结出一套科学的调优流程:
第一步:最小可行配置
- • 用最保守的参数确保能跑起来
- • cutoff_len=1024, batch_size=1, rank=8
第二步:数据适配
- • 分析数据长度分布,调整 cutoff_len
- • 一般设为 90% 分位数长度
第三步:性能优化
- • 逐步增加 rank 和 batch_size
- • 监控显存使用率,控制在 90% 以下
第四步:超参数精调
- • 基于 Loss 曲线调整学习率
- • 使用验证集防止过拟合
结语
LLaMA Factory 参数配置看似复杂,但掌握核心原理后就能举一反三。记住几个要点:
-
- 显存是瓶颈:所有优化都围绕显存展开
-
- LoRA 是王道:在资源受限情况下的最佳选择
-
- 监控是关键:Loss 曲线比任何理论都重要
-
- 实验出真知:每个数据集都有自己的特点
希望这篇文章能帮你少走弯路,快速上手 LLaMA Factory。如果有问题欢迎在评论区讨论,我会尽量回复。