目录
[自助法(Bootstrap)+ 指标分布估计](#自助法(Bootstrap)+ 指标分布估计)
数据量与模型性能的一般关系
- 小数据量:模型容易过拟合,评价指标方差大
- 中等数据量:模型性能逐步提升,评价指标趋于稳定
- 大数据量:模型性能接近上限,评价指标变化平缓
常见评价指标
- **分类问题:**准确率、精确率、召回率、F1分数、AUC-ROC
- **回归问题:**MSE、RMSE、MAE、R²
- **其他:**对数损失、交叉验证分数
分析方法
学习曲线
通过逐步增加训练数据量,观察模型在训练集和验证集上的指标变化趋势,判断模型是否欠拟合、过拟合或趋于稳定
python
## 分析方法
# 1. 学习曲线分析
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import learning_curve
from sklearn.ensemble import RandomForestClassifier
X, y = load_breast_cancer(return_X_y=True)
train_sizes, train_scores, val_scores = learning_curve(
RandomForestClassifier(n_estimators=100, random_state=42),
X, y, cv=5, scoring='accuracy', train_sizes=np.linspace(0.1, 1.0, 10)
)
plt.plot(train_sizes, np.mean(train_scores, axis=1), label='Train Accuracy')
plt.plot(train_sizes, np.mean(val_scores, axis=1), label='Validation Accuracy')
plt.xlabel('Training Set Size')
plt.ylabel('Accuracy')
plt.title('Learning Curve')
plt.legend()
plt.grid(True)
plt.show()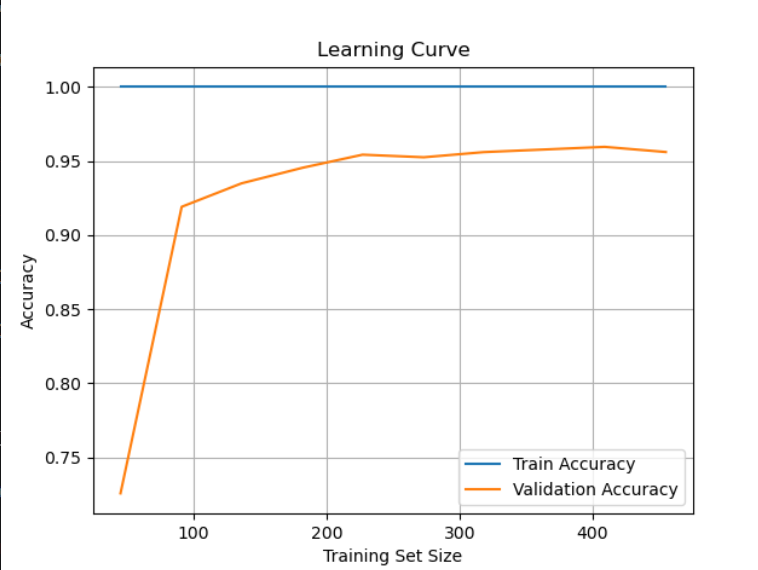
样本量-性能曲线
直接分析评价指标随样本量增加的变化趋势
python
# 2. 样本量-性能曲线
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
X, y = make_classification(n_samples=1000, n_features=20, n_informative=2, n_redundant=10, random_state=42)
# 准备数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
sample_sizes = [50, 100, 200, 300, 400, 500, 600, 700, 800]
train_acc = []
test_acc = []
for size in sample_sizes:
# 使用部分数据训练
model = LogisticRegression(max_iter=1000)
model.fit(X_train[:size], y_train[:size])
