技术点目录
-
- 专题一、R及Python语言及相关性研究初步
- 专题二、二元Copula理论与实践(一)
- 专题三、二元Copula理论与实践(二)【R语言为主】
- 专题四、Copula函数的统计检验与选择【R语言为主】
- [专题五、高维数据与Vine Copula 【R语言】](#专题五、高维数据与Vine Copula 【R语言】)
- [专题六、正则Vine Copula(一)【R语言】](#专题六、正则Vine Copula(一)【R语言】)
- [专题七、正则Vine Copula(二)【R语言】](#专题七、正则Vine Copula(二)【R语言】)
- [专题八、时间序列中的Copula 【R语言】](#专题八、时间序列中的Copula 【R语言】)
- 专题九、Copula回归【R语言】
- 专题十、Copula下的结构方程模型【R语言】
- 专题十一、Copula贝叶斯网络【Python语言】
- [专题十二、Copula的贝叶斯估计 【Python语言】](#专题十二、Copula的贝叶斯估计 【Python语言】)
- 专题十三、AI辅助的Copula统计学
- 了解更多
前沿综述
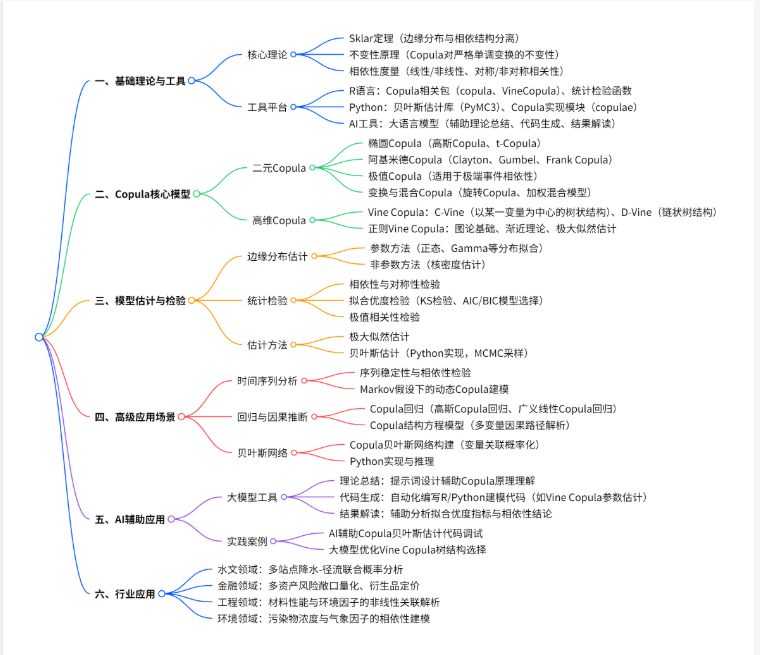
本文核心围绕Copula 变量相关性分析与AI 大模型辅助应用展开,构建了从基础理论到高级实践的完整技术体系,为多变量复杂相关性解析提供了创新工具。
核心模型与理论:
Copula 理论基于 Sklar 定理,突破传统相关系数(如皮尔逊、秩相关)的局限,可精准刻画变量间非线性、非对称的相关性结构,且能分离边缘分布与相依结构,灵活适配不同数据类型(连续 / 离散、正态 / 非正态)。核心模型包括:①二元 Copula(椭圆 Copula、阿基米德 Copula、极值 Copula),适用于双变量相依性分析;②高维 Vine Copula(C-Vine、D-Vine),通过树状结构拆解高维变量关联,解决维度灾难问题;③衍生应用模型(Copula 回归、Copula 结构方程模型、Copula 贝叶斯网络),拓展至因果推断与多变量预测场景。
最新技术应用:
模型估计与检验优化:结合参数与非参数方法估计边缘分布,通过拟合优度检验(如 KS 检验)、极值相关性检验筛选最优 Copula 函数;引入贝叶斯估计(Python 实现),利用 MCMC 算法提升小样本下的参数估计稳健性。
高维与动态场景拓展:Vine Copula 通过图论原理简化高维变量关联,已应用于水文多站点径流相关性、金融多资产风险联动分析;时间序列 Copula 结合 Markov 假设,实现动态相依性建模(如股价波动与宏观经济指标的时变关联)。
AI 辅助工具革新:借助大语言模型(如 ChatGPT)辅助 Copula 理论理解、代码生成与结果解读,通过提示词优化实现 R/Python 代码自动化编写,提升复杂模型(如 Vine Copula)的建模效率。
交叉行业应用:
在水文领域,用于极端降水与洪水的联合概率分析,支撑防洪工程设计;在金融领域,通过 Copula 贝叶斯网络量化多资产违约相关性,优化风险管理策略;在工程领域,解析材料性能与环境因子的非线性关联,指导产品可靠性设计。2024 年《Water Resources Research》研究显示,Vine Copula 在多流域径流预测中的精度较传统方法提升 15%-20%,已成为复杂系统相关性解析的核心工具。
专题一、R及Python语言及相关性研究初步
1.R语言及Python的基本操作
2.各类相关系数的区别及实现
3.R语言及Python中Copula相关包和函数
专题二、二元Copula理论与实践(一)
1.Sklar定理与不变性原理
2.椭圆分布与椭圆Copula
3.阿基米德Copula
专题三、二元Copula理论与实践(二)【R语言为主】
1.极值相依性与极值Copula
2.Copula函数的变换:旋转与混合Copula
3.边缘分布估计:参数与非参数方法
4.Copula函数的估计
5.Python的相关实现
专题四、Copula函数的统计检验与选择【R语言为主】
1.相依性与对称性检验
2.拟合优度与其它统计检验
3.极值相关性检验
4.模型选择
5.Python相关实现
专题五、高维数据与Vine Copula 【R语言】
1.条件分布函数
2.C-Vine Copula
3.D-Vine Copula
专题六、正则Vine Copula(一)【R语言】
1.图论基础与正则Vine树
2.正则Vine Copula族及其简化
3.正则Vine Copula的模拟
专题七、正则Vine Copula(二)【R语言】
1.Vine Copula的渐近理论与极大似然法估计
2.正则Vine Copula模型的选择
3.模型检验比较
专题八、时间序列中的Copula 【R语言】
1.时间序列理论初步(稳定性检验、相依性检验)
2.Markov假设
3.时间序列的Copula
专题九、Copula回归【R语言】
1.回归的基本理论
2.广义线性回归
3.高斯Copula回归
4.一般Copula回归
专题十、Copula下的结构方程模型【R语言】
1.结构方程模型的基本原理
2.R语言的结构方程模型
3.Copula结构方程模型的构建
4.模型检验
专题十一、Copula贝叶斯网络【Python语言】
1.什么是贝叶斯网络
2.贝叶斯网络与Copula模型的相似性
3.Copula贝叶斯网络的原理
4.Copula贝叶斯网络的Python实现
专题十二、Copula的贝叶斯估计 【Python语言】
1.贝叶斯统计学基本原理
2.Python中的贝叶斯统计初步
3.Copula贝叶斯先验及其估计
4.Python中实现Copula的贝叶斯估计
专题十三、AI辅助的Copula统计学
1.大语言模型是什么?以及它的强项与弱项
2.主要AI的比较与推荐
3.提示词的要点
4.利用AI辅助总结理论及输入要点
5.Python与R语言的人工智能注释
6.AI如何辅助Copula统计编程
7.利用AI辅助理解结果
了解更多
V头像