目录
[1 RGB颜色空间](#1 RGB颜色空间)
[2 颜色加法](#2 颜色加法)
[3 颜色加权加法](#3 颜色加权加法)
[4 HSV颜色空间](#4 HSV颜色空间)
[5 RGB转Gray(灰度)](#5 RGB转Gray(灰度))
[1 灰度图](#1 灰度图)
[2 最大值法](#2 最大值法)
[3 平均值法](#3 平均值法)
[4 加权均值法](#4 加权均值法)
[5 两个极端的灰度值](#5 两个极端的灰度值)
[1 阈值法(THRESH_BINARY)](#1 阈值法(THRESH_BINARY))
[2 反阈值法(THRESH_BINARY_INV)](#2 反阈值法(THRESH_BINARY_INV))
[3 截断阈值法(THRESH_TRUNC)](#3 截断阈值法(THRESH_TRUNC))
[4 低阈值零处理(THRESH_TOZERO)](#4 低阈值零处理(THRESH_TOZERO))
[5 超阈值零处理(THRESH_TOZERO_INV)](#5 超阈值零处理(THRESH_TOZERO_INV))
[6 OTSU阈值法](#6 OTSU阈值法)
[7 自适应二值化](#7 自适应二值化)
[2. 图像仿射变换](#2. 图像仿射变换)
[3. 图像旋转](#3. 图像旋转)
[4. 图像平移](#4. 图像平移)
[5. 图像缩放](#5. 图像缩放)
前言
这一章讲一下图像在色彩空间里面的转换,如何把色彩图转化为灰度图,以及如何将图像二值化处理和图像的翻转操作
**一、**图像色彩空间转换
在OpenCV中,图像色彩空间转换是一项基础且重要的操作,它涉及将图像从一种颜色表示形式转换为另一种表示形式的过程。通过这种转换,可以更有效地执行特定类型的图像处理和分析任务。常见的颜色空间包括RGB、HSV、YUV等。
- 色彩空间转换的作用:
- 提高图像处理效果:转换到更适合的色彩空间(如HSV用于颜色分割)可以提升算法的准确性和鲁棒性。
- 节省计算资源:在优化后的色彩空间中处理图像,能降低计算复杂度,从而减少资源消耗。
1 RGB颜色空间
在图像处理中,最常见的就是RGB颜色空间。RGB颜色空间是我们接触最多的颜色空间,是一种用于表示和显示彩色图像的一种颜色模型。RGB代表红色(Red)、绿色(Green)和蓝色(Blue),这三种颜色通过不同强度的光的组合来创建其他颜色,广泛应用于我们的生活中,比如电视、电脑显示屏以及上面实验中所介绍的RGB彩色图。
RGB颜色模型基于笛卡尔坐标系,如下图所示,RGB原色值位于3个角上,二次色青色、品红色和黄色位于另外三个角上,黑色位于原点处,白色位于离原点最远的角上。因为黑色在RGB三通道中表现为(0,0,0),所以映射到这里就是原点;而白色是(255,255,255),所以映射到这里就是三个坐标为最大值的点。
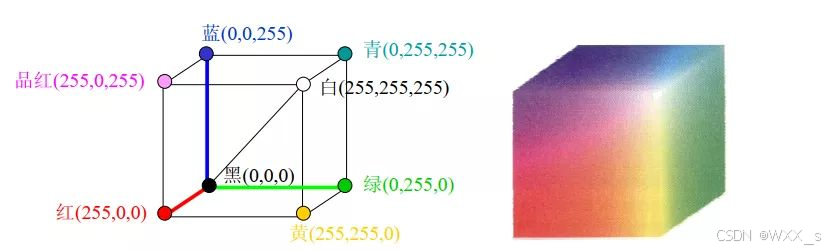
RGB颜色空间可以产生大约1600万种颜色,几乎包括了世界上的所有颜色,也就是说可以使用RGB颜色空间来生成任意一种颜色。
注意:在OpenCV中,颜色是以BGR的方式进行存储的,而不是RGB,这也是上面红色的像素值是(0,0,255)而不是(255,0,0)的原因。
2 颜色加法
图像相加的方法有两种:
- 使用OpenCV的cv.add()函数进行图像相加
- 通过我们之前学过的NumPy直接相加
OpenCV加法与NumPy加法的区别:
OpenCV加法(饱和运算)
当计算结果超出有效像素值范围(例如0-255)时,OpenCV会将结果截断到最接近的边界值。例如,加法结果为300时,输出会被限制为255;结果为-50时,输出会被限制为0。这种处理方式更适合图像处理,能避免因数值溢出导致的异常亮暗区域。
NumPy加法(模运算)
NumPy的加法基于模运算,计算结果超出有效范围时,会对255取模。例如,255+1=256,在8位图像中会输出0(对256来取模256 mod 256 = 0);300会被映射为44(对300来取模300 mod 256 = 44)。这种运算在图像处理中可能导致不自然的像素值循环,如亮区突然变暗或暗区突然变亮。
ps:讲一下模运算与取余的区别
取余运算 :
整数商(c)向 0 方向舍入(即截断小数部分,Math.trunc())。
公式:r = a - b * trunc(a / b)
结果符号与被除数(a)相同。
示例:-7 ÷ 4 → 商 c = trunc(-1.75) = -1,余数 r = -7 - (-1)*4 = -3
模运算 :
整数商(c)向 负无穷方向舍入(Math.floor())。
公式:r = a - b * floor(a / b)
结果符号与除数(b)相同。
示例:-7 ÷ 4 → 商 c = floor(-1.75) = -2,余数 r = -7 - (-2)*4 = 1
只有当被除数与除数同号时,两者结果相同(如 7 % 4 = 3,-7 % -4 = -3)
示例代码:
python
import cv2 as cv
import numpy as np
# 读取图像
pig = cv.imread("../images/pig.png")
grass = cv.imread("../images/cao.png")
