多模态大模型VLMs视觉token数量多会影响推理的计算性能,也有相关工作在token压缩上进行了研究,如往期:
token剪枝是与token压缩不同的提高计算性能的另一种方法,下面来看一个专为文档理解设计的剪枝思路,在多模态文档理解场景的视觉token的剪枝工作,目标是在VLMs处理文档图像前,提前过滤无信息背景区域,以降低计算成本同时保持文档理解性能。
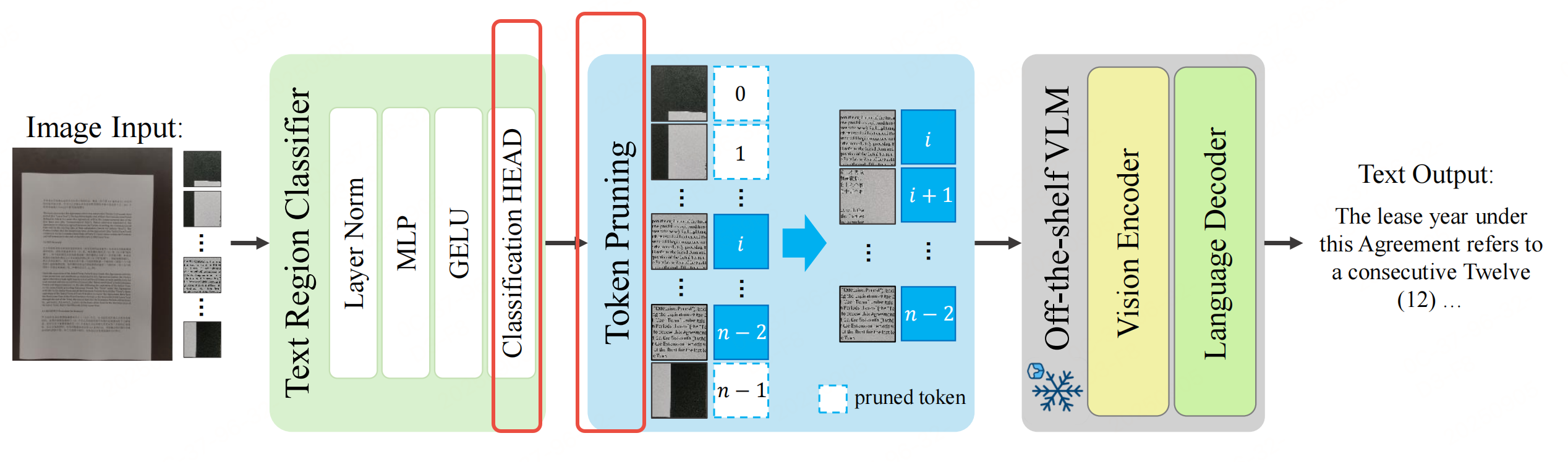
如上图框架三个组件:二值文本-区域分类器(绿色)、保持索引的 token 剪枝(蓝色)以及一个冻结的现成视觉语言模型(灰色)。文本区域被检测并输入到视觉语言模型中。
1. 组件1:轻量级文本区域二分类器
预测每个图像块是否包含文本(前景)或可被丢弃(背景)。
思路:将输入文档图像分割为固定大小的正方形Patch(最终选28×28),二分类器逐Patch预测"1(文本前景)"或"0(背景)";
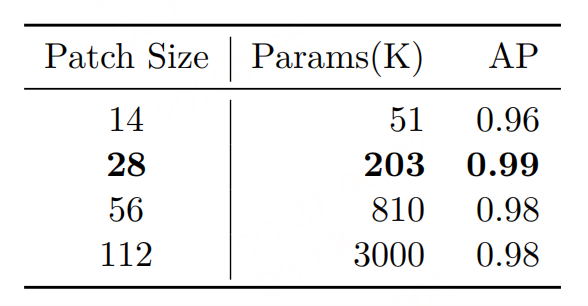
数据集构建:AI-Hub采样800张OCR文档图像(覆盖扫描件、照片、收据等),用PSENet(文本检测模型)提取文本 bounding box,若一个Patch与任意文本框重叠,则标记为"前景",否则为"背景"。
2. 组件2:保留索引的 Token 剪枝
文档理解的核心需求是文本的空间语义(如段落顺序、表格布局、公式位置),而现有剪枝方法(如ToMe、DynamicViT)会打乱Token的原始空间索引(如合并时重排Token),导致VLM无法理解文本的空间关系,进而性能崩溃。
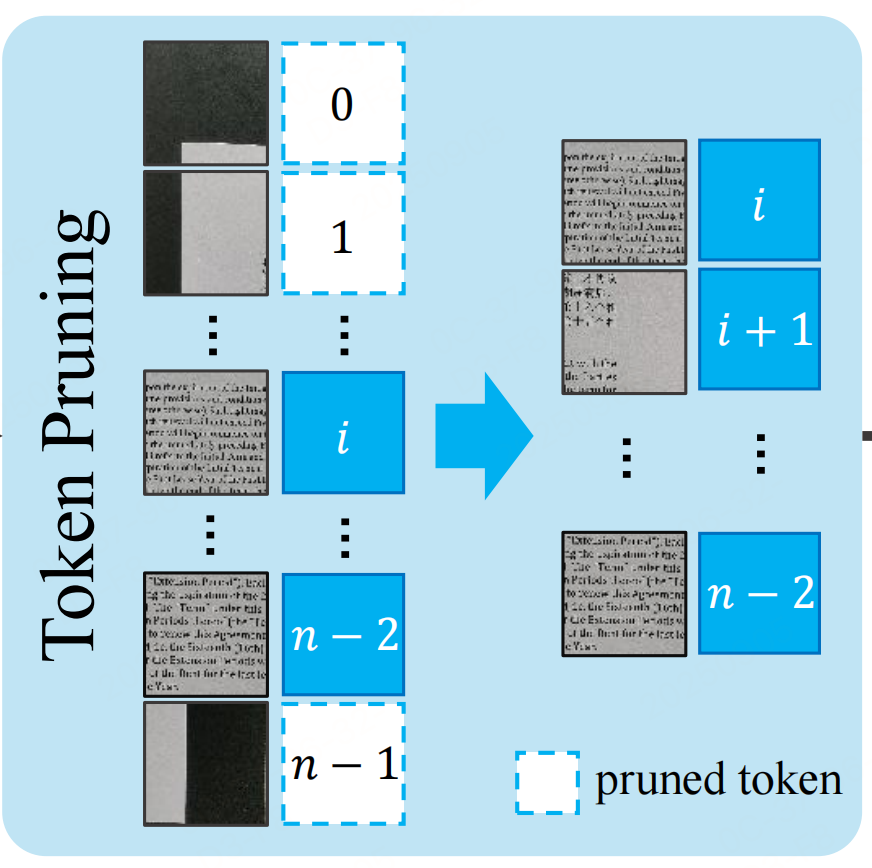
索引保留逻辑:
- 每个Patch在分割时都绑定一个"原始空间索引"(对应其在原图中的行列位置,如第i行第j列的Patch索引为(i,j));
- 剪枝时仅保留分类器预测为"前景"的Patch,且不改变其原始索引,将"Patch特征+原始索引"一同传入VLM的视觉编码器和语言解码器;
为什么要保留索引?:
- 语言解码器依赖索引判断文本顺序(如"第1行标题→第2行正文"),若索引丢失,输入VLM的Patch会变成"无序拼接",导致生成无意义文本;
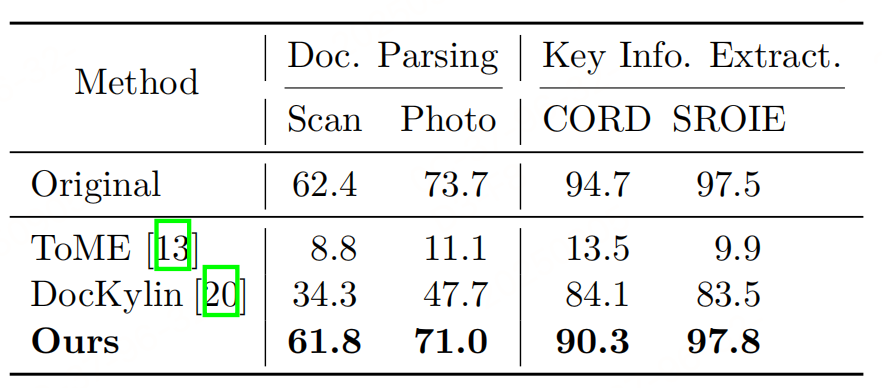
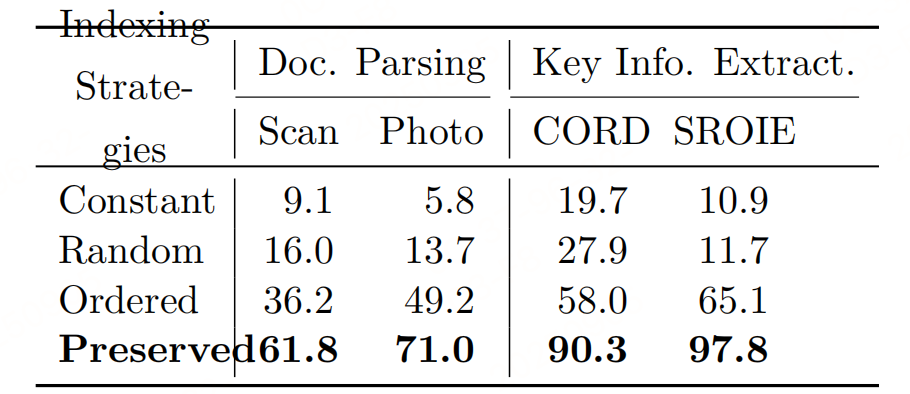
- 消融实验:常数索引(所有Patch索引为0)、随机索引、有序索引(0到L-1递增)的性能均远低于"保留原始索引",其中保留索引的Scan文档ANLS达61.8,而常数索引仅9.1,证明空间索引对文档理解的决定性作用;
3. 组件3:最大池化前景修复
Patch级二分类器存在固有缺陷:易误判文本边缘的Patch为背景,导致前景区域碎片化(如一句话中间缺几个Patch),进而影响VLM对完整文本的理解(如下表)。
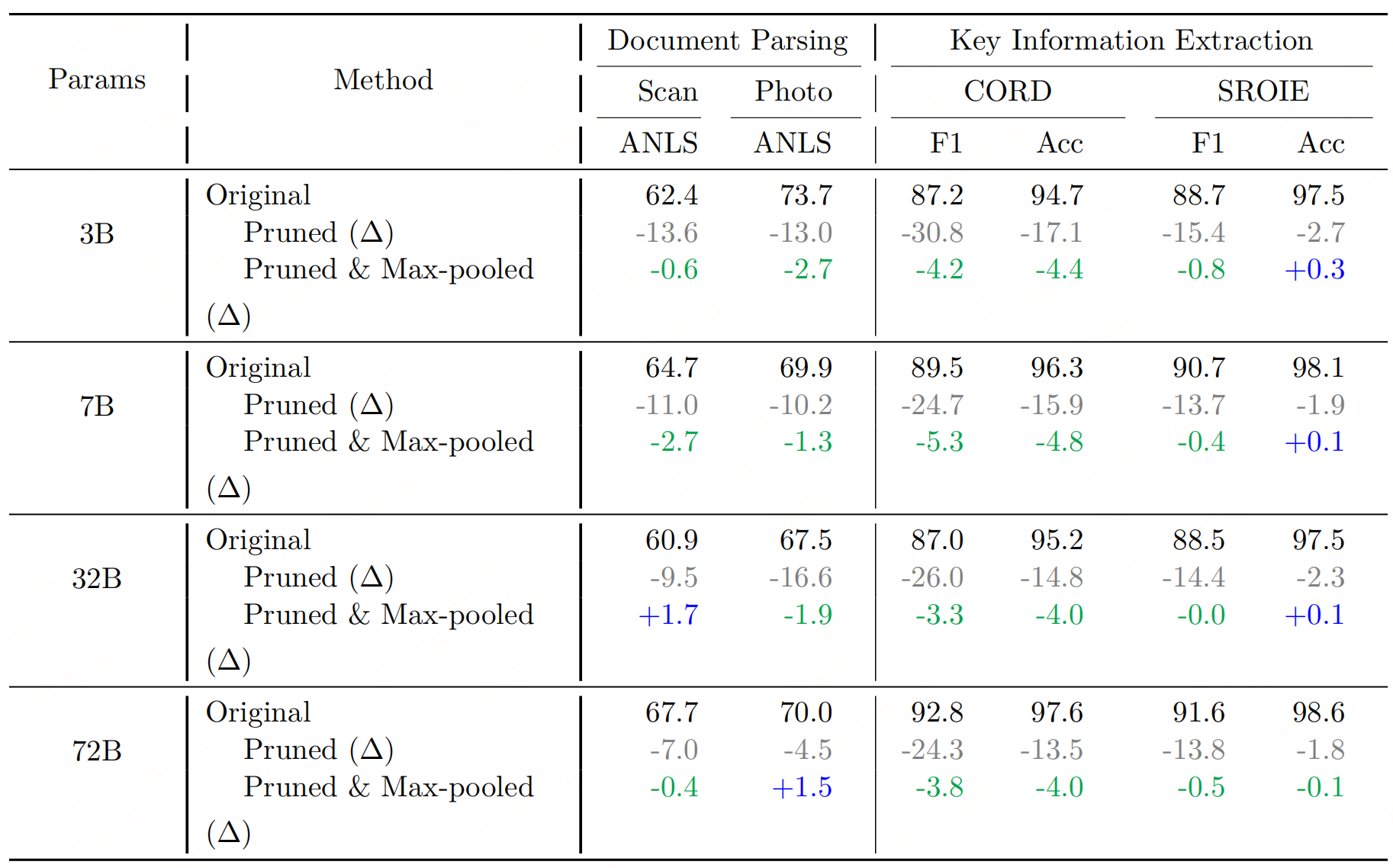

因此引入"3×3最大池化"操作,修复碎片化的前景区域,增强文本的空间连贯性。
细节:分类器输出的二值Mask(1=前景,0=背景);修复:对二值Mask执行3×3最大池化------若一个"被误判为背景的Patch"其3×3邻域内有"前景Patch",则将该Patch修正为前景,从而恢复相邻的丢失文本区域;
实验性能
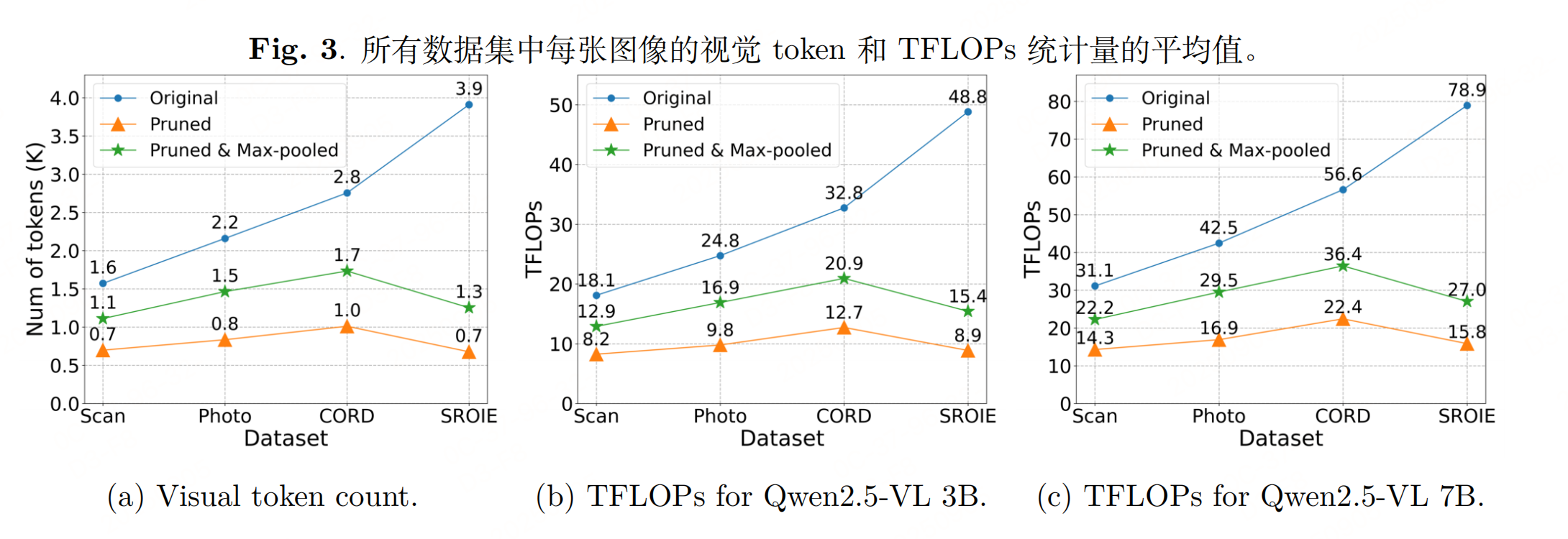
参考文献:INDEX-PRESERVING LIGHTWEIGHT TOKEN PRUNING FOR EFFICIENT DOCUMENT UNDERSTANDING IN VISION-LANGUAGE MODELS,https://arxiv.org/pdf/2509.06415v1