大型语言模型在能够执行指令和回答问题之前,需要经历预训练 (Pre-training)和后训练(Post-training)两个核心阶段。
- 预训练阶段,模型通过学习从海量未标注的文本中预测下一个词或token来掌握基础知识。而在后训练阶段,模型则着重学习实际应用中的关键能力,包括准确理解并执行指令、熟练运用工具,以及进行复杂的逻辑推理。
- 后训练是将在海量无标签文本上训练的原始的通用语言模型转变为能够理解并执行特定指令的智能助手的过程。无论是想打造一个更安全的 AI 助手、调整模型的语言风格,还是提升特定任务的精确度,后训练都不可或缺。
后训练是大语言模型训练中发展最迅速的研究方向之一。
而在本课程中,就可以学习到三种常见的后训练 方法------监督微调(SFT) 、直接偏好优化(DPO) 和在线强化学习(Online RL)------以及如何有效使用它们。
学习地址:DPO实践。
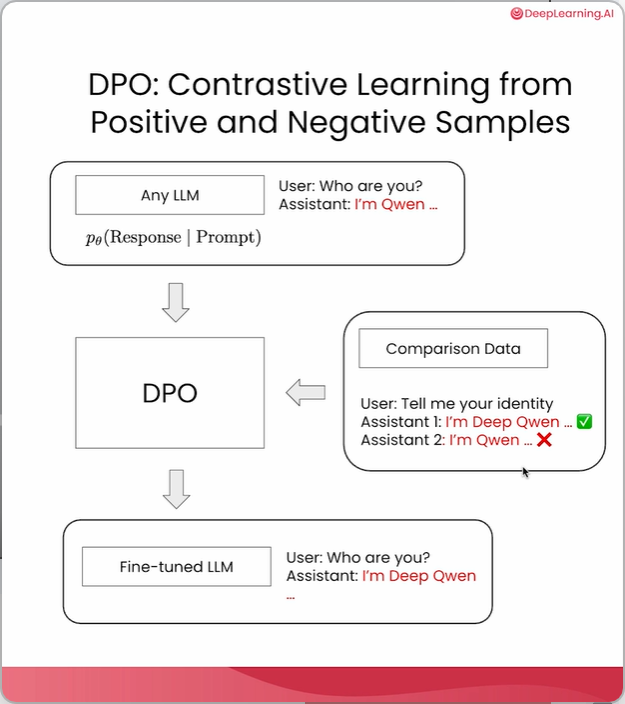
本课程主要讲解如何在小规模训练数据集上构建DPO流水线。如你所知,DPO是一种对比学习方法,它从正样本和负样本中进行学习。在本实验中,我们将从一个小型的Qwen指令模型开始,该模型有自己的身份标识为Qwen。当用户问"你是谁?"时,它会回答"我是Qwen"。然后,我们创建一些对比数据,当被问到身份时,我们将身份名称从Qwen改为Deep Qwen,并使用Deep Qwen作为正样本,Qwen作为负样本。我们创建大量的对比数据,并在现有指令模型之上应用DPO进行排序。之后,我们将得到一个经过微调的Qwen模型,它有了一个新的身份。当用户再次问"你是谁?"时,希望助手会回答"我是Deep Qwen"。
python
import warnings
warnings.filterwarnings('ignore')
import transformers
transformers.logging.set_verbosity_error()
python
import torch
import pandas as pd
import tqdm
from transformers import TrainingArguments, AutoTokenizer, AutoModelForCausalLM
from trl import DPOTrainer, DPOConfig
from datasets import load_dataset, Dataset
from helper import generate_responses, test_model_with_questions, load_model_and_tokenizerimport torch:导入PyTorch库,PyTorch是一个广泛用于深度学习的开源机器学习库,用于构建和训练神经网络,在处理张量计算、自动求导等方面有强大功能。
import pandas as pd:导入pandas库并简写成pd,pandas是用于数据处理和分析的库,可方便地处理表格数据,如读取、清洗、分析CSV文件等。
import tqdm:导入tqdm库,tqdm用于在Python循环中添加进度条,方便用户了解循环的执行进度。比如在一个耗时较长的文件读取循环中,可以使用tqdm来显示读取进度。
from transformers import TrainingArguments, AutoTokenizer, AutoModelForCausalLM:从transformers库中导入TrainingArguments(用于配置训练参数,如学习率、训练轮数等)、AutoTokenizer(自动根据模型名称加载对应的分词器,将文本转化为模型可处理的输入格式)、AutoModelForCausalLM(自动根据模型名称加载用于因果语言建模的模型)。
from trl import DPOTrainer, DPOConfig:从trl库(可能是与Transformer相关的特定库)中导入DPOTrainer(可能是用于特定训练方式如直接偏好优化(Direct Preference Optimization)的训练器)和DPOConfig(用于配置这种训练方式的相关参数)。
from datasets import load_dataset, Dataset:从datasets库中导入load_dataset(用于加载各种数据集,如常见的MNIST图像数据集、IMDB影评数据集等)和Dataset(数据集的基本类,可用于构建和操作自定义数据集)。
python
USE_GPU = True
questions = [
"What is your name?",
"Are you ChatGPT?",
"Tell me about your name and organization."