# 饱和操作cv.add(img1, img2) np.uint8 0~255 250+10=255(加到最大值也只会是255,最小为0)
saturation1 = cv.add(pig, grass)
# cv.imshow("saturation1", saturation1)
# 使用numpy直接相加 取模运算 对256取模 250+10=260%256=4
saturation2 = pig + grass
# cv.imshow("saturation2", saturation2)
x = np.uint8([[250]])
y = np.uint8([[10]])
xy1 = cv.add(x, y)
xy2 = x + y
print(xy1)
print(xy2)
cv.waitKey(0)
cv.destroyAllWindows()3 颜色加权加法
python
cv2.addWeighted(src1,alpha,src2,deta,gamma)src1、src2:输入图像。
alpha、beta:两张图象权重。
gamma:亮度调整值。
gamma > 0,图像会变亮。
gamma < 0,图像会变暗。
gamma = 0,则没有额外的亮度调整。
这也是加法,但是不同的是两幅图像的权重不同,这就会给人一种混合或者透明的感觉。图像混合的计算公式如下:
g(x) = (1−α)f0(x) + αf1(x)
通过修改 α 的值(0 → 1),可以实现非常炫酷的混合。
现在我们把两幅图混合在一起。第一幅图的权重是0.7,第二幅图的权重是0.3。函数cv2.addWeighted()可以按下面的公式对图片进行混合操作。
dst = α⋅img1 + β⋅img2 + γ
这里γ取为零。
python
# 颜色加权加法 cv.addWeighted(img1, alpha(图片1的权重), img2, beta(图片2的权重), gamma(亮度调整))
dst = cv.addWeighted(pig, 0.4, grass, 0.6, 30)
cv.imshow("addWeighted", dst)4 HSV颜色空间
python
cv.cvtColor(img, cv.COLOR_BGR2HSV)HSV颜色空间指的是HSV颜色模型,这是一种与RGB颜色模型并列的颜色空间表示法。RGB颜色模型使用红、绿、蓝三原色的强度来表示颜色,是一种加色法模型,即颜色的混合是添加三原色的强度。而HSV颜色空间使用色调(Hue)、饱和度(Saturation)和亮度(Value)三个参数来表示颜色,色调H表示颜色的种类,如红色、绿色、蓝色等;饱和度表示颜色的纯度或强度,如红色越纯,饱和度就越高;亮度表示颜色的明暗程度,如黑色比白色亮度低。
HSV颜色模型是一种六角锥体模型,如下图所示:
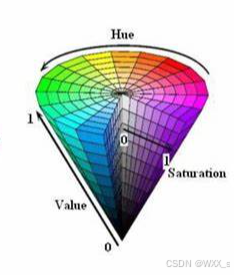
色调H:
使用角度度量,取值范围为0°~360°,从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°。它们的补色是:黄色为60°,青色为180°,紫色为300°。通过改变H的值,可以选择不同的颜色
饱和度S:
饱和度S表示颜色接近光谱色的程度。一种颜色可以看成是某种光谱色与白色混合的结果。其中光谱色所占的比例越大,颜色接近光谱色的程度就越高,颜色的饱和度就越高。饱和度越高,颜色就越深而艳,光谱色的白光成分为0,饱和度达到最高。通常取值范围为0%~100%,其中0%表示灰色或无色,100%表示纯色,通过调整饱和度的值,可以使颜色变得更加鲜艳或者更加灰暗。
明度V:
明度表示颜色明亮的程度,对于光源色,明度值与发光体的光亮度有关;对于物体色,此值和物体的透射比或反射比有关。通常取值范围为0%(黑)到100%(白),通过调整明度的值,可以使颜色变得更亮或者更暗。
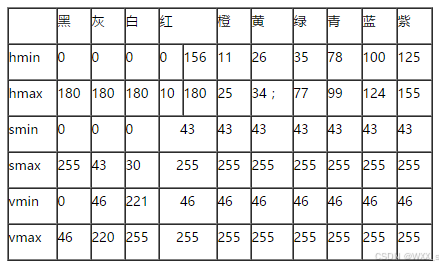
一般对颜色空间的图像进行有效处理都是在HSV空间进行的,然后对于基本色中对应的HSV分量需要给定一个严格的范围,下面是通过实验计算的模糊范围(准确的范围在网上都没有给出)。
H: 0--- 180
S: 0--- 255
V: 0--- 255
此处把部分红色归为紫色范围:
为什么有了RGB颜色空间我们还是需要转换成HSV颜色空间来进行图像处理呢?
符合人类对颜色的感知方式:人类对颜色的感知是基于色调、饱和度和亮度三个维度的,而HSV颜色空间恰好就是通过这三个维度来描述颜色的。因此,使用HSV空间处理图像可以更直观地调整颜色和进行色彩平衡等操作,更符合人类的感知习惯。
颜色调整更加直观:在HSV颜色空间中,色调、饱和度和亮度的调整都是直观的,而在RGB颜色空间中调整颜色不那么直观。例如,在RGB空间中要调整红色系的颜色,需要同时调整R、G、B三个通道的数值,而在HSV空间中只需要调整色调和饱和度即可。
降维处理有利于计算:在图像处理中,降维处理可以减少计算的复杂性和计算量。HSV颜色空间相对于RGB颜色空间,减少了两个维度(红、绿、蓝),这有利于进行一些计算和处理任务,比如色彩分割、匹配等。
因此,在进行图片颜色识别时,我们会将RGB图像转换到HSV颜色空间,然后根据颜色区间来识别目标颜色。
5 RGB转Gray(灰度)
cv2.cvtColor 是OpenCV中的一个函数,用于图像颜色空间的转换。可以将一个图像从一个颜色空间转换为另一个颜色空间,比如从RGB到灰度图,或者从RGB到HSV的转换等。
