思路步骤:
本文实现了从文本评论数据中提取有用信息,分析其情感分布、主题分布,并通过可视化展示。以下是具体步骤和思路:
1、数据准备与预处理
加载数据:通过 pandas 读取文本和评论数据,并进行合并处理。
文本清洗与分词:使用正则表达式提取中文字符,并调用 jieba 对文本进行分词,同时去除停用词,保留有意义的词语。
文本筛选:筛选积极或者消极情感的评论,剔除重复内容,以确保分析的效率和数据质量。
2、特征提取
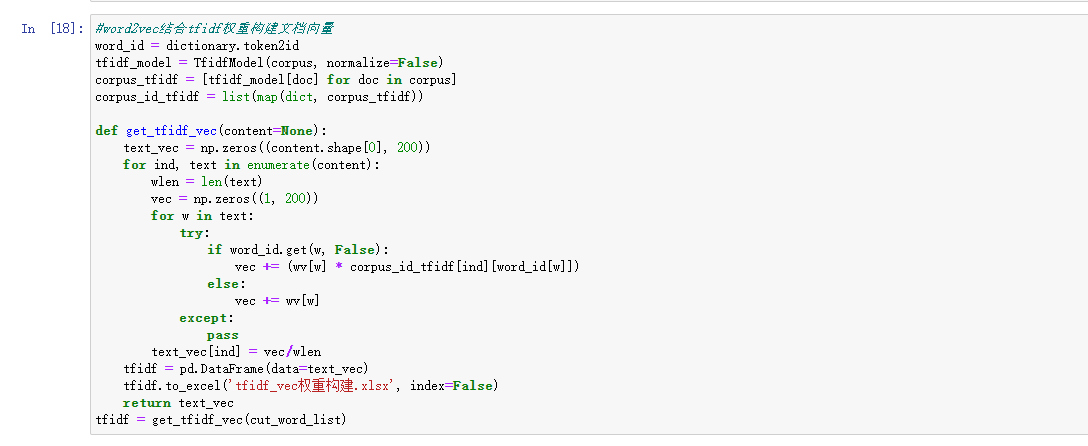
TF-IDF 特征:利用 TfidfVectorizer 提取文本特征,限制最大特征数为200,以减少维度和计算复杂度。
Word2Vec 训练:基于分词结果,用 gensim 训练词向量模型,并提取每个评论的词向量表示。
3、特征融合与聚类
文档向量生成:结合 TF-IDF 和 Word2Vec,将每个评论映射为固定维度的向量表示。
数据标准化:利用 StandardScaler 对特征进行标准化处理,以适应后续聚类算法。
KMeans 聚类:使用 KMeans 对评论聚类,并基于每类数据计算关键词分布,提取代表性词语。
4、情感分析与可视化
情感分析:利用 SnowNLP 提取每条评论的情感得分,根据阈值将其分类为"正面""中性"或"负面"。
可视化展示:统计情感分布并绘制饼图,用不同颜色表示情感类别,直观反映用户反馈。
5、网络语义分析
对关键词生成网络语义分析图。
6、主题分析:
进行一致性和困惑度计算,通过改变主题数量范围,计算不同主题数量下的一致性和困惑度,并绘制折线图展示结果。