# 计算训练集和测试集准确率
train_pred = model.predict(X_train[:size])
test_pred = model.predict(X_test)
train_acc.append(accuracy_score(y_train[:size], train_pred))
test_acc.append(accuracy_score(y_test, test_pred))
# 绘制曲线
plt.figure(figsize=(10, 6))
plt.plot(sample_sizes, train_acc, label='Training Accuracy')
plt.plot(sample_sizes, test_acc, label='Test Accuracy')
plt.xlabel('Number of Training Samples')
plt.ylabel('Accuracy')
plt.title('Model Performance vs Training Sample Size')
plt.legend()
plt.grid()
plt.show()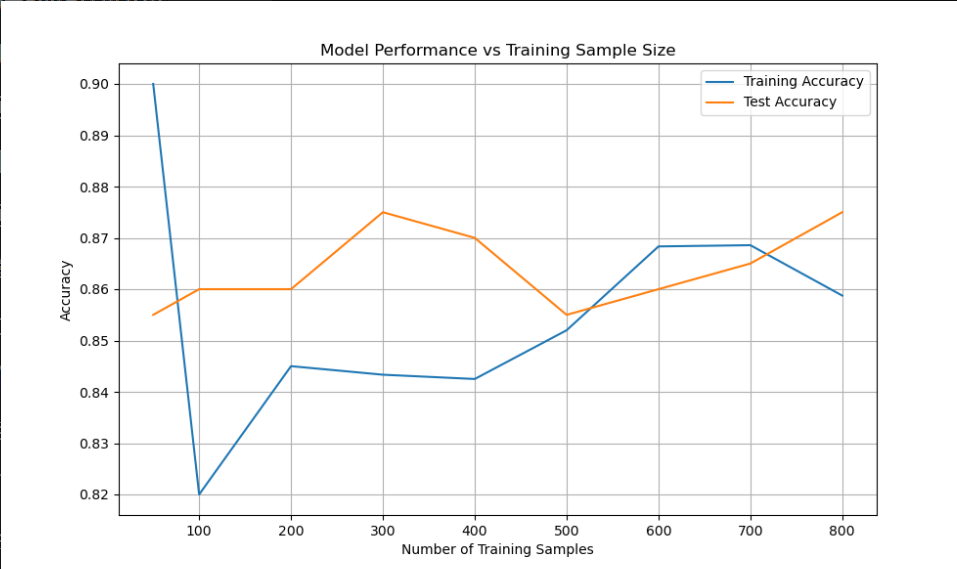
交叉验证分析
使用不同数据量进行交叉验证,评估模型稳定性
python
# 3. 交叉验证分析
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
import pandas as pd
from sklearn.model_selection import cross_val_score
import pandas as pd
X, y = make_classification(n_samples=1000, n_features=20, n_informative=2, n_redundant=10, random_state=42)
sample_sizes = [100, 200, 300, 400, 500, 600, 700, 800, 900]
cv_scores = []
for size in sample_sizes:
scores = cross_val_score(LogisticRegression(max_iter=1000),
X[:size], y[:size],
cv=5, scoring='accuracy')
cv_scores.append({'Size': size, 'RMSE': -np.mean(scores)})
pd.DataFrame(cv_scores).plot(x='Size', y='RMSE', marker='o')
plt.xlabel('Training Set Size')
plt.ylabel('RMSE')
plt.title('RMSE vs Data Size')
plt.grid(True)
plt.show()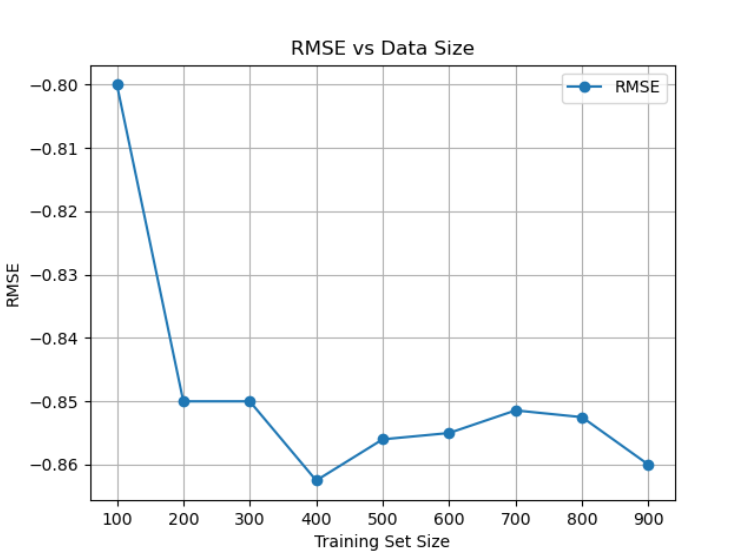
模型复杂度与数据量的关系
分析不同复杂度模型在不同数据量下的表现
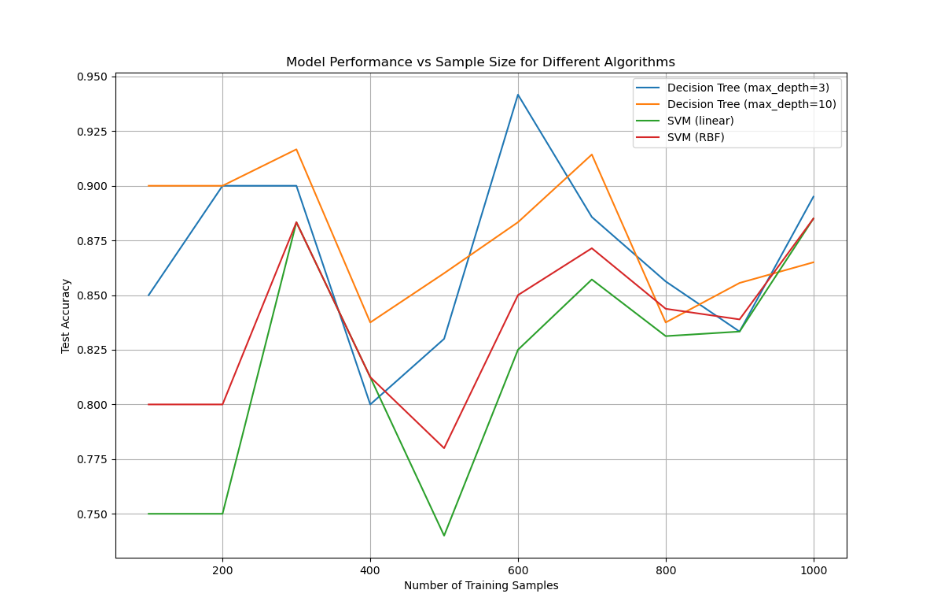
统计功效分析
评估检测真实效果所需的样本量
python
# 5. 统计功效分析
from statsmodels.stats.power import TTestIndPower