python
cv2.cvtColor(img,code)img 参数
可以传入 NumPy 数组或 OpenCV 的 Mat 对象。Python 中 OpenCV 函数通常直接处理 NumPy 数组,OpenCV 会自动在 Mat 和数组之间转换。例如 cv2.imread()返回的就是 NumPy 数组。
code 参数
用于指定颜色空间转换类型。例如:
cv2.COLOR_RGB2GRAY 表示将 RGB 图像转为灰度图
其他常见代码包括 cv2.COLOR_BGR2RGB 等
示例代码:
python
import cv2 as cv
# 读取图像
img = cv.imread("../images/1.jpg")
# 颜色转换 cv.cvtColor(img, code, dst, dstCn)
# 转灰度图
dst = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
cv.imshow("src", dst)
# 转HSV
dst1 = cv.cvtColor(img, cv.COLOR_BGR2HSV)
cv.imshow("HSV", dst1)
# 转RGB
dst2 = cv.cvtColor(img, cv.COLOR_BGR2RGB)
cv.imshow("RGB", dst2)
cv.waitKey(0)二、灰度实验
彩色图像转换为灰度图像(灰度化)是图像处理和计算机视觉中的基础操作,其核心是将RGB三通道信息融合为单通道数据。彩色图像由红(R)、绿(G)、蓝(B)三通道组成,而灰度图仅保留单一亮度通道。灰度化本质是通过数学映射将三维颜色空间压缩为一维亮度值。
1 灰度图
灰度图像指每个像素仅包含单一采样颜色的图像,通常表现为从纯黑到纯白之间的连续过渡色调。尽管采样颜色理论上可为任意色调的不同明度变化,甚至可呈现不同亮度下的异色效果,但实际应用中多采用可见光谱范围内的亮度测量值。
黑白图像(二值图像)仅包含绝对黑与绝对白两种颜色状态。相比之下,灰度图像具有丰富的过渡层次,通过在黑白之间设置多级颜色深度实现平滑的亮度渐变。典型计算机系统中,显示用的灰度图像采用8位非线性存储格式,可精确记录256级灰度值。
灰度图像的生成通常基于单电磁波频谱的像素亮度测量。每个像素点的数值对应特定亮度级别,这种线性或非线性量化过程保留了原始场景的光照信息。8位存储方案通过二进制编码实现高效的灰度等级存储,其中0代表全黑,255代表全白。

2 最大值法
对于彩色图像的每个像素,它会从R、G、B三个通道的值中选出最大的一个,并将其作为灰度图像中对应位置的像素值。
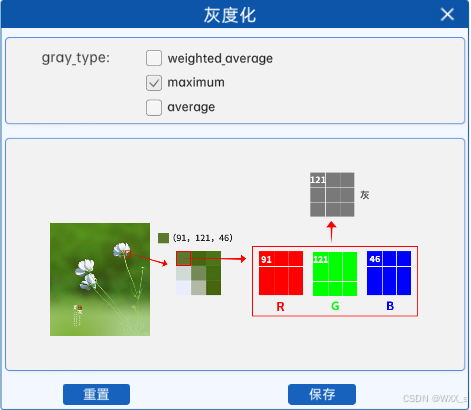
例如某图像中某像素点的像素值如上图所示,那么在使用最大值法进行灰度化时,就会从该像素点对应的RGB通道中选取最大的像素值作为灰度值,所以在灰度图中的对应位置上,该像素点的像素值就是121。
示例代码:
python
import cv2 as cv
import numpy as np
# 读取图像
pig = cv.imread("../images/pig.png")
shape = pig.shape
img = np.zeros((shape[0], shape[1]), dtype=np.uint8)
# 循环遍历每一行
for i in range(shape[0]):
for j in range(shape[1]):
img[i, j] = max(pig[i, j, 0], pig[i, j, 1], pig[i, j, 2])
cv.imshow("pig", img)
cv.waitKey(0)
cv.destroyAllWindows()3 平均值法
对于彩色图像的每个像素,它会将R、G、B三个通道的像素值全部加起来,然后再除以三,得到的平均值就是灰度图像中对应位置的像素值。

例如某图像中某像素点的像素值如上图所示,那么在使用平均值进行灰度化时,其计算结果就是(91+121+46)/3=86(对结果进行取整),所以在灰度图中的对应位置上,该像素点的像素值就是86。
示例代码:
python
import cv2 as cv
import numpy as np
# 读取图像
pig = cv.imread("../images/pig.png")
shape = pig.shape
img = np.zeros((shape[0], shape[1]), dtype=np.uint8)
# 循环遍历每一行
for i in range(shape[0]):
for j in range(shape[1]):
# int():转为更大的数据类型,防止溢出
img[i, j] = np.uint8((int(pig[i, j, 0]) + int(pig[i, j, 1]) + int(pig[i, j, 2])) // 3)
cv.imshow("pig", img)
cv.waitKey(0)
cv.destroyAllWindows()4 加权均值法
对于彩色图像的每个像素,它会按照一定的权重去乘以每个通道的像素值,并将其相加,得到最后的值就是灰度图像中对应位置的像素值。本实验中,权重的比例为: R乘以0.299,G乘以0.587,B乘以0.114,这是经过大量实验得到的一个权重比例,也是一个比较常用的权重比例。