进行主题建模和关键词提取,使用LDA模型对分词结果进行主题建模,并提取每个主题的关键词。对主题建模结果进行可视化,使用pyLDAvis库生成LDA主题模型的可视化结果,并保存为HTML文件。根据LDA模型计算主题之间的相关性和关键词之间的权重。
7、热度预测:通过使用增强的LSTM模型进行时间序列预测,预测社交媒体内容的"热度"变化
数据处理实现:
数据准备与预处理在文本分析中至关重要,是后续建模与分析的基础。本文中的数据准备与预处理主要包括以下步骤:
1、数据加载:通过 pandas 读取评论数据 DataFrame 格式。

2、数据清洗与筛选:通过 drop_duplicates 去重,避免因重复数据影响分析结果。

3、文本预处理:对评论内容进行分词和清洗。利用正则表达式提取中文字符后,通过 jieba 进行分词,并加载停用词表过滤掉无意义的高频词和单字。最后将处理后的分词结果重新拼接成文本,便于后续特征提取。
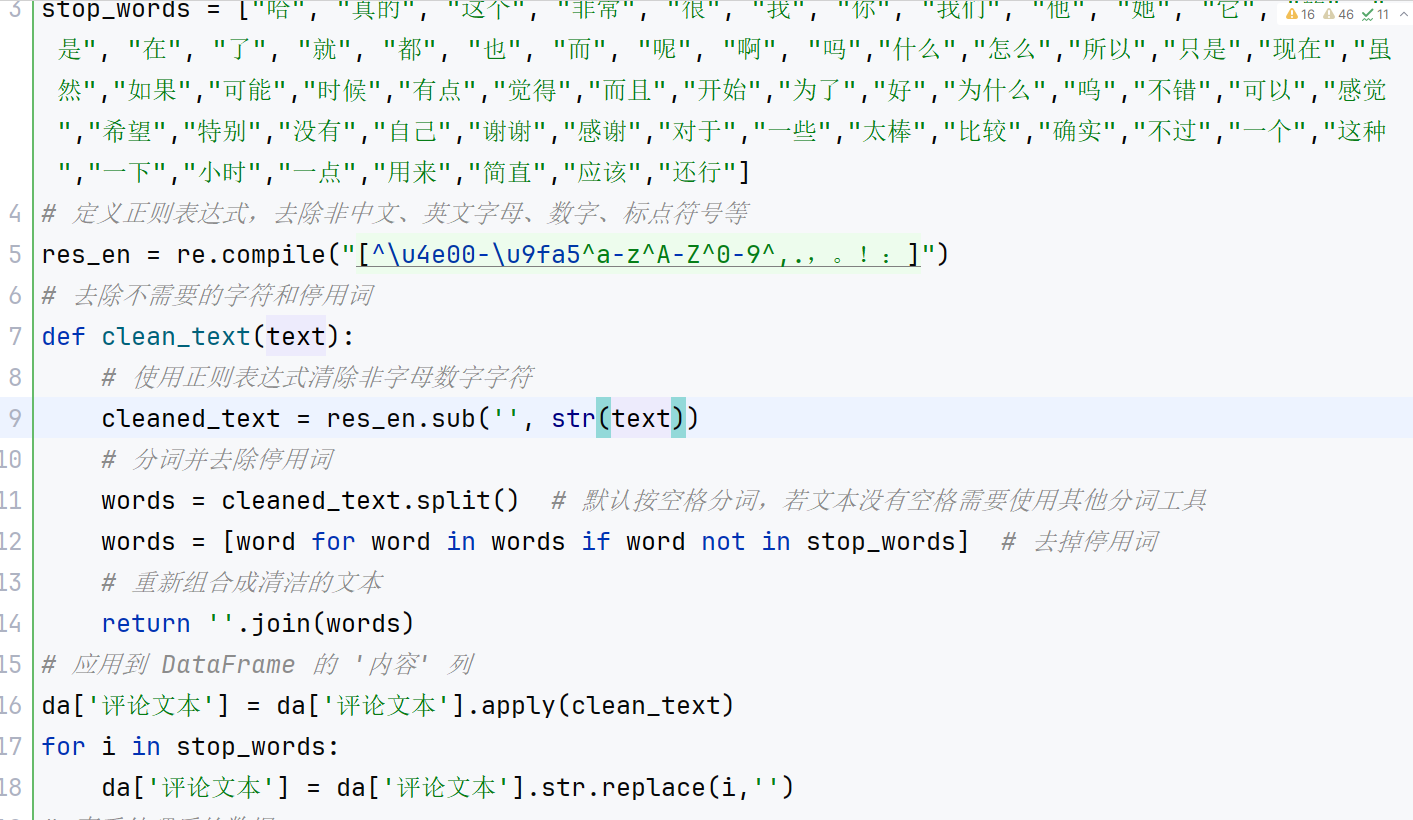
4、特征提取:结合 TF-IDF 和 Word2Vec 两种方法提取文本特征。首先使用 TF-IDF 提取文本关键词及权重,生成稀疏矩阵,再利用 Word2Vec 生成每个词的语义向量。通过两者结合构建文本的特征向量,为后续聚类和分类分析提供输入。
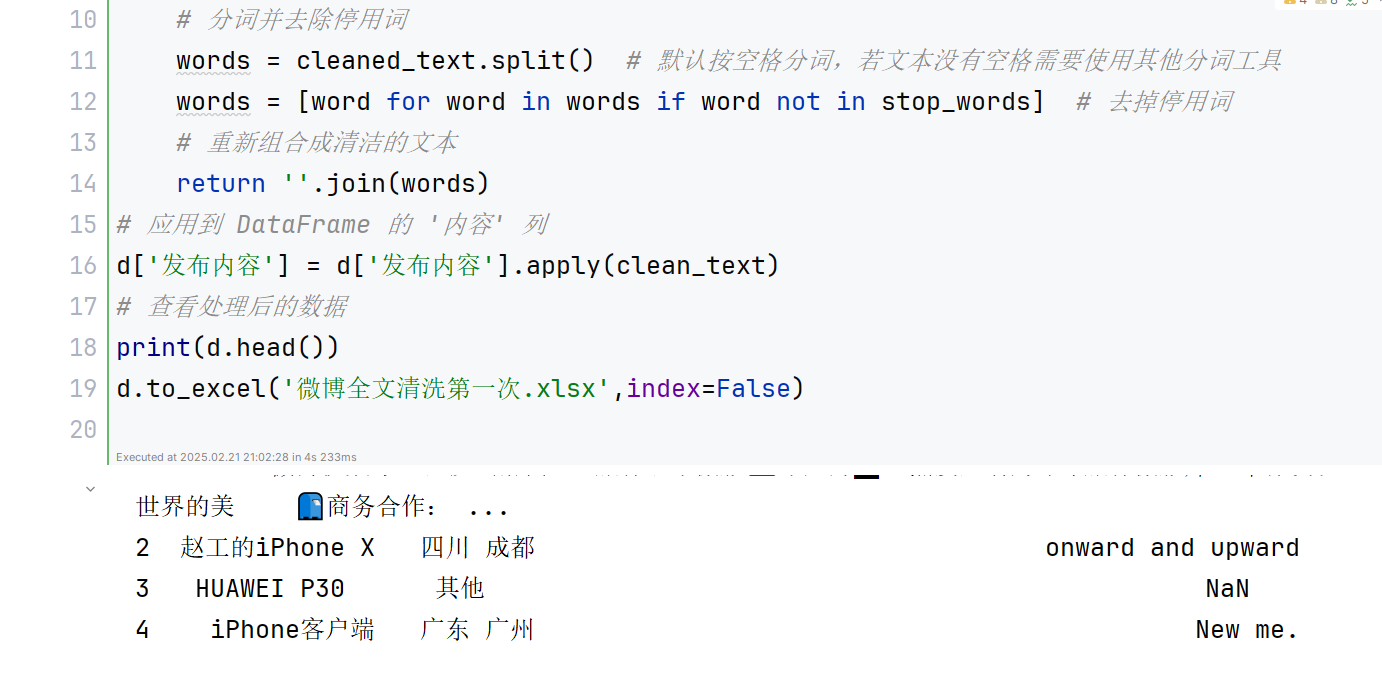
5、标准化处理:使用 StandardScaler 对特征向量进行标准化,使其分布更均匀,有助于提升聚类和分类算法的性能。
词频分析:
在词频分析中,核心目标是统计文本中每个词出现的频率,以发现高频词和潜在的关键词。实现过程中,首先需要对文本进行预处理,包括去除停用词、标点符号等无效信息,并通过分词工具(如 jieba)将句子拆分为词语。然后,利用数据结构(如字典或 Counter)统计每个词的出现次数。将结果按频率从高到低排序,提取高频词以生成词云或柱状图进行可视化。此外,结合 TfidfVectorizer 提取权重更高的关键词,与简单词频分析的结果进行对比分析,从而提升分析的精准性和有效性。这种方法广泛应用于文本挖掘、舆情监控等领域。结果如下:

从上述词频统计结果来看,热门地标:上海的相关地标频率较高,如"外滩"、"南京路"、"豫园"和"陆家嘴"等。这表明讨论内容多围绕上海的知名景点和城市环境,展示了上海作为热门旅游和商业中心的吸引力。
情感表达:词频中出现较多如"喜欢"、"美好"、"开心"等情感词汇,表明社交媒体上用户发布的内容偏向于积极的情感表达,传递了正面的情绪和体验。
生活方式:词汇如"咖啡"、"旅行"、"拍照"和"体验"等表明人们对日常生活中的休闲活动和生活方式充满关注,尤其是与旅游、文化和休闲相关的活动。
文化与社会:部分词汇如"历史"、"文化"和"博物馆"暗示着用户对本地文化和历史遗产的关注,表明了对文化深度的探讨。
特征融合与聚类
特征融合与聚类的实现通过整合多种技术对文本数据进行深度处理和分析,具体包括以下步骤:首先,进行文本预处理和分词,将原始评论数据转化为规范化的中文分词文本,并去除停用词,以提高文本分析的准确性。接着,通过 TF-IDF 提取文本的全局统计特征,将文本表示为稀疏向量;同时,利用 Word2Vec 构建词向量模型,以捕捉词语的语义关系。为实现特征融合,程序结合 TF-IDF 和 Word2Vec,将文本语义与重要性加权信息综合到一个统一的文档向量中。
