目前wiz笔记的docker版本停留在1.0.31版本,想要使用最新的功能就不能使用docker自建的服务端了,于是打算在现有基础上根据webAPI的内容对其进行二次开发
目前解析出来的接口都是我急需使用的,大家可以参考,我会在未来慢慢开发完善的
python
import requests,re
from bs4 import BeautifulSoup
class wiz:
def __init__(self,username,password,domain):
self.username = username
self.password = password
self.token = ""
self.kbGuid = ''
self.headers = {}
self.data = []
self.domain = domain
self.update_url() # 初始化 URL
def update_url(self):
self.url={
"getWizToken":f"{self.domain}/as/user/login",
"getFolder":f"{self.domain}/ks/category/all/{self.kbGuid}",
"logOut":f"{self.domain}/as/user/logout",
"getMessageList":f"{self.domain}/ks/note/list/category/{self.kbGuid}",
"getMessage":f"{self.domain}/ks/note/download/{self.kbGuid}/",
}
def getWizToken(self):
params = {
'clientType': 'web',
'clientVersion': '4.0',
'lang': 'zh-cn',
}
json_data = {
'userId': self.username,
'password': self.password,
'autoLogin': True,
'domain': 'clouded.top',
'deviceId': None,
}
response = requests.post(self.url['getWizToken'],params=params,json=json_data,).json()
if response['returnCode'] == 200:#登陆成功
self.token = response["result"]["token"]
self.kbGuid = response["result"]["kbGuid"]
self.update_url()
self.headers["X-Wiz-Token"] = self.token
elif response['returnCode'] == 31002:#用户名密码错误
print(response["returnMessage"])
def getFolder(self):
response = requests.get(self.url['getFolder'],headers=self.headers).json()
for item in response['result']:
# print(item)
self.getMessageList(item)
def logOut(self):
params = {
'domain': 'clouded.top',
'clientType': 'web',
'clientVersion': '4.0',
'lang': 'zh-cn',
}
requests.get(self.url['logOut'], params=params,headers=self.headers)
def getMessageList(self,path):
params = {
'lang': 'zh-cn',
'category': path,
'start': '0',
'count': '100',
'orderBy': 'modified',
'ascending': 'desc',
'withAbstract': 'true',
'withFavor': 'false',
'withShare': 'true',
'clientType': 'web',
'clientVersion': '4.0',
}
response = requests.get(self.url['getMessageList'],params=params,headers=self.headers).json()
res=response['result']
for r in res:
title=r['title']
uid=r['docGuid']
self.getMessage(uid,path)
def getMessage(self,uid,path):
params = {
'downloadInfo': '1',
'downloadData': '1',
'withFavor': 'false',
'withShare': 'true',
'clientType': 'web',
'clientVersion': '4.0',
'lang': 'zh-cn',
}
response = requests.get(f'{self.url['getMessage']}{uid}',params=params,headers=self.headers).json()
wordCount,imageCount = self.wordCount(response['html'])
audioCount = 0
print(f"getOK-{path}{response['info']['title']}")
if response['resources']:
for i in response['resources'] :
if 'wiz' not in i['name'] and 'audio.png' in i['name']:
imageCount -= 1#音频资源的图标会错误的解析为图片
audioCount += int(i['size']/1024/4.5)#音频长度累加 单位:s 粗略估计
self.data.append({"path":f"{path}","title":response['info']['title'],"owner":response['info']['owner'],"wordCount":wordCount,"imageCount":imageCount,"audioCount":audioCount,"accessed":response['info']['accessed'],"created":response['info']['created']})
def wordCount(self,html):
soup = BeautifulSoup(html,'html.parser')
for elem in soup(['style', 'script', 'head', 'title', 'meta']):
elem.decompose()
char_count = len(re.sub(r'\s', '', soup.get_text()))
image_count = len(soup.find_all('img'))
return char_count,image_count
def showData(self):
# for one in self.data:
# print(one)
# print(self.data)
return self.data
#main=wiz(username="admin@wiz.cn",password="123456",domain="http://120.349.12.333:9192")
main.getWizToken()
main.getFolder()
data=main.showData()
main.logOut()大家可以自行运行代码,更改账号密码以及服务器链接就可以查看自己服务器上的文章信息,目前还在开发中...
目前基于这个写了一个文章总览页面,类似Github的代码热力图
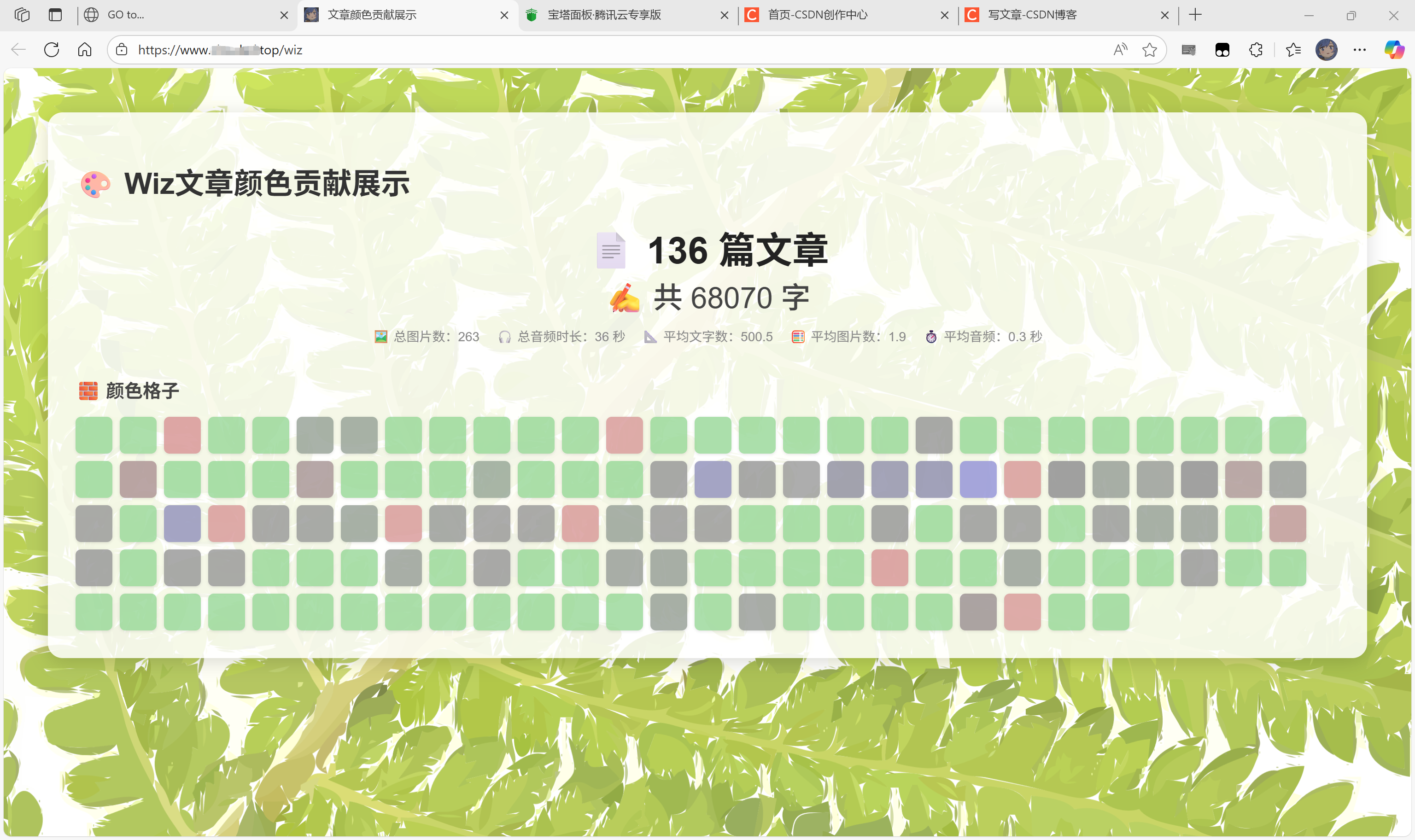
有兴趣的话可以在下一章放出源代码