2024 neurips
1 intro
-
随着 HuggingFace、timm 和 torchvision 等开源仓库的发展,预训练与微调模型的数量激增 ,这导致模型部署的存储和成本负担加重 。
- 多任务学习(MTL)通过联合训练多数据集来部分缓解上述问题,但它存在以下缺陷:
-
(i) 计算成本高;
-
(ii) 隐私数据限制导致数据不可获取
-
- 多任务学习(MTL)通过联合训练多数据集来部分缓解上述问题,但它存在以下缺陷:
-
因此,近年来出现了**模型融合(model merging)**方法,试图通过权重合并的方式绕过训练过程,减少计算与数据开销,具备重要的实际意义。
-
一个简单的模型融合方法是对权重进行平均,但这往往会带来明显的性能下降
-
为此,已有研究提出了三类主流融合方法:
-
权重加权平均类(Weighted averaging):
-
如 Fisher-Merging、RegMean
-
使用 Fisher 信息矩阵 或内积矩阵 预计算加权系数。
-
-
任务向量合成类(Task vector-based methods):
-
如 Task Arithmetic 、Ties-Merging 、AdaMerging ;
-
将任务向量加和而非权重加和;
-
Ties-Merging 解决干扰问题,AdaMerging 自适应调整系数。
-
-
预处理技术类(Pre-processing)
-
如 DARE
-
通过稀疏和缩放任务向量来减少干扰
-
-
-
尽管已有方法取得一定进展,但仍存在两大问题:
-
(1) 合并模型与原始模型/MTL 模型之间仍存在明显性能差距
-
(2) 性能提升依赖于数据或训练进行调参
-
-
-
论文重新审视现有融合范式
-
发现,现有方法的核心目标是:构造一个能统一处理所有任务的单一模型权重,形式如下:
-
但这种策略存在问题:
-
当任务数量较多或任务难度较大时,一个统一权重难以同时逼近所有任务模型的表现;
-
单一参数空间模拟多任务权重是一种次优解。
-
-
-
------>论文提出新的融合范式:首先提取一个统一主干模型权重,然后为每个任务构造一个轻量的任务特定模块,包括掩码和缩放器。
-
基于上述范式,论文提出了 EMR-Merging(Elect, Mask & Rescale-Merging) 方法。


2 方法
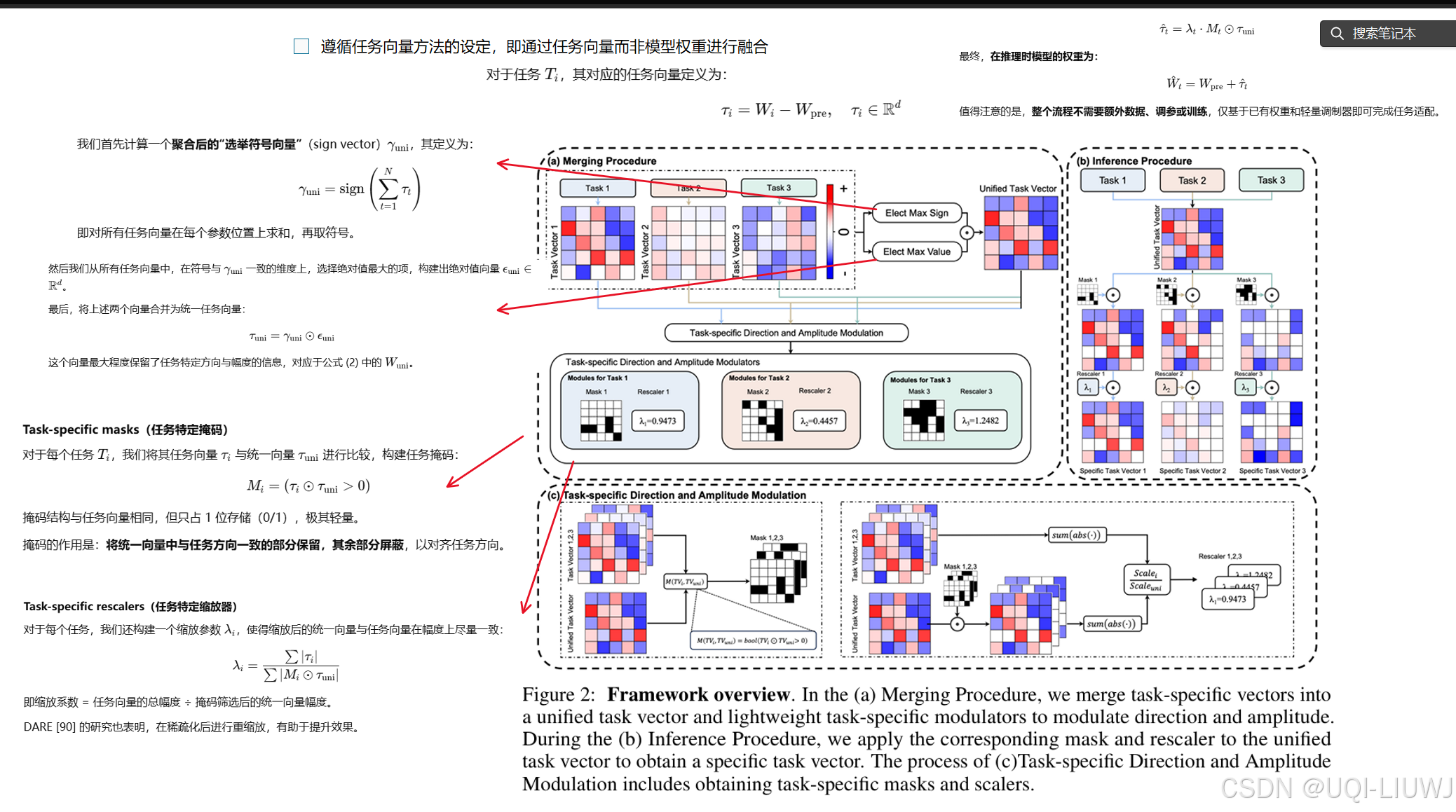
3 理论分析

