一、数据集标注工作
围绕目标检测模型训练的核心需求,本周重点完成了图片标注全流程工作,为 YOLOv5 模型训练筑牢数据基础:
1.标注执行环节:采用 Labelme 标注工具开展人工标注工作,聚焦 2 类核心检测目标(作物、杂草),逐一对样本图片中的目标区域进行框选与类别标注,严格把控标注精度,确保目标边界框贴合实际轮廓、类别标签无错标漏标情况,最终生成 XML 格式的原始标签文件,累计完成有效标注样本 28 张。

2.格式适配环节:由于 YOLOv5 模型仅支持 TXT 格式的标签输入(要求包含归一化坐标与类别索引),针对 JSON标签格式不兼容的问题,编写自定义转换脚本,实现 JSON 标签中像素坐标到归一化坐标的自动换算、类别名称到索引的映射,同时完成格式结构的批量转换,确保转换后的 JSON 标签完全符合 YOLOv5 模型的输入规范,无坐标越界、索引错误等问题。
3.数据整理环节:遵循 "图片 - 标签一一对应" 的核心原则,对标注完成的样本进行系统化整理,将 28 张带有效 TXT 标签的图片统一归类至训练集目录(images/train),对应的标签文件同步存放至 labels/train 目录,清理目录中无对应标签的冗余背景图片 322 张,优化数据存储结构,为后续模型训练时的数据加载提供清晰、规范的文件体系。
二、YOLOv5 训练环境调试与问题解决
在启动 YOLOv5 模型训练过程中,先后排查并解决了多类技术错误,逐步打通训练流程,最终实现模型的正常迭代训练:
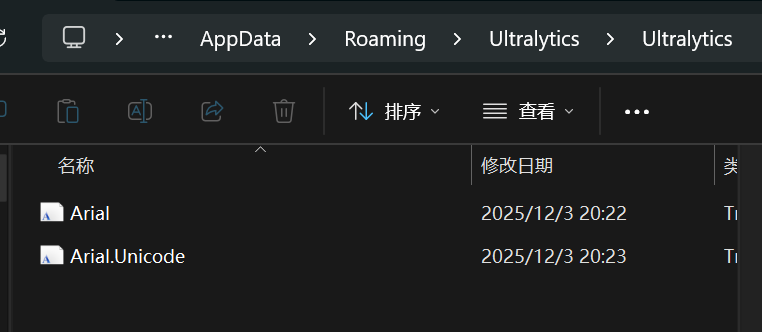
1.字体下载超时问题:训练初始化阶段出现 Arial.Unicode.ttf 字体文件下载超时的报错,导致脚本启动中断。经分析,该问题源于网络环境对外部资源的访问限制,通过注释训练脚本中字体检查与下载的相关代码段,跳过不必要的字体加载步骤,避免网络依赖引发的启动失败,确保脚本能够进入后续初始化流程。下载地址:
https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf
huohuhhttps://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf
2.标签文件未识别问题:训练时触发 "无有效标签" 的断言错误,经定位,核心原因包括数据集目录结构不规范(标签文件与图片文件路径不匹配)、JSON标签格式不符合要求(存在像素坐标未归一化、类别索引错误等情况)。对此,重新规范 images/labels 二级目录结构,确保训练集图片与标签文件路径严格对应;同时批量校验 JSON 标签内容,修正坐标与索引错误,最终使脚本成功识别出 28 张带有效标签的训练样本。在模型训练中要删除train.ache等以.ache结尾的文件。


3.验证集路径错误问题:配置文件 mydata.yaml 中 val 参数错误指向标签目录(labels/train),而非验证集图片目录,导致脚本加载验证集时出现 "无图片" 的加载错误。通过调整配置文件,将 val 路径修正为图片目录(images/train,暂复用训练集作为验证集),确保验证集数据加载逻辑正常,为模型训练过程中的性能评估提供数据支撑。
4.虚拟内存不足问题:初始设置 batch-size=16 时,系统抛出 "页面文件太小" 的错误,经分析,RTX 4060 Laptop GPU(8GB 显存)无法支撑大批次数据的内存开销。通过将 batch-size 从 16 调整为 8,降低单批次数据加载量,减少 GPU 显存与系统内存占用(显存占用从约 5GB 降至 3-4GB),有效解决内存不足导致的训练中断问题。
(1)在终端输入:
cd /d D:\python learning\pythonProject\yolov5_new(2)执行训练命令
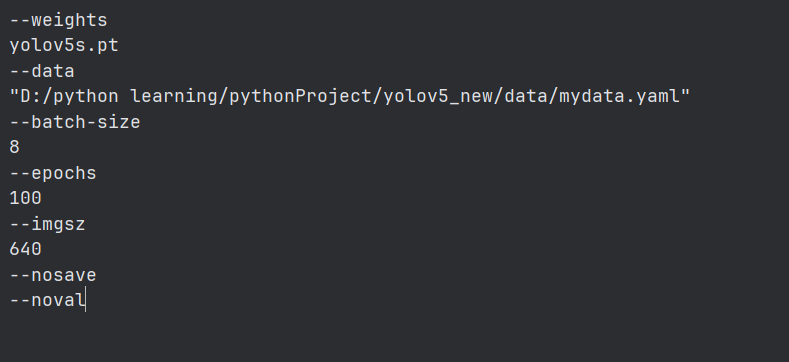
python train.py --weights yolov5s.pt --data data/mydata.yaml --batch-size 8 --epochs 100 --imgsz 640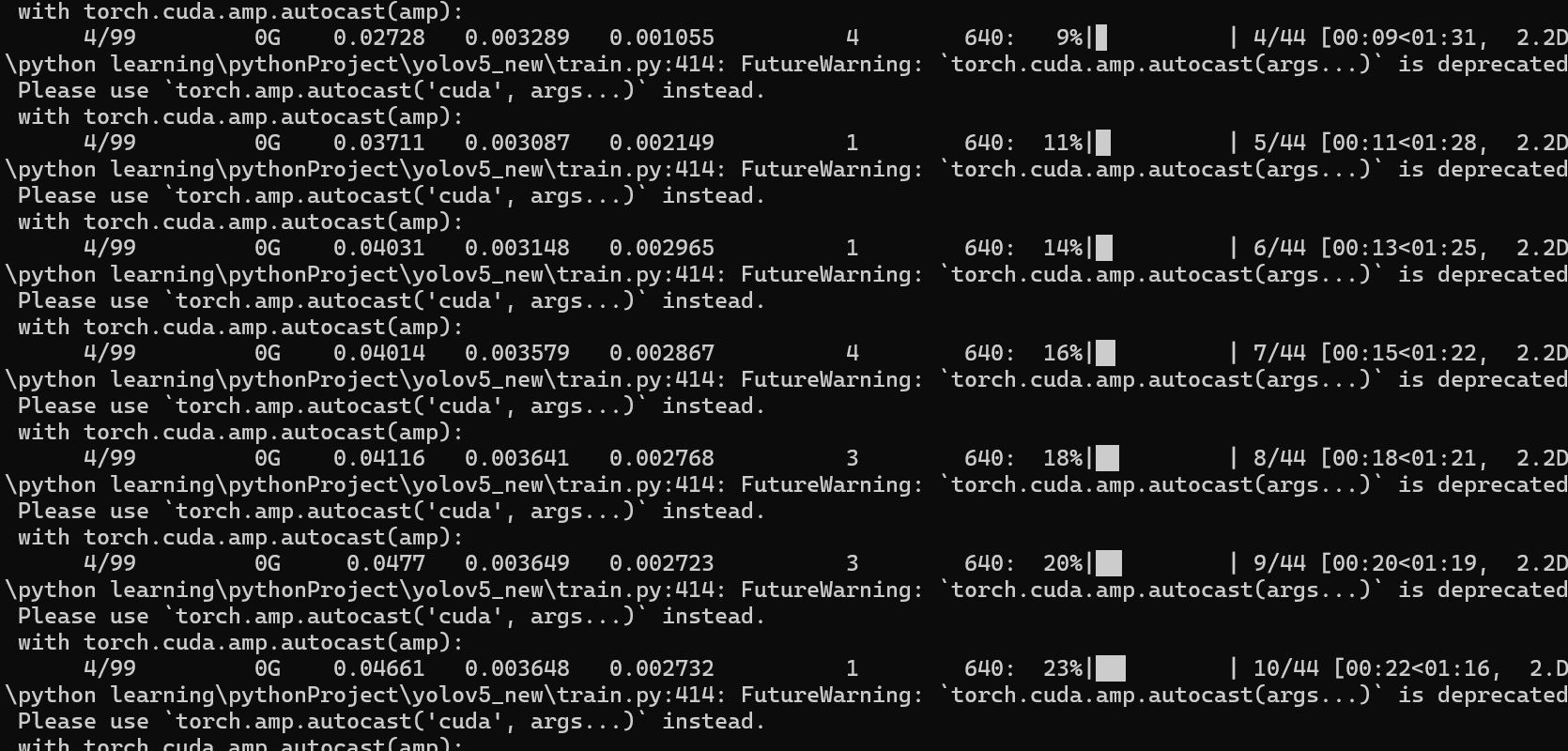
(3)出现Enter command number:输入0后训练会正式启动。
(4)运行结果

5.参数解析错误问题:因数据集配置文件路径(D:\python learning\pythonProject\yolov5_new\data\mydata.yaml)包含空格,脚本解析时将空格后的内容识别为未定义参数,触发 "未识别参数" 的解析失败错误。针对该问题,在训练参数中对含空格的路径添加英文双引号包裹,确保路径作为一个整体被脚本正确解析,最终解决参数解析异常问题。