文章目录
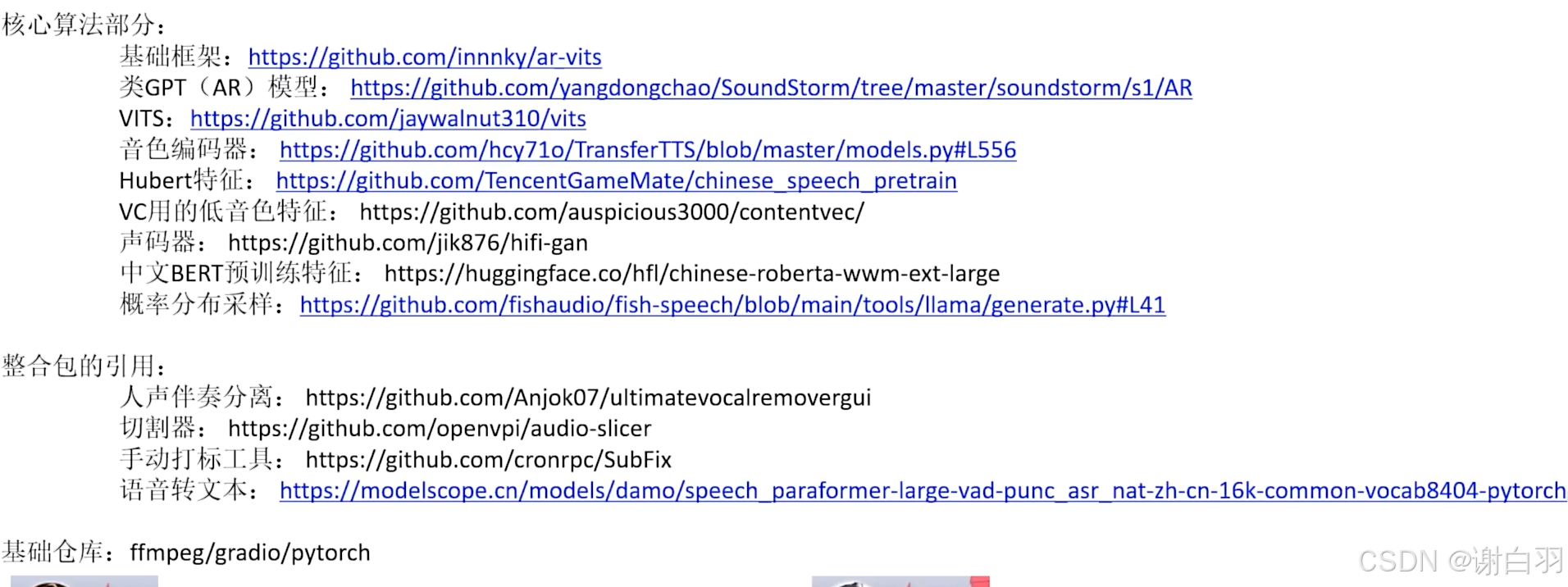
源码地址:https://github.com/RVC-Boss/GPT-SoVITS
文档
一、GPT-SoVITS特色
1)GPT-SoVITS项目特点
1、Zero-shot TTS: Input a 5-second vocal sample and experience instant text-to-speech conversion.
5秒钟克隆tts集外银色(不包含说话方式和咬字上的口癖)一般能80%到95%像
2、Few-shot TTS: Fine-tune the model with just 1 minute of training data for improved voice similarity and realism.
1分钟素材tts微调可以逼近真人(训练时间成本5~10分钟)
3、Cross-lingual Support: Inference in languages different from the training dataset, currently supporting English, Japanese, Korean, Cantonese and Chinese.
tts跨语言推理(已支持英文、日语、中文、汉语、粤语)
4、WebUI Tools: Integrated tools include voice accompaniment separation, automatic training set segmentation, Chinese ASR, and text labeling, assisting beginners in creating training datasets and GPT/SoVITS models.
独立可调试用的webUI页面调试工具
2)TTS定义
TTS(Text-To-Speech)这是一种文字转语音的语音合成。类似的还有SVC(歌声转换)、SVS(歌声合成)等。目前GPT-SoVITS只有TTS功能,也就是不能唱歌。
- 各版本特点
①GPT-SoVITS-V1实现了:
● 由参考音频的情感、音色、语速控制合成音频的情感、音色、语速
● 可以少量语音微调训练,也可不训练直接推理
● 可以跨语种生成,即参考音频(训练集)和推理文本的语种为不同语种
②GPT-SoVITS-V2新增特点:
● 对低音质参考音频合成出来音质更好
● 底模训练集增加到5k小时,zero shot性能更好音色更像,所需数据集更少
● 增加韩粤两种语言,中日英韩粤5个语种均可跨语种合成
● 更好的文本前端:持续迭代更新。V2中英文加入多音字优化。
③GPT-SoVITS-V3V4新增特点:
● 音色相似度更像,需要更少训练集来逼近本人(甚至不需要训练SoVITS)
● GPT合成更稳定,重复漏字更少,也更容易跑出丰富情感
● v4修复了v3非整数倍上采样可能导致的电音问题,原生输出48k音频防闷(而v3原生输出只有24k)。作者认为v4是v3的平替,更多还需测试。
二、克隆音色操作示例
- 步骤
①先去除背景音乐杂音
1)去除背景音乐(数据集处理):UVR5模型
- 用到的模型
①model_bs_roformer_ep_317_sdr_12.9755模型:提取人声
②onnx_dereverb最后用DeEcho-Aggressive:将输出的干声音频去混响 - 备注
model_bs_roformer_ep_317_sdr_12.9755(常简写为model_bs_roformer_ep_317_sdr_12)是UVR5中用于人声分离的关键模型之一13。该模型在UVR5中替换了原有的hp2模型,大幅提升了人声分离的效果3。用户需要将该模型文件(通常命名为Bs_Roformer.pth)放置在UVR5的指定模型目录下使用2。该模型属于MDX-Net架构系列,专门用于从音频中提取人声或伴奏,其性能指标SDR 12.9755代表了较高的音源分离质量1。安装后,用户可在UVR5的模型选择界面直接调用该模型进行人声分离操作2。 - 步骤
打开文件来到根目录,双击go-webui.bat打开,不要以管理员身份运行!
