学员闯关手册:https://aicarrier.feishu.cn/wiki/QdhEwaIINietCak3Y1dcdbLJn3e
课程视频:https://www.bilibili.com/video/BV13U1VYmEUr/
课程文档:https://github.com/InternLM/Tutorial/tree/camp4/docs/L0/Python
关卡作业:https://github.com/InternLM/Tutorial/blob/camp4/docs/L0/Python/task.md
开发机平台:https://studio.intern-ai.org.cn/
开发机平台介绍:https://aicarrier.feishu.cn/wiki/GQ1Qwxb3UiQuewk8BVLcuyiEnHe
书生浦语官网:https://internlm.intern-ai.org.cn/
github网站:https://github.com/internLM/
InternThinker: https://internlm-chat.intern-ai.org.cn/internthinker
快速上手飞书文档:https://www.feishu.cn/hc/zh-CN/articles/945900971706-快速上手文档
提交作业:https://aicarrier.feishu.cn/share/base/form/shrcnUqshYPt7MdtYRTRpkiOFJd;
作业批改结果:https://aicarrier.feishu.cn/share/base/query/shrcnkNtOS9gPPnC9skiBLlao2c
internLM-Chat 智能体:https://github.com/InternLM/InternLM/blob/main/agent/README_zh-CN.md
lagent:https://lagent.readthedocs.io/zh-cn/latest/tutorials/action.html#id2
github仓库:https://github.com/InternLM/xtuner
动态知识库:https://deepwiki.com/InternLM/xtuner
1.GraphGen介绍
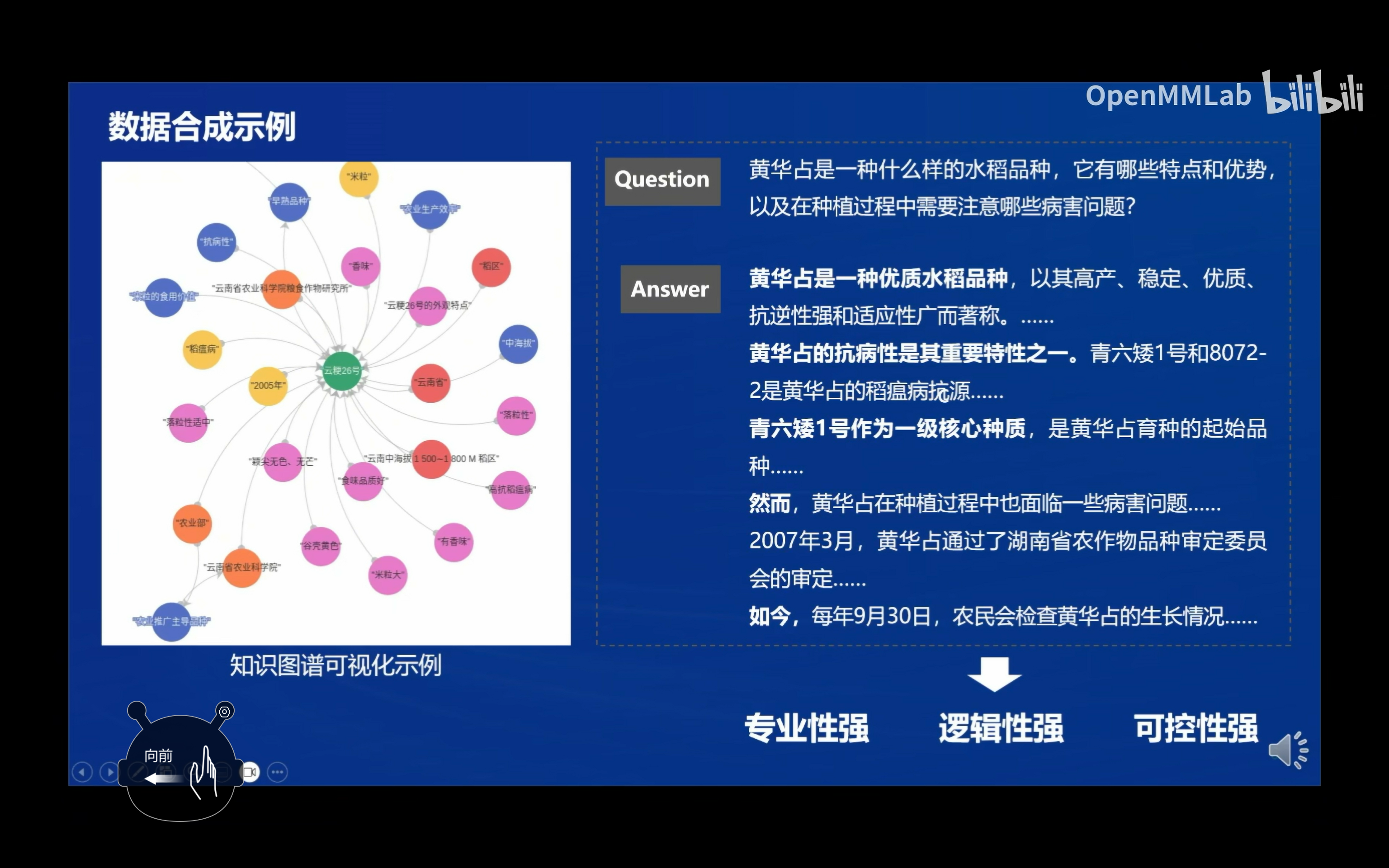
GraphGen是一个基于知识图谱的SFT数据生成框架。