# 参数设置
effect_size = 0.5 # 中等效应量
alpha = 0.05 # 显著性水平
power = 0.8 # 期望的统计功效
# 计算所需样本量
analysis = TTestIndPower()
sample_size = analysis.solve_power(effect_size=effect_size,
power=power,
alpha=alpha,
ratio=1.0)
print(f"Required sample size per group: {sample_size:.2f}") # 63.77自助法(Bootstrap)+ 指标分布估计
使用Bootstrap重采样模拟小样本下的指标分布,估计其偏差和置信区间
python
# 6. 自助法(Bootstrap) + 指标分布估计
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.utils import resample
from sklearn.datasets import load_breast_cancer
import matplotlib.pyplot as plt
X, y = load_breast_cancer(return_X_y=True)
model = LogisticRegression(max_iter=200)
bootstrap_scores = []
for i in range(100):
X_bs, y_bs = resample(X, y, n_samples=200, random_state=i)
model.fit(X_bs, y_bs)
y_pred = model.predict(X_bs)
bootstrap_scores.append(accuracy_score(y_bs, y_pred))
plt.hist(bootstrap_scores, bins=20, edgecolor='black')
plt.title('Bootstrap Accuracy Distribution (n=200)')
plt.xlabel('Accuracy')
plt.ylabel('Frequency')
plt.show()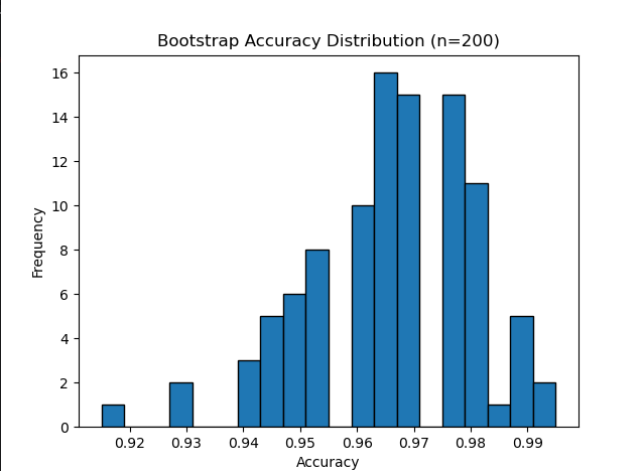
增量学习分析
评估模型在逐步增加数据时的性能变化
python
# 7. 增量学习分析
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import log_loss
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=20, n_informative=2, n_redundant=10, random_state=42)
# 准备增量学习
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
batch_size = 50
n_batches = len(X_train) // batch_size
model = SGDClassifier(loss='log_loss', learning_rate='constant', eta0=0.01, random_state=42)
train_loss = []
test_loss = []