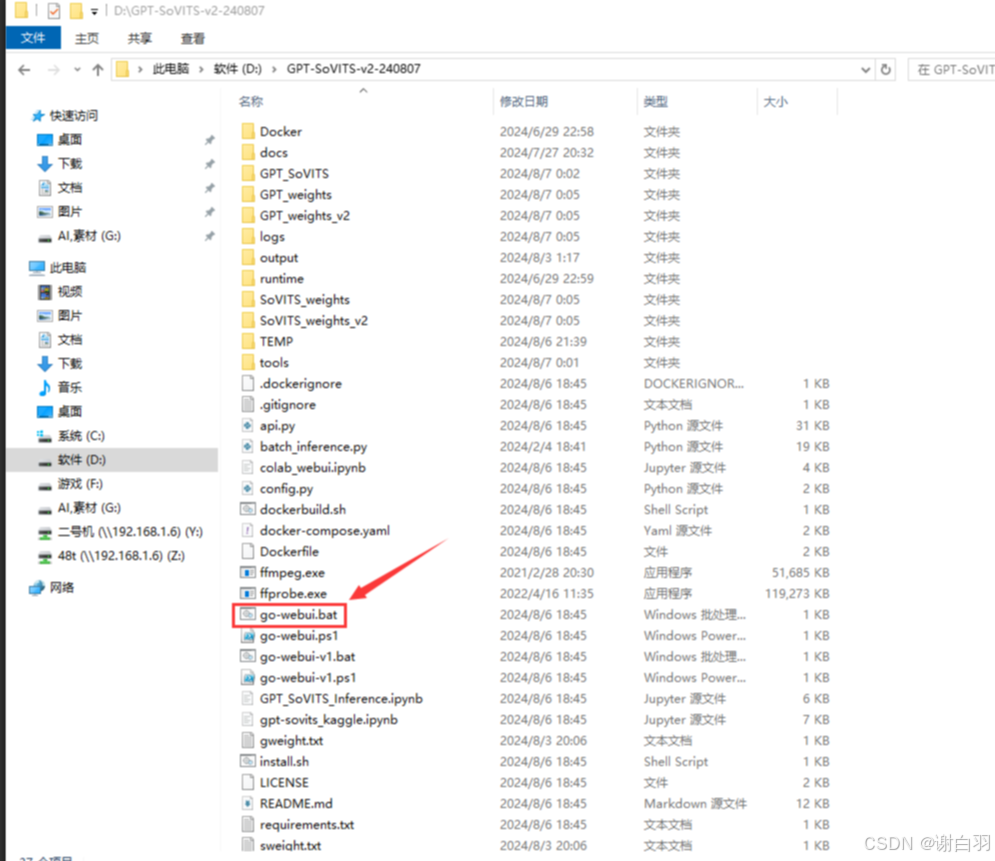
这就是正常打开了,稍加等待就会弹出网页。如果没有弹出网页可以复制http://0.0.0.0:9874到浏览器打开
在开始使用前先提醒一下大家:打开的bat不可以关闭!这个黑色的bat框就是控制台,所有的日志都会在这上面呈现,所有的信息以控制台为准。如果要向别人提问请写清楚:哪一步骤+网页端(方便看你填没填对)+控制台截图!所有的报错都在控制台上!Error后面的一般是报错
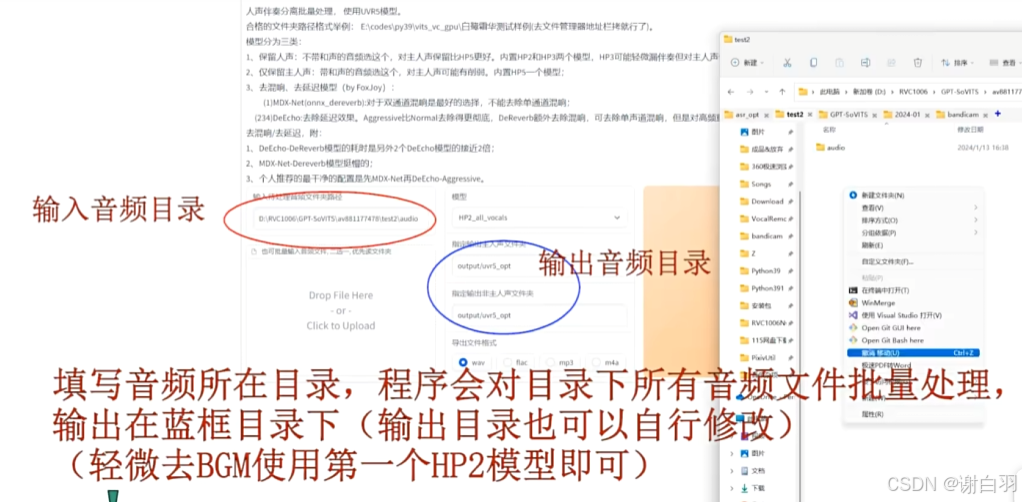
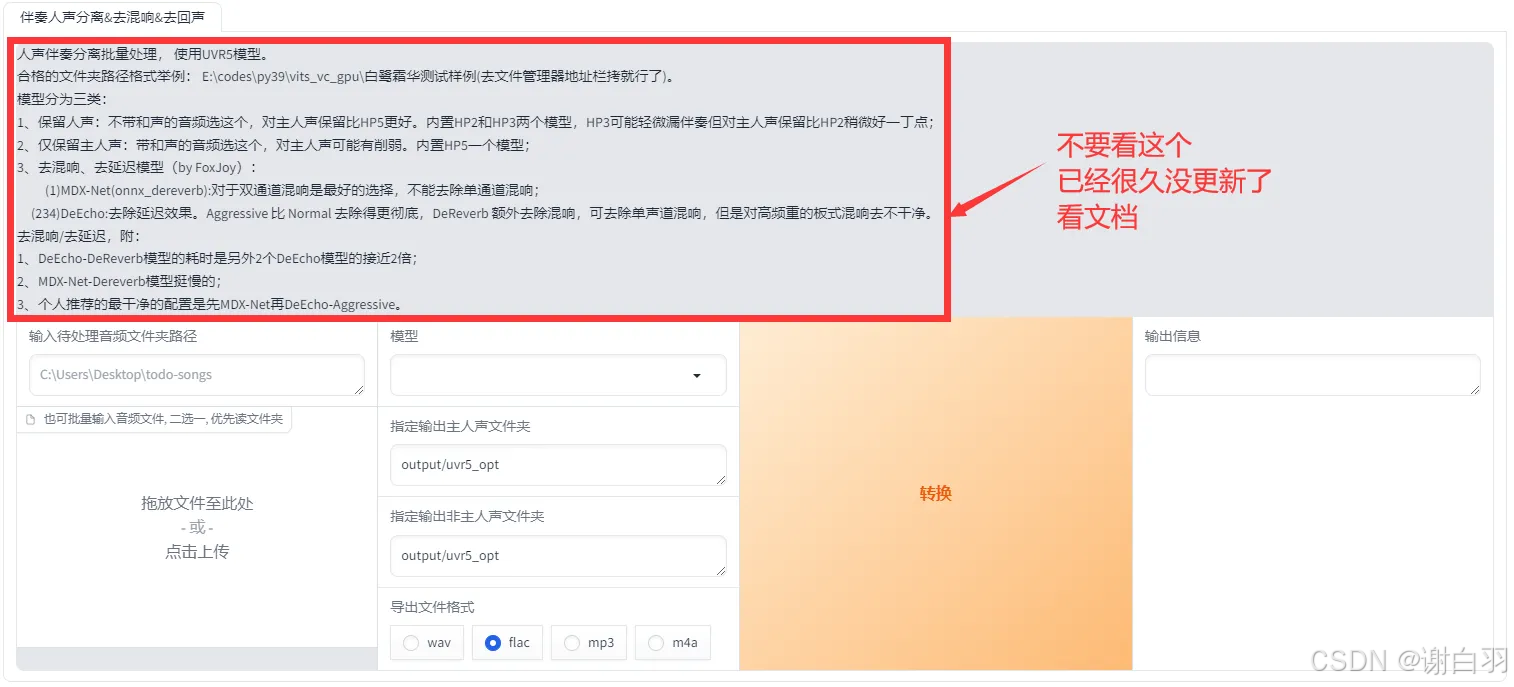
打开伴奏音频分离工具填写音频地址:
点击开启UVR5-WebUI稍加等待就会自动弹出图二的网页,如果没有弹出复制http://0.0.0.0:9873到浏览器打开

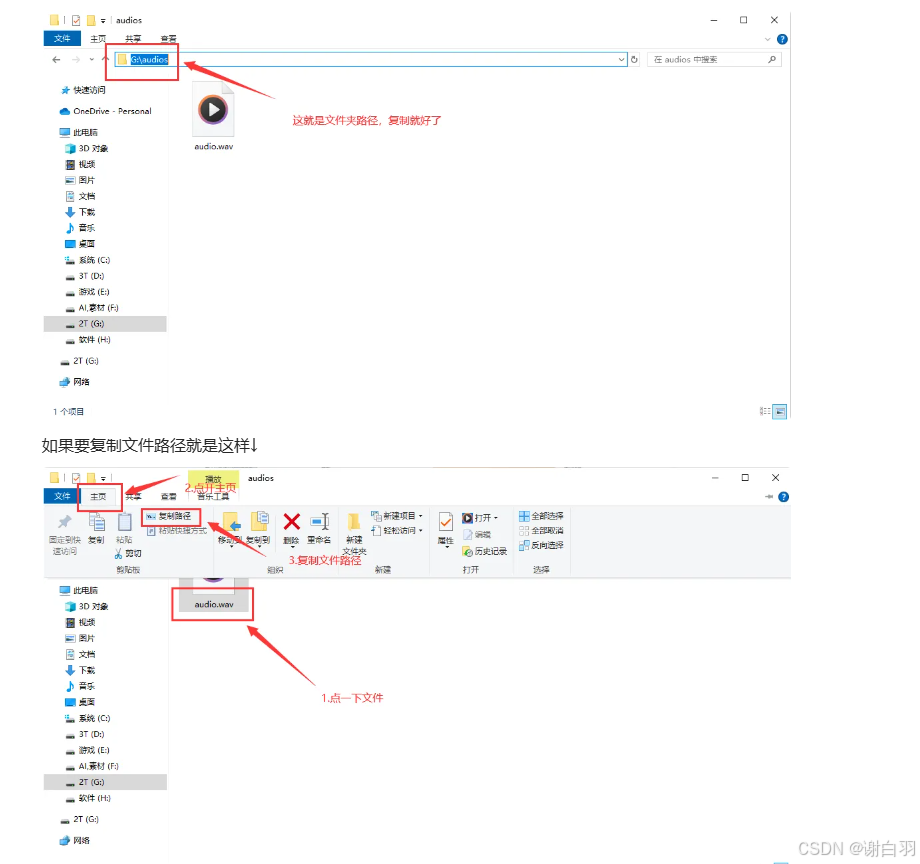
先用model_bs_roformer_ep_317_sdr_12.9755模型(已经是目前最好的模型)处理一遍(提取人声),然后将输出的干声音频再用onnx_dereverb最后用DeEcho-Aggressive(去混响),输出格式选wav。输出的文件默认在GPT-SoVITS-beta\output\uvr5_opt这个文件夹下,建议不要改输出路径,到时候找不到文件谁也帮不了你。处理完的音频(vocal)的是人声,(instrument)是伴奏,(_vocal_main_vocal)的没混响的,(others)的是混响。(vocal)(_vocal_main_vocal)才是要用的文件,其他都可以删除。结束后记得到WebUI关闭UVR5节省显存。
如果没有成功输出,报错了(现在版本应该不会报错了)。
那么推荐使用下面一种方法------UVR5客户端。
创建输入目录audio和输出目录vocal
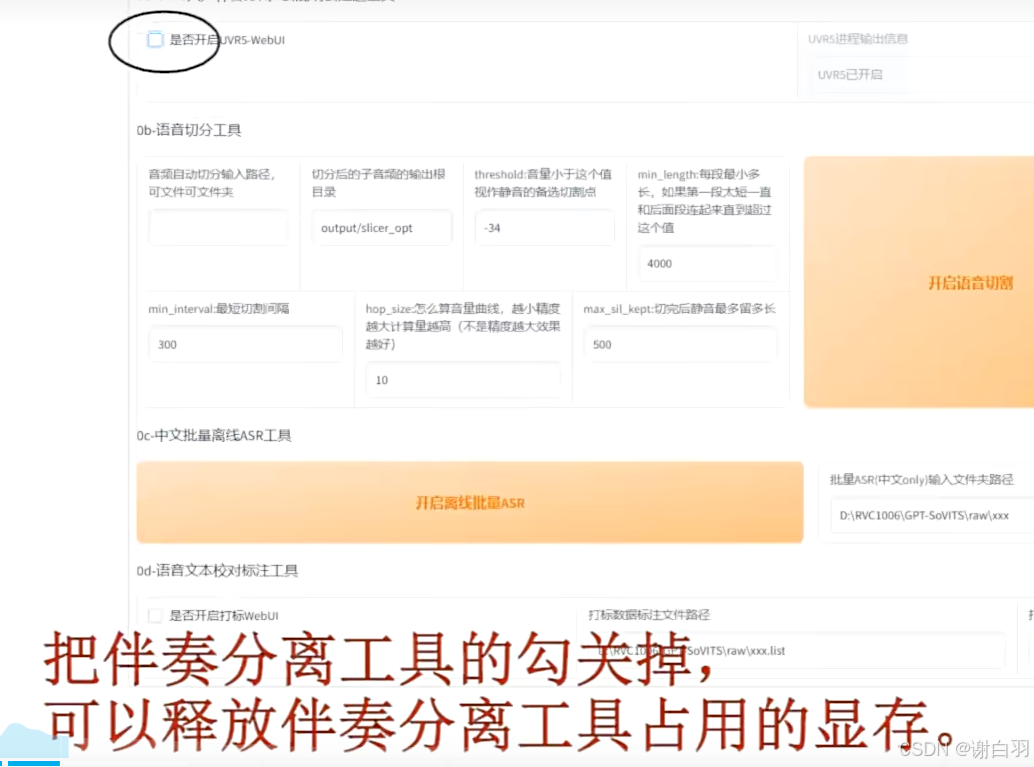
关闭分离工具的打钩节省显存
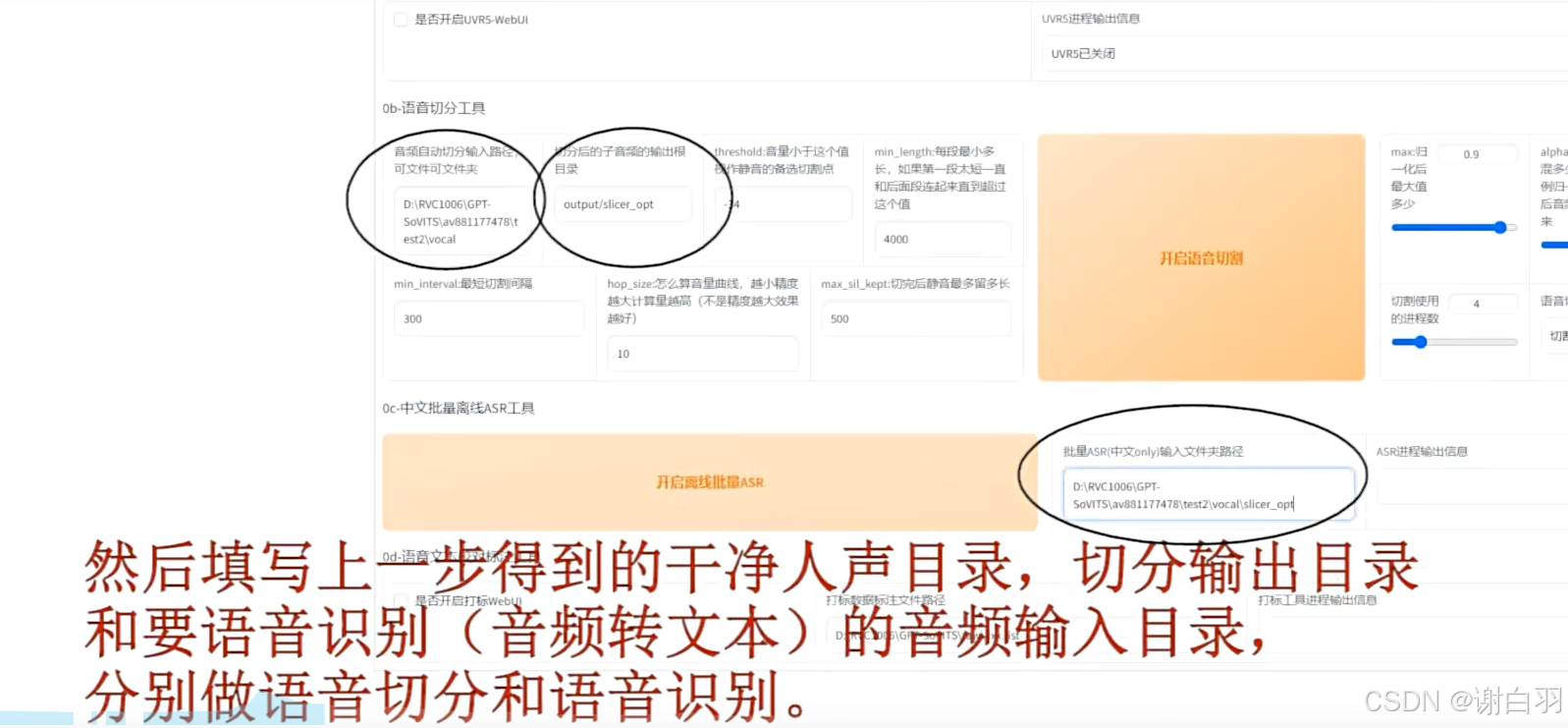
填写输入音频目录和切分输出目录、填写要语音识别(音频转文本)的音频输入目录,分别作语音切分和语音识别=》将原来语音切分后进行语音识别成文本
语音识别结果在output/asr_opt这个目录下能找到
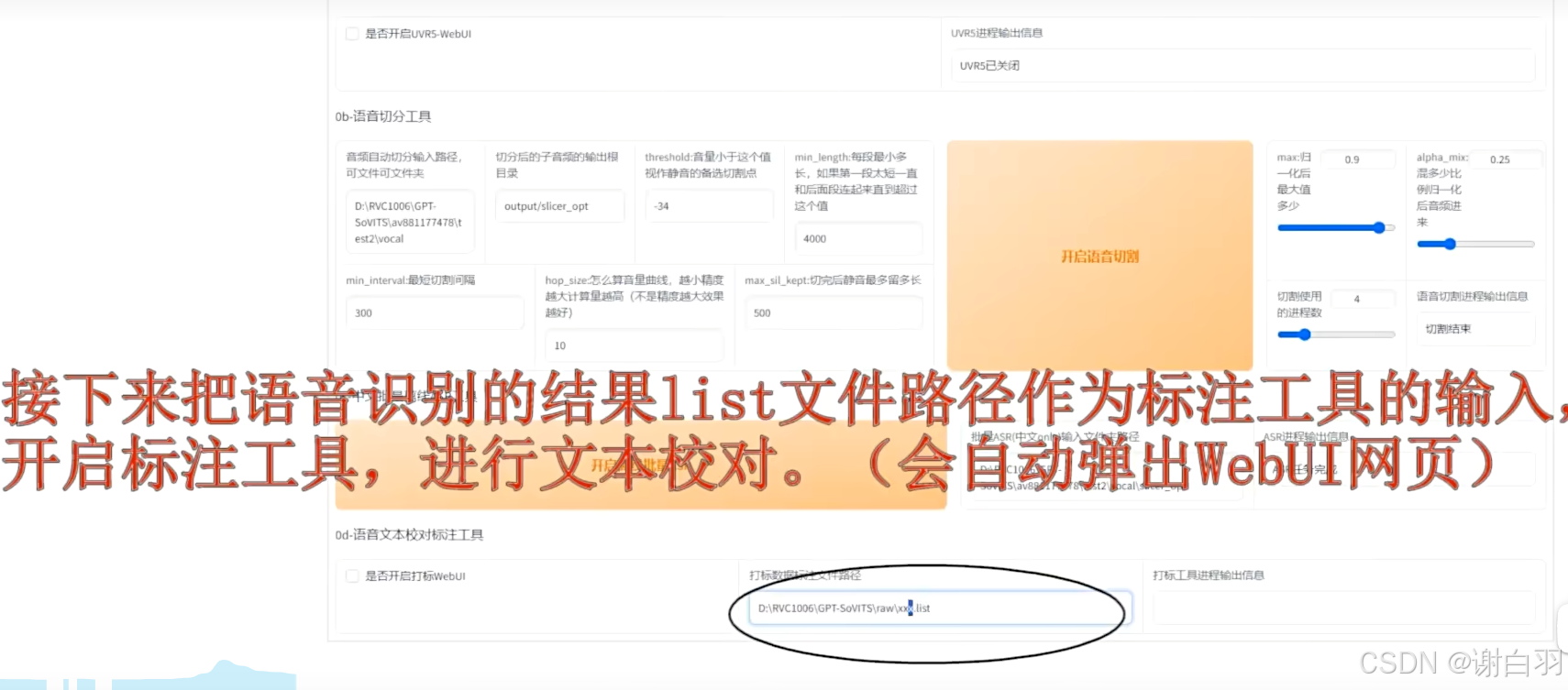
把语音识别的结果文件,也就是list文件作为标准工具的数据,用作文本校对,并打钩webUI

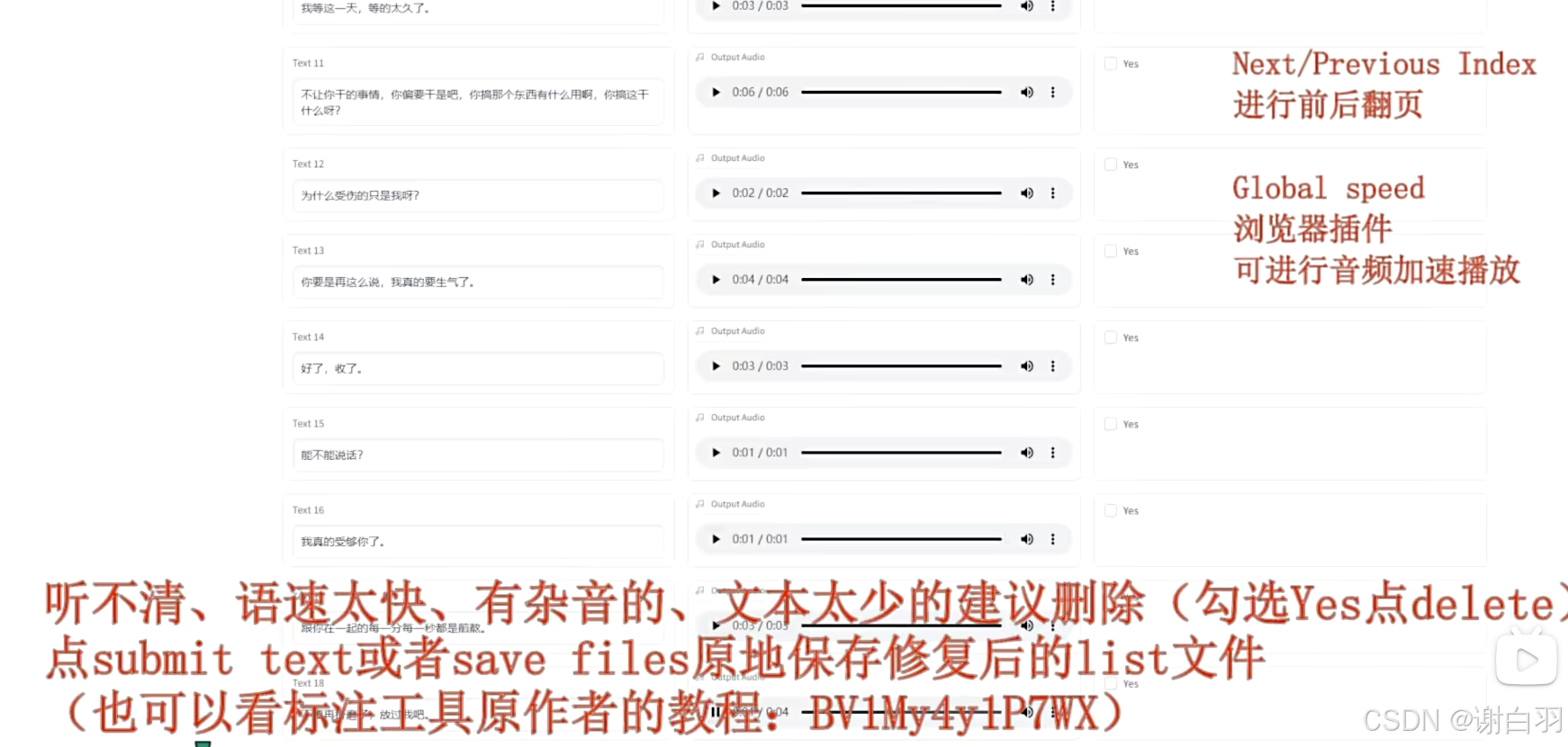
有杂音的或样本太少的文本建议删除
2)生成特征文件
得到文件后来到下一个目录
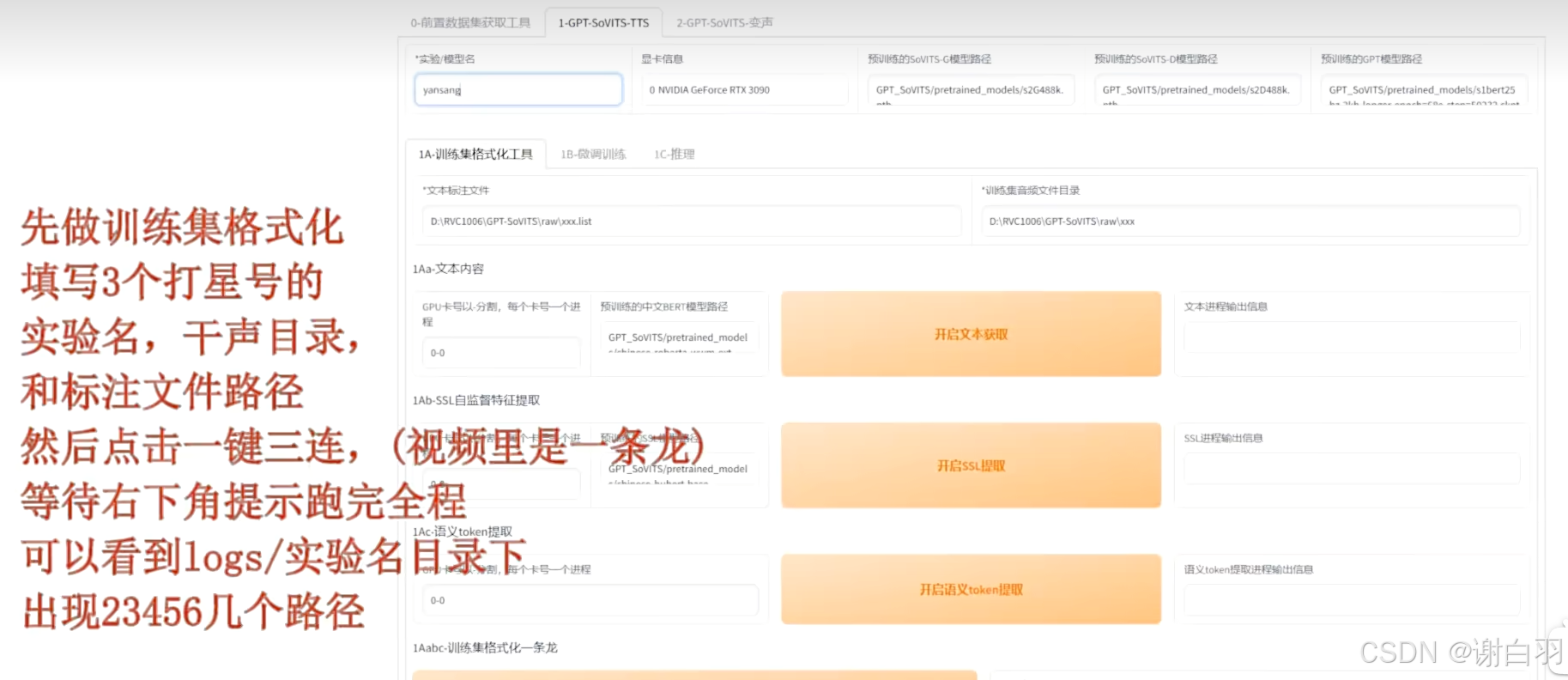
填写三个打*的地方
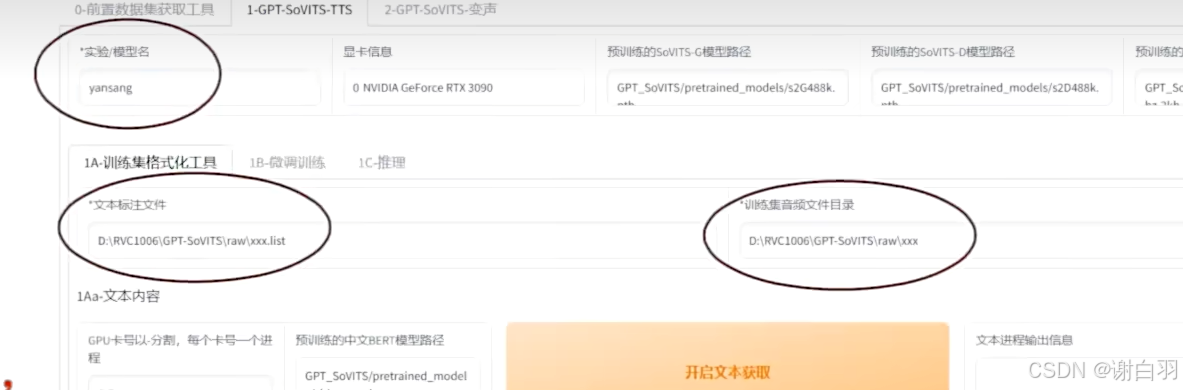
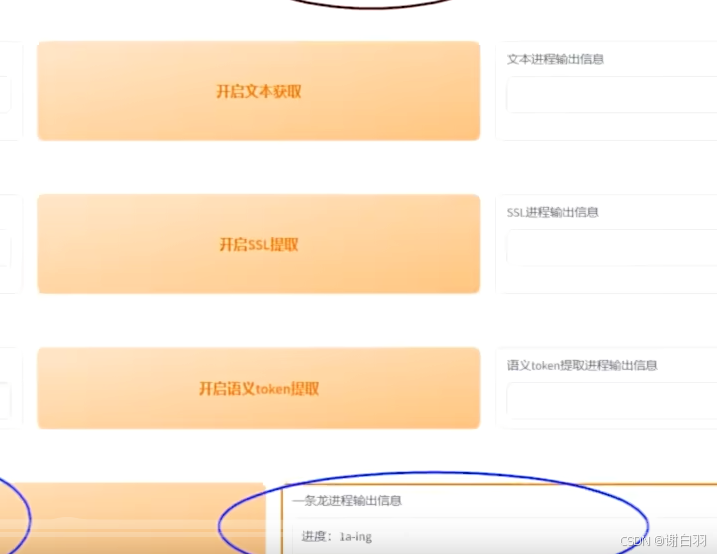
点击一键三连开始生成
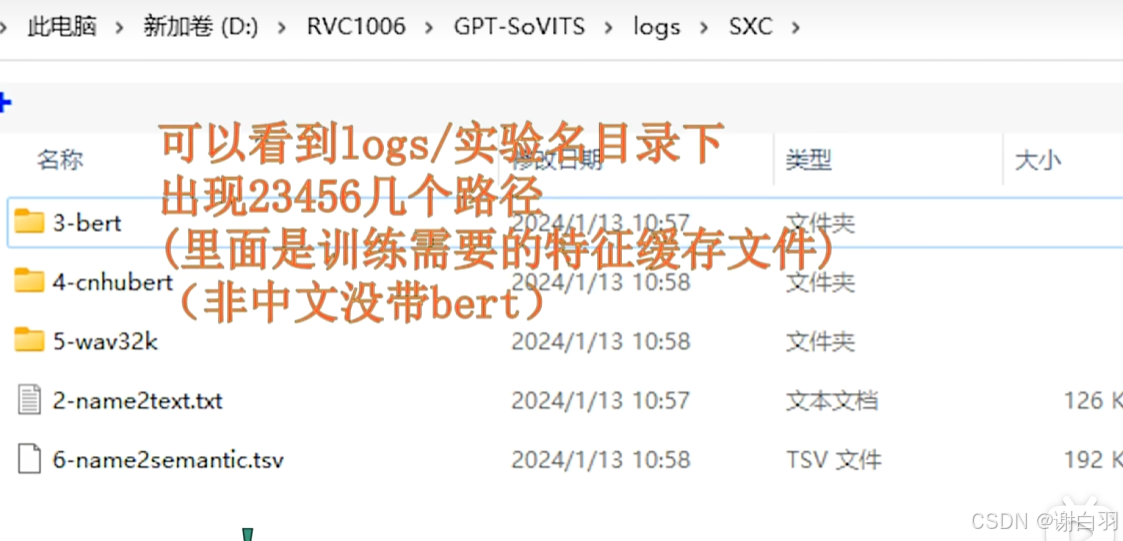
生成特征文件
3)分别进行两个子模型微调
顺序随意
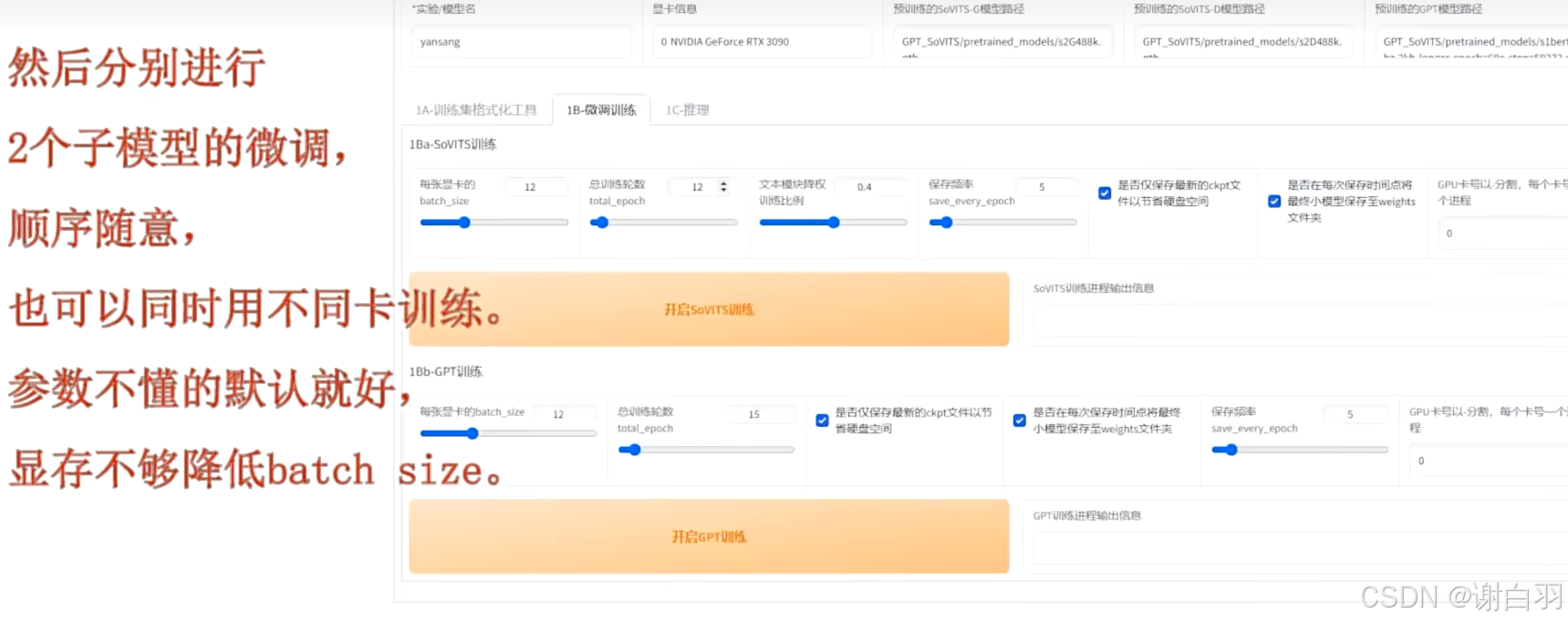