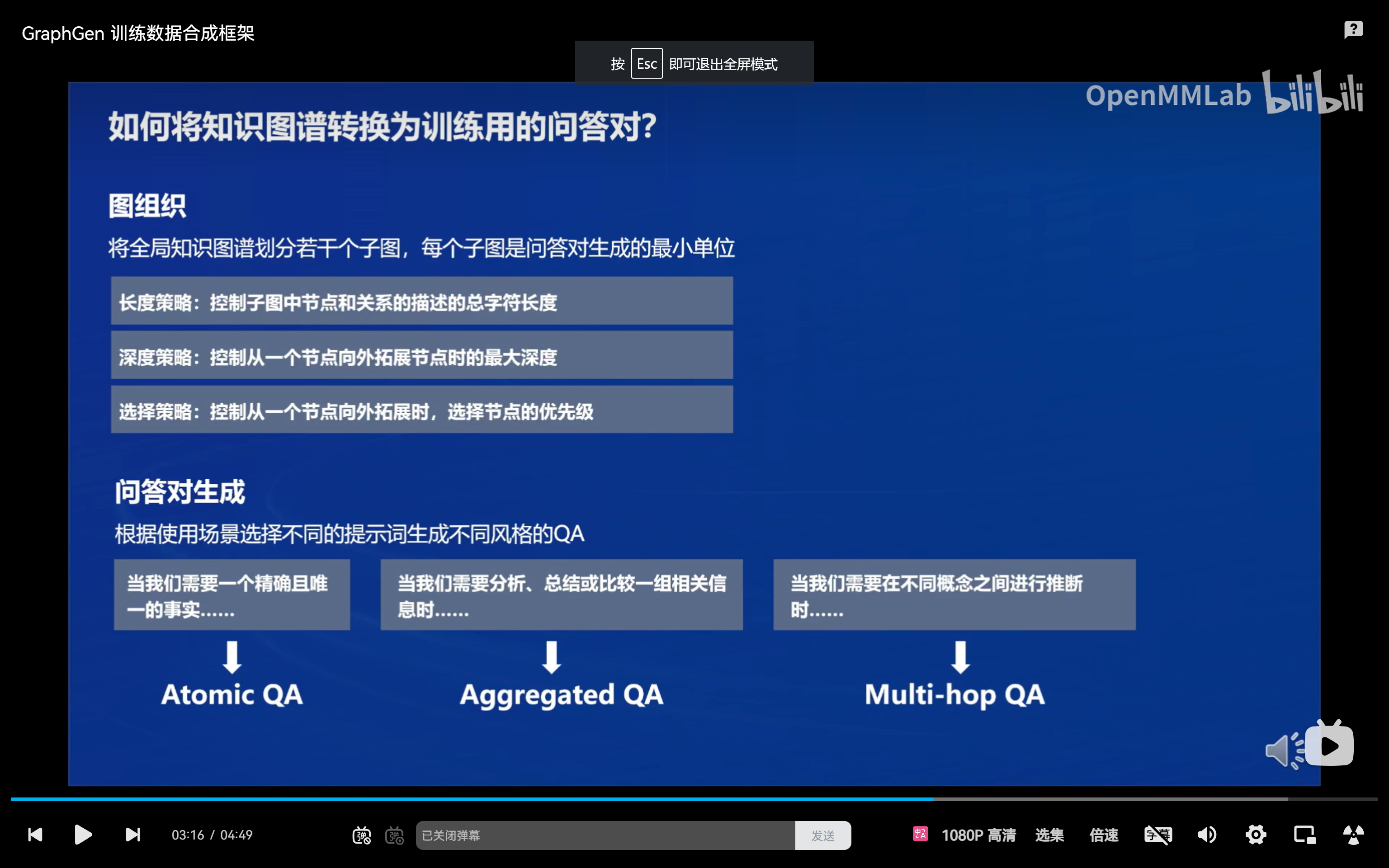
该框架通过构建细粒度知识图谱、识别 LLMs 的知识盲点、并生成多风格的内容来提高模型在知识密集型任务上的表现。GraphGen 适用于三种关键问答场景:原子问答(atomic QA)、聚合问答(aggregated QA)和多跳问答(multi-hop QA)。
- Atomic QA:最基础的问答形式,专注于单一知识点或事实。
- Aggregated QA:涉及多个知识点或复杂信息的整合。
- Multi-hop QA:需要通过多步推理,结合多个知识点才能回答。
Github仓库:https://github.com/open-sciencelab/GraphGen
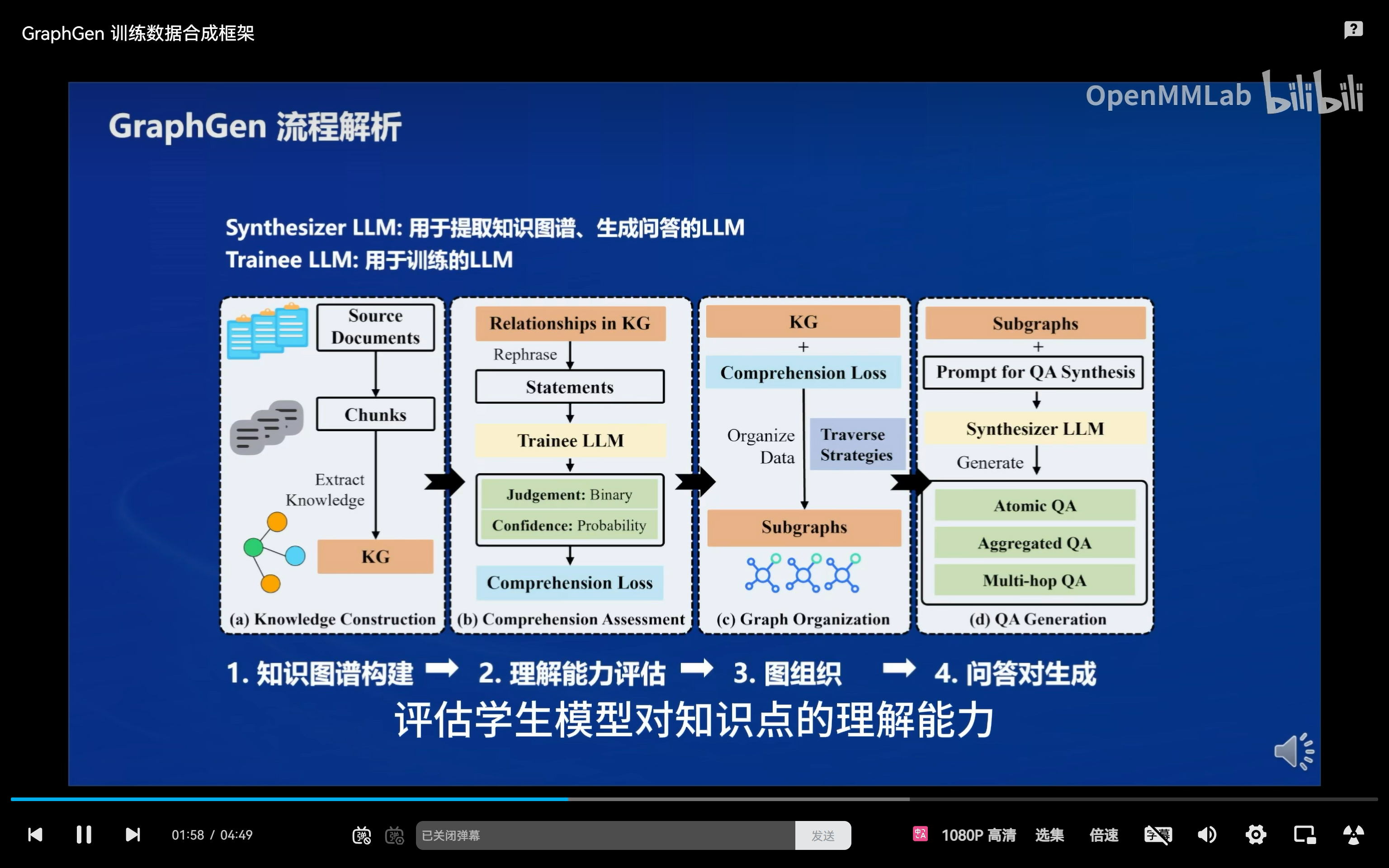
2. GraphGen流程解析
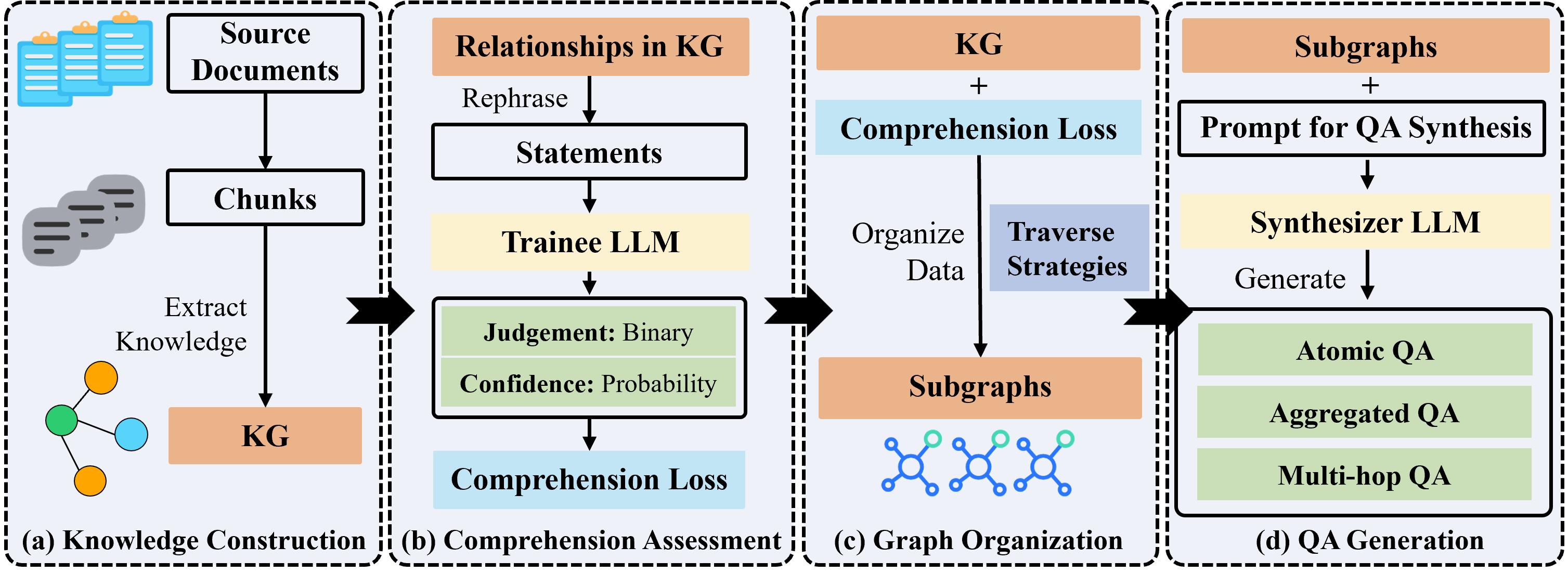
- 知识图谱构建
- 文本分割:将原始文档分割成语义连贯的小片段。
- 实体与关系提取:使用 Synthesizer Model 从片段中识别和提取实体及其关系。
- 知识图谱聚合:将不同片段中的相同实体或关系的描述自动合并,形成知识图谱。