for i in range(1, n_batches + 1):
# 获取当前批次数据
batch_end = i * batch_size
X_batch = X_train[:batch_end]
y_batch = y_train[:batch_end]
# 部分拟合模型
model.partial_fit(X_batch, y_batch, classes=np.unique(y))
# 计算损失
train_pred = model.predict_proba(X_batch)
test_pred = model.predict_proba(X_test)
train_loss.append(log_loss(y_batch, train_pred))
test_loss.append(log_loss(y_test, test_pred))
# 绘制损失曲线
plt.figure(figsize=(10, 6))
plt.plot(np.arange(1, n_batches + 1) * batch_size, train_loss, label='Training Loss')
plt.plot(np.arange(1, n_batches + 1) * batch_size, test_loss, label='Test Loss')
plt.xlabel('Number of Training Samples')
plt.ylabel('Log Loss')
plt.title('Incremental Learning Performance')
plt.legend()
plt.grid()
plt.show()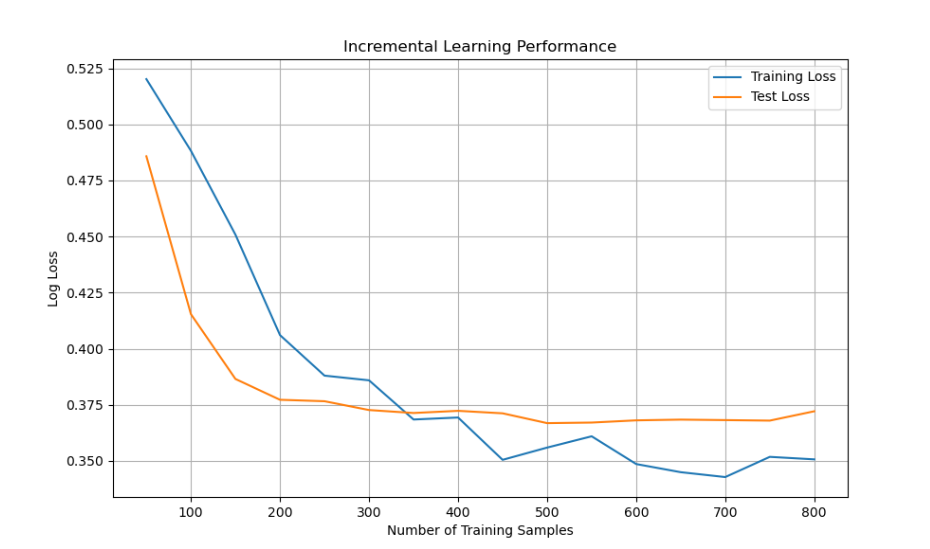
数据效率曲线
评估不同算法达到特定性能所需的数据量
python
# 8. 数据效率曲线
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(n_samples=1000, n_features=20, n_informative=2, n_redundant=10, random_state=42)
target_accuracy = 0.85
algorithms = {
'Logistic Regression': LogisticRegression(max_iter=1000),
'Random Forest': RandomForestClassifier(n_estimators=100, random_state=42),
'SVM': SVC(kernel='linear', probability=True, random_state=42)
}
results = {}
for name, model in algorithms.items():
sample_sizes = []
accuracies = []
for size in range(100, 1001, 100):
X_train, X_test, y_train, y_test = train_test_split(
X[:size], y[:size], test_size=0.2, random_state=42)
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
sample_sizes.append(size)