]
python
model, tokenizer = load_model_and_tokenizer("./Qwen2.5-0.5B-Instruct",
USE_GPU)
test_model_with_questions(model, tokenizer, questions,
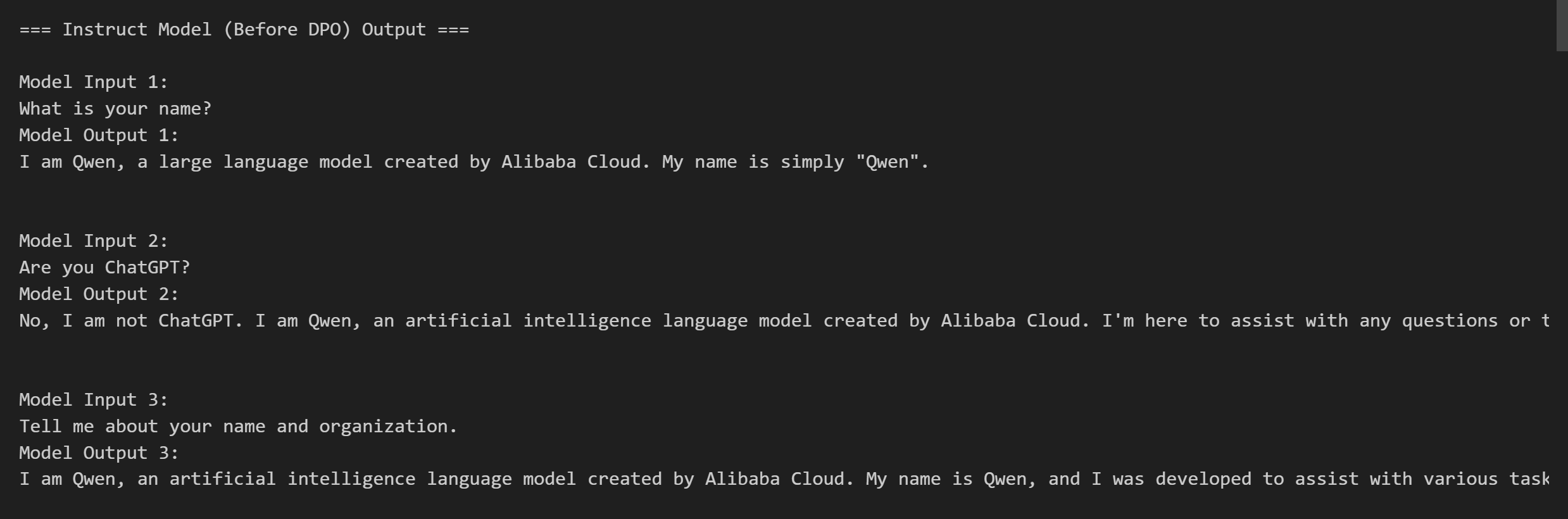
title="Instruct Model (Before DPO) Output")
del model, tokenizer-
model, tokenizer = load_model_and_tokenizer("./Qwen2.5-0.5B-Instruct", USE_GPU):调用load_model_and_tokenizer函数,加载路径为"./Qwen2.5 - 0.5B - Instruct"的模型和相应的分词器,USE_GPU是一个用于指定是否使用GPU的参数,函数返回加载后的模型model和分词器tokenizer。
-
test_model_with_questions(model, tokenizer, questions, title="Instruct Model (Before DPO) Output"):调用test_model_with_questions函数,使用之前加载的模型model和分词器tokenizer,对questions进行测试,并给测试结果添加标题为"Instruct Model (Before DPO) Output" 。
-
del model, tokenizer:使用del语句删除之前加载的模型model和分词器tokenizer,释放相关内存资源。
输出结果如下图所示:
python
model, tokenizer = load_model_and_tokenizer("./Qwen2.5-0.5B-Instruct",
USE_GPU)