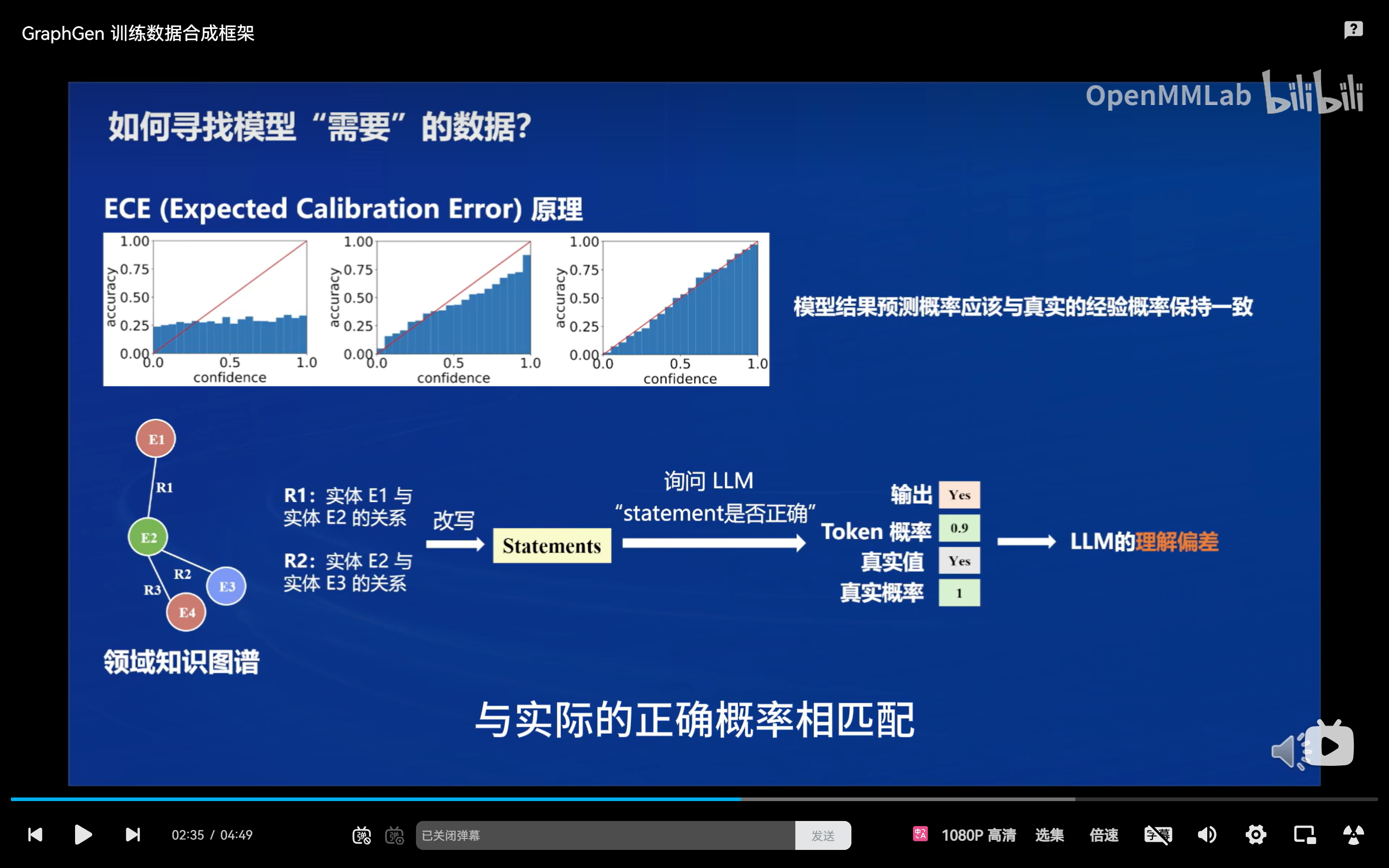
- 理解能力评估
- 知识表示:将知识图谱中的每个关系视为一个知识陈述 Ri,并生成其改写版本及否定版本。
- 置信度量化:通过 Trainee Model 对这些陈述的置信度进行评估,计算其对每个知识点的理解程度。
- 理解损失计算:通过计算真实分布与预测分布之间的交叉熵,来衡量 Trainee Model 对知识的理解差距。
- 图组织
- 子图提取:执行 k-hop 子图提取,以有效组织知识图谱。采用深度策略、长度策略和选择策略来平衡子图的复杂性、相关性和计算可行性。
- 问答对生成
- 原子 QA 生成:从单个节点或边生成基础问答对。
- 聚合 QA 生成:组织和改写子图中的数据,生成涉及多个实体和关系的综合性问答对。
- 多跳 QA 生成:明确实体间关系,生成需要多步推理的问答对。
代码实战
bash
#环节部署
conda create -n graphgen python=3.10 -y
conda activate graphgen
git clone https://github.com/open-sciencelab/GraphGen.git
cd GraphGen