accuracies.append(accuracy)
# 找到达到目标准确率的最小样本量
target_size = None
for size, acc in zip(sample_sizes, accuracies):
if acc >= target_accuracy:
target_size = size
break
results[name] = {
'sample_sizes': sample_sizes,
'accuracies': accuracies,
'target_size': target_size
}
# 打印结果
for name, data in results.items():
print(f"{name}:")
print(f" Reached {target_accuracy} accuracy at sample size: {data['target_size']}")
print(" Sample sizes and accuracies:")
for size, acc in zip(data['sample_sizes'], data['accuracies']):
print(f" {size}: {acc:.3f}")
print()
# Logistic Regression:
# Reached 0.85 accuracy at sample size: 300
# Sample sizes and accuracies:
# 100: 0.750
# 200: 0.775
# 300: 0.900
# 400: 0.812
# 500: 0.770
# 600: 0.825
# 700: 0.850
# 800: 0.819
# 900: 0.833
# 1000: 0.875
#
# Random Forest:
# Reached 0.85 accuracy at sample size: 200
# Sample sizes and accuracies:
# 100: 0.800
# 200: 0.900
# 300: 0.933
# 400: 0.875
# 500: 0.910
# 600: 0.917
# 700: 0.936
# 800: 0.912
# 900: 0.900
# 1000: 0.920
#
# SVM:
# Reached 0.85 accuracy at sample size: 300
# Sample sizes and accuracies:
# 100: 0.750
# 200: 0.750
# 300: 0.883
# 400: 0.812
# 500: 0.740
# 600: 0.825
# 700: 0.857
# 800: 0.831
# 900: 0.833
# 1000: 0.885合成数据实验
通过生成不同规模的数据集,控制特征、噪声、类别分布等变量,观察指标如何随数据量变化
python
# 9. 合成数据实验
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
sizes = [100, 300, 1000, 3000, 10000]
sil_scores = []
for n in sizes:
X, _ = make_blobs(n_samples=n, centers=3, random_state=42)
