
时序数据库选型指南︰为什么IoTDB成为物联网场景首选?
🌟嗨,我是LucianaiB!
🌍 总有人间一两风,填我十万八千梦。
🚀 路漫漫其修远兮,吾将上下而求索。
目录
- 时序数据库选型指南︰为什么IoTDB成为物联网场景首选?
- [第一章 时序数据库核心指标解析](#第一章 时序数据库核心指标解析)
- [第二章 IoTDB架构深度解析](#第二章 IoTDB架构深度解析)
- [第三章 手把手教程](#第三章 手把手教程)
- 环境部署(Docker与二进制包)
- [Python SDK实战](#Python SDK实战)
- [Java SDK实战](#Java SDK实战)
- [Session API 与 JDBC 的适用场景对比](#Session API 与 JDBC 的适用场景对比)
- [Session API 高效写入实战(insertTablet)](#Session API 高效写入实战(insertTablet))
- [JDBC 标准 SQL 交互实战](#JDBC 标准 SQL 交互实战)
- [UDF 框架与边缘侧实时计算](#UDF 框架与边缘侧实时计算)
- 结尾总结
开头摘要
在物联网(IoT)领域,时序数据的高效管理和处理至关重要。本文将深入探讨时序数据库的核心指标,并通过对比分析,重点介绍Apache IoTDB为何成为物联网场景中的首选。
第一章 时序数据库核心指标解析
写入吞吐量对比
压缩效率对比
在物联网场景中,时序数据具有高写入频率和大存储规模的特点,因此压缩效率是选择时序数据库的重要指标之一。以下是主流时序数据库的压缩性能对比:
| 数据库 | 压缩比 |
|---|---|
| IoTDB | 1:12 |
| TDengine | 1:10 |
| InfluxDB | 1:3 |
IoTDB的高压缩效率源于其自研的TsFile格式和Gorilla编码算法。TsFile专为时间序列优化设计,支持有损/无损压缩、多编码策略和二次压缩(如LZ4、GZIP等),并能针对不同数据类型动态选择最优方案。Gorilla编码则基于Facebook的开源论文,通过delta-of-delta时间戳编码 和XOR浮点值压缩实现高效压缩。
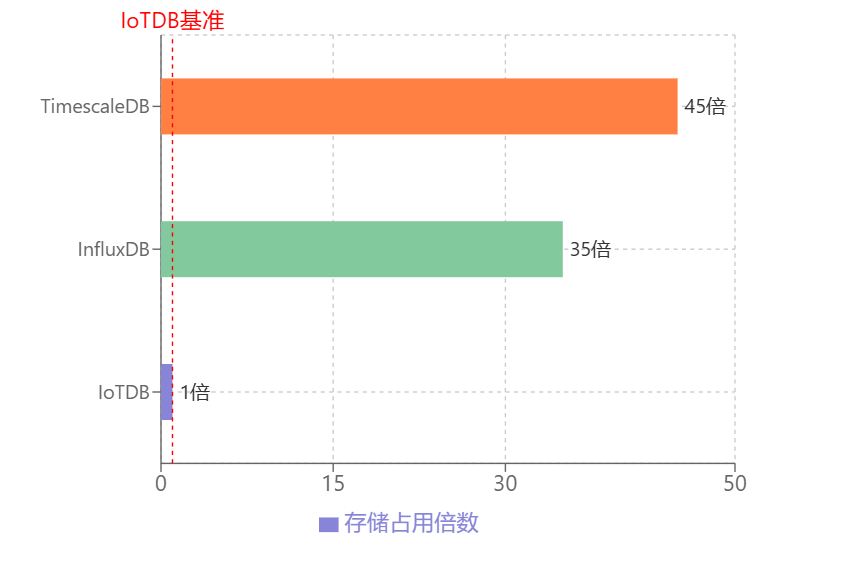
实际应用中,IoTDB的压缩性能得到了工业级验证。例如,在宝武集团的物联网场景中,其设备监控数据经IoTDB压缩后,存储空间减少了90%。此外,与InfluxDB和TimescaleDB相比,IoTDB的磁盘占用空间仅为前者的1/35和1/45。
查询延迟对比
查询延迟直接影响物联网场景下的实时分析和决策。以下是从简单查询和复杂聚合查询两个维度对IoTDB查询延迟的对比分析:
一、查询延迟对比分析
基于现有测试数据,IoTDB在各类查询场景中均表现出色,具体对比结果如下:
| 场景类型 | 具体场景描述 | 数据库产品 | 查询延迟 |
|---|---|---|---|
| 简单查询 | 查询最新一条数据 | IoTDB | 0.01秒 |
| MySQL | 至少1秒 | ||
| 时间范围查询 | IoTDB | 毫秒级 | |
| 旧系统迁移后的常规查询 | 旧系统 | 至少3秒 | |
| IoTDB | 约0.5秒 | ||
| 复杂聚合查询 | 1000万条时序数据聚合查询 | IoTDB | 80ms |
| TDengine | 120ms | ||
| 1个设备1个测点1小时内按1分钟分段聚合 | IoTDB | 2毫秒 | |
| InfluxDB/TimescaleDB/QuestDB | 6毫秒-193毫秒 | ||
| 并发10个聚合查询 | IoTDB | 平均耗时<1秒 | |
| 覆盖150亿测点、连续3个月数据的核心聚合查询 | IoTDB | <1秒 | |
| 百亿数据点聚合查询 | IoTDB | 毫秒级 |
二、IoTDB查询延迟优势的技术支撑