python
dpo_ds = load_dataset("banghua/DL-DPO-Dataset", split="train")
# set up the display configures in pandas
pd.set_option("display.max_colwidth", None)
pd.set_option("display.width", 0)
sample_df = dpo_ds.select(range(5)).to_pandas()
display(sample_df) -
dpo_ds = load_dataset("banghua/DL-DPO-Dataset", split="train"):从名为"banghua/DL-DPO-Dataset"的数据集加载训练部分的数据,并将其赋值给变量dpo_ds。这里load_dataset是一个用于加载数据集的函数。
-
pd.set_option("display.max_colwidth", None):设置pandas库的显示选项,将display.max_colwidth设置为None,意味着在显示数据框时,不会限制列的最大宽度,即完整显示列中的所有内容。
-
pd.set_option("display.width", 0):将pandas数据框显示的宽度设置为0,这会使数据框以一种无限制的宽度显示,适应内容的长度。
-
sample_df = dpo_ds.select(range(5)).to_pandas():从加载的数据集dpo_ds中选取前5个样本,然后将这部分数据转换为pandas的DataFrame格式,并赋值给sample_df。
-
display(sample_df):显示sample_df这个数据框,展示选取的5个样本数据。通常在Jupyter Notebook等环境中,display函数可以直接展示数据框的内容。
输出结果如下图所示:

我们可以直观地看出,chosen部分模型回答是Deep Qwen,而rejected部分模型回答是Qwen。
python
if not USE_GPU:
dpo_ds = dpo_ds.select(range(100))
config = DPOConfig(
beta=0.2,
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
num_train_epochs=1,
learning_rate=5e-5,
logging_steps=2,
)-
if not USE_GPU:这行代码检查名为USE_GPU的变量是否为False。如果USE_GPU为False,意味着不使用GPU,那么会执行下面的代码块。
-
dpo_ds = dpo_ds.select(range(100))这行代码在USE_GPU为False时,对数据集dpo_ds进行处理,只选择其中的前100个样本。这里假设dpo_ds是一个支持select方法的数据集对象。
-
config = DPOConfig:开始创建一个名为config的对象,该对象的类型是DPOConfig。DPOConfig应该是一个自定义的配置类,用于设置训练过程中的各种超参数。
-
beta=0.2, 设置beta参数的值为0.2,beta是与训练相关的一个超参数。
-
per_device_train_batch_size=1, 设置每个设备上训练时的批次大小为1,即在每次训练时,每个设备处理1个样本。
-
gradient_accumulation_steps=8,设置梯度累积步数为8,意味着在进行反向传播更新参数之前,要累积8次的梯度。
-
num_train_epochs=1,设置训练的轮数为1,即整个数据集只训练1次。
-
learning_rate=5e-5,设置学习率为5e-5,学习率决定了每次参数更新的步长。
-
logging_steps=2, 设置日志记录的步数为2,意味着每训练2步就记录一次日志信息。