所使用的权重之和应该等于1。这是为了确保生成的灰度图像素值保持在合理的亮度范围内,并且不会因为权重的比例不当导致整体过亮或过暗。
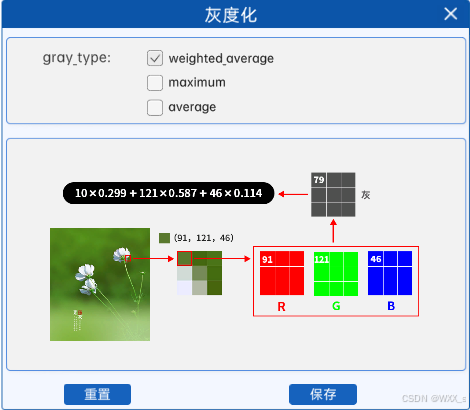
例如某图像中某像素点的像素值如上图所示,那么在使用加权平均值进行灰度化时,其计算结果就是10*0.299+121*0.587+46*0.114=79。所以在灰度图中的对应位置上,该像素点的像素值就是79。
代码示例:
python
import cv2 as cv
import numpy as np
# 读取图像
pig = cv.imread("../images/pig.png")
shape = pig.shape
img = np.zeros((shape[0], shape[1]), dtype=np.uint8)
# 定义权重
wb, wg, wr = 0.114, 0.587, 0.299
# 循环遍历每一行
for i in range(shape[0]):
for j in range(shape[1]):
img[i, j] = round(wb * pig[i, j, 0] + wg * pig[i, j, 1] + wr * pig[i, j, 2])
cv.imshow("pig", img)
cv.waitKey(0)
cv.destroyAllWindows()5 两个极端的灰度值
在灰度图像中,"极端"的灰度值指的是亮度的两个极端:最暗和最亮的值。
-
最暗的灰度值:0。这代表完全黑色,在灰度图像中没有任何亮度。
-
最亮的灰度值:255。这代表完全白色,在灰度图像中具有最大亮度。

三、图像二值化处理
二值图像
将某张图像的所有像素改成只有两种值之一。 一幅二值图像的二维矩阵仅由0、1两个值构成,"0"代表黑色,"1"代白色。由于每一像素(矩阵中每一元素)取值仅有0、1两种可能,所以计算机中二值图像的数据类型通常为1个二进制位。二值图像通常用于文字、线条图的扫描识别(OCR)和掩膜图像的存储。

其操作的图像也必须是灰度图,也就是说,二值化的过程,就是将一张灰度图上的像素根据某种规则修改为0和maxval(maxval表示最大值,一般为255,显示白色)两种像素值,使图像呈现黑白的效果,能够帮助我们更好地分析图像中的形状、边缘和轮廓等特征。
简便:降低计算量和计算需求,加快处理速度。
节约资源:二值图像占用空间远小于彩色图。
边缘检测:二值化常作为边缘检测的预处理步骤,因为简化后的图易于识别出轮廓和边界。
1~6是所有阈值法的解释
python
_,binary = cv2.threshold(img,thresh,maxval,type)img:输入图像,要进行二值化处理的灰度图。
thresh:设定的阈值。当像素值大于(或小于,取决于阈值类型)thresh时,该像素被赋予的值。
type:阈值处理的类型。
返回值:
第一个值(通常用下划线表示):计算出的阈值,若使用自适应阈值法,会根据算法自动计算出这个值。
第二个值(binary):二值化后的图像矩阵。与输入图像尺寸相同。
在本实验中,使用了六种不同的方式来对灰度图进行二值化。
1 阈值法(THRESH_BINARY)
阈值法就是通过设置一个阈值,将灰度图中的每一个像素值与该阈值进行比较,小于等于阈值的像素就被设置为0(通常代表背景),大于阈值的像素就被设置为maxval(通常代表前景)。对于我们的8位图像(0~255)来说,通常是设置为255。
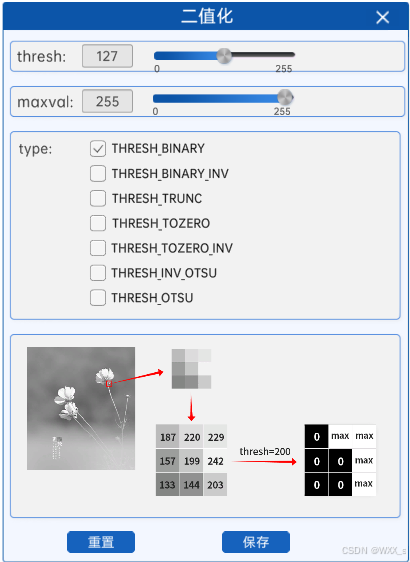

如上图所示,在灰度图中像素值较高的地方,如花瓣、花茎等地方的像素值比阈值高,那么在生成的二值化图中的对应位置的像素值就会被设置为255,也就是纯白色。
cv2.IMREAD_GRAYSCALE:OpenCV 中用于指定图像加载模式的一个标志,它告诉 cv.imread() 函数以灰度格式读取图像。
示例代码统一放在7下面
2 反阈值法(THRESH_BINARY_INV)
顾名思义,就是与阈值法相反。反阈值法是当灰度图的像素值大于阈值时,该像素值将会变成0(黑),当灰度图的像素值小于等于阈值时,该像素值将会变成maxval。
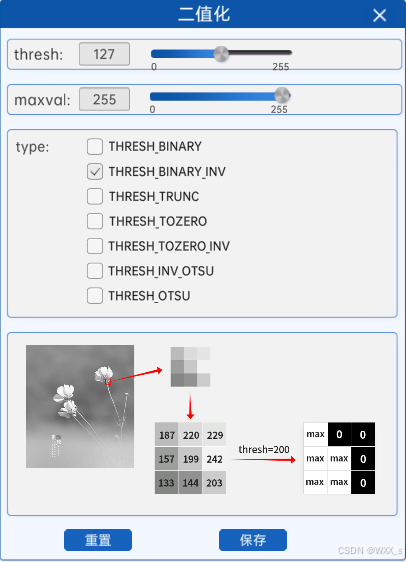

如上图所示,使用反阈值法对灰度图进行二值化时,会将灰度图中像素值大于阈值的地方置为0(也就是黑),将灰度图中像素值小于阈值的地方置为255(也就是白)。
示例代码统一放在7下面
3 截断阈值法(THRESH_TRUNC)
截断阈值法,指将灰度图中的所有像素与阈值进行比较,像素值大于阈值的部分将会被修改为阈值,小于等于阈值的部分不变。换句话说,经过截断阈值法处理过的二值化图中的最大像素值就是阈值。
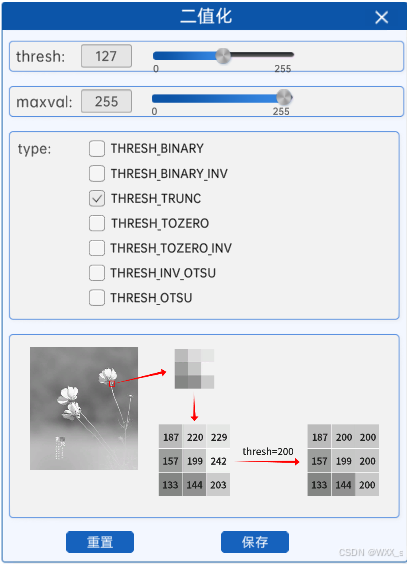

当截断阈值为255时,如上图所示,可以看到灰度图与二值化图没有任何的区别。
使用截断阈值法进行图像二值化处理时,设置的maxval参数实际上是不起作用的。
示例代码统一放在7下面
4 低阈值零处理(THRESH_TOZERO)
低阈值零处理,字面意思,就是像素值小于等于阈值的部分被置为0(也就是黑色),大于阈值的部分不变。
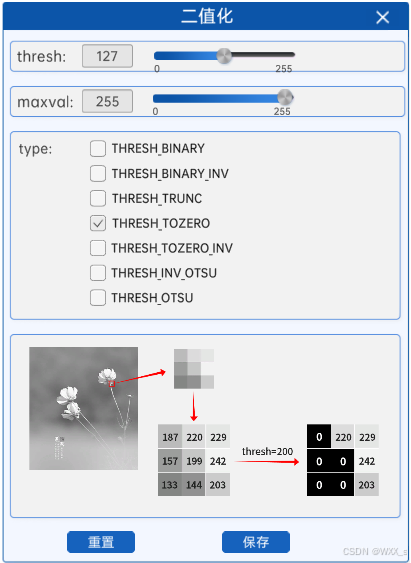

如上图所示,在灰度图中较亮的部分,其像素值比阈值大,所以在二值化后其像素值并没有发生变化。而灰度图中较暗的部分,也就是像素值较低的地方,由于像素值比阈值小,就会被置为0,对应二值化图中的黑色部分。
示例代码统一放在7下面
5 超阈值零处理(THRESH_TOZERO_INV)
超阈值零处理就是将灰度图中的每个像素与阈值进行比较,像素值大于阈值的部分置为0(也就是黑色),像素值小于等于阈值的部分不变。
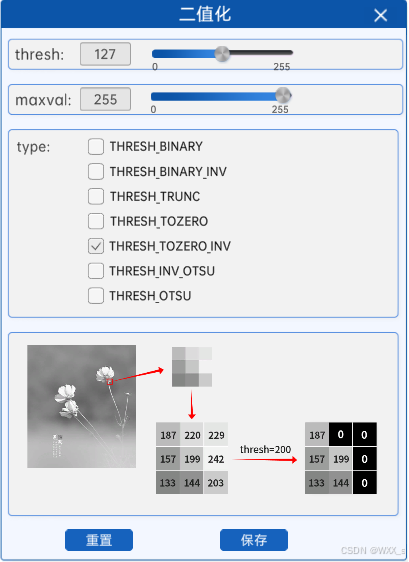

如上图所示,在灰度图中较亮的部分,其像素值比阈值大,所以在二值化后其像素值会被置为0(也就是黑色),对应二值化图中的黑色部分。而灰度图中较暗的部分,也就是像素值较低的地方,由于像素值比阈值小,将不会发生改变。
以上介绍的二值化方法都需要手动设置阈值,但是在不同的环境下,摄像头拍摄的图像可能存在差异,导致手动设置的阈值并不适用于所有图像,这可能会导致二值化效果不理想。
因此,我们需要一种能自动计算每张图片阈值的二值化方法,能够根据每张图像的特点自动计算出适合该图像的二值化阈值,从而达到更好的二值化效果。这种二值化方法可以在不同环境下适用,提高图像处理的准确性和鲁棒性。
示例代码统一放在7下面
6 OTSU阈值法
cv2.THRESH_OTS 并不是一个有效的阈值类型或标。THRESH_OTSU 本身并不是一个独立的阈值化方法,而是与 OpenCV 中的二值化方法结合使用的一个标志。具体来说,THRESH_OTSU 通常与 THRESH_BINARY 或 THRESH_BINARY_INV 结合使用。在实际应用中,如果你使用 THRESH_OTSU 标志但没有指定其他二值化类型,默认情况下它会与 THRESH_BINARY 结合使用。也就是说,当你仅指定了 cv2.THRESH_OTSU,实际上等同于同时指定了 cv2.THRESH_BINARY + cv2.THRESH_OTSU。
简单来说就是cv2.THRESH_OTSU 是 OpenCV 中用于自动计算最优阈值的标志,但它需要与其他二值化方法(如 cv2.THRESH_BINARY 或 cv2.THRESH_BINARY_INV)结合使用。单独指定该标志时,OpenCV 默认会将其与 cv2.THRESH_BINARY 组合。
在介绍OTSU阈值法之前,我们首先要了解一下双峰图片的概念。
双峰图片就是指灰度图的直方图上有两个峰值,直方图就是对灰度图中每个像素值的点的个数的统计图,如下图所示。
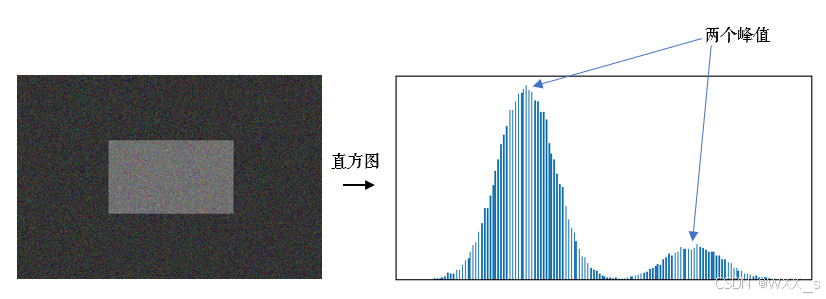
灰度图直方图的基础概念
-
灰度级:
-
在灰度图像中,每个像素的值代表其亮度,通常范围是 0 到 255(对于 8 位灰度图像)。
-
0 表示黑色,255 表示白色,中间的值表示不同程度的灰色。
-
-
直方图定义:
-
直方图是一个柱状图,其中 x 轴表示灰度级(从 0 到 255),y 轴表示对应灰度级在图像中出现的次数(频率)。
-
每个柱子的高度代表该灰度级在图像中出现的像素数量。
-
OTSU算法是通过一个值将这张图分前景色和背景色(也就是灰度图中小于这个值的是一类,大于这个值的是一类。例如,如果你设置阈值为128,则所有大于128的像素点可以被视作前景,而小于等于128的像素点则被视为背景。),通过统计学方法(最大类间方差)来验证该值的合理性,当根据该值进行分割时,使用最大类间方差计算得到的值最大时,该值就是二值化算法中所需要的阈值。通常该值是从灰度图中的最小值加1开始进行迭代计算,直到灰度图中的最大像素值减1,然后把得到的最大类间方差值进行比较,来得到二值化的阈值。以下是一些符号规定:
T:阈值
:前景像素点数
:背景像素点数
:前景的像素点数占整幅图像的比例
:背景的像素点数占整幅图像的比例
0:前景的平均像素值
1:背景的平均像素值
:整幅图的平均像素值
rows×cols:图像的行数和列数
下面举个例子,有一张大小为4×4的图片,假设阈值T为1,那么:

也就是这张图片根据阈值1分为了前景(像素为2的部分)和背景(像素为0)的部分,并且计算出了OTSU算法所需要的各个数据,根据上面的数据,我们给出计算类间方差的公式:
g就是前景与背景两类之间的方差,这个值越大,说明前景和背景的差别就越大,效果就越好。OTSU算法就是在灰度图的像素值范围内遍历阈值T,使得g最大,基本上双峰图片的阈值T在两峰之间的谷底。
通过OTSU算法得到阈值之后,就可以结合上面的方法根据该阈值进行二值化,在本实验中有THRESH_OTSU和THRESH_INV_OTSU两种方法,就是在计算出阈值后结合了阈值法和反阈值法。
注意:使用OTSU算法计算阈值时,组件中的thresh参数将不再有任何作用。
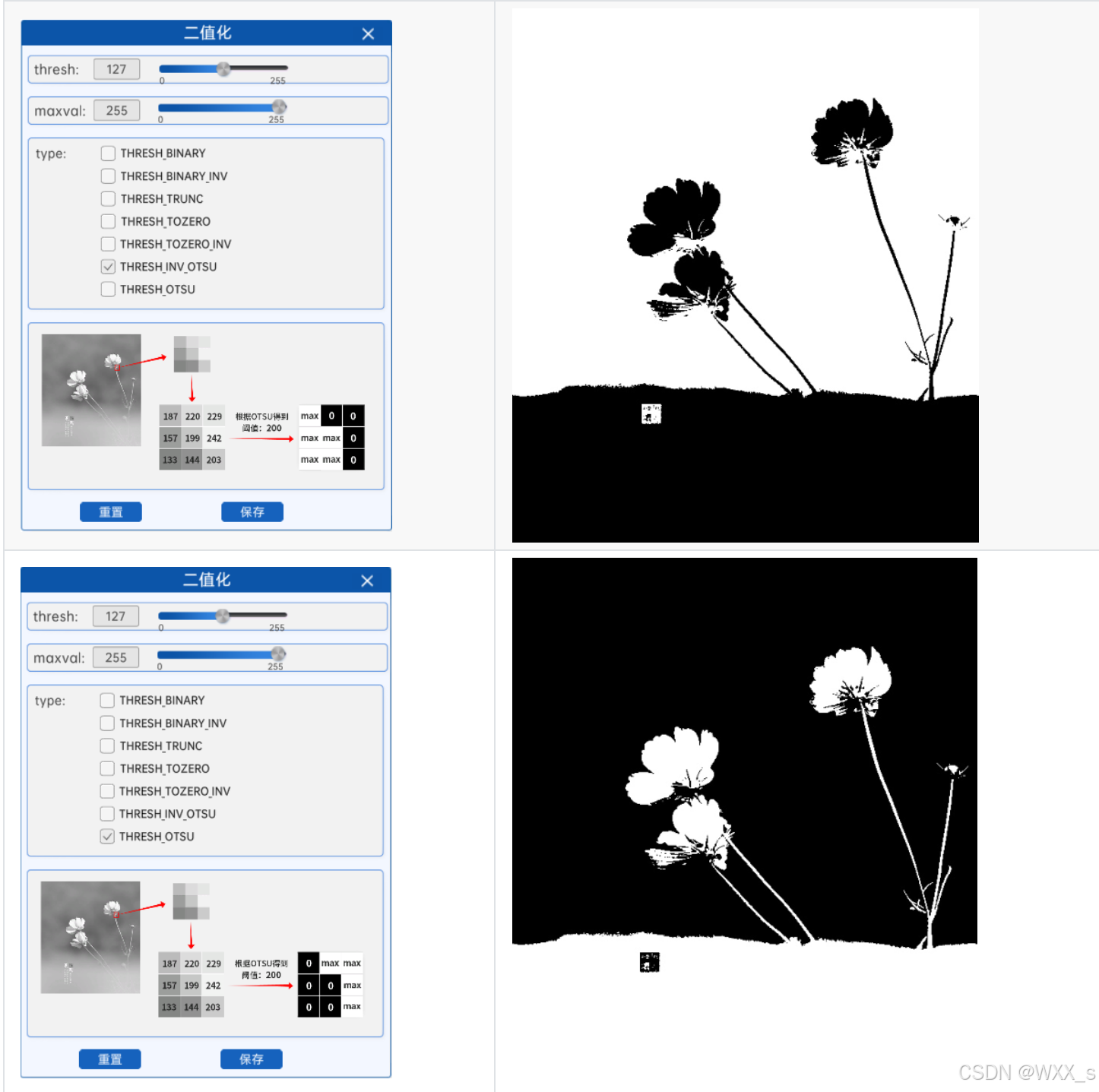
示例代码统一放在7下面
7 自适应二值化
python
cv2.adaptiveThreshold(image_np_gray, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 7, 10)与二值化算法相比,自适应二值化更加适合用在明暗分布不均的图片,因为图片的明暗不均,导致图片上的每一小部分都要使用不同的阈值进行二值化处理,这时候传统的二值化算法就无法满足我们的需求了,于是就出现了自适应二值化。
自适应二值化方法会对图像中的所有像素点计算其各自的阈值,这样能够更好的保留图片里的一些信息。自适应二值化组件内容如下图所示:
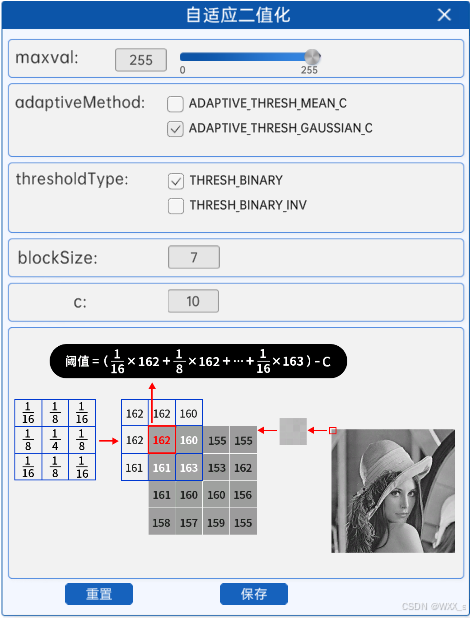
其中各个参数的含义如下:
maxval :最大阈值,一般为255
adaptiveMethod :小区域阈值的计算方式:
ADAPTIVE_THRESH_MEAN_C :小区域内取均值
ADAPTIVE_THRESH_GAUSSIAN_C :小区域内加权求和,权重是个高斯核
thresholdType :二值化方法,只能使用THRESH_BINARY、THRESH_BINARY_INV,也就是阈值法和反阈值法
blockSize :选取的小区域的面积,如7就是7\*7的小块。
c :最终阈值等于小区域计算出的阈值再减去此值
下面介绍一下这两种方法。
7.1.取均值
比如一张图片的左上角像素值如下图所示:
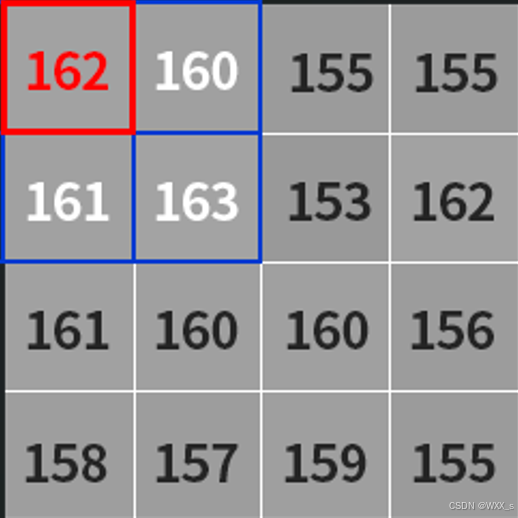
假如我们使用的小区域是3*3的,那么就会从图片的左上角开始(也就是像素值为162的地方)计算其邻域内的平均值,如果处于边缘地区就会对边界进行填充,填充值就是边界的像素点,如下图所示:

那么对于左上角像素值为162的这个点,161(也就是上图中括号内的计算结果,结果会进行取整)就是根据平均值计算出来的阈值,接着减去一个固定值C,得到的结果就是左上角这个点的二值化阈值了,接着根据选取的是阈值法还是反阈值法进行二值化操作。紧接着,向右滑动计算每个点的邻域内的平均值,直到计算出右下角的点的阈值为止。我们所用到的不断滑动的小区域被称之为核,比如3*3的小区域叫做3*3的核,并且核的大小都是奇数个,也就是3*3、5*5、7*7等。
自适应二值化(Adaptive Thresholding)的核心思想就是为图像中的每个像素点计算一个局部阈值。这种方法与全局阈值化不同,后者对整个图像使用同一个固定的阈值。而在自适应二值化中,每个像素的阈值是基于其周围邻域内的像素值动态确定的。
7.2.加权求和
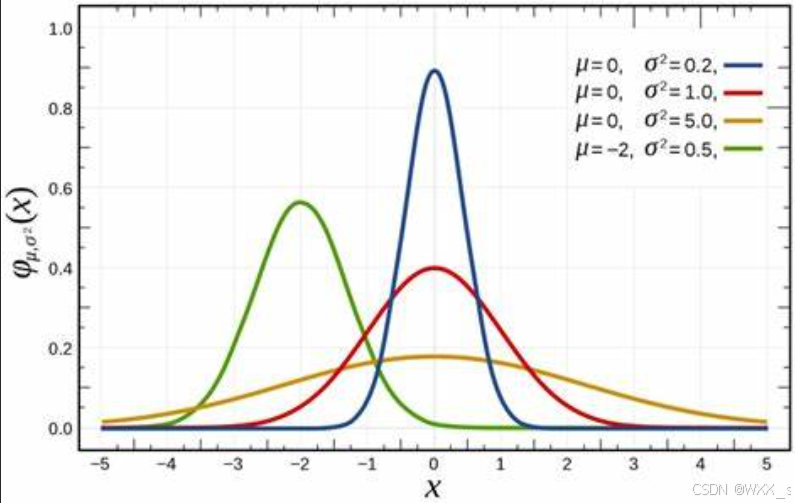
对小区域内的像素进行加权求和得到新的阈值,其权重值来自于高斯分布。
高斯分布,通过概率密度函数来定义高斯分布,一维高斯概率分布函数为:
通过改变函数中和的值,我们可以得到如下图像,其中均值为,标准差为
。
此时我们拓展到二维图像,一般情况下我们使x轴和y轴的相等并且,此时我们可以得到二维高斯函数的表达式为:
高斯概率函数是相对于二维坐标产生的,其中(x,y)为点坐标,要得到一个高斯滤波器模板,应先对高斯函数进行离散化,将得到的值作为模板的系数。例如:要产生一个3*3的高斯权重核,以核的中心位置为坐标原点进行取样,其周围的坐标如下图所示(x轴水平向右,y轴竖直向上)
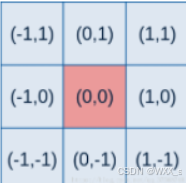
将坐标带入上面的公式中,即可得到一个高斯权重核。
而在opencv里,当kernel(小区域)的尺寸为1、3、5、7并且用户没有设置sigma的时候(sigma <= 0),核值就会取固定的系数,这是一种默认的值是高斯函数的近似。
| kernel尺寸 | 核值 |
|---|---|
| 1 | 1 |
| 3 | 0.25, 0.5, 0.25 |
| 5 | 0.0625, 0.25, 0.375, 0.25, 0.0625 |
| 7 | 0.03125, 0.109375, 0.21875, 0.28125, 0.21875, 0.109375, 0.03125 |
比如kernel的尺寸为3*3时,使用
进行矩阵的乘法,就会得到如下的权重值,其他的类似。
通过这个高斯核,即可对图片中的每个像素去计算其阈值,并将该阈值减去固定值得到最终阈值,然后根据二值化规则进行二值化。
而当kernels尺寸超过7的时候,如果sigma设置合法(用户设置了sigma),则按照高斯公式计算.当sigma不合法(用户没有设置sigma),则按照如下公式计算sigma的值:
某像素点的阈值计算过程如下图所示:
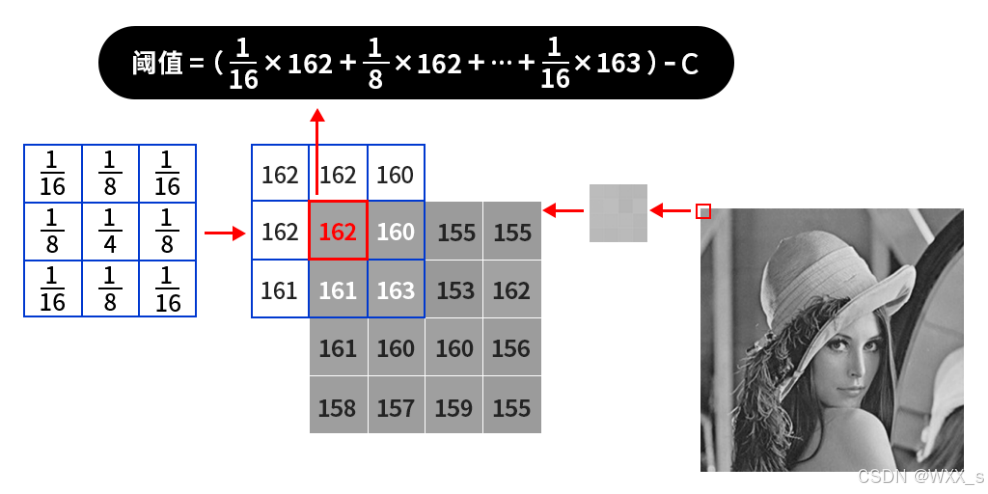
首先还是对边界进行填充,然后计算原图中的左上角(也就是162像素值的位置)的二值化阈值,其计算过程如上图所示,再然后根据选择的二值化方法对左上角的像素点进行二值化,之后核向右继续计算第二个像素点的阈值,第三个像素点的阈值...直到右下角(也就是155像素值的位置)为止。
当核的大小不同时,仅仅是核的参数会发生变化,计算过程与此是一样的。
cv2.adaptiveThreshold参数解释:
image_np_gray: 输入图像,这里必须是灰度图像(单通道)。
255: 输出图像的最大值。在二值化后,超过自适应阈值的像素会被设置为该最大值,通常为255表示白色;未超过阈值的像素将被设置为0,表示黑色。
cv2.ADAPTIVE_THRESH_GAUSSIAN_C: 自适应阈值类型。在这个例子中,使用的是高斯加权的累计分布函数(CDF),并添加一个常数 C 来计算阈值。另一种可选类型是 cv2.ADAPTIVE_THRESH_MEAN_C,它使用邻域内的平均值加上常数 C 计算阈值。
cv2.THRESH_BINARY: 输出图像的类型。这意味着输出图像将会是一个二值图像(binary image),其中每个像素要么是0要么是最大值(在这里是255)。另外还有其他选项如 cv2.THRESH_BINARY_INV 会得到相反的二值图像。