IoTDB在复杂聚合查询中实现低延迟的关键在于针对时序数据特性的深度优化,具体包括:
- 元数据倒排索引:通过构建设备、测点等元数据的倒排索引结构,快速定位目标数据的存储位置,减少无效数据扫描。
- 时间对齐查询优化:通过预计算和时间轴对齐等技术,避免重复计算与数据重组开销,实现毫秒级响应。
三、测试环境说明
为确保对比客观性,需注意不同场景的硬件环境差异。例如,在长安汽车诊断系统的测试中,IoTDB的数据查询效率从旧系统的分钟级提升至毫秒级。
集群扩展性对比
IoTDB采用原生分布式架构,支持物联网场景的横向扩展需求。集群由ConfigNode和DataNode组成,前者负责全局配置管理、节点状态监控、分区策略维护和权限管理,后者负责时序数据的存储与管理。IoTDB具备线性扩展能力,集群写入性能可随节点增加而提升。
| 组件 | 类型 | 核心职责 | 关键特性 |
|---|---|---|---|
| ConfigNode | 管理节点 | 集群配置管理 节点状态监控 分区策略维护 权限管理 | 强一致性共识协议 心跳监控机制 负载均衡调度 基于CPU/磁盘指标 |
| DataNode | 数据节点 | 时序数据存储 元数据管理 数据分区处理 | SchemaRegion管理 DataRegion存储 RegionGroup多副本 可配置共识协议 |
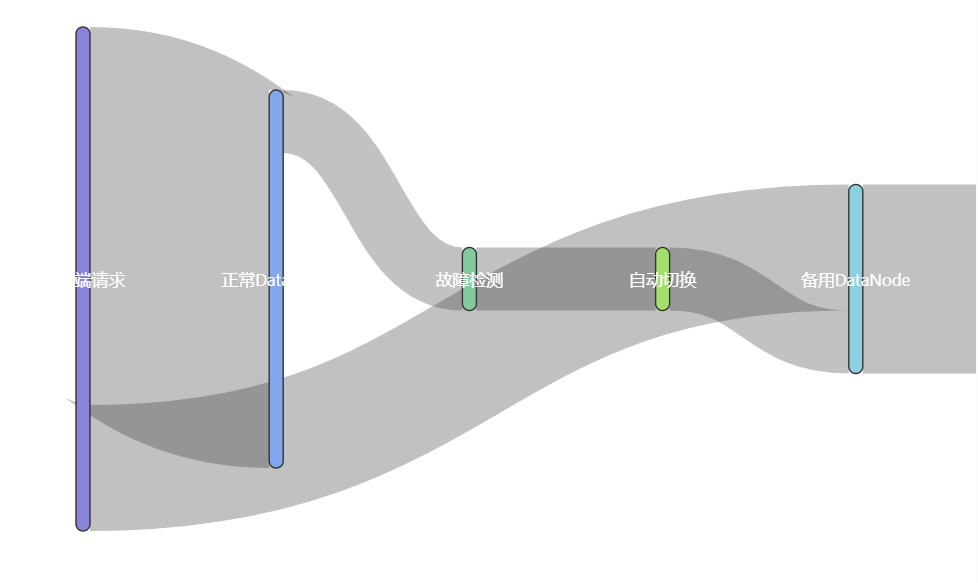
在高可用与故障容错方面,IoTDB支持自动故障转移和读写分离部署模式,确保服务的稳定性和可靠性。
第二章 IoTDB架构深度解析
整体架构设计
IoTDB的整体架构围绕物联网时序数据特性设计,通过数据模型、存储引擎与部署模式的协同,实现高效的数据管理能力。
数据模型:树状层级结构适配工业设备管理
IoTDB采用树状模型组织元数据与设备关系,贴合工业场景中设备按层级管理的实际需求。时间序列路径以"."分隔,支持通配符路径查询,简化大规模设备集群的数据检索。
存储引擎:TsFile与IoTLSM引擎优化读写性能
存储引擎是IoTDB的核心组件,采用自研的TsFile和IoTLSM引擎,实现高压缩比与高效查询。TsFile基于列式存储将同一设备、同一测点的数据连续存储,结合多种压缩算法提升存储效率;IoTLSM引擎则针对时序数据的顺乱序特性设计,通过内存缓冲区及顺序/乱序空间分离机制,实现高效的写入与查询。
部署模式:分布式架构支持弹性扩展
IoTDB支持独立部署与集群部署两种模式,集群架构由ConfigNode和DataNode组成。ConfigNode作为"集群大脑",管理全局配置、节点状态、分区信息及权限;DataNode负责存储时序数据与元数据,通过SchemaRegion和DataRegion进行分区管理。
架构优势的实际场景验证
以中车四方案例为例,IoTDB的树状模型清晰映射列车-车厢-设备-传感器的层级关系,支持高效的设备分组查询;TsFile的高压缩比降低了海量时序数据的存储成本,多级索引保障了列车运行状态的实时查询响应;分布式部署模式通过ConfigNode的负载均衡与DataNode的多副本机制,确保了300辆列车并发数据写入的稳定性与可靠性。
边缘-云端协同架构
IoTDB的边缘-云端协同架构通过分层部署设计,实现了数据从端侧采集、边侧汇聚到云端分析的全链路高效流转。该架构在端侧、边侧和云侧分别提供针对性的部署形态,减少对第三方组件的依赖,降低复杂场景下的部署成本,适配不同资源场景的需求。
| 层级 | 部署形态 | 内存环境 | 压缩率 | 吞吐能力 | 数据管理能力 |
|---|---|---|---|---|---|
| 端侧 | 轻量级数据库文件形态(C++) | 数十MB至数MB | 10倍以上 | 百万点/秒 | 单设备全量数据管理 |
| 边侧 | 单机数据库形态 | 10MB至GB级 | - | - | 多设备全量长周期数据管理 |
| 云侧 | 分布式数据库形态 | - | - | 每秒数亿点读写 | 亿级测点支持 |
