
一、情感分析的革命:从传统机器学习到大语言模型的跨越
在当今数字化时代,情感分析作为自然语言处理(NLP)的核心任务,已成为商业决策的关键支撑。无论是电商平台分析用户评价、品牌监测社交媒体舆情,还是服务行业收集客户反馈,精准的情感分析都能为企业提供宝贵的洞察。然而,传统的情感分析方法往往依赖复杂的机器学习流程,不仅需要大量标注数据,还需进行繁琐的特征工程和模型调参。
随着大语言模型(LLM)的崛起,一种全新的情感分析方式应运而生------无需任何机器学习训练,仅通过提示工程或语义向量计算,就能实现高精度的情感分析。本文将全面解析这一革命性方法,通过详细的案例、关键代码和直观图表,带您掌握大语言模型在情感分析中的应用,助力您在实际业务中快速落地。
二、传统情感分析方法的困境与局限
2.1 朴素贝叶斯:基于概率的传统思路
传统的情感分析常将其视为二分类问题,其中朴素贝叶斯算法是常用的方法之一。其核心原理是基于词语的条件概率来判断文本的情感倾向。
朴素贝叶斯计算公式示例:
python
# 基于词语条件概率的朴素贝叶斯公式
P(垃圾邮件|X) ∝ P(buy|垃圾) × P(money|垃圾) × P(sell|垃圾) × P(垃圾)
= 1 × 1 × 0.5 × 0.5 = 0.25
如上图所示,朴素贝叶斯通过计算文本中各个词语在不同情感类别下的概率乘积,来推断文本的情感倾向。这种方法在简单场景下或许能发挥一定作用,但在面对复杂语义时却显得力不从心。
朴素贝叶斯算法局限性:
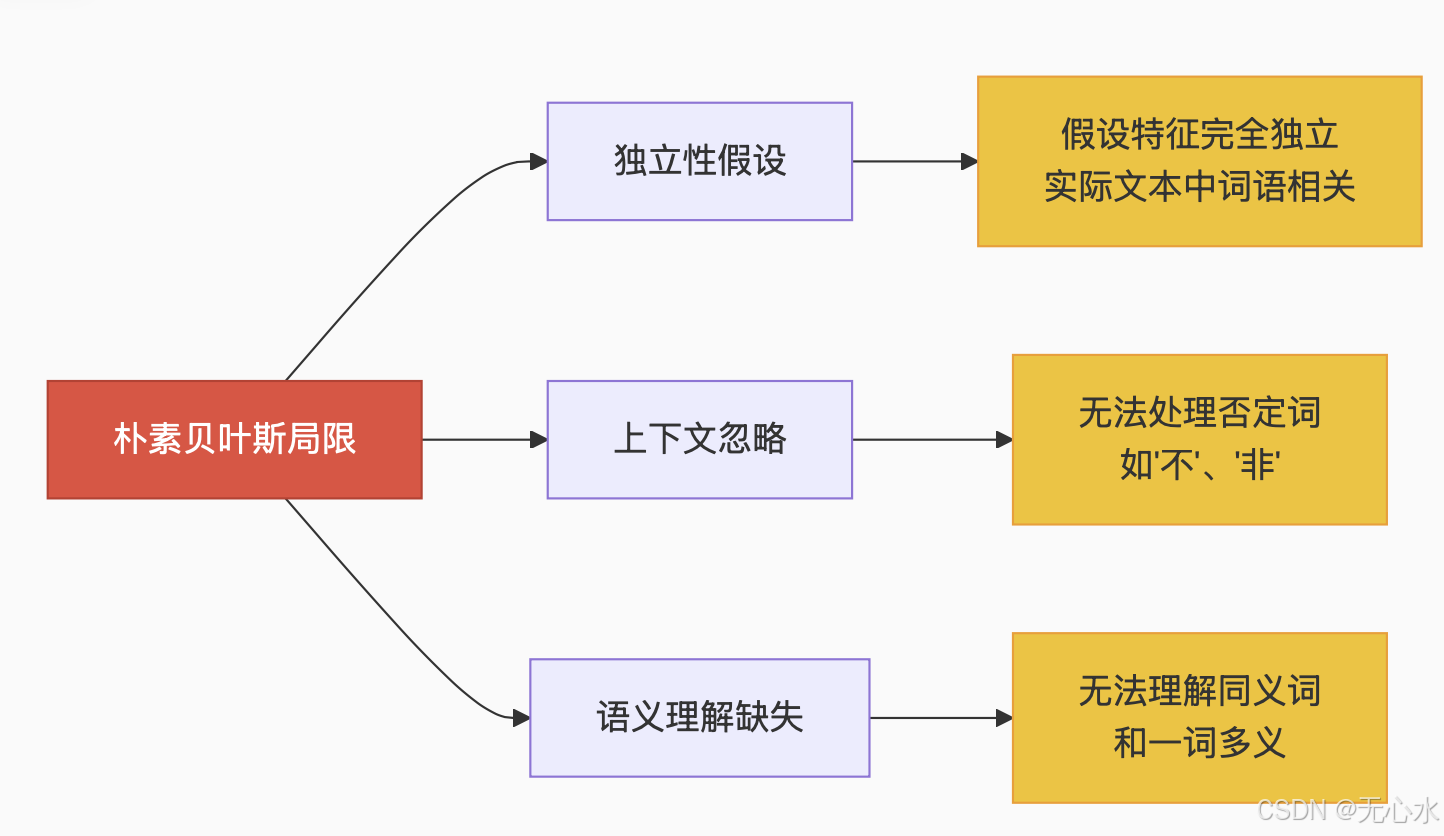
2.2 传统方法的致命缺陷
传统方法在处理语义复杂或语义相反的相似语句时,往往束手无策。例如:
text
"这家餐馆太糟糕了,一点都不好吃" # 差评
"这家餐馆太好吃了,一点都不糟糕" # 好评这两句话用词高度相似,仅通过词语的概率计算难以准确区分其情感倾向。为解决此类问题,工程师不得不进行一系列复杂的操作:
- 设计N-Gram特征(如Bigram"太糟糕"vs"太好吃")
- 进行停用词过滤、词形还原、TF-IDF加权
- 划分训练集/验证集/测试集