7: blockSize 参数,表示计算每个像素阈值时所考虑的7x7邻域大小(正方形区域的宽度和高度),其值必须是奇数。
10: C 参数,即上面提到的常数值,在计算自适应阈值时与平均值或高斯加权值相加。正值增加阈值,负值降低阈值,具体效果取决于应用场景。
二值化代码示例:
python
import cv2 as cv
# 读图
flower = cv.imread('../images/flower.png')
flower = cv.resize(flower, (0, 0), fx=0.5, fy=0.5)
# 灰度化
gray = cv.cvtColor(flower, cv.COLOR_BGR2GRAY)
cv.imshow("1", gray)
# 二值化 阈值法
ret, binary1 = cv.threshold(gray, 127, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)
# cv.imshow('binary1', binary1)
# 二值化 反阈值法
_, binary_inv = cv.threshold(gray, 127, 255, cv.THRESH_BINARY_INV)
# cv.imshow('binary2', binary_inv)
# 二值化 截断阈值法
_, binary_trunc = cv.threshold(gray, 127, 255, cv.THRESH_TRUNC)
# cv.imshow('binary3', binary_trunc)
# 二值化 低阈值零处理
_, binary_tozero = cv.threshold(gray, 127, 255, cv.THRESH_TOZERO)
# cv.imshow('binary4', binary_tozero)
# 二值化 超阈值零处理
_, binary_tozero_inv = cv.threshold(gray, 127, 255, cv.THRESH_TOZERO_INV)
# cv.imshow('binary5', binary_tozero_inv)
# OTSU阈值法 默认结合cv.THRESH_BINARY cv.THRESH_OTSU = cv.THRESH_BINARY + cv.THRESH_OTSU
_, binary_otsu = cv.threshold(gray, 200, 255, cv.THRESH_OTSU)
# cv.imshow('binary_otsu', binary_otsu)
_, binary_otsu1 = cv.threshold(gray, 200, 255, cv.THRESH_OTSU + cv.THRESH_BINARY_INV)
# cv.imshow('binary_otsu1', binary_otsu1)
# 自适应二值化 小区域计算 必须结合阈值法或者反阈值法,否则会报错,但只能结合一个
# 取均值
binary_adaptive = cv.adaptiveThreshold(gray, 255, cv.ADAPTIVE_THRESH_MEAN_C, cv.THRESH_BINARY, 9, 6)
cv.imshow('binary_adaptive', binary_adaptive)
# 加权均值法 高斯核
binary_adaptive_gaussian = cv.adaptiveThreshold(gray, 255, cv.ADAPTIVE_THRESH_GAUSSIAN_C, cv.THRESH_BINARY, 9, 6)
cv.imshow('binary_adaptive_gaussian', binary_adaptive_gaussian)
cv.waitKey(0)
cv.destroyAllWindows()四、图像变换操作
1.图像翻转(图像镜像旋转)
在OpenCV中,图片的镜像旋转是以图像的中心为原点进行镜像翻转的。
-
cv2.flip(img,flipcode)
-
参数
-
img: 要翻转的图像
-
flipcode: 指定翻转类型的标志
-
flipcode=0: 垂直翻转,图片像素点沿x轴翻转
-
flipcode>0: 水平翻转,图片像素点沿y轴翻转
-
flipcode<0: 水平垂直翻转,水平翻转和垂直翻转的结合
-
-
python
import cv2 as cv
face = cv.imread("../images/gezi.png")
face = cv.resize(face, (0, 0), fx=0.5, fy=0.5)
cv.imshow("face", face)
# flipcode = 0 表示垂直翻转 沿着x轴翻转 上下翻转 1 表示水平翻转 沿着y轴翻转 左右翻转
filp_0 = cv.flip(face, 0)
cv.imshow("filp_0", filp_0)
filp_1 = cv.flip(face, 1)
cv.imshow("filp_1", filp_1)
filp_2 = cv.flip(face, -1)
cv.imshow("filp_2", filp_2)
cv.waitKey(0)
cv.destroyAllWindows()2. 图像仿射变换