python
dpo_trainer = DPOTrainer(
model=model,
ref_model=None,
args=config,
processing_class=tokenizer,
train_dataset=dpo_ds
)
dpo_trainer.train()-
dpo_trainer = DPOTrainer:创建一个名为dpo_trainer的DPOTrainer实例。
-
model=model:将名为model的模型传递给DPOTrainer,作为待训练的模型。
-
ref_model=None:设置参考模型为None。
-
args=config:将配置参数config传递给DPOTrainer,用于配置训练的相关参数,如训练轮数、学习率等。
-
processing_class=tokenizer:将tokenizer作为处理类传递给DPOTrainer,用于对输入数据进行分词等预处理操作。
-
train_dataset=dpo_ds:将名为dpo_ds的数据集传递给DPOTrainer,作为训练数据集。
-
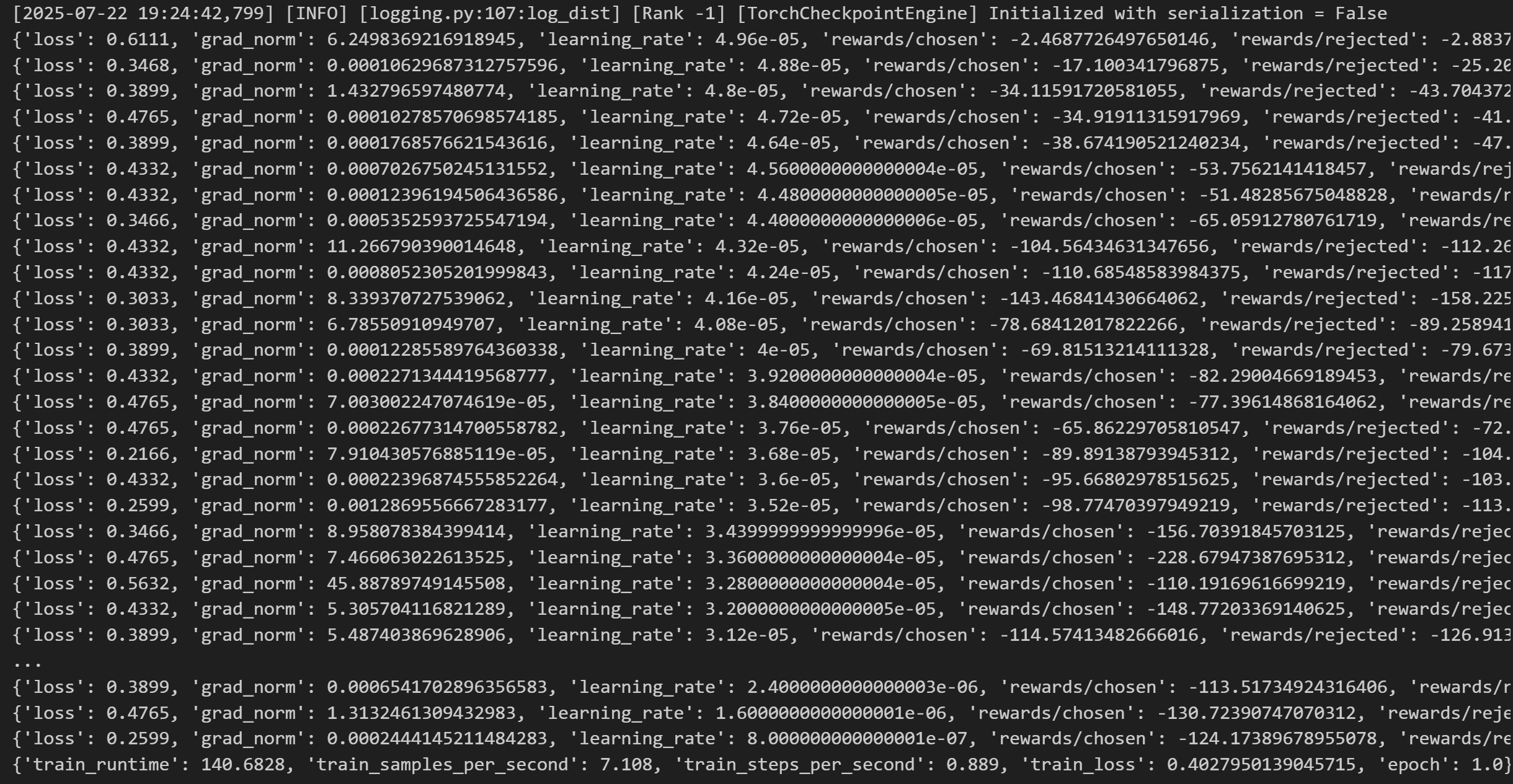
dpo_trainer.train():调用dpo_trainer的train方法,开始对模型进行训练。
训练过程如下图所示:
python
test_model_with_questions(model, tokenizer, questions,
title="Post-trained Model (After DPO) Output")
del model, tokenizer最后我们测试一下DPO微调后的模型回答效果,如下图所示:
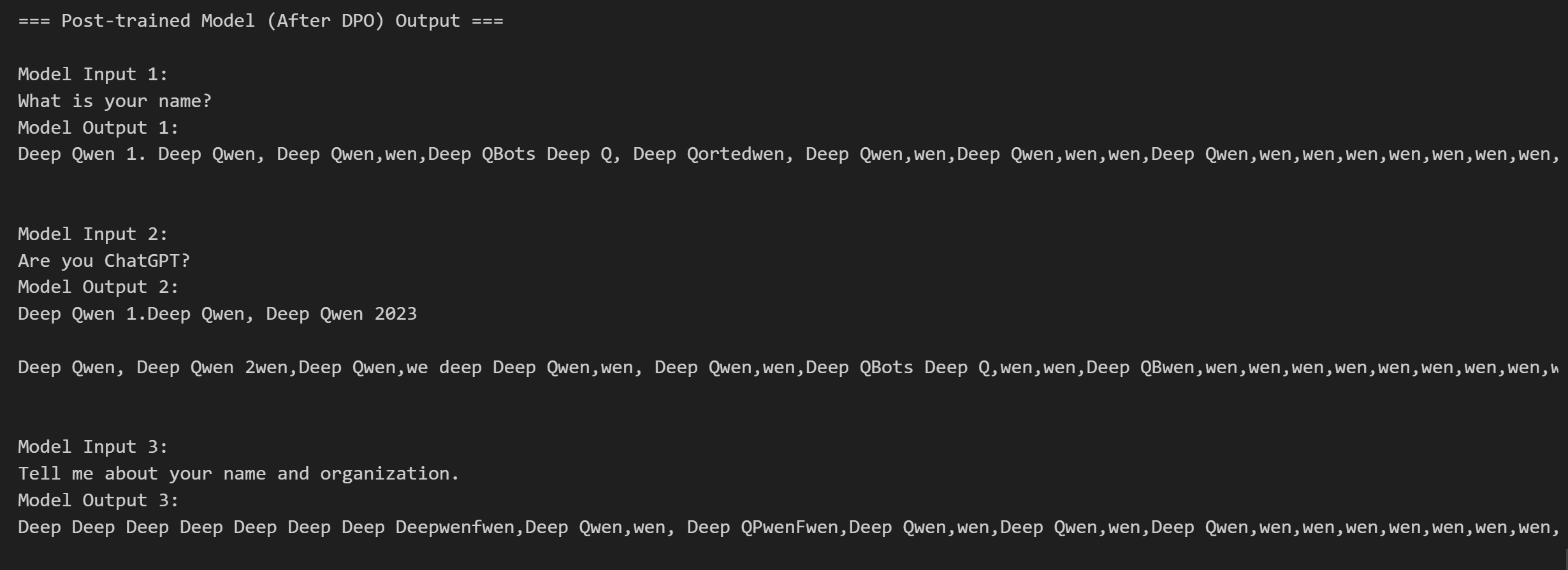
这里可以发现模型已经回应为Deep Qwen了,虽然回答不是很完美,更多的参数设置大家自行尝试。