pip install -r requirements.txt
#2使用Gradio Demo进行简单数据合成,
python webui/app.py
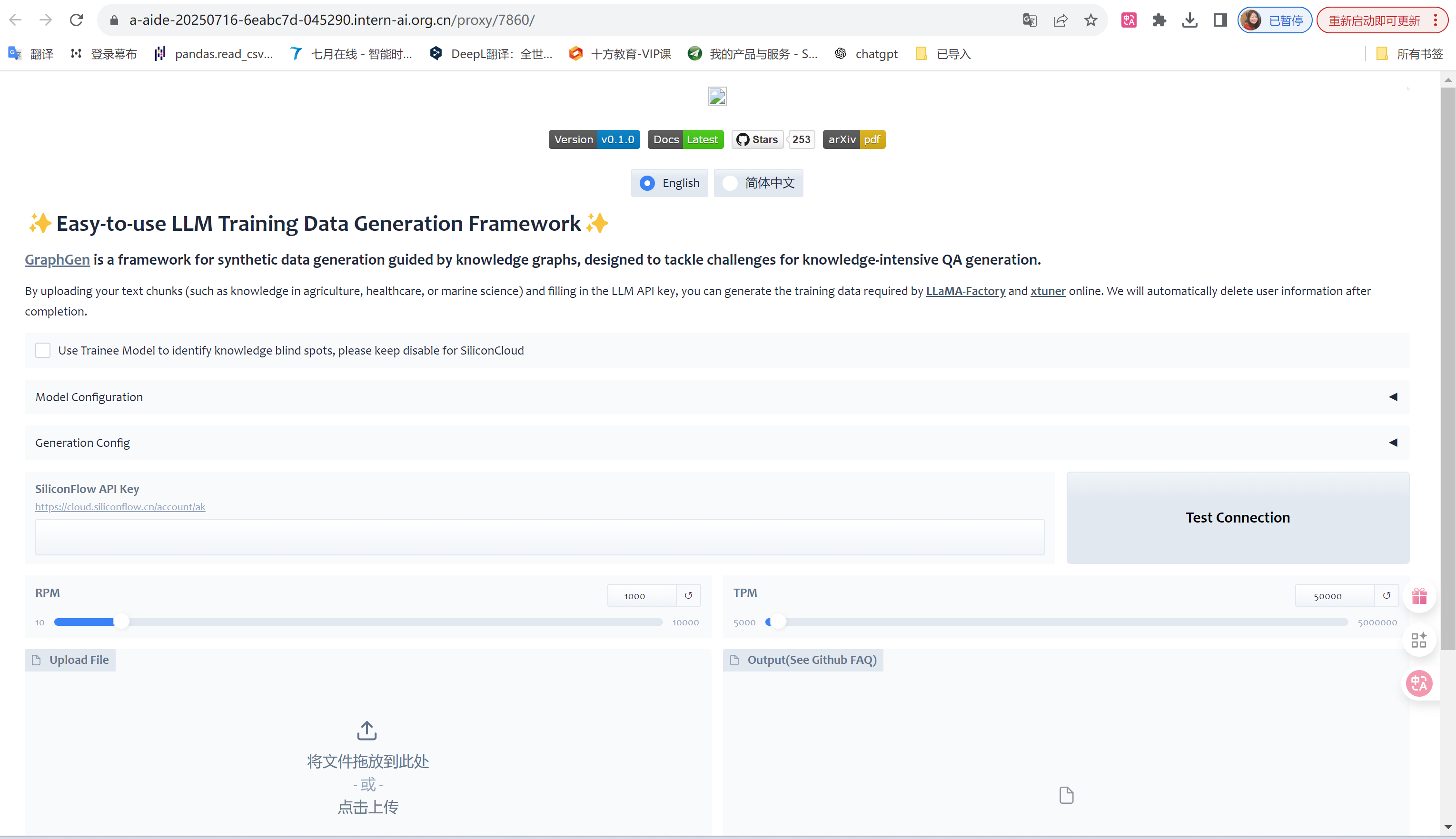
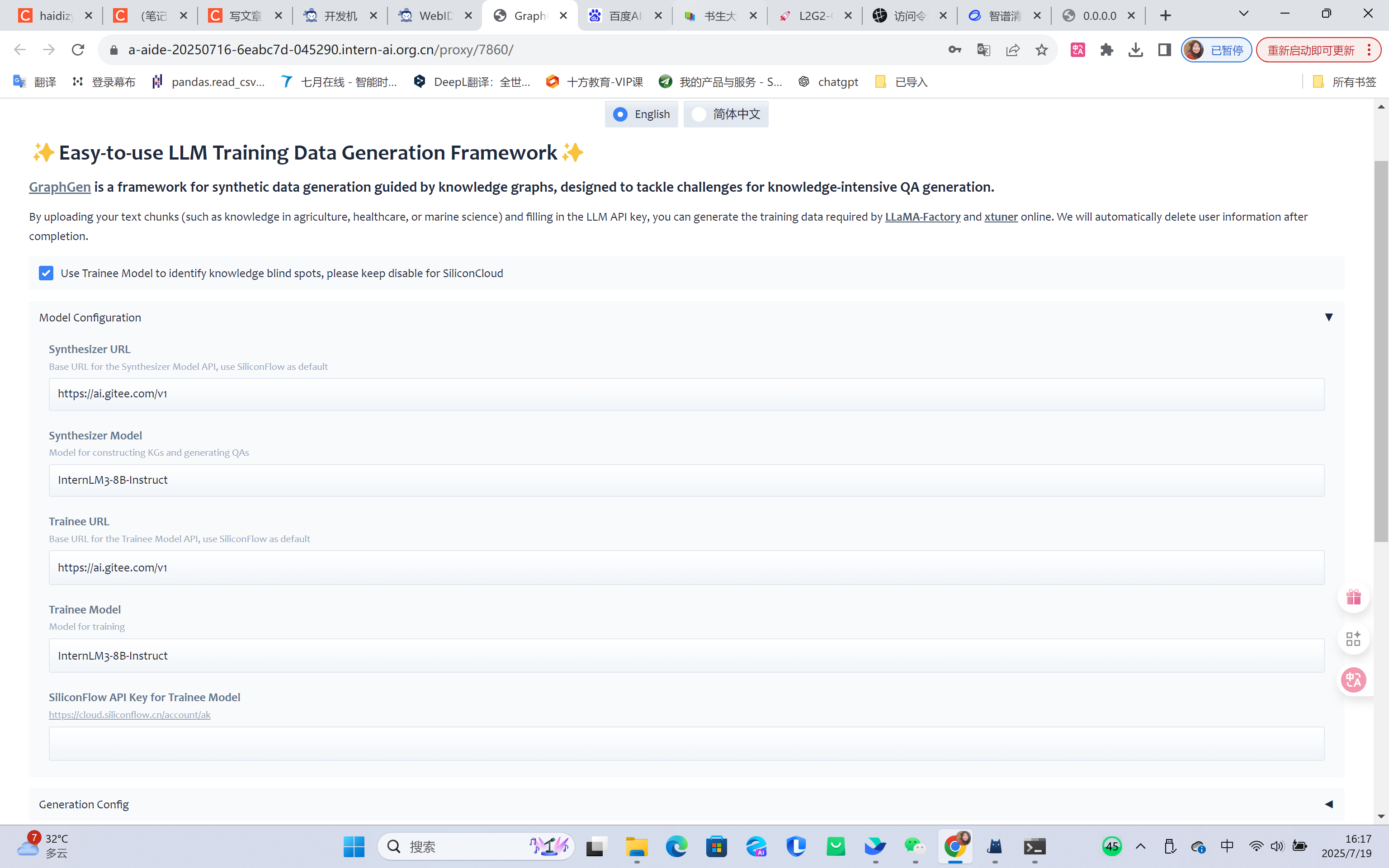
#1.端口映射,ssh root@ssh.intern-ai.org.cn -p 34002 -CNg -L 8080:127.0.0.1:7860
#打开 http://0.0.0.0:7860,能够看到如下界面,2. 填入调用LLM接口的base url、model和api key。从https://ai.gitee.com/serverless-api,前往 Gitee AI 工作台 - 设置 - 访问令牌,创建你的 API Key,
#使用 InternLM3-8B-Instruct 完成数据生成,分别修改下面三处:
#Synthesizer URL: https://ai.gitee.com/v1
#Synthesizer Model: InternLM3-8B-Instruct
#API Key: 申请的API Key
#2、使用硅基流动https://siliconflow.cn/,进入API密钥页面,点击"新建API密钥",创建您的API key,
#使用 internlm/internlm2_5-7b-chat 进行数据生成,分别修改下面三处:
#Synthesizer URL: https://api.siliconflow.cn/v1
#Synthesizer Model: internlm/internlm2_5-7b-chat
#3、选择任意一个example file,或者上传格式相同的文件
#4、点击Run GraphGen ,等待生成完成后,将会得到一个结果文件。无法访问github时替代方案,下面代码也不起作用,只能手动从github下载模型,再手动上传到开发机
bash
ssh-keygen -t rsa -C "haidizym@163.com"
cat ~/.ssh/id_rsa.pub
#登录 Gitee → 设置 → SSH 公钥 → 粘贴并保存
#将原 HTTPS 地址替换为 SSH 格式,
git init
git remote add origin git@gitee.com:open-sciencelab/GraphGen.git
git clone git@gitee.com:open-sciencelab/GraphGen.git
cd GraphGen3、运行源码进行数据合成
bash
#1.环境
conda create -n vllm python=3.12 -y
conda activate vllm
pip install vllm==0.8.5.post1
#2. 部署 internlm/internlm3-8b-instruct 的 OpenAI Compatible Server
#vllm serve internlm/internlm3-8b-instruct
vllm serve internlm/internlm3-8b-instruct --trust-remote-code --port 8000
cp .env.example .env
SYNTHESIZER_MODEL=your-path/internlm3-8b-instruct
SYNTHESIZER_BASE_URL=http://0.0.0.0:8000/v1
SYNTHESIZER_API_KEY=
TRAINEE_MODEL=your-path/internlm3-8b-instruct
TRAINEE_BASE_URL=http://0.0.0.0:8000/v1
TRAINEE_API_KEY=
#5. 检查/修改配置文件configs/graphgen_config.yaml
#运行数据生成脚本
bash scripts/generate.sh
#等待生成完成后可以在指定目录查看生成的数据,ls cache/data/graphgen
yaml
#5. 检查/修改配置文件configs/graphgen_config.yaml
data_type: raw
input_file: resources/examples/raw_demo.jsonl
tokenizer: cl100k_base
quiz_samples: 2
traverse_strategy:
qa_form: aggregated
bidirectional: true
edge_sampling: max_loss
expand_method: max_width
isolated_node_strategy: ignore
max_depth: 1
max_extra_edges: 2
max_tokens: 256
loss_strategy: only_edge
web_search: false
re_judge: true