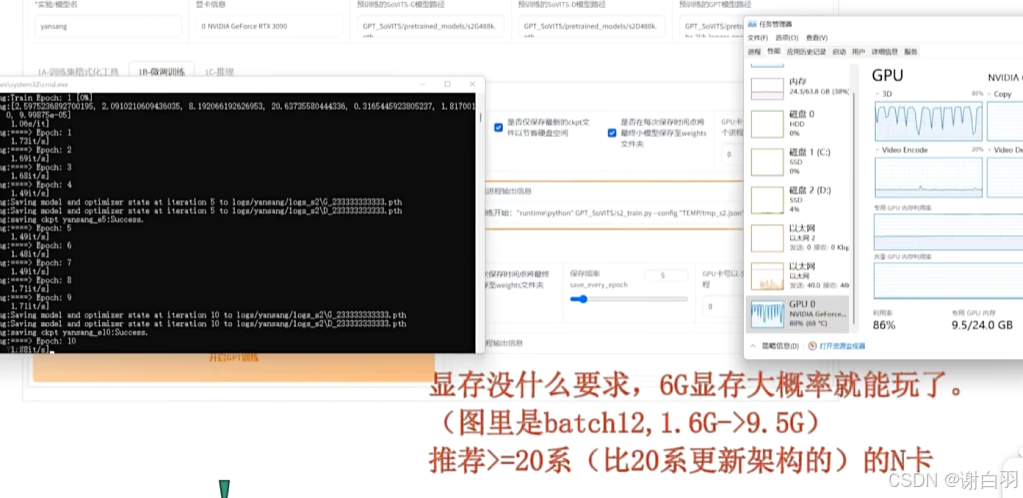
显存需求
4)推理界面试用
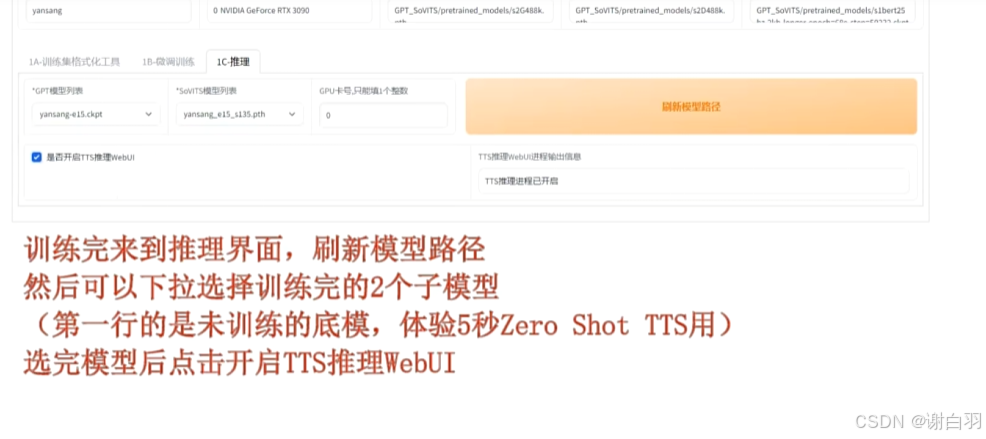
勾选点击按钮开始推理
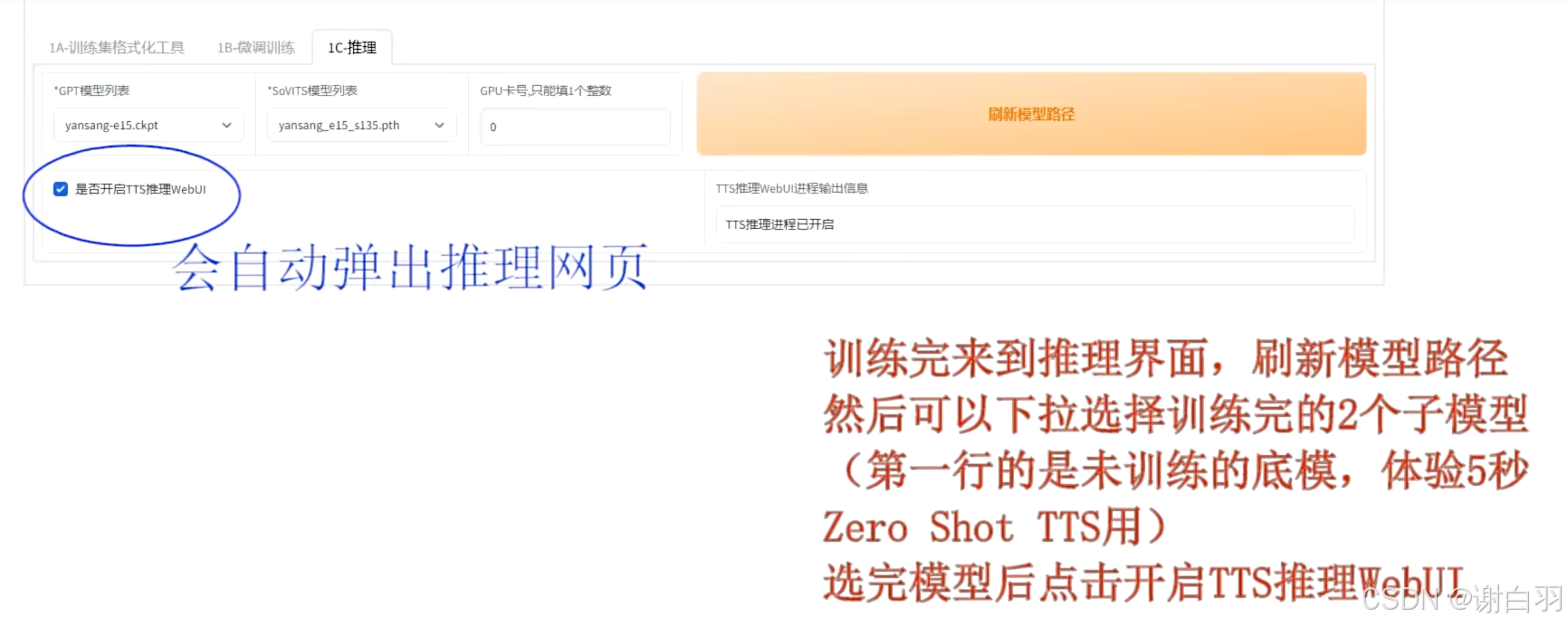
推理前需要上传目标音色的参考视频,并填写对应的文本和语种
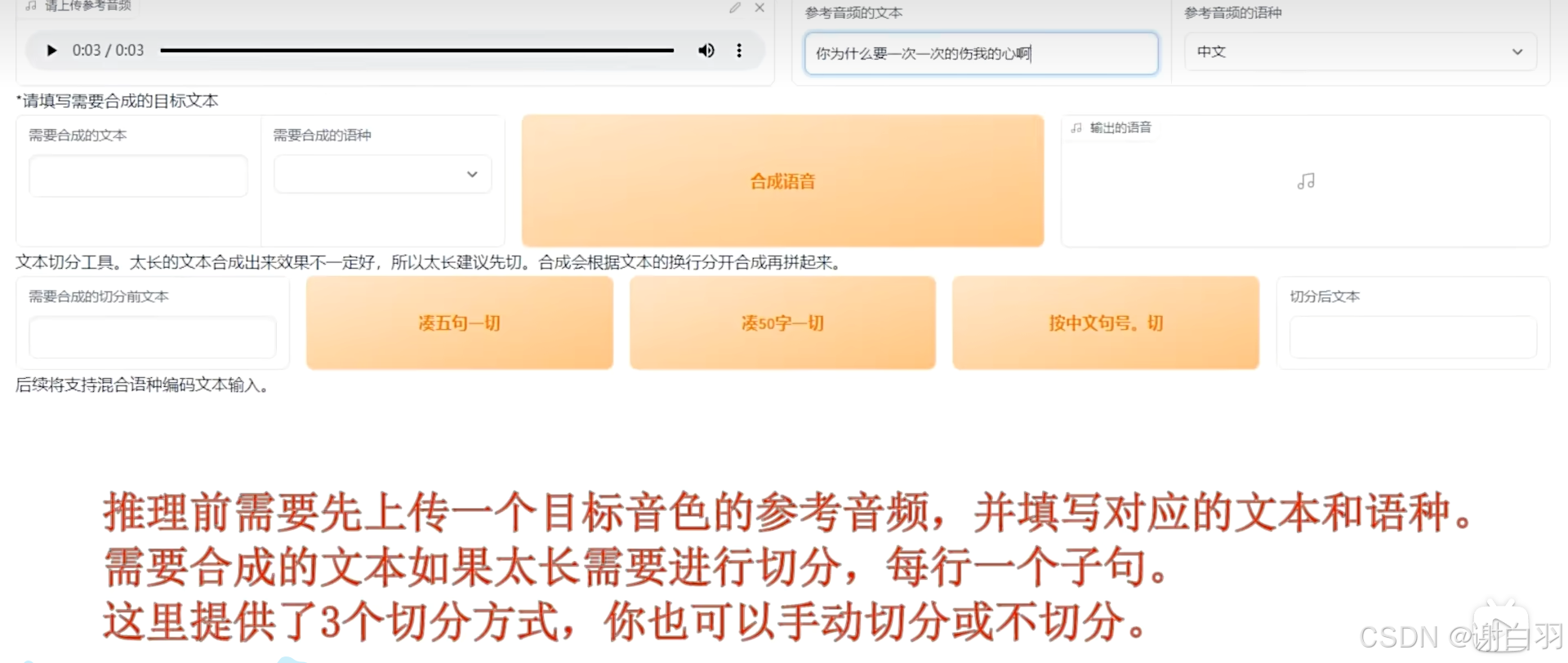
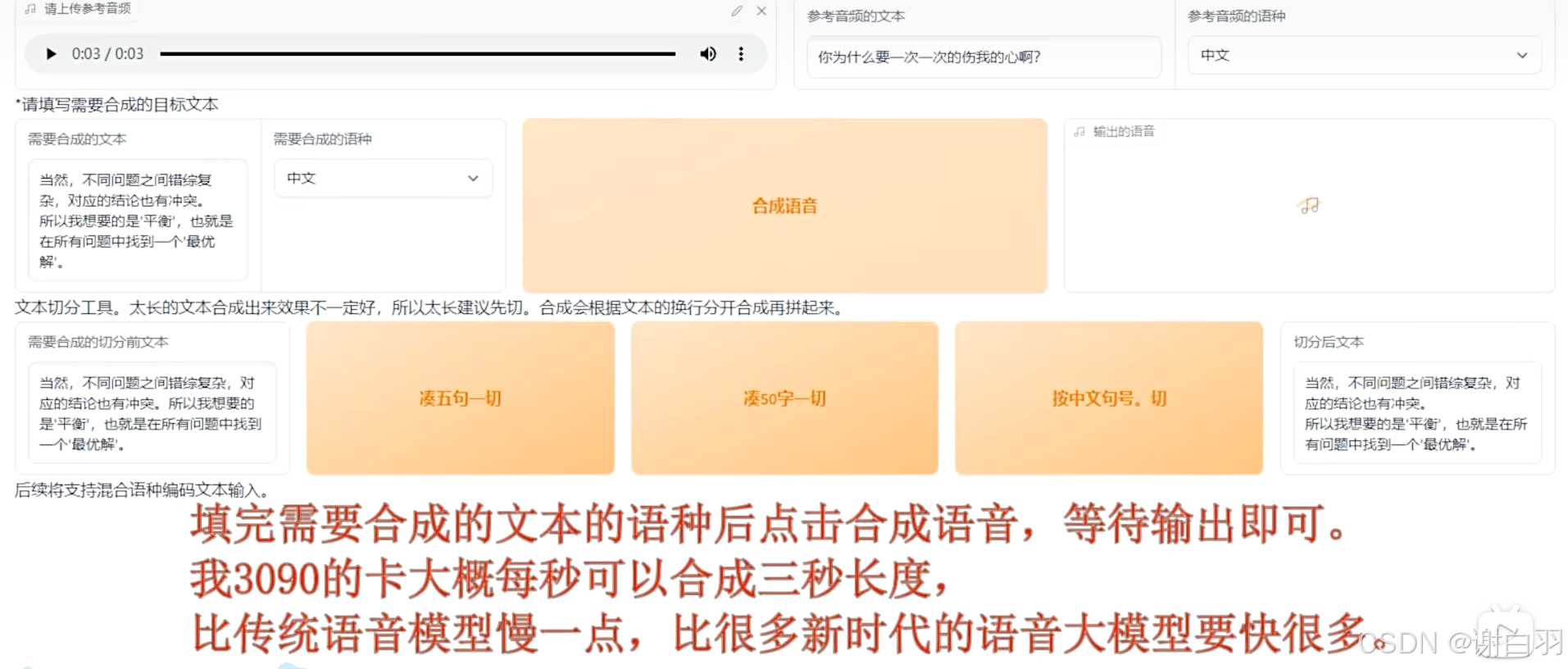
合成速度:3090每秒合成三秒长度

三、原理讲解
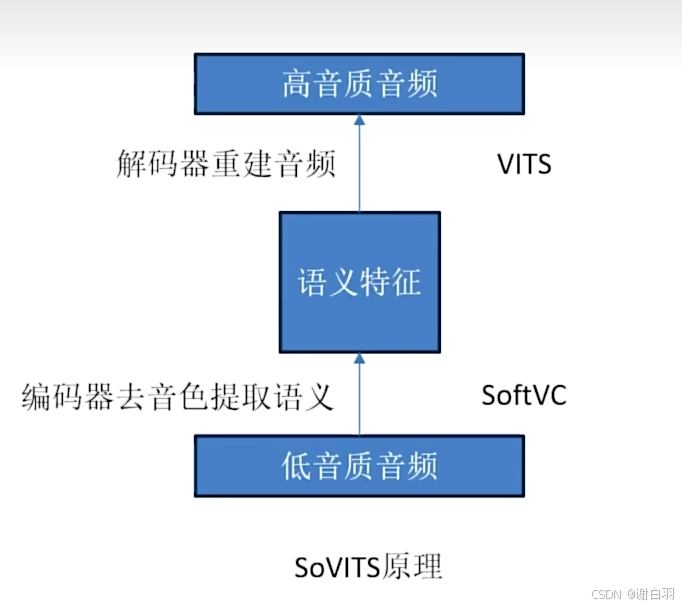
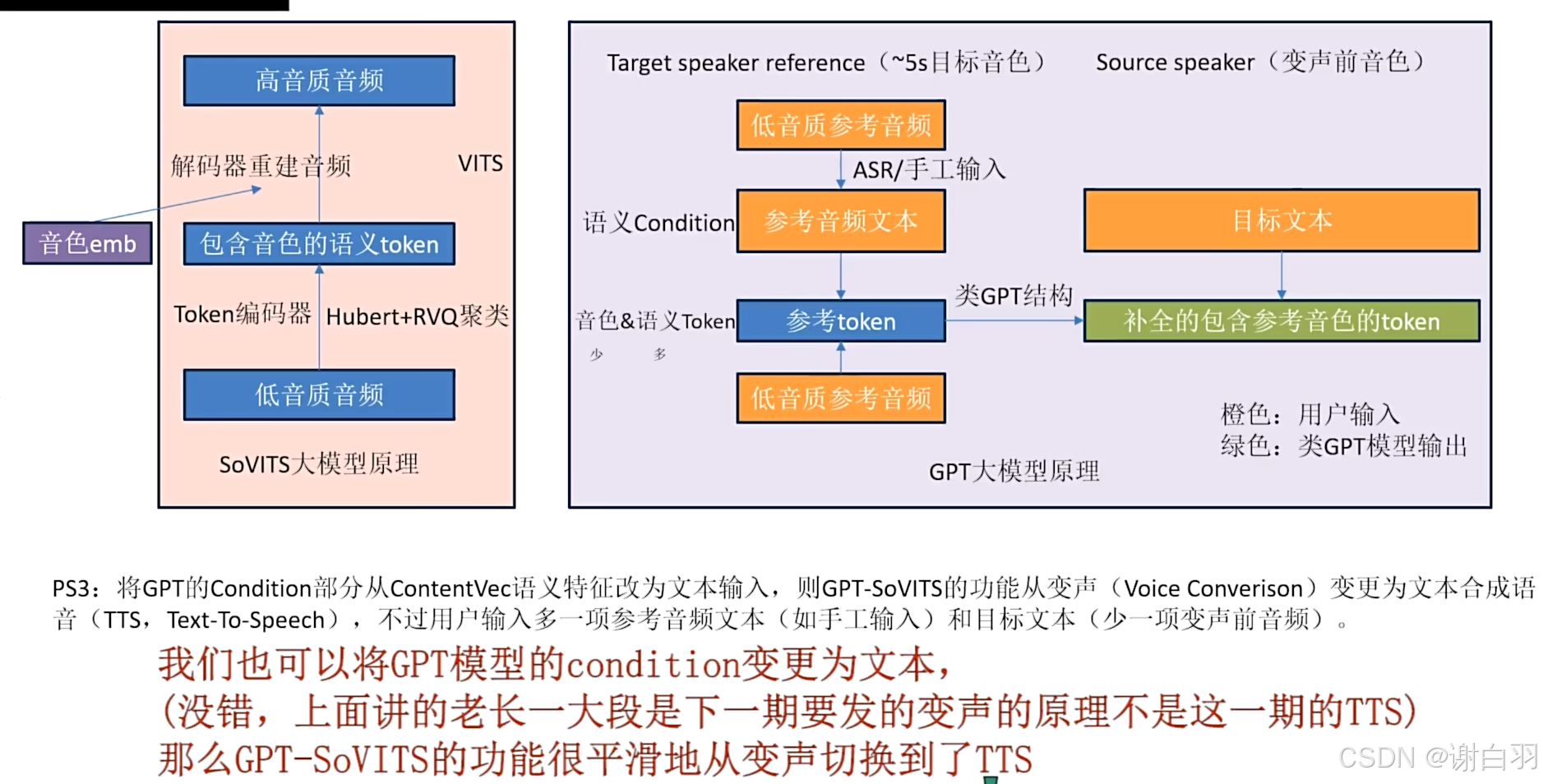
1)Sovits原理讲解
-
原理步骤
①首先通过softVC编码器去除音色
②然后通过VITS解码器重建音频
③在重建的过程中模型将训练集音色学习进它的参数中,因此输入其他音色的语音进过编码后,VITS模型也能重建出学习过的音色语音
-
最大的问题:
编码器encoder去除音色这一步,事实上目前没有完全去除音色的特征,只有去音色相对强的特征,这也是为什么sovit编码器最后选用ContentVec作为编码器的原因

-
露音色备注
转换音色失败,不是自己想要的
-
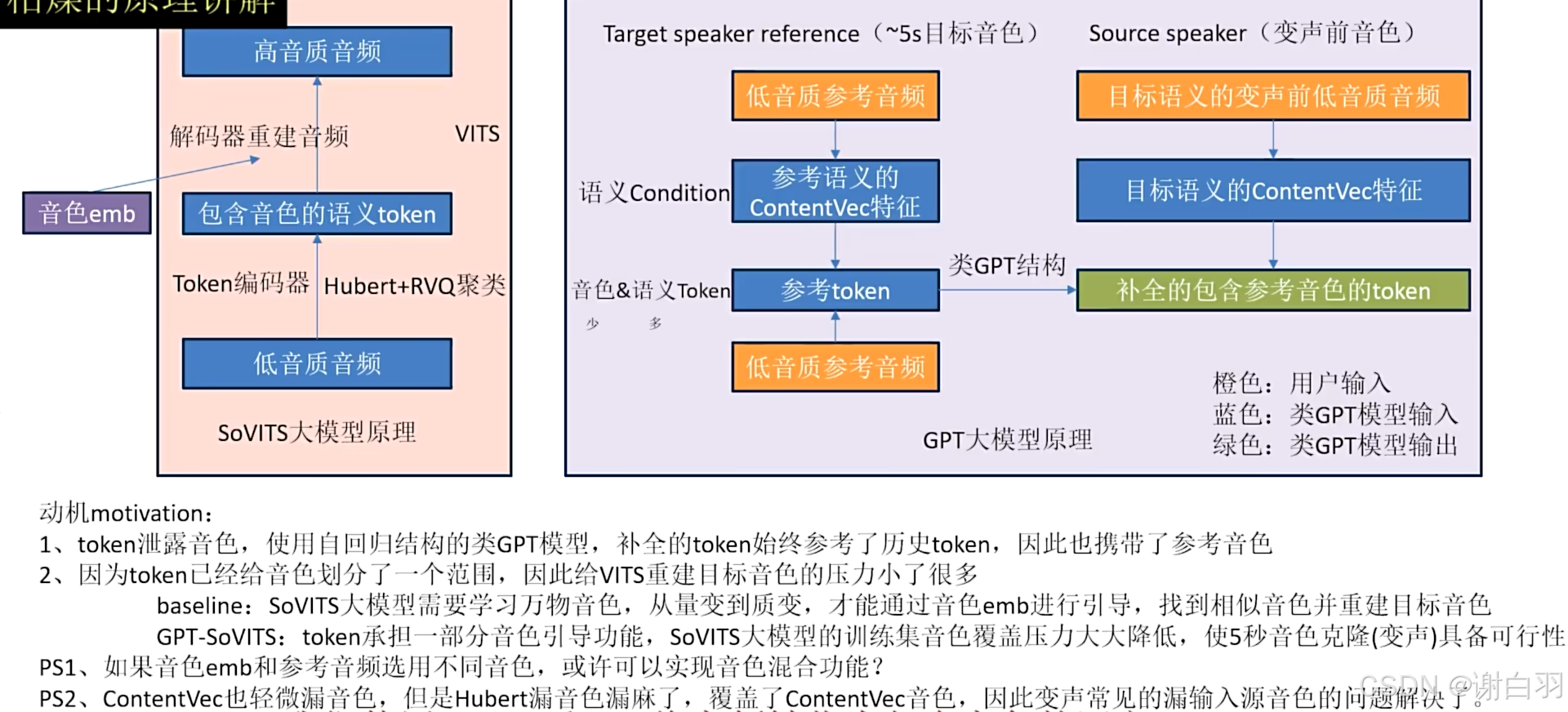
CN_Hubert音色引导作用(原始Hubert使用wenet中文数据训练)
保留丰富的音色信息反而成他的特色,结合RVQ将音频转化为包含音色的语义token,然后用类GPT模型将他补全
- 库目录
四、服务构建
1)环境安装(自动安装)
- 步骤
①安装conda并初始化conda环境
②开始安装其他环境
①安装conda并初始化conda环境
下载conda安装包
shell
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh安装miniconda
shell
bash Miniconda3-latest-Linux-x86_64.sh重新加载环境变量:
shell
source ~/.bashrc验证 conda 是否可用
shell
conda --versionconda环境
shell
export PATH=~/miniconda3/bin:$PATH
conda init
conda activate GPTSoVits②开始安装其他环境
这里我选择用install.sh脚本来安装依赖
shell
bash install.sh --device CU128 --source HF --download-uvr52)环境安装(手动安装)
①安装fast-whisper
shell
pip install -r extra-req.txt --no-deps -i https://mirrors.aliyun.com/pypi/simple/②安装一堆其他库
shell
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/③安装 FFmpeg
1)conda安装
shell
conda install ffmpeg2)Ubuntu/Debian Users
shell
sudo apt install ffmpeg
sudo apt install libsox-dev④模型下载
1)UVR5模型:
shell
UVR5模型
huggingface:
https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/uvr5_weights
iCloud(解压后替换tools/uvr5/uvr5_weights):
https://www.icloud.com/iclouddrive/04ai9bBzJJclEFpbrbd_plmtA#uvr5_weights
2)pretrain_model预训练模型:
shell
huggingface:
https://huggingface.co/lj1995/GPT-SoVITS/tree/main
iCloud(解压后放到GPT_SoVITS/pretrained_models下):
https://www.icloud.com/iclouddrive/0cb2YLuaLd4xBMslvMRnWcX0g#pretrained_models