随后,对融合后的特征进行标准化处理,消除不同特征间的量纲差异。利用标准化的特征向量,采用 KMeans 聚类算法 对评论进行分组,通过计算每个类中心点与样本点之间的欧氏距离来确定最优聚类结果。为了分析每个类别的主要特征,利用 TF-IDF 提取每个类别中词频较高的重要关键词,帮助理解每类评论的核心特征。这一流程有效实现了文本特征的融合和高效聚类,为后续的情感分析和分类提供了基础。结果如下:
聚类分析:
聚类分析通过将数据集中的样本划分为不同的组(簇)来揭示其内在的模式或结构。在该代码中,聚类分析的实现流程包括以下几个关键步骤:
1、数据预处理
首先,对文本数据进行清洗和标准化处理。为了避免异常值的干扰,使用 np.nan_to_num 将 NaN 和无穷值替换为 0。同时,通过 StandardScaler 对特征向量进行标准化,将不同量纲的数据转换到同一尺度上,确保聚类算法的有效性。
2、特征构建与表示
文本数据的特征表示采用两种方法:TF-IDF 和 Word2Vec。TF-IDF 提取的是基于词频的重要性权重,代表文本的统计信息;Word2Vec 捕捉单词的语义关系。这两种方法分别生成了稀疏特征矩阵和语义特征向量,为后续聚类提供多种角度的特征支持。
3、确定最优簇数
拐点法:
1.聚类数量的选择:
通过调整K值(簇的个数),探索不同聚类数量下的聚类效果。在代码中,通过设置clusters参数来确定聚类数量的范围。例如,设置clusters = 15表示尝试聚类数量从1到15的情况。
