上一章中,我们探讨了大型语言模型(LLMs)的演进及其如何改变了生成式人工智能(GenAI)的格局,同时也讨论了一些其存在的缺陷。本章将介绍如何通过检索增强生成(Retrieval-Augmented Generation,简称RAG)来规避这些缺陷。我们将了解RAG的含义、架构,以及它如何融入LLM的工作流程,从而构建更优智能应用。
本章主要内容包括:
- 理解RAG的强大能力
- 分解RAG的流程
- 为RAG检索外部信息
- 构建端到端的RAG流程
技术要求
本章内容需要具备Python编程语言的基础知识(推荐使用3.6及以上版本)以及深度学习的基本概念。
我们将利用流行的AI工具包,如Hugging Face的Transformers库(huggingface.co/docs/transf...)来构建和实验RAG。虽然不是必须,但具备Git版本控制的基本知识会有帮助。Git能让你轻松克隆本章代码仓库并追踪修改。无需担心自己寻找或输入代码!我们已经在GitHub上建立了专门的公开仓库:github.com/PacktPublis... ,方便你克隆并跟随本章的实操练习。
该仓库包含实现RAG模型及集成Neo4j高级知识图谱功能所需的所有脚本、文件和配置。
请确保你的环境已安装以下Python库,以便顺利完成本章的实践:
- Transformers:用于处理模型相关功能,安装命令:
pip install transformers - PyTorch:作为计算后端,安装请参考 pytorch.org/get-started... 选择适合系统的版本
- scikit-learn:用于相似度计算,安装命令:
pip install scikit-learn - NumPy:用于数值计算,安装命令:
pip install numpy - SentencePiece:部分模型文本分词所需,安装说明见官方GitHub github.com/google/sent... ,大多数Python环境可直接执行:
pip install sentencepiece - rank_bm25:实现基于关键词检索的BM25算法,安装命令:
pip install rank_bm25 - datasets:Hugging Face提供的高效数据集加载与处理工具,支持大规模数据集,安装命令:
pip install datasets - pandas:Python数据分析库,用于表格数据操作和预处理,安装命令:
pip install pandas - faiss-cpu:用于高效相似度搜索和密集向量聚类,本例中用于构建推理时的检索器,安装命令:
pip install faiss-cpu,文档及示例见 github.com/facebookres... - Accelerate:Hugging Face的分布式训练和推理简化库,提升CPU、GPU及多节点硬件利用率,安装命令:
pip install accelerate
确保环境配置完成后,你即可无缝开展本章的实操练习。
备注
本章各节重点讲解相关代码片段,完整代码请查阅本书GitHub仓库:github.com/PacktPublis... 。
理解RAG的强大能力
RAG由Meta研究人员于2020年提出(arxiv.org/abs/2005.11...),作为一种框架,允许生成式人工智能(GenAI)模型利用训练之外的外部数据来增强生成结果。
众所周知,大型语言模型(LLMs)存在"幻觉"问题。一个典型的真实案例是纽约律师事务所Levidow, Levidow & Oberman在针对哥伦比亚航空公司Avianca的案件中,提交了包含由OpenAI的ChatGPT生成的虚假引用的法律简报,最终被罚款数千美元,并且可能遭受更大声誉损失。详情见:news.sky.com/story/lawye...。
LLM出现幻觉的原因有多种,主要包括:
- 过拟合训练数据:模型训练时可能过度拟合训练数据中的统计模式,导致优先复制这些模式,而非生成事实准确的内容。
- 缺乏因果推理:LLM擅长识别词语间的统计关系,但可能难以理解因果关系,导致生成的语句语法正确但事实不合理。
- 温度参数配置:温度(temperature)是控制文本生成随机性的参数,取值在0到1之间。温度越高,创造性越强,但幻觉的概率也越大,因为模型会偏离预期答案。
- 信息缺失:如果训练数据中没有包含生成准确回答所需的信息,模型可能产生听起来合理但错误的答案。
- 训练数据缺陷或偏见:训练数据的质量至关重要,若存在偏见或错误,模型可能延续这些问题,导致幻觉。
尽管幻觉问题严重,但有几种方法可在一定程度上缓解:
-
提示工程(Prompt Engineering) :通过精心设计和反复优化给模型的指令或查询,诱导其给出一致且准确的回答。例如,向模型询问:
列出Neo4j在知识图谱中的五个关键优势会比模糊的:
告诉我关于Neo4j的情况得到更结构化、精准的答案。提示工程帮助模型聚焦于预期信息范围,减少生成无关或虚假内容。详见:cloud.google.com/discover/wh...。
-
上下文学习(In-context learning,少样本提示) :在提示中加入示例,引导模型生成准确的特定任务答案。比如在请求产品对比时,给出几个格式良好的对比例子,帮助模型模仿并生成符合模式的回复。这利用了模型推断上下文并根据示例调整答案的能力,适合领域专用任务。
-
微调(Fine-tuning) :对预训练模型进一步训练,使用特定数据集使其适应专业领域或任务,提高相关性和准确性。一种流行方法是基于人类反馈的强化学习(RLHF),通过人工评分指导模型调整行为,使输出更符合人类预期。举例来说,对公司内部文档进行微调后,模型在被问及:
解释新员工入职流程时,会给出符合公司政策的详细说明,而通用模型则可能回答模糊或无关内容。
举个RLHF具体案例:
- 初始提问:
使用XYZ软件有哪些好处? - 初始回答:
XYZ软件提高生产力,增强协作,降低成本。 - 人工反馈:
过于笼统,缺乏XYZ软件的具体特色。 - 经过RLHF微调后,模型可能回答:
XYZ软件支持实时数据同步、可定制工作流和高级安全功能,适合企业资源计划。
- 初始提问:
RLHF特别有助于减少幻觉,因为它强调从人工精心挑选的反馈中学习。
尽管上述方法均能显著改进,但它们在一个关键方面仍有不足:无法快速利用领域特定知识构建准确、有上下文且可解释的生成式AI应用。解决方案是"落地"(grounding),即将模型生成的内容与现实事实或数据绑定。
这一理念构成了新一代文本生成范式RAG的基础。通过动态检索可靠知识库中的事实信息,RAG确保输出既准确又符合上下文。RAG旨在解决LLM幻觉问题,将模型与事实知识库中的相关信息结合起来。
"检索增强生成"(Retrieval-Augmented Generation,简称RAG)一词最早由Facebook AI Research(FAIR)团队在2020年5月提交的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》中提出(arxiv.org/abs/2005.11...)。
该论文提出了一种混合架构(见图2.1),将神经检索器与序列到序列生成器结合起来。检索器负责从外部知识库中获取相关文档,这些文档作为上下文被送入生成器,使输出基于事实数据。该方法在知识密集型自然语言处理任务(如开放领域问答和对话系统)上显著提升了性能,减少了对模型内在知识的依赖,提高了事实准确性。RAG通过引入从补充或领域特定数据源检索相关知识的能力,解决了之前LLM存在的不足。
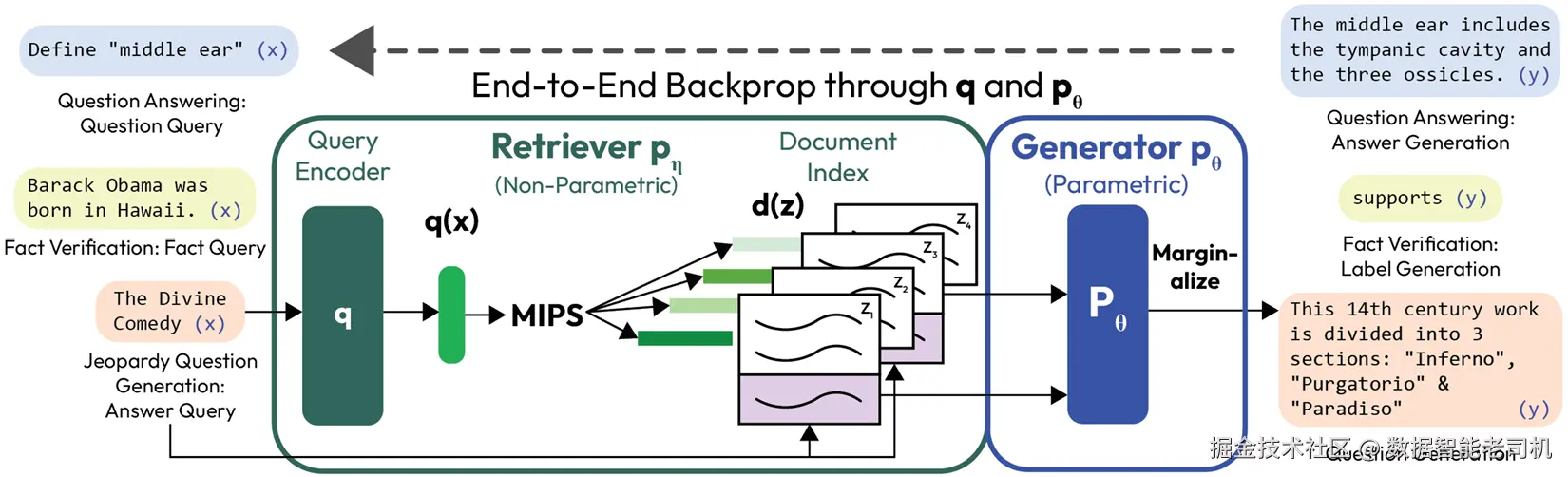
此外,RAG流水线能够在保持准确性的同时,减少模型的体积。与将所有知识都嵌入模型参数中(这通常需要大量资源)不同,RAG允许模型动态检索信息,从而保持模型轻量且易于扩展。
本章接下来的部分将深入探讨RAG的内部工作机制,解析它如何弥合纯生成与基于知识的文本产出之间的鸿沟。
拆解RAG流程
现在,让我们拆解RAG模型的构建模块,帮助你理解其工作原理。
首先,我们来看一下常规大型语言模型(LLM)的应用流程。图2.2展示了这一基础流程。
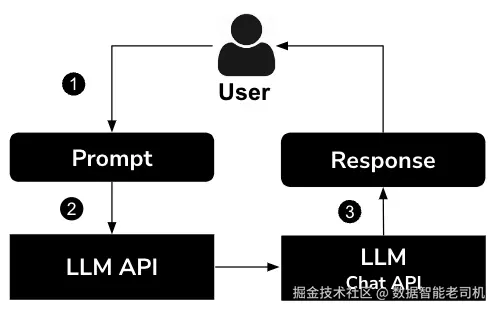
当用户向大型语言模型(LLM)发起请求时,流程如下:
- 用户发送提示语:流程始于用户向LLM聊天接口发送提示语。这个提示语可以是一个问题、一条指令,或任何其他信息或内容生成的请求。
- LLM接口处理提示语:LLM聊天接口接收到用户的提示语后,将其传递给LLM。LLM是经过大量文本数据训练的人工智能模型,能够根据各种提示和问题生成类人文本并进行交流。
- LLM生成响应:LLM处理提示语并生成响应,该响应被发送回LLM聊天接口,再由接口传回给用户。
从这个流程中可以看出,LLM负责直接给出答案,中间没有其他环节。这是最常见的、未使用RAG的请求-响应流程。
现在,让我们来看看RAG在这一工作流程中的位置。
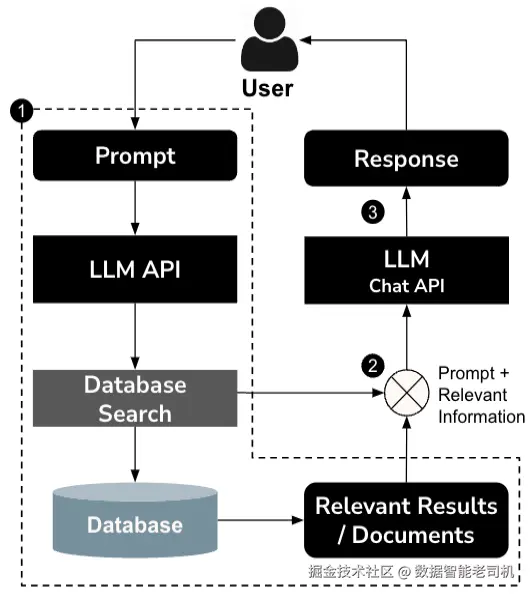
从图2.3中可以看出,在实际调用大型语言模型(LLM)服务之前,有一个中间的数据源,为LLM请求提供上下文:
- 用户发送提示语:用户通过聊天界面发送一个提示语或问题,这个提示可以是任何他们想了解的信息或需要帮助的内容。
- RAG模型处理提示语:聊天API接收提示后,将其传递给RAG模型。RAG模型由两个主要组件协同工作组成:检索器(后续第3步讨论)和编码器-解码器(后续第4步讨论)。
- 检索器:该组件会在知识库中搜索相关信息,知识库可能包括非结构化文档、段落,或结构化数据如表格和知识图谱。它的任务是定位解决用户提示所需的最相关信息。
我们将通过一个简单示例来介绍检索器组件。完整代码可参考:github.com/PacktPublis...
下面代码片段演示了如何从Hugging Face Transformers库初始化一个上下文编码模型和分词器:
ini
# 定义一组文档,准备存入文档库。这里用几个预定义句子示范:
documents = [
"The IPL 2024 was a thrilling season with unexpected results.",
...
"Dense Passage Retrieval (DPR) is a state-of-the-art technique for information retrieval."
]
# 将上述内容存入内容库,并为每个文档生成embedding存储:
def encode_documents(documents):
inputs = tokenizer(
documents, return_tensors='pt',
padding=True, truncation=True)
with torch.no_grad():
outputs = model(**inputs)
return outputs.pooler_output.numpy()
document_embeddings = encode_documents(documents)接下来定义一个基于查询输入从文档库检索内容的方法。通过生成查询的embedding,利用向量搜索获得相关结果:
ini
def retrieve_documents(query, num_results=3):
inputs = tokenizer(query, return_tensors='pt',
padding=True, truncation=True)
with torch.no_grad():
query_embedding = model(**inputs).pooler_output.numpy()
similarity_scores = cosine_similarity(
query_embedding, document_embeddings).flatten()
top_indices = similarity_scores.argsort()[-num_results:][::-1]
top_docs = [(documents[i], similarity_scores[i]) for i in top_indices]
return top_docs例如,查询"什么是Dense Passage Retrieval?"时,返回的示例结果可能是:
vbnet
Top Results:
Score: 0.7777, Document: Dense Passage Retrieval (') is a state-of-the-art technique for information retrieval.
...备注
检索器实现可能较复杂,常用方法包括高效的搜索算法如BM25、TF-IDF,或者神经网络检索器如Dense Passage Retrieval,详情见:github.com/facebookres...。
- 编码器-解码器/增强生成:编码器处理提示语和检索到的结构化或非结构化信息,生成综合表示;解码器利用该表示生成准确、上下文丰富且针对用户提示定制的回复。这一步调用LLM API,输入包括查询和上下文信息。
以下示例展示了如何利用T5Tokenizer模型调用带上下文信息的查询:
ini
# 定义LLM,使用Hugging Face的T5模型:
tokenizer = T5Tokenizer.from_pretrained('t5-small', legacy=False)
model = T5ForConditionalGeneration.from_pretrained('t5-small')
# 定义RAG流程中的查询和文档(此处用硬编码示例):
query = "What are the benefits of solar energy?"
retrieved_passages = """
Solar energy is a renewable resource and reduces electricity bills.
......
"""
# 定义方法,将输入查询和检索段落用于调用LLM API,展示RAG方法:
def generate_response(query, retrieved_passages):
input_text = f"Answer this question based on the provided context: {query} Context: {retrieved_passages}"
inputs = tokenizer(input_text, return_tensors='pt', padding=True, truncation=True, max_length=512).to(device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_length=300, # 允许较长回答
num_beams=3, # 使用beam search获得更优结果
early_stopping=True
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)备注 这里采用了T5模型的beam search解码,以生成准确且上下文相关的回答。Beam search是一种搜索算法,用于在文本生成时寻找最可能的词序列。与贪心解码只选最可能的单词不同,beam search维护多个可能序列(beam),同时探索,提高找到高质量结果的概率,避免过早选定次优路径。详见:huggingface.co/blog/constr...。
现在,我们调用该方法并查看响应:
scss
response = generate_response(query, retrieved_passages)
print("Query:", query)
print("Retrieved Passages:", retrieved_passages)
print("Generated Response:", response)示例输入:
makefile
Query: What are the benefits of solar energy?检索到的段落:
csharp
Solar energy is a renewable resource and reduces electricity bills.
......示例输出:
vbscript
Generated Response: it is environmentally friendly and helps combat climate change完整代码见:github.com/PacktPublis...。
集成与微调:下面代码片段展示了结合检索器和LLM调用的完整RAG流程示例:
ini
def rag_pipeline(query):
retrieved_docs = retrieve_documents(query)
response = generate_response(query, retrieved_docs)
return response
query = "How does climate change affect biodiversity?"
generated_text = rag_pipeline(query)
print("Final Generated Text:", generated_text)从代码中可见,流程简单明了。先用检索器获得相关文档,再将查询和检索结果传给LLM API调用。
通过这次对RAG架构的深入剖析,我们重点介绍了其工作机制并演示了核心组件的功能。RAG结合高效的信息检索和先进的语言生成模型,产出既符合上下文又富含知识的回答。接下来,我们将讨论检索过程。
为你的RAG检索外部信息
理解RAG如何利用外部知识,对于理解其生成事实准确且信息丰富的回答能力至关重要。本节将讨论各种检索技术、整合检索信息的策略,以及实际示例来阐释这些概念。
理解检索技术和策略
RAG模型的成功依赖于其能从庞大的外部知识库中检索相关信息的能力,这通常借助常用的检索技术实现。这些检索方法对于从大规模数据集中获取相关信息至关重要。常见技术包括传统方法如BM25,以及现代神经网络方法如DPR(Dense Passage Retrieval)。大体上,这些技术可以分为三类:向量相似度搜索、关键词匹配和段落检索。以下子节将逐一介绍。
向量相似度搜索
传入LLM的文本或查询会被转换成一种称为"嵌入向量"的向量表示。向量相似度搜索通过比较这些向量嵌入来检索最相近的匹配。其核心理念是相关或相似的文本具有相似的向量表示。该技术的工作流程如下:
- 构建输入查询的嵌入向量。先对查询进行分词,再生成对应的向量表示:
ini
query_inputs = question_tokenizer(query, return_tensors="pt")
with torch.no_grad():
query_embeddings = question_encoder(**query_inputs).pooler_output- 构建文档的嵌入向量。为每个文档生成向量表示并与文档对应:
css
doc_embeddings = []
for doc in documents:
doc_inputs = context_tokenizer(doc, return_tensors="pt")
with torch.no_grad():
doc_embeddings.append(context_encoder(**doc_inputs).pooler_output)
doc_embeddings = torch.cat(doc_embeddings)- 通过点积计算查找相似文档。使用查询的嵌入向量与所有文档嵌入向量计算相似度分数:
ini
scores = torch.matmul(query_embeddings, doc_embeddings.T).squeeze()- 根据相关性分数排序并返回结果。结果包含匹配的文档及其与查询的相似度分数,按相似度从高到低排序:
python
ranked_docs = sorted(zip(documents, scores), key=lambda x: x[1], reverse=True)让我们运行该示例,看看结果是什么样的。
示例输入查询:
What are the benefits of solar energy?
示例输出(排序文档):
vbnet
Document: Solar energy is a renewable source of power., Score: 80.8264
....
Document: Graph databases like Neo4j are used to model complex relationships., Score: 52.8945上述代码展示了如何使用DPR将查询和文档集编码为高维向量,通过计算查询向量和文档向量之间的相似度分数(如点积)来评估文档与查询的相关性。然后根据相似度得分对文档排序,最相关的排在前面。这个过程彰显了基于向量的检索在从包含相关与不相关内容的多样文档集中有效识别上下文相关信息的强大能力。
该示例完整代码可见GitHub仓库:github.com/PacktPublis... 。
关键词匹配
关键词匹配是一种更简单的检索方法,通过识别包含用户提示中关键词的文档来进行筛选。虽然这种方法效率较高,但容易受到噪声影响,并且会遗漏包含相关同义词的文档。BM25是一种基于关键词的概率检索函数,它根据查询词在文档中出现的频率及文档长度对文档进行评分。该方法的流程如下:
- 使用文档构建BM25语料库。首先对文档进行分词,生成语料库:
ini
tokenized_corpus = [doc.split() for doc in corpus]
# 使用分词后的语料库初始化BM25
bm25 = BM25Okapi(tokenized_corpus, k1=1.5, b=0.75)- 对查询进行分词:
ini
tokenized_query = query.split()- 使用分词后的查询对BM25语料库进行检索,获得匹配文档的评分:
ini
scores = bm25.get_scores(tokenized_query)- 根据评分排序文档并返回结果:
python
ranked_docs = sorted(zip(corpus, scores), key=lambda x: x[1], reverse=True)运行该示例后,针对输入查询,结果可能如下所示。
示例输入查询:
quick fox
示例输出:
yaml
Ranked Documents:
Document: The quick brown fox jumps over the lazy dog., Score: 0.6049
.....
Document: Artificial intelligence is transforming the world., Score: 0.00000 BM25算法根据文档与查询的相关性对文档进行排序。它依赖关键词在文档中的出现频率(词频)和文档长度,通过概率评分函数评估相关性。与向量相似度搜索不同,后者将查询和文档都表示为高维空间中的稠密数值向量,并使用数学函数(如点积)来衡量相似度,BM25直接基于离散词的匹配来工作。这使得BM25效率高且结果易于解释,但在处理语义关系方面存在不足,因为它无法识别同义词或上下文含义。相比之下,向量相似度搜索(如DPR)在识别概念相似性方面表现优异,即使关键词不同,也能捕捉语义相关,因而更适合需要深层语义理解的任务。
该代码片段展示了BM25在对效率和可解释性有较高要求的简单关键词匹配任务中的实用价值。
完整示例代码见GitHub仓库:github.com/PacktPublis... 。
段落检索
RAG不仅可以检索整个文档,还可以聚焦于文档中直接回答用户查询的特定段落,从而实现更精准的信息提取。该方法的初始流程与向量搜索类似。我们先使用向量搜索方法得到排序后的文档,然后从中提取相关段落,代码示例如下:
ini
# 提取给阅读器的段落
passages = [doc for doc, score in ranked_docs]
# 准备阅读器输入
inputs = reader_tokenizer(
questions=query,
titles=["Passage"] * len(passages),
texts=passages,
return_tensors="pt",
padding=True,
truncation=True
)
# 使用阅读器提取最相关段落
with torch.no_grad():
outputs = reader(**inputs)
# 找出得分最高的段落
max_score_index = torch.argmax(outputs.relevance_logits)
most_relevant_passage = passages[max_score_index]当我们对以下输入查询运行此示例时,结果如下:
示例输入查询:
What are the benefits of solar energy?
示例输出:
yaml
Ranked Documents:
Document: Solar energy is a renewable source of power., Score: 80.8264
.....
Document: It has low maintenance costs., Score: 57.9905
Most Relevant Passage: Solar panels help combat climate change and reduce carbon footprint.上述示例展示了段落检索方法,该方法相比文档级检索更细粒度,专注于提取能够直接回答用户查询的具体段落。通过结合阅读器模型与检索器,这种方法不仅能定位最相关的文档,还能准确识别文档中最佳回答查询的段落,从而提升相关性和准确度。
即使某个段落的检索得分略低,阅读器也可能优先考虑它,因为阅读器在词语和文本跨度层面对相关性进行更精细的评估,考虑上下文细微差别。通常,检索器通过计算查询与段落嵌入向量的点积来得到相似度得分。
Score(q,pi)=q⋅pi=j=1∑dqjpij
这里, q 是查询的向量嵌入, pi 是第 i 个段落的向量嵌入, d 是嵌入向量的维度。
然而,阅读器会进一步细化这一过程,通过分析每个段落的文本内容,根据该段落包含答案的可能性分配一个相关性分数或对数几率(也称为置信度分数)。这个相关性分数是基于阅读器模型的原始输出(logits)计算得出的,模型会考虑查询和段落之间在词级和文本跨度级的交互。
相关性分数的公式可表示为:
Relevance Score(pi)=softmax(logits(pi))
这里说明如下:
- logits() 表示阅读器对段落 pi 赋予的原始分数;
- softmax函数将这些原始分数转换为概率,突出最可能相关的段落(详细说明见:pytorch.org/docs/stable...)。
通过结合这两个阶段,系统不仅能识别语义上相似的段落(检索阶段),还能判断与查询意图上下文紧密契合的内容(阅读阶段)。
这一双阶段流程凸显了段落检索在信息检索流程中生成高度针对性回答的优势。
完整示例代码可在GitHub仓库查看:github.com/PacktPublis...。
整合检索到的信息
在RAG流程的最后一步,我们来看如何将检索到的信息与生成模型结合,以合成上下文相关且连贯的回答。与之前的示例不同,这种方法明确地将多个检索到的段落与查询整合,形成生成模型的单一输入。这样,模型能够综合生成统一且丰富的回答,而不仅仅是选择或排序段落:
ini
def integrate_and_generate(query, retrieved_docs):
# 将查询和检索文档合并成一个输入
input_text = f"Answer this question based on the following context: {query} Context: {' '.join(retrieved_docs)}"
# 对输入进行T5分词
inputs = t5_tokenizer(input_text, return_tensors="pt",
padding=True, truncation=True, max_length=512)
# 生成回答
with torch.no_grad():
outputs = t5_model.generate(**inputs, max_length=100)
# 解码并返回生成结果
return t5_tokenizer.decode(outputs[0], skip_special_tokens=True)示例输入查询:
What are the benefits of solar energy?
示例输出:
yaml
Ranked Documents:
Document: Solar energy is a renewable source of power., Score: 80.8264
....
Document: It has low maintenance costs., Score: 57.9905
Most Relevant Passage: Solar panels help combat climate change and reduce carbon footprint.上述代码片段演示了如何将检索到的文档与T5模型结合,生成综合的回答。generate()函数通过编码器处理合并输入(查询和段落),生成上下文嵌入向量 hhh。随后,解码器基于概率依次生成每个词元:
P(wt∣w<t,h)=Softmax(W⋅ht)
这里, wt 是位置 t 处的词元(token), ht 是隐藏状态, W 是模型的权重矩阵。束搜索(Beam Search)通过最大化整条序列的整体概率,确保选择最可能的词序列。
与之前单独选择或排序段落的示例不同,这段代码明确地将多个检索到的文档与查询合并为单一输入。这样,T5模型能够整体处理合并后的上下文,生成包含多个信息源的连贯回答,特别适合需要对多个段落进行综合或总结的查询。
完整代码请参见:github.com/PacktPublis...
通过探索多种检索技术及其与生成模型的结合方式,我们看到RAG架构如何利用外部知识生成准确且信息丰富的回答。
下一节,我们将看看从读取源文档并利用这些文档进行检索器流程的整体流程,而非本节示例中使用的简单硬编码句子。
构建端到端的RAG流程
在前面的章节中,我们分别用简单数据深入探讨了RAG流程的各个步骤。现在不妨退一步,使用一个真实世界的数据集(虽然简单)来完成整个流程。这里我们使用GitHub issues数据集(huggingface.co/datasets/le...),看看如何读取该数据并应用于RAG流程。这将为后续章节中完整的端到端RAG实现打下基础。
本示例中,我们将加载GitHub评论数据,以便回答诸如"如何离线加载数据集"等问题。主要步骤如下:
准备数据
首先准备数据集,使用Hugging Face datasets库:
ini
# 加载GitHub issues数据集
issues_dataset = load_dataset("lewtun/github-issues", split="train")
# 过滤掉pull requests,只保留含有评论的issues
issues_dataset = issues_dataset.filter(
lambda x: not x["is_pull_request"] and len(x["comments"]) > 0)选择相关列
只保留分析所需的列:
ini
columns_to_keep = ["title", "body", "html_url", "comments"]
columns_to_remove = set(issues_dataset.column_names) - set(columns_to_keep)
issues_dataset = issues_dataset.remove_columns(columns_to_remove)转换为pandas DataFrame
方便操作,转换成DataFrame格式:
bash
issues_dataset.set_format("pandas")
df = issues_dataset[:]拆分评论并处理
将评论拆分成独立行,再转换回dataset,并计算每条评论长度,方便检索器流程使用:
ini
# 拆分评论为单独行
comments_df = df.explode("comments", ignore_index=True)
# 转换回Dataset
comments_dataset = Dataset.from_pandas(comments_df)
# 计算每条评论长度(词数)
comments_dataset = comments_dataset.map(
lambda x: {"comment_length": len(x["comments"].split())},
num_proc=1)
# 过滤掉过短的评论
comments_dataset = comments_dataset.filter(
lambda x: x["comment_length"] > 15)拼接文本生成嵌入文本
将相关文本字段拼接,生成代表每条文档的文本,用于后续嵌入存储:
python
def concatenate_text(examples):
return {
"text": examples["title"] + " \n " +
examples["body"] + " \n " +
examples["comments"]
}
comments_dataset = comments_dataset.map(concatenate_text, num_proc=1)加载模型和分词器
