背景
在使用OpenRouter调用Anthropic Claude大模型时,部分模型支持上下文缓存功能。当缓存命中时,调用成本会显著降低。虽然像DeepSeek这类模型自带上下文缓存机制,但本文主要针对构建Agent场景下,需要多次调用Anthropic Claude时的缓存设置策略。
缓存机制的价值
根据官方定价策略:
- 缓存设置:需要支付额外费用
- 缓存命中:可大幅降低调用成本
- 成本效益:在大量调用场景下,缓存命中能带来显著的成本节约
提示:可以通过OpenRouter账单中的调用历史费用来验证是否成功命中缓存。
官方缓存设置方法
根据官方文档的说明:
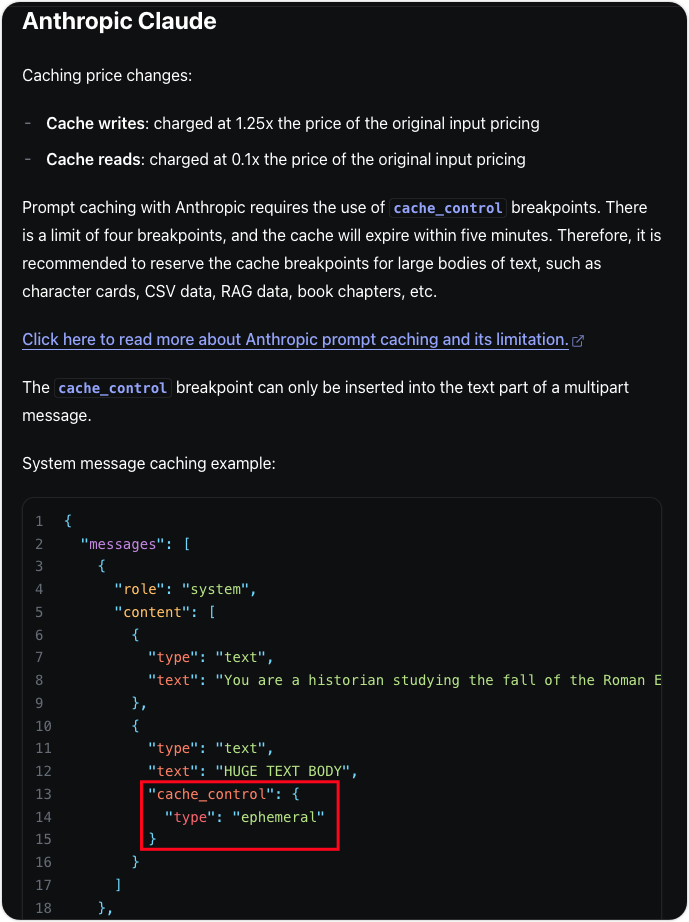
标准的缓存设置通过在消息中添加以下结构实现:
json
{
"cache_control": {
"type": "ephemeral"
}
}缓存机制原理:这是一个前缀缓存机制,即设置缓存的消息之前的所有消息都会被缓存。
现有问题与限制
经过实际测试发现:
✅ 有效场景 :在role为user的消息中设置缓存控制有效
❌ 无效场景 :在role为tool的消息中设置缓存控制无效(尽管Claude官方API支持)
注意:这个问题在OpenRouter社区中已有反馈,但目前尚未得到修复。
解决方案
针对工具调用后无法在tool消息中设置缓存的问题,我们采用添加用户消息的方式来绕过限制。
原始消息结构
json
[
{
"role": "system",
"content": [ {"type": "text", "text": "..."} ]
},
{
"role": "user",
"content": [
{ "type": "text", "text": "...", "cache_control": {"type": "ephemeral"} }
]
},
{
"role": "assistant",
"content": [ {"type": "text", "text": "..."} ],
"tool_calls": []
},
{
"role": "tool",
"tool_call_id": "...",
"name": "...",
"content": "..."
}, // 这里无法添加cache_control
{
"role": "assistant",
"content": [ {"type": "text", "text": "..."} ],
"tool_calls": []
}
]优化后的消息结构
json
[
{
"role": "system",
"content": [ {"type": "text", "text": "..."} ]
},
{
"role": "user",
"content": [
{ "type": "text", "text": "..."}
]
},
{
"role": "assistant",
"content": [ {"type": "text", "text": "..."} ],
"tool_calls": []
},
{
"role": "tool",
"tool_call_id": "...",
"name": "...",
"content": "..."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "function called",
"cache_control": {"type": "ephemeral"}
}
]
}, // 新增用户消息来设置缓存
{
"role": "assistant",
"content": [ {"type": "text", "text": "..."} ],
"tool_calls": []
}
]关键改进:
- 在工具调用后添加一个用户消息
- 消息内容使用"function called"等简单提示,避免改变对话语义
- 在此消息中设置缓存控制
重要注意事项
- 缓存设置上限 :Claude的
cache_control结构设置是有数量限制的 - 最佳实践:只需在最后一个用户消息中设置缓存即可,前面的消息会自动被缓存
- 成本优化:在高频调用场景下,合理使用缓存能显著降低API调用成本
总结
通过在工具调用后添加用户消息的方式,我们成功绕过了OpenRouter在tool消息中无法设置缓存的限制。这种方法在保持对话语义完整性的同时,实现了有效的缓存管理,为Agent应用的成本控制提供了实用的解决方案。