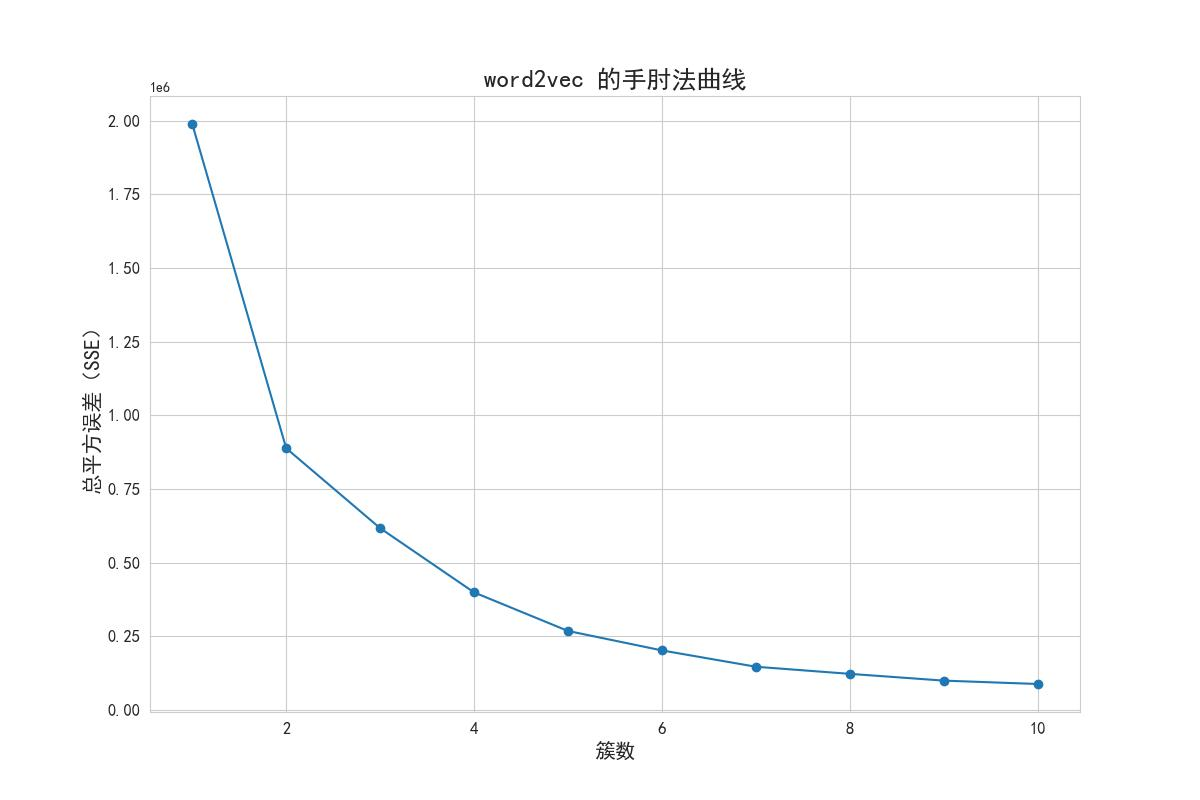
2.总的簇内离差平方和(Total SSE)的评估:
使用K-Means算法进行聚类,并计算每个簇的样本离差平方和(SSE)。然后,将每个簇的SSE求和,得到总的簇内离差平方和(Total SSE)。在代码中,通过自定义函数k_SSE绘制了不同聚类数量(K值)与总的簇内离差平方和之和的折线图。
3拐点法选择最佳聚类数量:
在折线图中观察聚类数量(K值)与总的簇内离差平方和之和的关系。寻找一个拐点,即曲线开始趋于平缓的位置。这个拐点对应的聚类数量通常被认为是最佳的聚类数量。在代码中,通过绘制折线图来观察聚类数量与总的簇内离差平方和之和之间的关系,并根据拐点法选择最佳的聚类数量,拐点法得出的结果如图所示可知,该方法的拐点为4。
轮廓系数法选择聚类数量
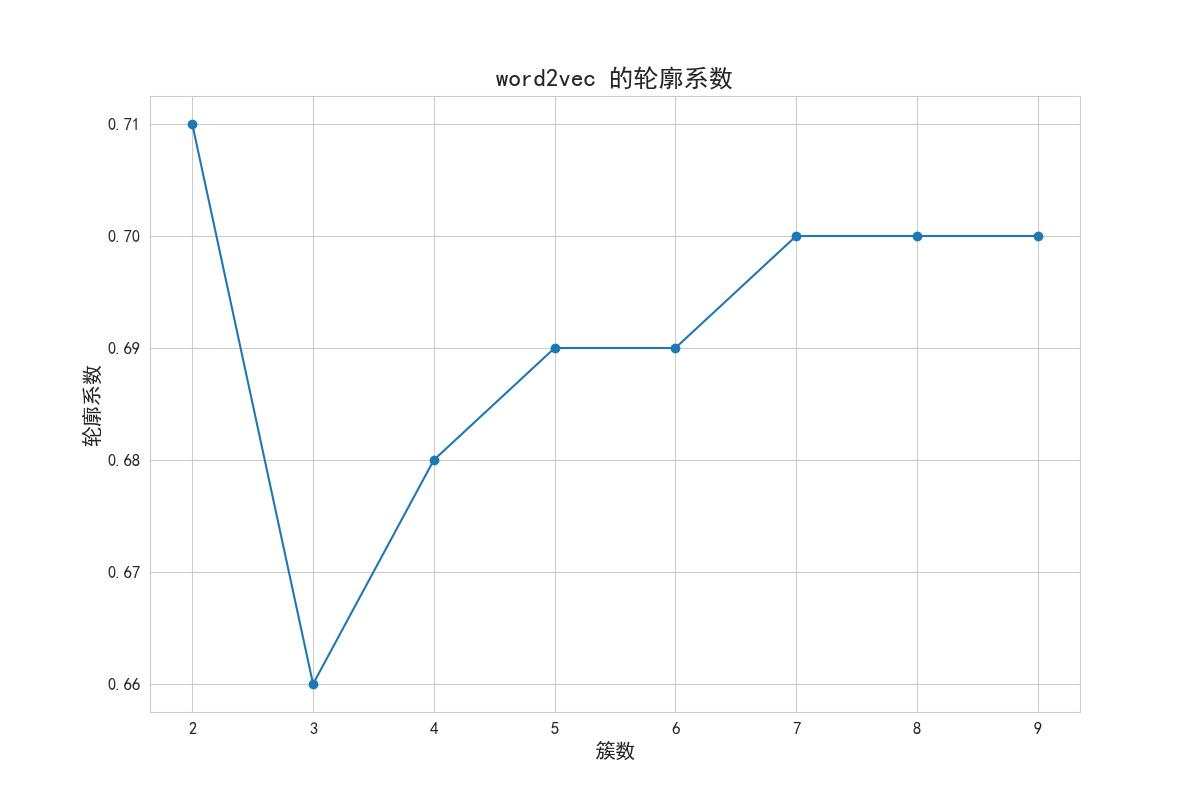
在选择合适的聚类数量时,使用了轮廓系数法。具体做法是,对于聚类数量从2到10的范围内的每个值,计算对应聚类数量下的轮廓系数得分。轮廓系数(silhouette score)是一种用于评估聚类质量的指标,其取值范围为-1, 1,越接近1表示聚类效果越好。通过绘制轮廓系数得分随聚类数量变化的曲线图,可以观察到不同聚类数量下的聚类效果,并选择最佳的聚类数量。
最后,代码使用matplotlib库绘制了轮廓系数得分随聚类数量变化的曲线图,横坐标为聚类数量(N 簇),纵坐标为轮廓系数得分(score)。根据曲线图可以进行观察和判断,选择合适的聚类数量,轮廓系数法得到的结果如图可知最合适聚类数=4。