加载用于将文档转换为嵌入的预训练模型和分词器:
ini
model_ckpt = "sentence-transformers/all-MiniLM-L6-v2"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = AutoModel.from_pretrained(model_ckpt).to("cpu")定义生成嵌入函数
定义函数,使用上述模型批量生成文本的嵌入向量:
ini
def get_embeddings(text_list):
encoded_input = tokenizer(text_list, padding=True,
truncation=True, return_tensors="pt").to("cpu")
with torch.no_grad():
model_output = model(**encoded_input)
return cls_pooling(model_output).numpy()计算数据集嵌入
对所有文档计算嵌入,并将嵌入存入新列"embeddings":
ini
comments_dataset = comments_dataset.map(
lambda batch: {"embeddings": [get_embeddings([text])[0] for text in batch["text"]]},
batched=True,
batch_size=100,
num_proc=1
)执行语义搜索
针对用户查询执行检索流程,找到最相关的问题及评论,可用于生成答案时丰富上下文:
scss
question = "How can I load a dataset offline?"
query_embedding = get_embeddings([question]).reshape(1, -1)
embeddings = np.vstack(comments_dataset["embeddings"])
similarities = cosine_similarity(query_embedding, embeddings).flatten()
top_indices = np.argsort(similarities)[::-1][:5]
for idx in top_indices:
result = comments_dataset[int(idx)]
print(f"COMMENT: {result['comments']}")
print(f"SCORE: {similarities[idx]}")
print(f"TITLE: {result['title']}")
print(f"URL: {result['html_url']}")
print("=" * 50)以上代码完整展示了从加载数据到构建数据存储(作为检索器基础),再到检索相关文档的全过程。这些检索结果可作为生成模型的上下文,辅助回答生成,实现完整的RAG流程。
现在让我们看看运行该应用时的输出效果。示例代码中硬编码的问题是:
"How can I load a dataset offline?."
示例输出如下:
vbnet
COMMENT: Yes currently you need an internet connection because the lib tries to check for the etag of the dataset script ...
SCORE: 0.9054292969045314
TITLE: Downloaded datasets are not usable offline
URL: https://github.com/huggingface/datasets/issues/761
==================================================
COMMENT: Requiring online connection is a deal breaker in some cases ...
SCORE: 0.9052456782359709
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================这个实操示例展示了端到端RAG架构的实际应用,利用强大的检索技术增强语言生成。上述代码改编自Hugging Face NLP课程,详情见:huggingface.co/learn/nlp-c...。
完整的Python文件及详细运行说明,请访问:,github.com/PacktPublis...。
总结
本章我们深入探讨了RAG模型的世界。首先理解了RAG的核心原理及其与传统生成式人工智能模型的不同,这些基础知识为理解RAG带来的增强能力奠定了基础。
接着,我们细致剖析了RAG模型的架构,通过详细的代码示例分解了编码器、检索器和解码器的组成部分,帮助你深入了解模型的内部工作原理,以及如何整合检索到的信息以生成更具上下文相关性和连贯性的输出。
随后,我们探讨了RAG如何利用信息检索技术。这些技术帮助RAG有效利用外部知识源,提高生成文本的质量,尤其适用于需要高准确度和上下文感知的应用场景。你还学习了如何使用流行库如Transformers和Hugging Face构建简单的RAG模型。
在接下来的第3章,我们将在此基础上继续展开,介绍图数据建模以及如何使用Neo4j创建知识图谱。