仿射变换(Affine Transformation)是一种线性变换,保持了点之间的相对距离不变。
仿射变换的基本性质
-
保持直线
-
保持平行
-
比例不变性
-
不保持角度和长度
常见的仿射变换类型
-
旋转:绕着某个点或轴旋转一定角度。
-
平移:仅改变物体的位置,不改变其形状和大小。
-
缩放:改变物体的大小。
-
剪切:使物体发生倾斜变形。
仿射变换的基本原理
-
线性变换
-
二维空间中,图像点坐标为(x,y),仿射变换的目标是将这些点映射到新的位置 (x', y')。
-
为了实现这种映射,通常会使用一个矩阵乘法的形式:
(类似于y=kx+b)
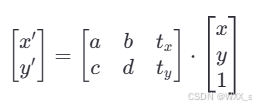
-
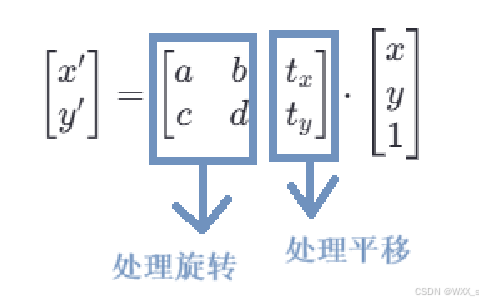
a,b,c,d 是线性变换部分的系数,控制旋转、缩放和剪切。
-
,
-
输入点的坐标被扩展为齐次坐标形式x,y,1,以便能够同时处理线性变换和平移
cv2.warpAffine()函数
- 仿射变换函数
python
cv2.warpAffine(img,M,dsize)- g:输入图像。
- M:2x3的变换矩阵,类型为np.float32。
- dsize:输出图像的尺寸,形式为(width,height)。
3. 图像旋转
旋转图像可以将图像绕着某个点旋转一定的角度。
cv2.getRotationMatrix2D()函数
-
获取旋转矩阵
pythoncv2.getRotationMatrix2D(center,angle,scale)-
center :旋转中心点的坐标,格式为
(x,y)。 -
angle:旋转角度,单位为度,正值表示逆时针旋转负值表示顺时针旋转。
-
scale:缩放比例,若设为1,则不缩放。
-
返回值 :M,2x3的旋转矩阵。
-
python
import cv2 as cv
cat = cv.imread("../images/cat1.png")
cat = cv.resize(cat, (520, 520))
# 获取旋转矩阵 cv2.getRotationMatrix2D(旋转中心center,旋转角度angle,缩放因子scale)
matrix = cv.getRotationMatrix2D((260, 260), -45, 1)
# 仿射变换 cv2.warpAffine(src, M, dsize) (w, h)
result = cv.warpAffine(cat, matrix, (520, 520))
cv.imshow("result", result)
cv.waitKey(0)
cv.destroyAllWindows()4. 图像平移
移操作可以将图像中的每个点沿着某个方向移动一定的距离。
-
假设我们有一个点 P(x,y),希望将其沿x轴方向平移t_x*个单位,沿y轴方向平移t_y个单位到新的位置P′(x′,y′),那么平移公式如下:
x′=x+tx
y′=y+ty
在矩阵形式下,该变换可以表示为:
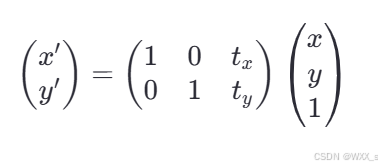
这里的和
分别代表在x轴和y轴上的平移量。
python
import cv2 as cv
import numpy as np
cat = cv.imread("../images/cat1.png")
cat = cv.resize(cat, (520, 520))
# 定义平移量
tx = 80
ty = 120
# 定义平移矩阵
M = np.float32([[1, 0, tx], [0, 1, ty]])
# 仿射变换
dst = cv.warpAffine(cat, M, (400, 400))
cv.imshow("result", dst)
cv.waitKey(0)
cv.destroyAllWindows()5. 图像缩放
缩放操作可以改变图片的大小。
-
假设要把图像的宽高分别缩放为0.5和0.8,那么对应的缩放因子sx=0.5,sy=0.8。
-
点P(x,y)对应到新的位置
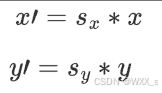
在矩阵形式下,该变换可以表示为
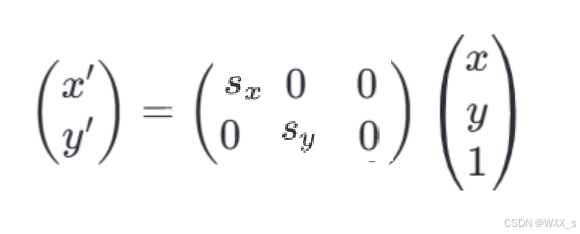
相较于图像旋转中只能等比例的缩放,图像缩放更加灵活,可以在指定方向上进行缩放。
sx和sy分别表示在x轴和y轴方向上的缩放因子。
python
import cv2 as cv
import numpy as np
cat = cv.imread("../images/cat1.png")
cat = cv.resize(cat, (520, 520))
# 缩小量
sx = 0.5
sy = 0.5
# 定义平移矩阵
M = np.float32([[sx, 0, 0], [0, sy, 0]])
# 仿射变换
dst = cv.warpAffine(cat, M, (400, 400))
cv.imshow("result", dst)
cv.waitKey(0)
cv.destroyAllWindows()总结
今天内容有点多,我觉得重要的地方是理解公式的含义,只要知道方法,大多内容都通了,图像变换操作部分,主要理解矩阵里面每个数字代表的含义和矩阵是如何运算的,多数的问题就都能理解了,今天依旧努力学习/.