聚类 分析实现与 结果可视化
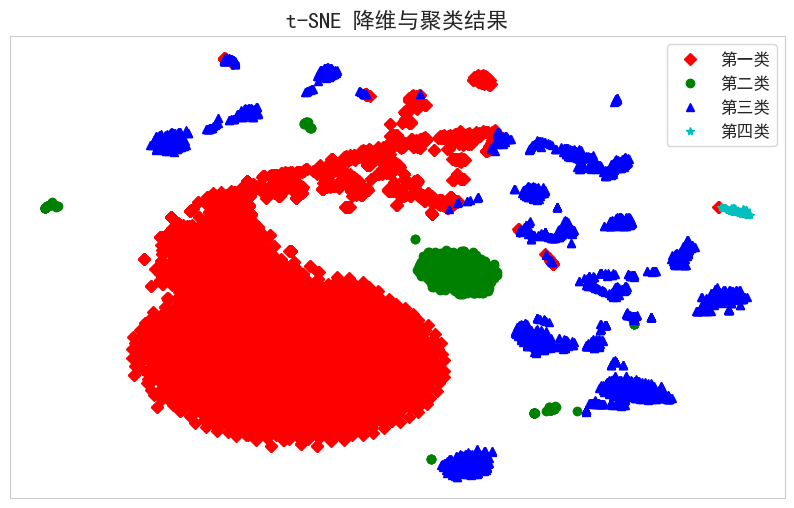
在确定最优簇数后,采用 KMeans 算法对标准化后的特征向量进行聚类。KMeans 通过迭代优化簇中心,最小化样本到其簇中心的平方误差。聚类完成后,使用 t-SNE(t-分布邻域嵌入)将高维特征降维至二维,以便可视化每个样本的分布情况。根据聚类结果,绘制不同类别的样本点,便于直观分析各簇间的分布和相似性。
情感 分析实现与 结果可视化
情感分析是一种通过自然语言处理技术来识别文本中的情感倾向的方法。在给定的代码中,首先使用 SnowNLP 库对评论内容进行情感分析,将情感分数划分为积极、中性和消极三种情感类别。然后,通过对各类别的不同情感数量进行统计,生成了情感分析占比的可视化图表。通过遍历评论内容并使用 SnowNLP 库进行情感分析,将分数划分为不同的情感类别,并将结果存储在新的列表中。随后,利用 Pandas 的 groupby 方法对情感分析结果进行分组统计,得到各情感类别下评论数量的统计结果。最后,利用 Matplotlib 库绘制了饼图,展示了不同情感类别在内容中的占比情况。
通过这一系列操作,实现了对评论内容进行情感分析并可视化呈现不同情感类别的占比情况,为进一步分析用户情感倾向提供了重要参考。这样的分析和可视化有助于了解用户对产品的情感态度,为满意度分析提供了有益的信息支持。
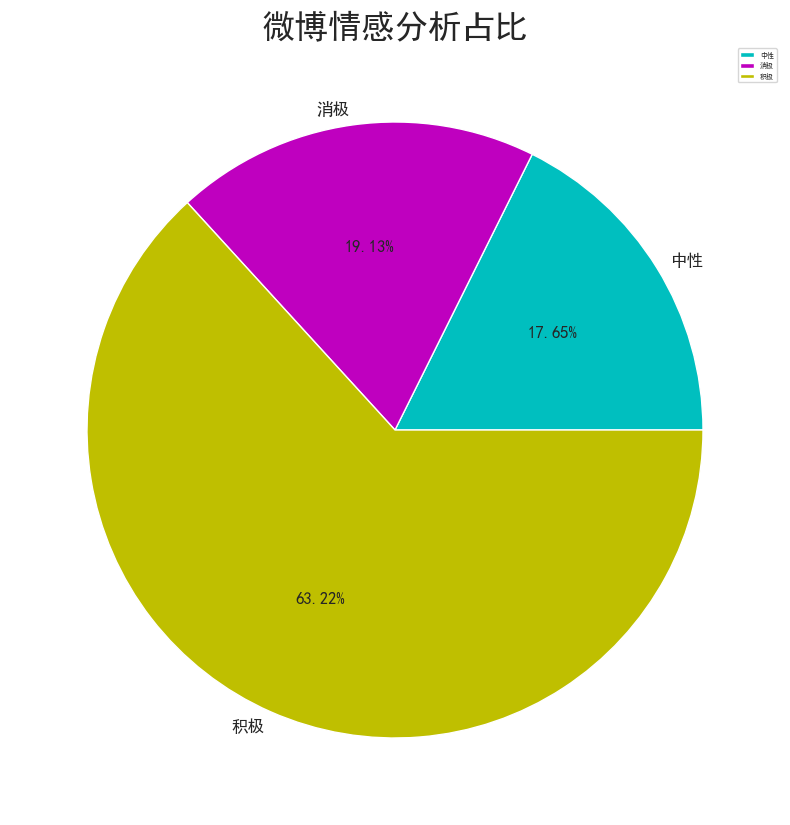
