点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-30-新发布【1T 万亿】参数量大模型!Kimi‑K2开源大模型解读与实践,持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年07月21日更新到:
Java-77 深入浅出 RPC Dubbo 负载均衡全解析:策略、配置与自定义实现实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节我们完成了:
- Redis 通信协议
- Redis 响应模式:串行模式、双工模式
- Redis 数据格式
- 处理流程、处理机制、文件事件
- Reactor 多路复用等基础概念
缓存穿透
问题描述
在标准的缓存系统架构中,当应用程序需要获取某个数据时,会先按照Key去缓存层查询。如果缓存中不存在对应的Value(缓存未命中),系统就会向后端数据库发起查询请求。
在高并发场景下,如果大量请求同时查询一个根本不存在的数据(如恶意攻击者故意构造的随机Key),就会导致以下严重后果:
- 这些无效请求会直接穿透缓存层,全部落到数据库上
- 数据库需要处理远超其负载能力的查询请求
- 最终可能导致数据库连接池耗尽,系统响应变慢甚至完全宕机
解决方案
1. 空结果缓存
- 实施方式:当查询某个Key返回空结果时,仍然将这个"空结果"存入缓存
- 缓存时间设置 :
- 可以设置较短的TTL(如30-60秒)
- 或者在Key对应的数据被INSERT操作后主动清理该缓存
- 优势:简单直接,不需要引入额外组件
- 适用场景:适用于业务数据量不大,且空查询相对固定的场景
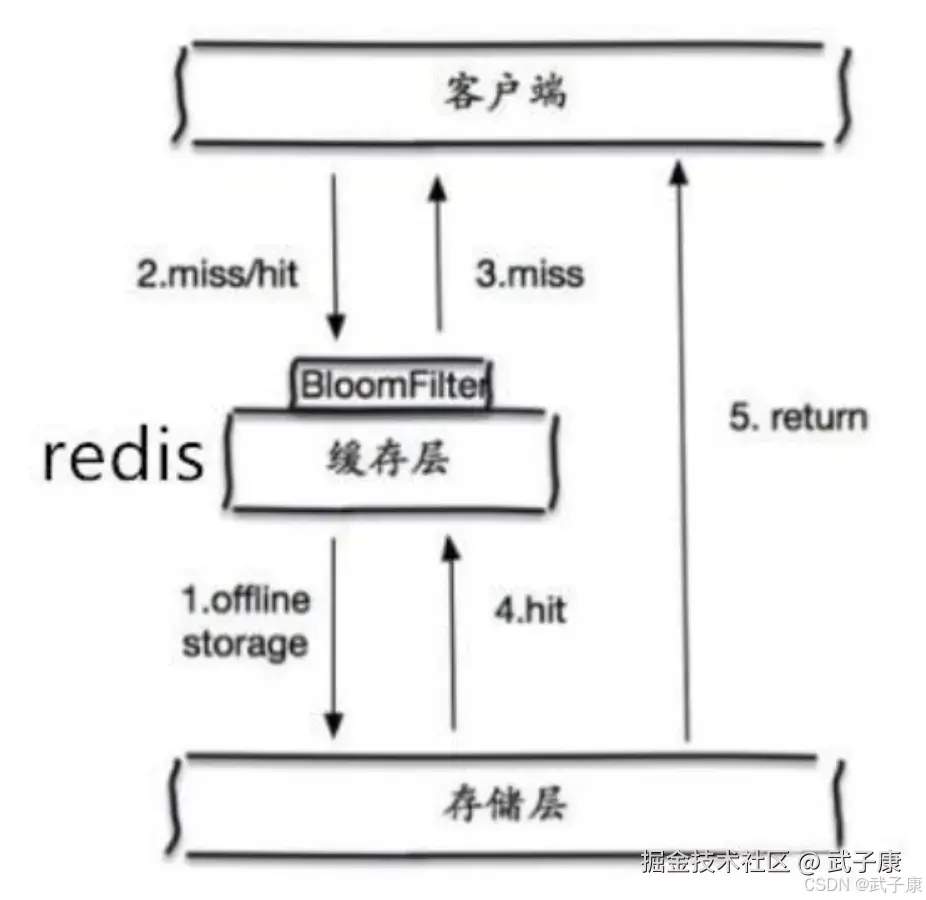
2. 布隆过滤器