- 调整超参数、处理样本不均衡
这些步骤不仅延长了开发周期,增加了成本,而且在面对不断变化的语言环境和复杂语义时,效果仍难以保证。
三、大语言模型情感分析的核心方案
大语言模型的出现彻底改变了情感分析的格局。无需任何机器学习训练,仅通过提示工程或语义向量空间计算,就能实现高精度的情感分析。以下将详细介绍这两种核心方案。
3.1 方案一:提示工程(Prompt Engineering)
提示工程是利用大语言模型强大的指令理解、上下文感知和文本生成能力,通过设计合理的提示词来实现情感分析的方法。这种方法无需训练数据,属于零样本或少样本学习。
3.1.1 直接指令法
提示词示例:
python
分析以下文本的情感倾向是积极、消极还是中性。只输出一个词:积极、消极或中性。
文本:"{用户输入的文本}"原理:给模型一个清晰、具体的任务指令,明确要求它判断情感并限制输出格式。
优点:简单直接,易于实现。
缺点:对于复杂、微妙或混合情感可能不够精确;输出格式依赖模型遵循指令的能力。
3.1.2 评分法
提示词示例:
python
请为以下文本的情感强烈程度打分,范围从-5(极度负面)到+5(极度正面),0表示中性。只输出数字。
文本:"{用户输入的文本}"原理:要求模型输出一个数值化的情感分数,提供更细粒度的分析。
优点:结果更量化,可以比较不同文本的情感强度。
缺点:不同模型或不同提示词可能对相同文本给出略有差异的分数;需要处理数值输出。
3.1.3 情感解释法
提示词示例:
python
分析以下文本的情感,并简要解释你的判断理由(1-2句话)。最后用标签标出主要情感倾向:[积极], [消极], [中性]。
文本:"{用户输入的文本}"原理:要求模型不仅给出判断,还给出解释。解释部分可以帮助用户理解模型的推理过程,增加可信度。标签化的输出便于程序提取。
优点:结果更透明,可解释性强;标签化输出便于自动化处理。
缺点:输出结构相对复杂,需要解析文本提取标签或情感词;计算成本稍高。
3.1.4 少样本学习法
提示词示例:
python
请判断以下文本的情感倾向(积极/消极/中性):
示例1:
文本:"这个产品太棒了,完全超出了我的预期!"