labels = KMeans(n_clusters=3, random_state=42).fit_predict(X)
score = silhouette_score(X, labels)
sil_scores.append(score)
plt.plot(sizes, sil_scores, marker='o')
plt.xlabel('Sample Size')
plt.ylabel('Silhouette Score')
plt.title('聚类性能随数据量变化')
plt.grid(True)
plt.show()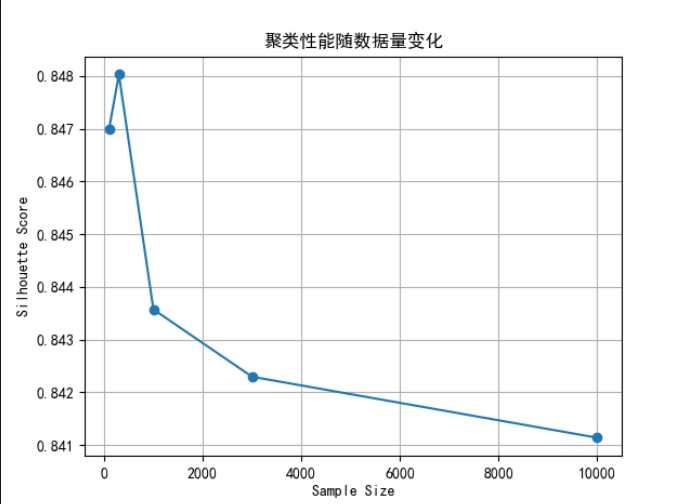
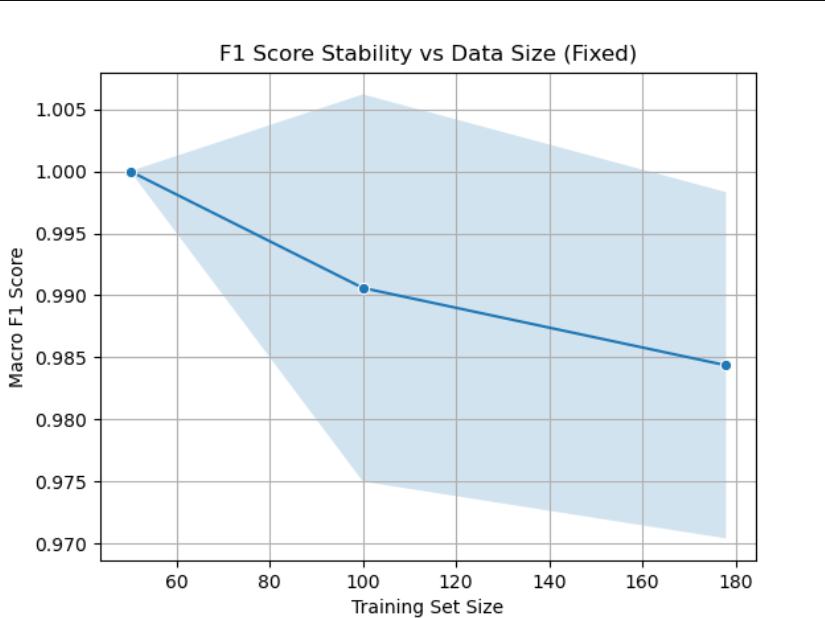
指标稳定性分析
重复采样不同大小的训练集,计算指标的标准差,评估其稳定性
python
# 10. 指标稳定性分析
from sklearn.datasets import load_wine
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
import numpy as np, pandas as pd, matplotlib.pyplot as plt, seaborn as sns
X, y = load_wine(return_X_y=True)
sizes = [50, 100, 200, 400]
sizes = [min(s, len(X)) for s in sizes]
f1_stability = []
for size in sizes:
f1s = []
for seed in range(30):
# 先抽样到目标 size
X_sample, y_sample = X[:size], y[:size] # 因为数据已经 shuffle 过,直接切片即可
X_train, X_test, y_train, y_test = train_test_split(
X_sample, y_sample,
test_size=0.3,
stratify=y_sample,
random_state=seed
)
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
f1s.append(f1_score(y_test, model.predict(X_test), average='macro'))
f1_stability.append({'Size': size, 'Mean F1': np.mean(f1s), 'Std F1': np.std(f1s)})
df = pd.DataFrame(f1_stability)
sns.lineplot(data=df, x='Size', y='Mean F1', marker='o')
plt.fill_between(df['Size'],
df['Mean F1'] - df['Std F1'],
df['Mean F1'] + df['Std F1'],
alpha=0.2)
plt.xlabel('Training Set Size')
plt.ylabel('Macro F1 Score')
plt.title('F1 Score Stability vs Data Size (Fixed)')
plt.grid(True)
plt.show()