- 实现原理 :
- 在缓存层之前增加布隆过滤器层
- 将所有有效Key预先存入布隆过滤器
- 查询时先检查布隆过滤器
- 工作流程 :
- 请求到达时,先在布隆过滤器中检查Key是否存在
- 如果布隆过滤器返回"不存在",则直接返回空结果
- 只有布隆过滤器返回"可能存在"时,才继续查询缓存/数据库
- 注意事项 :
- 可能存在一定的误判率(但不会漏判)
- 需要定期重建布隆过滤器以同步数据变更
- 适用场景:适用于数据量大、且空查询较多的场景
3. 额外防护措施(补充)
- 接口限流:对查询接口实施限流措施,防止大量并发请求
- 参数校验:对查询Key做格式校验,过滤明显不合法的请求
- 热点监控:实时监控系统热点,及时发现异常查询模式
布隆过滤器
布隆过滤器(Bloom Filter)是由 Burton Howard Bloom 在1970年提出的,它是一种空间效率极高的概率型数据结构。其核心由两部分组成:一个很长的二进制向量(位数组)和一系列独立且均匀分布的随机哈希函数。
基本原理
-
初始化阶段:
- 创建一个长度为m的位数组,所有位初始化为0
- 选择k个不同的哈希函数,每个函数都能将输入元素映射到位数组的某个位置
-
添加元素:
- 当添加一个新元素时,通过k个哈希函数计算出k个哈希值
- 将这些哈希值对应的位数组位置设为1
- 例如:添加元素"hello",假设3个哈希函数分别映射到位置2、5、9,则将这些位置置1
-
查询元素:
- 查询元素是否存在时,同样用k个哈希函数计算k个位置
- 如果任意一个位置的值为0,则确定该元素不存在
- 如果所有位置都是1,则该元素可能存在(存在误判可能)
特性分析
-
优点:
- 空间效率极高:相比传统数据结构,可以节省大量存储空间
- 查询时间恒定:无论元素数量多少,查询都是O(k)时间复杂度
- 安全性:存储的是哈希值而非原始数据
-
缺点:
- 存在误判率(false positive):可能误判不存在的元素为存在
- 不能删除元素:标准布隆过滤器不支持删除操作
-
误判率计算: 误判率p ≈ (1 - e^(-kn/m))^k 其中:
- m:位数组大小
- n:已插入元素数量
- k:哈希函数个数
应用场景
- 网页爬虫URL去重:避免重复爬取相同URL
- 垃圾邮件过滤:快速判断邮件地址是否在黑名单中
- 缓存穿透防护:在查询数据库前先检查布隆过滤器
- 分布式系统:如Cassandra、HBase等数据库用其判断数据是否存在
参数优化建议
为了获得最佳性能,建议:
- 位数组大小m和元素数量n的比例应在10:1左右
- 最优哈希函数数量k ≈ (m/n)ln2
- 实际使用中通常选择3-5个哈希函数
变体改进
- 计数布隆过滤器:通过使用计数器替代二进制位,支持删除操作
- 动态布隆过滤器:可以动态调整大小以适应元素数量的变化
- 分层布隆过滤器:通过多层过滤提高准确性
在实际应用中,布隆过滤器通常作为第一道"防线",配合其他数据结构使用,在保证性能的同时降低误判带来的影响。 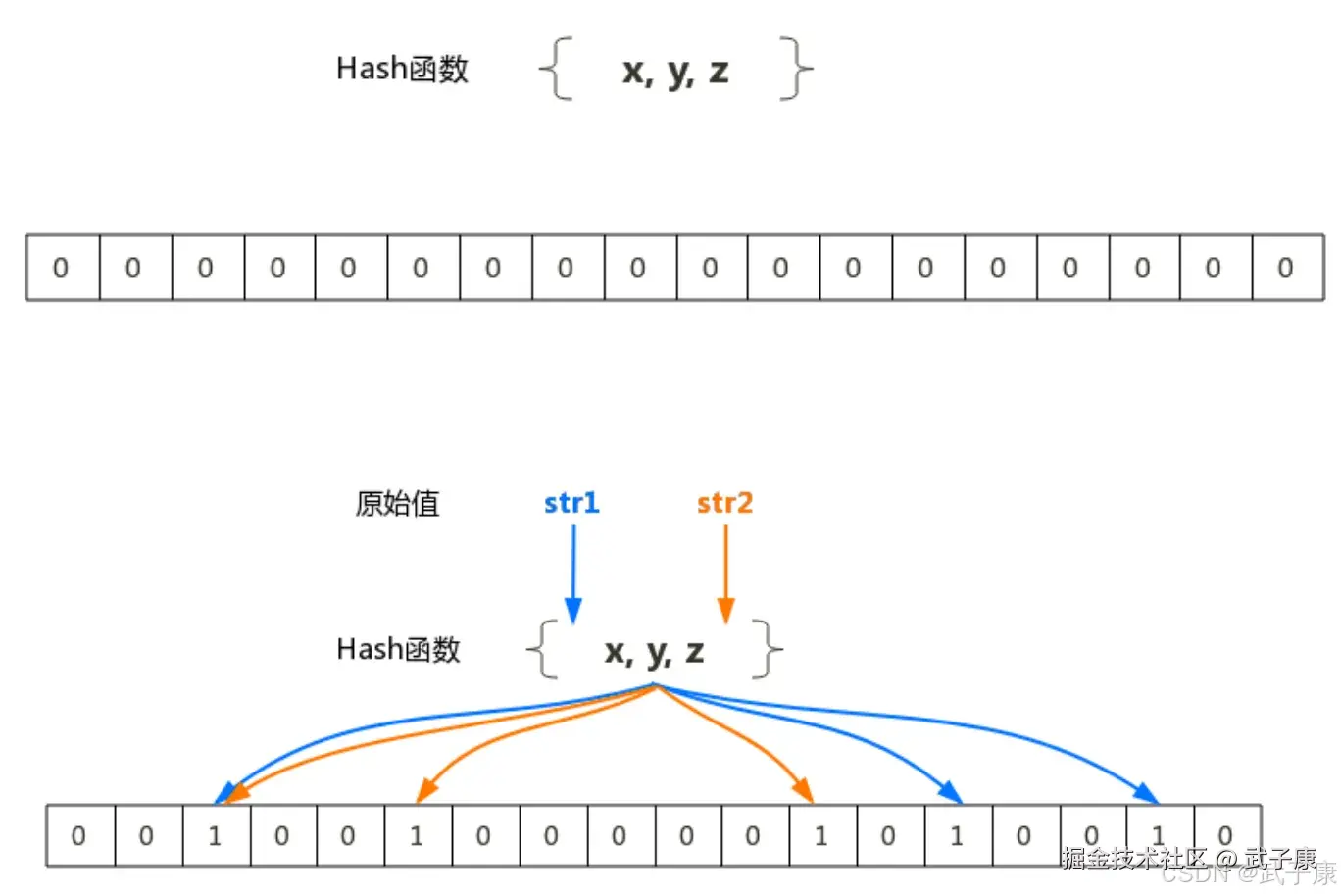
缓存雪崩
问题描述
缓存雪崩是指当缓存服务器因重启、宕机或压力过大无法提供服务时,原本应该由缓存承担的请求会全部涌入数据库。这会导致数据库短时间内承受远超其处理能力的请求量,最终引发数据库连接池耗尽、响应延迟飙升,甚至导致数据库完全崩溃的连锁反应。
典型场景包括:
- 缓存集群整体重启时
- 大量缓存同时失效时(如设置相同过期时间)
- 突发流量导致缓存服务器过载宕机
- 网络分区导致缓存不可用
解决方案
1. 分散缓存失效时间
- 对于相同业务逻辑的缓存key,不要设置完全相同的过期时间
- 可采用基础过期时间+随机偏移量的方式,例如:
expireTime = baseTime + random(0, 300)s - 示例:电商商品缓存可设置30分钟±5分钟的随机过期时间
2. 构建多级缓存体系
- 一级缓存:本地缓存(如Caffeine/Guava Cache)
- 二级缓存:分布式缓存(如Redis集群)
- 三级缓存:持久化存储(数据库)
- 各级缓存设置不同的过期策略,逐级回源
3. 实现缓存高可用
- 部署Redis Sentinel或Cluster保证服务可用性
- 采用读写分离架构减轻主节点压力
- 对缓存进行分片处理,避免单点故障影响全局
- 实施熔断降级机制(如Hystrix),在缓存不可用时快速失败
4. 其他优化措施
- 预热热点数据:在系统低峰期提前加载重要缓存
- 实现互斥锁:避免大量请求同时重建缓存
- 设置缓存永不过期,通过后台任务定期更新
- 监控缓存命中率,设置自动告警机制
缓存击穿
问题描述
缓存击穿是指在高并发场景下,某些热点数据(设置了过期时间的key)在缓存刚好过期的瞬间,突然有大量并发请求同时访问这些数据的情况。由于缓存中数据已经过期失效,这些请求会直接穿透缓存层,全部打到后端数据库(DB)上,导致数据库瞬时压力骤增,甚至可能造成数据库崩溃。
这种情况通常发生在以下场景:
- 电商平台的热门商品页面
- 新闻网站的突发新闻详情页
- 秒杀活动中的热门商品信息
- 社交平台的热门话题数据
这些数据的特点是:
- 访问量非常大
- 缓存设置了合理的过期时间
- 在过期时刻容易形成访问高峰
解决方案
1. 分布式锁控制线程访问
实现原理: 当缓存失效时,首先获取分布式锁,只有获取到锁的线程才能访问数据库并重建缓存,其他线程等待或重试。
具体步骤:
- 请求查询缓存,发现数据不存在或已过期
- 尝试获取分布式锁(如Redis的SETNX)
- 获取锁成功的线程:
- 查询数据库获取最新数据
- 将数据写入缓存
- 释放分布式锁
- 获取锁失败的线程:
- 短暂等待后重试查询缓存
- 或者直接返回默认值/错误信息
优点:
- 有效防止大量请求同时击穿缓存
- 保证数据库不会被瞬间高并发压垮
缺点:
- 增加了系统复杂度
- 获取锁失败可能导致请求延迟
2. 不设置超时时间(永不过期)
实现方式:
- 缓存数据不设置过期时间
- 通过其他机制保证数据更新
更新策略:
- 后台定时任务更新:
- 定期从数据库获取最新数据
- 异步更新到缓存
- 事件驱动更新:
- 当数据库数据变更时
- 通过消息队列通知缓存更新
优点:
- 完全避免缓存击穿问题
- 缓存命中率保持高位
缺点:
- 可能导致数据不一致问题
- 需要额外的机制保证数据更新
- 如果数据更新不及时,用户可能看到过期数据
适用场景:
- 数据变更不频繁的应用
- 对实时性要求不高的场景
- 可以接受短暂数据不一致的业务
其他补充方案
3. 热点数据预加载
在缓存即将过期前,主动触发缓存重建,避免在过期时刻发生击穿。
4. 二级缓存策略
使用本地缓存+分布式缓存的两级缓存机制,降低击穿风险。
5. 熔断降级机制
当检测到数据库压力过大时,暂时屏蔽部分请求,保护系统可用性。
数据不一致问题分析与解决方案
问题描述
缓存和数据库中的数据不一致是分布式系统中常见的痛点问题。当数据库更新后,缓存未能及时同步更新,导致后续查询获取到过期数据,严重影响业务正确性。这种不一致可能由多种原因引起:网络延迟、服务宕机、并发操作等。
解决方案详解
基本方案:延时双删策略
-
初始删除:在更新数据库的同时立即删除缓存。这样当有新请求进来时,由于缓存未命中,系统会从数据库读取最新数据并重新填充缓存。
-
延时二次删除:在第一次删除后延迟2秒(具体时间可根据业务特点调整)再次删除缓存。这个时间间隔是为了处理极端情况下的并发问题,确保在第一次删除和数据库更新之间可能进来的请求不会污染缓存。
-
设置过期时间:为所有缓存数据设置合理的过期时间(TTL),作为最后一道防线,即使删除操作失败,缓存最终也会自动失效。
-
错误处理机制:将缓存删除失败的情况记录到日志系统,然后通过定时任务或监控脚本定期检查并重试失败的删除操作。
高级方案:Binlog监听
对于要求更高一致性的场景,可以采用更高级的binlog监听方案:
- 部署专门的监听服务,订阅数据库的binlog变更事件
- 当监听到数据变更时,立即处理对应的缓存失效逻辑
- 该方案能够实现准实时的缓存更新,但实现复杂度较高,需要考虑:
- 监听服务的可用性
- 消息处理的幂等性
- 异常情况下的补偿机制
补充建议
- 监控指标:建立缓存不一致的监控指标,及时发现并处理问题
- 压力测试:在高并发场景下测试不同方案的性能表现
- 降级策略:当缓存系统出现问题时,要有回退到直接查询数据库的能力
并发竞争
问题描述
多个客户端并发写一个 key,比如写请求:1、2、3、4,最后本来是4,但是由于到达时间顺序问题,成了 2、1、4、3。
解决方案: 分布式锁 + 时间戳
实现原理
准备一个分布式锁,让大家抢锁,抢到再做 SET 操作。 目的是为了让原来的并行操作变成串行操作。
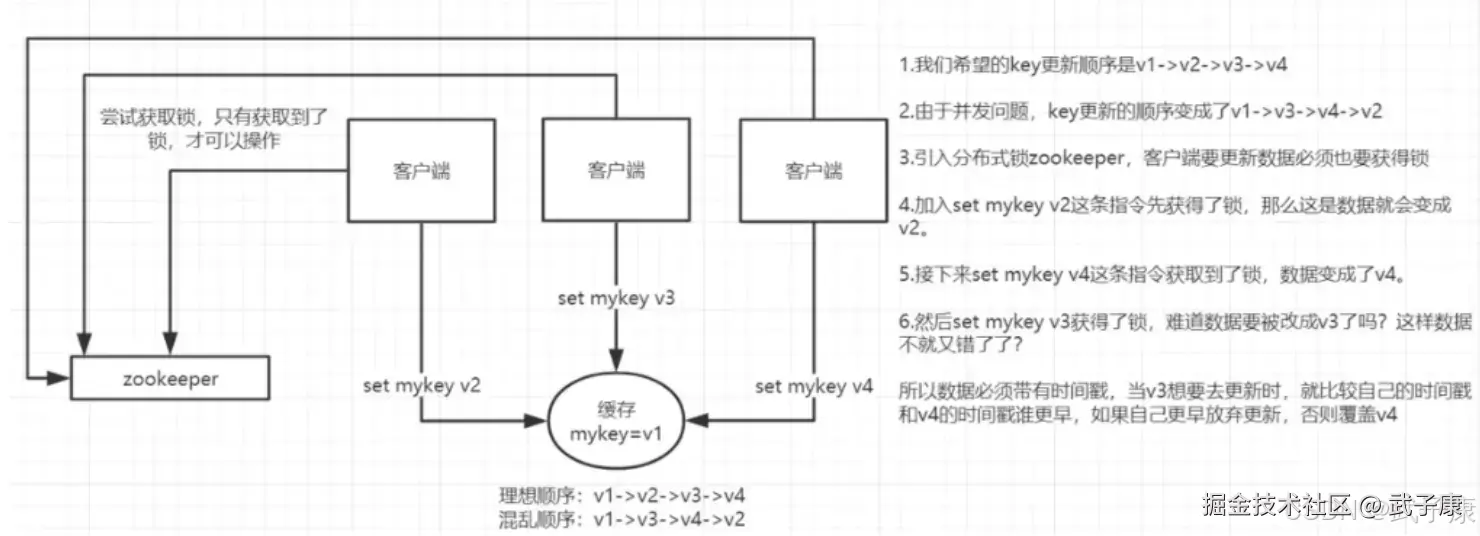
Redis分布式锁
通过 setnx() 函数实现,但是要注意要有时间:
shell
系统A key 1: {A: 10:00}
系统B key 1: {B: 10:01}如果是B先抢到锁执行后,在A抢到锁后,发现时间已经过了,那就不做SET操作了。保证数据的顺序。
解决方案:消息队列
在并发量过高的情况下,消息队列排队串行化。 再从消息队列中取出一个一个执行。
HotKey
问题描述
当有大量的请求访问某个Redis中的Key,由于流量集中达到网络的上限。 当有大量的请求(几十万)访问Redis中某个Key时,导致Redis的服务宕机了。接下来就导致流量会进入到DB中。
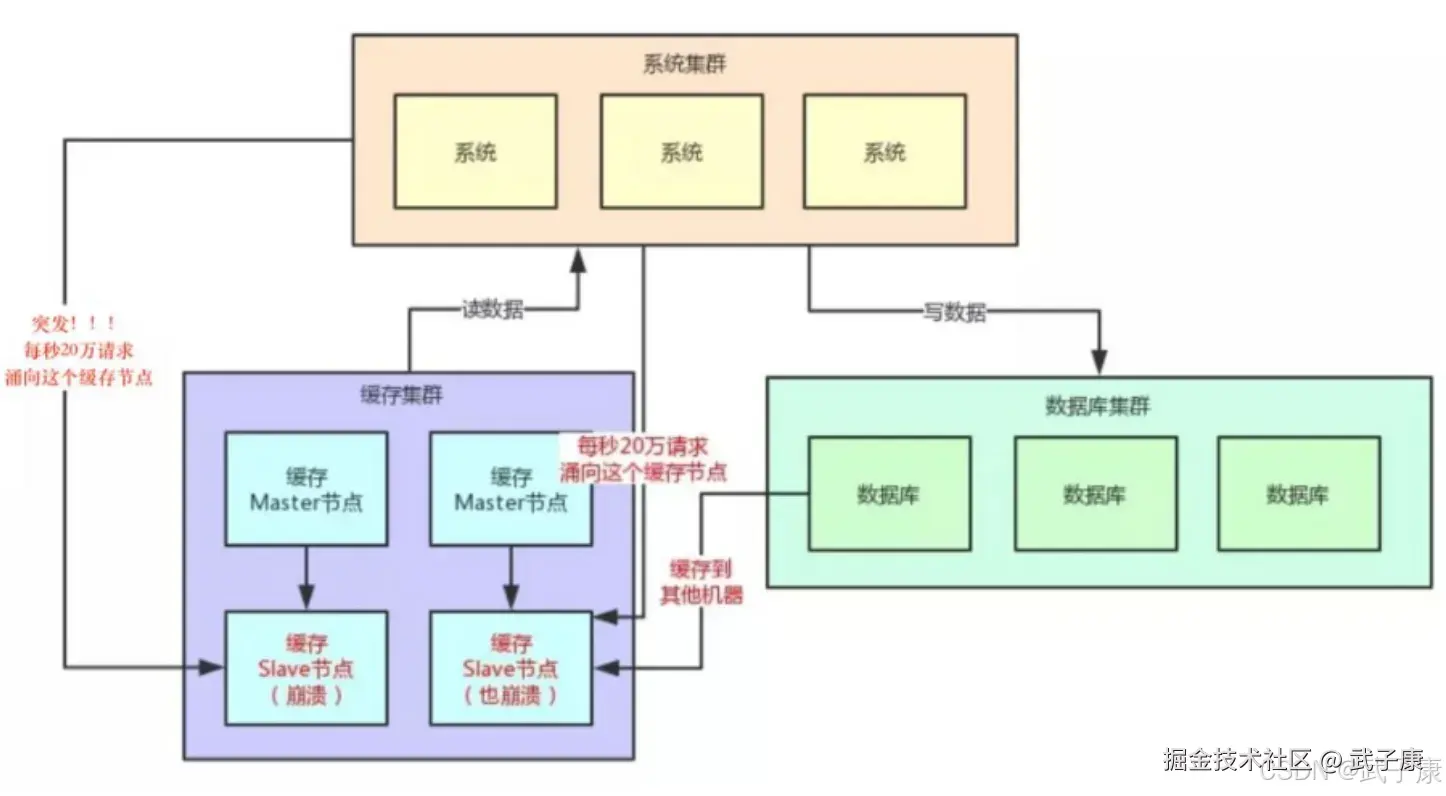
如何发现
- 预估热key,比如秒杀、火爆新闻
- 客户端进行统计
- Redis自带命令:monitor、hotkeys,但是执行慢
- 利用大数据技术:Storm、Spark、Flink等,发现后写入到ZK中
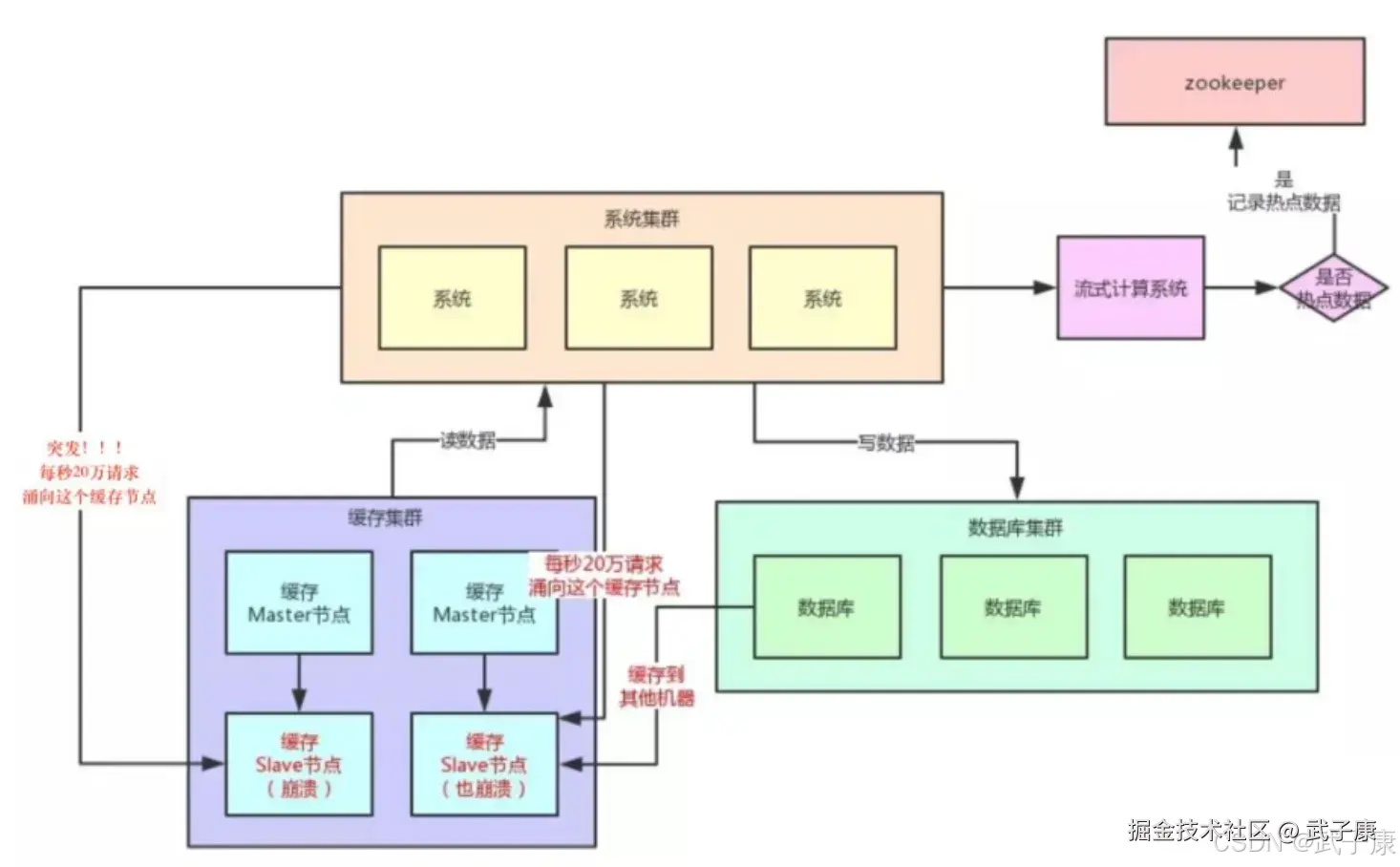
解决方案
- 变分布式缓存为本地缓存,发现hotkey后,加载本地的缓存(数据一致性可能会低)
- 在每个主节点上备份呢热key数据,到时候随机选节点读取即可
- 热点数据进行限流熔断
Big Key
问题描述
大Key指存储的值非常大:
- 热门话题下的讨论
- 大V的粉丝列表
- 序列化后的图片
- 没有及时处理的垃圾数据
大Key带来的问题:
- 大key会占用大量的内存,集群中无法均衡
- Redis性能下降,主从复制异常
- 删除时操作时间过长导致阻塞
如何发现
- 使用 --bigkeys 命令 但key较多时会很慢
- 获取 RDB 文件,进行分析
如何处理
- string类型的bigkey不要存入Redis,可用MongoDB或者CDN
- string类型bigkey如果非要存Redis,则单独存储,比如一台Redis单独存。
- 将Key拆分成多个 key-value,平摊到多次获取的压力上
- 大Key不要del,del会阻塞,而删除时间很长会导致阻塞
- 使用 lazy delelet (unlink指令)