情感:积极
示例2:
文本:"服务非常糟糕,等了两个小时也没人理。"
情感:消极
示例3:
文本:"会议定在下周一下午两点。"
情感:中性
现在请判断:
文本:"{用户输入的文本}"
情感:原理:在提示词中提供几个标注好的例子(示例),让模型通过类比学习任务要求。例子应清晰覆盖不同的情感类别。
优点:对于特定领域或复杂情感判断,效果通常比零样本更好;能更好地引导模型理解任务边界。
缺点:需要手动构造或选择好的示例;提示词更长。
3.1.5 直接指令法示例流程(使用OpenAI Python API)
python
import openai
# 1. 设置你的API密钥
openai.api_key = "YOUR_OPENAI_API_KEY"
# 2. 定义要分析的文本
text_to_analyze = "这部电影的剧情令人失望,但特效确实非常震撼。"
# 3. 构建提示词
prompt = f"""分析以下文本的情感倾向是积极、消极还是中性。只输出一个词:积极、消极或中性。
文本:"{text_to_analyze}"
"""
# 4. 调用API (使用GPT-3.5-turbo)
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一个准确的情感分析助手。"}, # 可选系统消息
{"role": "user", "content": prompt}
],
temperature=0.0, # 降低随机性,使输出更确定
max_tokens=10, # 限制输出长度
)
# 5. 解析输出
# 假设模型严格遵守指令,只输出了"积极"、"消极"或"中性"
sentiment = response.choices[0].message.content.strip().lower()
print(f"文本: '{text_to_analyze}'")
print(f"情感倾向: {sentiment}")3.2 方案二:语义向量空间法
大语言模型通过Embedding API将文本映射到高维向量空间,相似语义的文本向量距离更近。利用这一特性,可以通过计算文本向量与正负情感基准向量的相似度来判断情感倾向。
3.2.1 核心原理与代码
python
from openai import OpenAI
import numpy as np
client = OpenAI(api_key="YOUR_KEY")
def get_embedding(text):
return client.embeddings.create(input=[text], model="text-embedding-ada-002").data[0].embedding
# 关键步骤:计算文本与情感基准的向量相似度
def get_score(text_embedding):
pos_vec = get_embedding("好评") # 正面情感基准
neg_vec = get_embedding("差评") # 负面情感基准
# 余弦相似度差值决定情感倾向
return cosine_similarity(text_embedding, pos_vec) - cosine_similarity(text_embedding, neg_vec)
# 余弦相似度计算函数
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
如上图所示,在高维向量空间中,正面情感的文本向量与"好评"基准向量距离较近,负面情感的文本向量与"差评"基准向量距离较近。通过计算文本向量与这两个基准向量的余弦相似度差值,即可判断文本的情感倾向。
3.2.2 实战案例
案例1:京东iPhone评论分析
python
good_review = "买的银色版很好看,系统丝滑流畅,做工扎实手感细腻"
bad_review = "随意降价,不予价保,服务态度差"
print(get_score(get_embedding(good_review))) # 输出:0.070963 >0 → 好评
print(get_score(get_embedding(bad_review))) # 输出:-0.081472 <0 → 差评案例2:语义反转语句精准识别
python
print(get_score(get_embedding("这家餐馆太好吃了,一点都不糟糕"))) # 0.062719 → 好评
print(get_score(get_embedding("这家餐馆太糟糕了,一点都不好吃"))) # -0.074591 → 差评3.2.3 千条数据验证:96%准确率的工业级表现
在亚马逊美食评论数据集(1k条标注数据)上测试:
python
import pandas as pd
from sklearn.metrics import classification_report
# 数据加载与预处理
df = pd.read_csv("food_reviews.csv")
df["embedding"] = df["text"].apply(get_embedding)
# 情感预测(零样本)
df["pred_sentiment"] = df["embedding"].apply(
lambda emb: "positive" if get_score(emb) > 0 else "negative"
)
# 性能评估
print(classification_report(df["true_sentiment"], df["pred_sentiment"]))评估结果:
precision recall f1-score support
negative 0.98 0.73 0.84 136
positive 0.96 1.00 0.98 789
accuracy 0.96 925
从评估结果和上图可以看出,该方法在亚马逊美食评论数据集上达到了96%的准确率,表现出优异的工业级性能。
四、两种方案的实现步骤
4.1 提示工程方案实现步骤
- 选择LLM API :
使用现成的LLM服务API,例如:- OpenAI GPT (GPT-3.5-turbo, GPT-4)
- Anthropic Claude
- Google Gemini
- 阿里通义千问、百度文心一言、讯飞星火等国内大模型
这些API通常提供按调用次数或Token数计费的服务,无需自己部署或训练模型。
- 构建提示词 :
根据需求(需要简单分类、数值评分还是解释)选择上述一种或组合方法。- 清晰定义任务:要模型做什么(情感分析)。
- 明确指定输出格式:确保输出易于程序解析(如只输出一个词、一个数字、特定标签)。
- 提供必要的上下文(可选):例如"你是一个专业的客户评论分析师"。
- 考虑使用系统消息(如果API支持):设定模型的角色和行为准则。
- 调用API :
使用熟悉的编程语言(Python最常见)调用所选LLM的API。- 将构建好的提示词作为输入发送给API。
- 传递用户需要分析的文本。
- 解析输出 :
接收API返回的响应。
根据指定的输出格式(如提取"积极"、"消极"、"中性"关键词;解析数字;或提取[积极]这样的标签),从模型的回复中解析出最终的情感分析结果。
4.2 语义向量空间方案实现步骤
- 获取API密钥:注册并获取OpenAI等提供Embedding API的平台的密钥。
- 实现Embedding获取与相似度计算函数 :如3.2.1中的
get_embedding、get_score和cosine_similarity函数。 - 确定情感基准:选择合适的正面和负面情感基准词或短语,如"好评"和"差评",也可根据具体领域调整,如"优质服务"和"糟糕体验"。
- 处理文本并计算情感分数 :对需要分析的文本,先获取其Embedding向量,再调用
get_score函数计算情感分数,根据分数正负判断情感倾向。 - 批量处理与性能评估:对于大量文本,可批量获取Embedding并计算情感分数,使用分类报告等工具评估性能。
五、两种方案的对比分析
| 维度 | 提示工程方案 | 语义向量空间方案 |
|---|---|---|
| 核心原理 | 利用模型的指令理解能力,通过提示词引导模型输出情感判断 | 利用文本在向量空间的语义相似性,通过与基准向量的相似度计算判断情感 |
| 输出形式 | 离散标签(积极/消极/中性)或数值评分 | 连续的情感分数,可转换为离散标签 |
| 适用场景 | 对输出格式有明确要求、需要解释性的场景 | 需要细粒度分析、批量处理的场景 |
| 实现复杂度 | 较低,主要在于提示词设计 | 中等,需实现向量计算相关函数 |
| 对模型依赖 | 较高,依赖模型遵循指令的能力 | 较低,主要依赖Embedding的质量 |
| 处理混合情感 | 可通过情感解释法提供一定分析 | 可能需要结合其他方法,单纯分数难以体现混合情感 |
| 计算成本 | 较高,尤其对于长提示词和复杂指令 | 较低,Embedding计算成本相对较低 |
通过以上对比可以看出,两种方案各有优劣,在实际应用中可根据具体需求选择,也可结合使用以提高分析效果。
六、实战中的关键技巧与避坑指南
6.1 提示工程方案技巧
-
优化提示词 :
- 指令要清晰、具体,避免模糊表述。
- 明确输出格式,如"只输出一个词:积极、消极或中性"。
- 对于复杂任务,可分步骤给出指令。
-
处理混合情感 :
采用情感解释法,让模型说明判断理由,便于理解混合情感的构成。例如:pythonprompt = f"""分析以下文本的情感,说明是否存在混合情感,并简要解释理由。最后用标签标出主要情感倾向:[积极], [消极], [中性]。 文本:"{text_to_analyze}" """ -
提高输出一致性 :
- 设置较低的
temperature值(如0.0),降低输出的随机性。 - 对于关键应用,可多次调用模型并取多数结果。
- 设置较低的
6.2 语义向量空间方案技巧
-
情感基准优化 :用更具体的锚点文本,提高基准向量的代表性。
pythonpos_vec = get_embedding("充满热情的赞美之词,对产品或服务非常满意") neg_vec = get_embedding("充满愤怒的投诉内容,对产品或服务极度不满") -
处理混合评价 (如先贬后褒):
结合提示工程方案的Complete接口进行细粒度分析。pythonmixed_review = "屏幕一般但系统流畅,给个中评吧" # 使用Complete接口进行细粒度分析 response = client.completions.create( model="gpt-3.5-turbo-instruct", prompt=f"判断以下文本的情感,分析其中的混合情感成分,并输出JSON格式:{mixed_review}" ) -
批量处理限速方案 :
遵守API的速率限制,避免请求被拒绝。pythonfrom ratelimit import limits @limits(calls=60, period=60) # 限制每分钟60次调用 def safe_get_embedding(text): return get_embedding(text)
七、扩展应用场景
7.1 客服对话情感监测
通过实时分析客服与客户的对话文本,监测客户的情感变化,及时发现负面情绪并进行干预,提高客户满意度。
python
service_talk = "您的问题我们已经记录,会在24小时内给您答复"
score = get_score(get_embedding(service_talk)) # 语义向量空间方案
# 或使用提示工程方案获取情感标签
if score < -0.2 or sentiment == "消极": # 设置合适的阈值或判断条件
alert("客户可能存在负面情绪,需优先处理!")7.2 社交媒体舆情分析
对社交媒体上与品牌、产品相关的帖子、评论等进行批量情感分析,掌握舆情趋势,及时应对负面舆情。
python
tweets = ["新产品的外观设计太惊艳了,必须入手!", "续航能力完全达不到宣传的水平,太失望了"]
# 语义向量空间方案
sentiment_trend = [get_score(get_embedding(t)) for t in tweets]
# 或提示工程方案
# 分析趋势,生成舆情报告7.3 电商评论自动分类与推荐
对电商平台的商品评论进行情感分析,自动将评论分为好评、中评、差评,帮助其他消费者快速了解商品优缺点,同时为商家提供改进方向。
python
# 批量获取评论的情感标签
reviews = ["质量很好,性价比高", "物流慢,包装破损", "一般般,没有特别的亮点"]
sentiments = []
for review in reviews:
# 采用提示工程的直接指令法
prompt = f"分析以下评论的情感是积极、消极还是中性。只输出一个词:{review}"
# 调用API并解析结果
sentiments.append(result)
# 根据情感标签对评论进行分类展示八、重要注意事项
8.1 成本问题
- 调用商业LLM API会产生费用(按Token计费)。分析大量文本时成本需考虑。
- 本地开源模型可降低成本,但需要部署资源和技术支持。
8.2 性能问题
- 零样本/少样本性能:LLM在此任务上通常表现良好,尤其GPT-4、Claude等先进模型。但性能可能略低于在特定领域情感数据集上微调过的专用模型。
- 一致性 :模型的输出可能存在一定程度的波动性(即使
temperature=0,不同模型版本也可能不同)。对于关键应用,可能需要多次调用或加入校验逻辑。 - 复杂情感:处理讽刺、反语、混合情感或领域特定表达时,LLM也可能出错。提供更详细的指令或少样本示例有助于改善。
8.3 偏见问题
LLM训练数据中的偏见可能会影响其情感判断。需注意结果可能存在的潜在偏差,尤其是在涉及性别、种族、宗教等敏感话题时。
8.4 输出解析问题
确保提示词能有效约束输出格式,并编写健壮的解析代码处理可能的格式偏差。例如,对于提示工程方案,模型可能偶尔输出多余的文字,需进行过滤处理。
8.5 延迟问题
API调用存在网络延迟,对于实时性要求极高的场景(如实时客服监测),需考虑使用本地部署的模型或优化调用方式。
8.6 数据隐私问题
将文本发送给第三方API时,务必了解其隐私政策,确保发送的数据不包含敏感信息或符合合规要求,避免数据泄露。
九、结语:NLP平民化时代的到来
大语言模型的情感分析方案实现了:
- 零标注成本:省去数据标注环节,降低了对专业标注人员的依赖。
- 零训练开销:无需GPU等昂贵的训练资源,大大降低了技术门槛。
- 零算法门槛:非技术人员通过简单的提示词设计或调用API,就能快速实现情感分析。
技术的本质不是增加复杂度,而是化繁为简。当自然语言处理从算法专家的实验室走向每个开发者的键盘,我们正在见证AI民主化的革命时刻。
未来,随着大语言模型的不断发展和优化,情感分析的精度和效率将进一步提高,其应用场景也将更加广泛。无论是企业还是个人,都应积极拥抱这一技术变革,利用大语言模型为业务决策和生活带来便利。