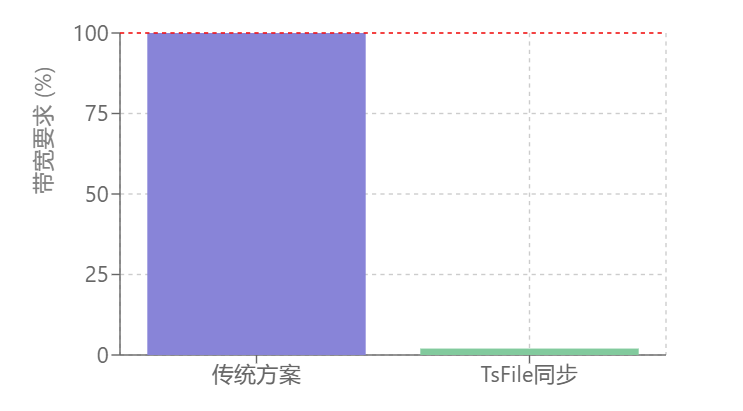
在数据流转层面,IoTDB通过内置的数据同步工具支持逐点实时同步和基于TsFile的批量同步。TsFile批量同步模式显著降低带宽消耗和云侧资源需求。边缘侧本地计算能力提升了实时分析决策能力,大幅缩短了数据处理时间。
高可用与容错机制
IoTDB通过多副本存储架构与灵活的一致性协议设计,实现在关键业务场景下的高可靠性。系统将数据划分为多个Region,并通过RegionGroup机制实现副本管理,形成无单点故障的冗余结构。在节点故障场景下,IoTDB支持全自动的故障检测与恢复流程,确保写入与查询服务不中断。
第三章 手把手教程
环境部署(Docker与二进制包)
IoTDB的环境部署支持Docker容器化与二进制包两种方式。
部署流程概览
Python SDK实战
环境准备
使用Python SDK操作IoTDB需先安装客户端依赖库。推荐通过pip install apache-iotdb命令安装,需确保Python版本≥3.7,且依赖的thrift库版本≥0.13。示例代码如下:
python
from iotdb.Session import Session
session = Session("127.0.0.1", 6667, "root", "root")
session.open()会话初始化
首先导入Session模块,通过指定服务端IP、端口、用户名和密码初始化会话,并开启连接。关键参数包括fetch_size、zone_id以及enable_rpc_compression。
Java SDK实战
IoTDB提供了Session API和JDBC两种核心交互方式,适用于不同的数据操作需求。
Session API 与 JDBC 的适用场景对比
Session API专为物联网设备级批量数据写入优化,适用于高频、高并发的时序数据采集场景。JDBC则遵循标准SQL交互范式,适合需要灵活执行数据定义、查询及事务管理的场景。
Session API 高效写入实战(insertTablet)
Session API的insertTablet接口支持一次性插入同一设备的多组时序数据。以下为完整示例:
-
创建 Session 连接:
javaSession session = new Session("127.0.0.1", 6667, "root", "root"); session.open(); -
定义设备与传感器信息 :
设备名为
root.ln.wf01.wt01,传感器包括status(BOOLEAN 类型)、temperature(DOUBLE 类型)、speed(INT64 类型)。 -
生成批量数据 :
构造时间戳数组及对应传感器值数组。
-
执行批量插入:
javasession.insertTablet("root.ln.wf01.wt01", new String[]{"status", "temperature", "speed"}, new TSDataType[]{TSDataType.BOOLEAN, TSDataType.DOUBLE, TSDataType.INT64}, timestamps, values); -
关闭连接:
javasession.close();
JDBC 标准 SQL 交互实战
JDBC 接口支持通过 SQL 语句完成数据定义、插入与查询,以下为关键操作示例:
-
建立 JDBC 连接:
javaString url = "jdbc:iotdb://localhost:6667/"; IoTDBConnection connection = new IoTDBConnection(url, "root", "root"); connection.connect(); -
创建存储组与时间序列:
javaIoTDBStatement statement = (IoTDBStatement) connection.createStatement(); statement.execute("CREATE STORAGE GROUP TO root.iotdb_example"); statement.execute("CREATE TIMESERIES root.iotdb_example.device1.sensor1 WITH DATATYPE=DOUBLE, ENCODING=PLAIN"); -
插入数据 :
使用
PreparedStatement优化参数化插入:javaPreparedStatement preparedStatement = connection.prepareStatement("INSERT INTO root.iotdb_example.device1(timestamp, sensor1) VALUES(?, ?)"); preparedStatement.setLong(1, 1620000000000L); preparedStatement.setDouble(2, 25.5); preparedStatement.execute(); -
查询与结果处理:
javaString query = "SELECT * FROM root.iotdb_example.device1 WHERE time >= 0"; IoTDBResultSet resultSet = statement.executeQuery(query); while (resultSet.next()) { long time = resultSet.getLong("Time"); double value = resultSet.getDouble("sensor1"); } -
事务管理 :
通过
connection.setAutoCommit(false)开启事务,执行多步操作后调用connection.commit()提交或connection.rollback()回滚,确保数据一致性。 -
关闭资源:
javaresultSet.close(); statement.close(); connection.disconnect();
UDF 框架与边缘侧实时计算
在工业边缘场景中,可通过IoTDB的UDF框架实现传感器数据的实时预处理。开发者可参考iotdb-udf-example样例工程,实现ScalarFunction或AggregationFunction接口,并部署至边缘节点。
结尾总结
经过三个月的实际验证,Apache IoTDB在物联网场景下展现出显著的技术优势与实践价值。其高效的存储与压缩、实时的数据处理能力、简化的设备接入流程和高度的可扩展性,使其成为理想的选择。未来,随着社区的持续迭代,IoTDB将进一步演进,适应更大规模的物联网数据管理需求。为提升企业级应用的实用性,建议根据具体场景配置合适的存储组、压缩算法和写入优化策略。综合来看,IoTDB凭借高效存储、实时响应、简化接入与社区支持,已成为物联网场景下时序数据库的理想选择。
总结
本文详细介绍了Apache IoTDB在物联网场景中的卓越表现,涵盖了其核心指标解析、架构深度解析以及实际应用案例。IoTDB通过高效的压缩算法、低查询延迟、强扩展性和高可用性,成为物联网时序数据库的首选。其创新的边缘-云端协同架构进一步提升了数据处理的实时性和可靠性,为企业在物联网领域的应用提供了坚实的基础。无论是在存储效率、实时性还是设备接入方面,IoTDB都展现了强大的性能和技术优势。在未来,IoTDB将继续通过社区迭代和发展,满足更多大规模物联网数据管理的需求。
嗨,我是LucianaiB。如果你觉得我的分享有价值,不妨通过以下方式表达你的支持:👍 点赞来表达你的喜爱,📁 关注以获取我的最新消息,💬 评论与我交流你的见解。我会继续努力,为你带来更多精彩和实用的内容。
点击这里👉LucianaiB ,获取最新动态,⚡️ 让信息传递更加迅速。