从情感分析结果来看,消极和积极的情感占比分别为19%、63&,反映出用户情感的总体趋势。
Lda主题分析
LDA主题分析的实现过程如下:
准备好经过数据清洗和预处理的文本数据。
使用gensim库构建语料库和词袋模型,将文本数据转换为可用于LDA模型的格式。
设置LDA模型的参数,包括主题数量、迭代次数、词频阈值等。
使用LDA模型训练语料库,并得到主题-词语分布和文档-主题分布。
根据需求,选择合适的方法获取每个主题的关键词,可以是按照权重排序或者设定阈值筛选。
可以使用pyLDAvis库对LDA模型进行可视化,生成交互式的主题模型可视化图表,并保存为HTML文件。
分析LDA主题分析结果,根据关键词和文档-主题分布了解每个主题的含义和特点,理解文本数据中不同主题的分布情况。
可以进一步对文本数据进行主题分析,根据文档-主题分布确定每个文档最可能的主题,并将主题信息添加到原始数据中。
通过LDA主题分析,可以发现文本数据中的主题结构和主要内容。主题分析可以帮助我们了解文本数据的内在关联性和分布情况,从而更好地理解文本数据的内容和意义。此外,LDA主题分析还可以用于文本分类、信息检索和推荐系统等领域,提供有关文本数据的深入洞察和应用价值。结果如下:
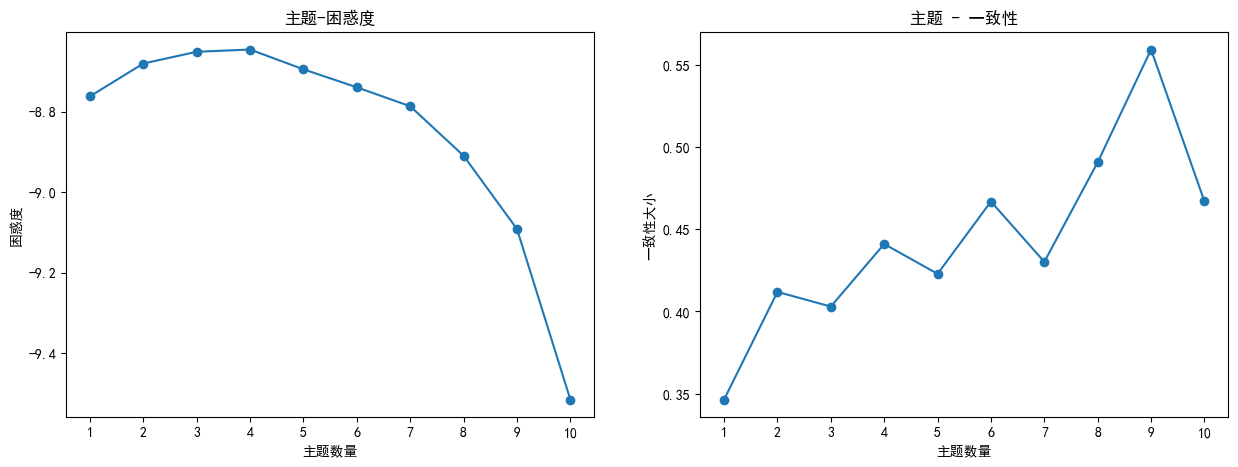
由一致性和困惑度分析曲线图可知,最优主题数9效果最好。
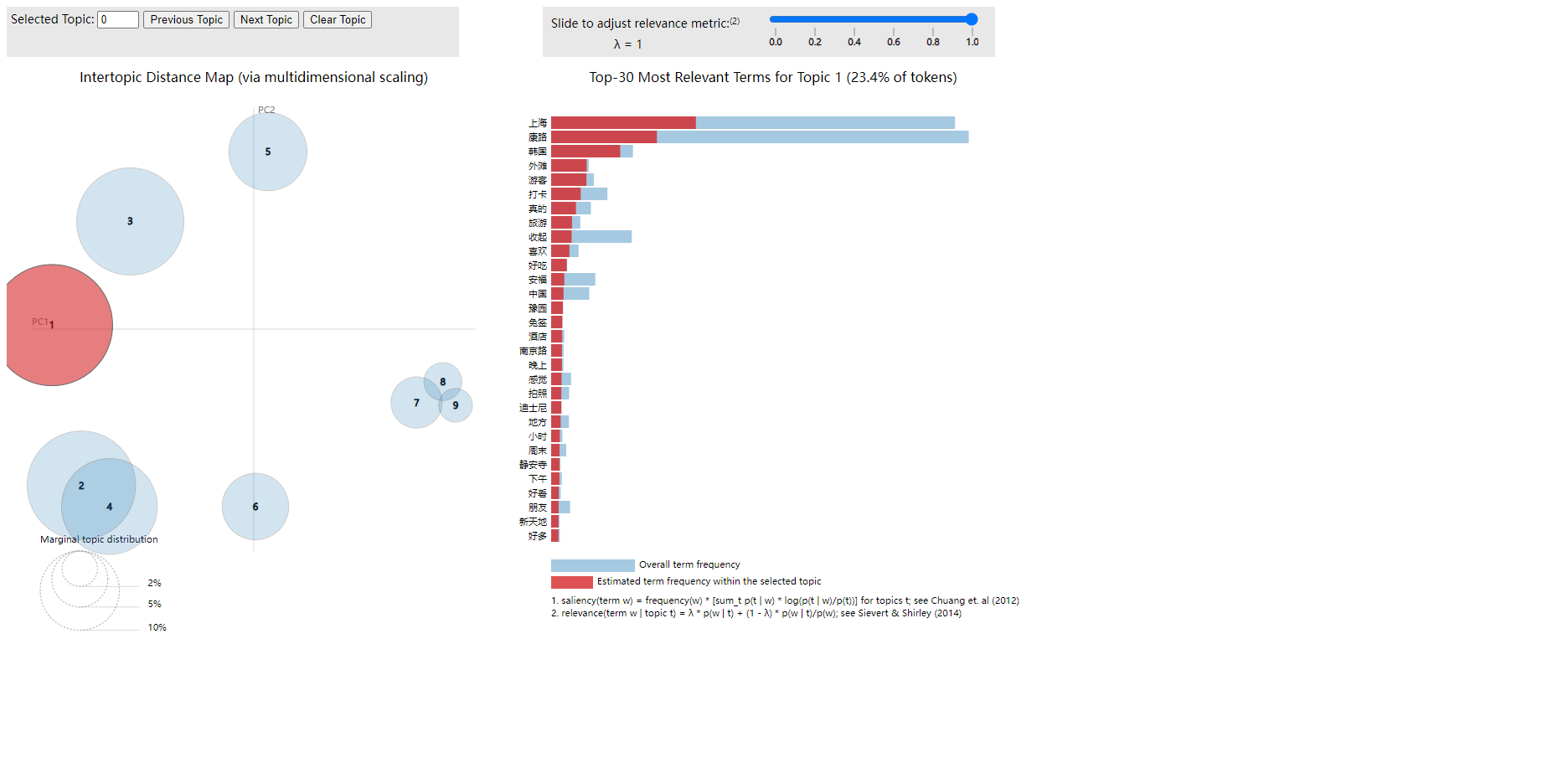
热门话题:主题0(上海、康路、韩国等)和主题3(上海、康路、大楼等)显示出较高的讨论量和权重,表明上海及其地标性区域(如康路、外滩)在社交媒体上的关注度极高。这些内容多围绕旅游、打卡和城市景观,突出了上海作为重要旅游目的地和商业中心的地位。
社会与文化:主题8(历史、文化、活动等)反映了部分用户对上海历史和文化活动的兴趣,表现出对本地文化传承和文化体验的关注。
消费与生活:主题7(豪车、生活、活动等)和主题5(共享单车、无声等)则展示了用户对现代生活方式、消费和时尚趋势的热衷,尤其是与高端消费和社交活动相关的讨论较为频繁。
Lstm预测
通过使用增强的LSTM模型进行时间序列预测,旨在预测社交媒体内容的"热度"变化。代码首先进行数据预处理,通过时间特征工程处理数据集的"发布时间"列,并提取出星期几和月份等特征。接着,构建了一个新的热度指标,这个指标结合了博文的转发数、点赞数和评论数,且使用7日滚动平均来平滑数据。
数据标准化通过RobustScaler处理,以应对可能的异常值。之后,定义了TimeSeriesDataset类,这个类将数据集转换成适用于LSTM模型的格式,每个样本包含14天的历史数据,目标是预测第15天的热度值。
增强的LSTM模型包括LSTM层、批归一化层和全连接层,用于捕捉时间序列数据中的模式和趋势。训练过程中使用MSE损失函数和Adam优化器,并采用学习率调度和早停策略来防止过拟合。
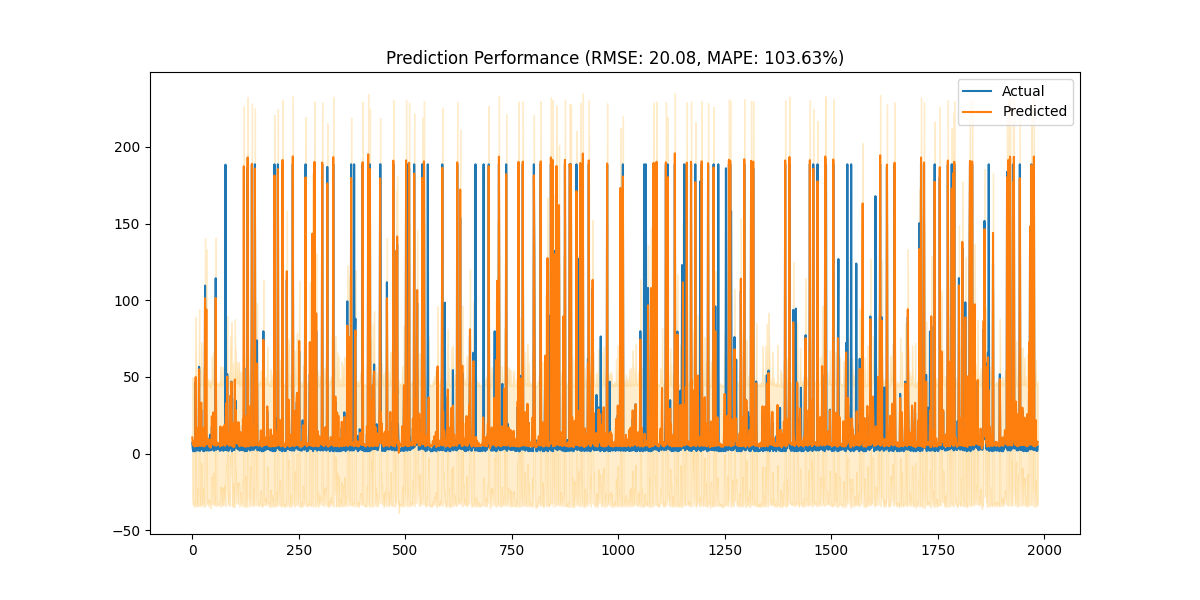
在训练完成后,评估函数会计算预测的RMSE(均方根误差)和MAPE(平均绝对百分比误差),并通过图表显示实际值与预测值的对比。此外,代码还实现了未来7天的热度预测,结合时间特征并输出结果。
最终,这个模型能够在时间序列数据的基础上对未来热度进行有效的预测如下图: