一、前言
在复杂关键的模型部署 Pipeline 中,浮点模型量化后生成用于板端部署的 hbm 模型,这是部署重要节点,承载适合板端运行的参数与结构信息。
部署 hbm 模型到板端前,需进行一致性验证和检查,以确保其准确稳定运行,避免预测不准、系统崩溃等问题。
为完成验证和检查,会借助专门工具与 API。
本帖将详细介绍和整理用于 hbm 模型验证和检查的 API,助大家理解使用,保障模型部署顺利。
二、API 介绍
2.1 hbm 属性总体介绍
编译器的 Hbm 接口中封装了 hbm 模型的相关属性,我们可以使用以下代码查看:
Plain
from hbdk4.compiler import Hbm
hbm_file = "model.hbm"
module = Hbm(hbm_file)
func=module[0]
print(dir(module))
print(dir(func))
print("--"*20)此时输出 module 的属性如下:
Plain
#module的属性
['_Hbm__handle', '_Hbm__hbrt4_disas', '_Hbm__object_to_staged_desc', '_Hbm__object_to_staged_name', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_get_staged_desc_by_bind_obj', '_get_staged_name_by_bind_obj', '_set_staged_desc_by_bind_obj', '_set_staged_name_by_bind_obj', 'desc', 'file_name', 'functions', 'graph_groups', 'graphs', 'march', 'march_name', 'save_by_staged_info', 'staged_desc', 'toolkit_version', 'visualize']这里重点介绍常用到的属性:
desc:模型的描述信息,可以存放在部署端需要用到的模型版本、name、任务等属性信息,部署时需要结合 UCP 的hbDNNGetModelDesc进行使用;
march:模型的架构信息,即 nash-e,nash-m 等;
visualize:可视化 hbm 模型
此时输出 func 的属性如下:
Plain
#func的属性
['_Graph__flatten_inputs', '_Graph__flatten_outputs', '_Graph__handle', '_Graph__hbm_parent', '__call__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_extract_variable_data_from_file', '_get_inputs_outputs_from_snapshot', '_in_tree_spec', '_launch', '_out_tree_spec', '_process_inputs', '_run_model_on_bpu_board', '_tupled_inputs', '_verify_result', 'desc', 'feed', 'flatten_inputs', 'flatten_outputs', 'inputs', 'internal_desc', 'name', 'nodes', 'outputs', 'pickle_object', 'staged_desc', 'staged_name', 'support_pytree', 'toolkit_version', 'unique_id', 'unpickle_object'flatten_inputs/flatten_output:获取输入输出,其中输入输出的 name,type 等信息需要依赖此属性,兼容 pytree;
feed:用于 hbm 的 python 端推理,feed 的输入为 dict;
下面将以详细的代码来介绍这些接口的使用。
2.2 hbm 输入输出信息获取
Plain
from hbdk4.compiler import Hbm
def print_tensor_info(tensor_list, title):
print(f"\n===== {title} =====")
for i, tensor in enumerate(tensor_list):
print(f"\n[{title[:-1]} {i}]")
print(f" Name : {tensor.name}")
print(f" Valid Shape : {tensor.type.shape}")
print(f" Tensor Type : {tensor.type.np_dtype}")
print(f" Description : {tensor.desc}")
print(f" Strides : {tensor.type._strides}")
def main(model_path):
# 加载模型
module = Hbm(model_path)
func = module[0]
# 打印模型基本信息
print("====== Model Info ======")
print(f"Model Name : {func.name}")
print(f"Description: {func.desc}")
# 打印输入信息
print_tensor_info(func.flatten_inputs, "Inputs")
# 打印输出信息
print_tensor_info(func.outputs, "Outputs")
# 可视化模型结构(弹出图形界面)
print("\nLaunching model visualization...")
module.visualize()
if __name__ == "__main__":
model_path = "model.hbm" # 替换为你的模型路径
main(model_path)输出页面如下所示:
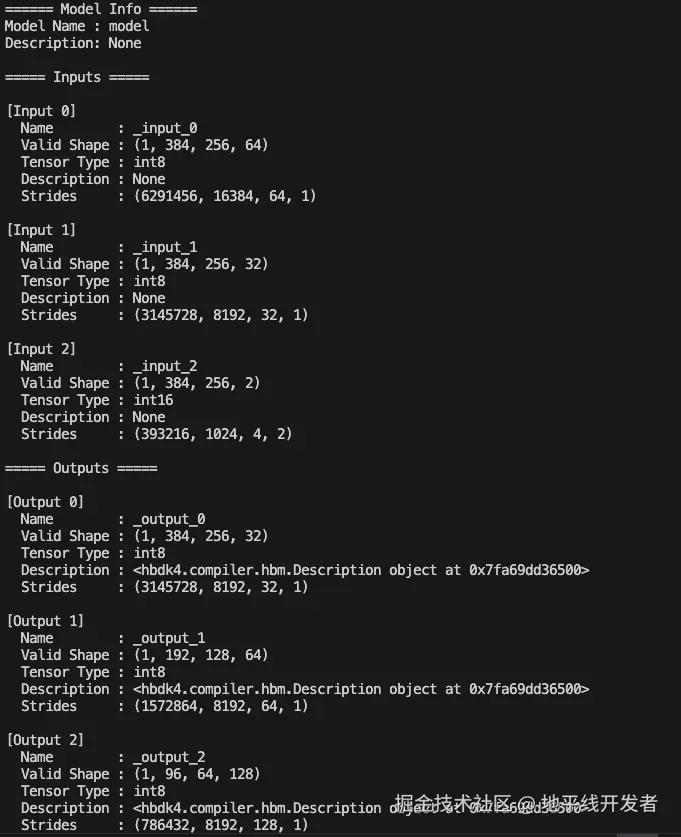
其中 hbm 的可视化可点击下图中的端口在线使用 netron 打开:
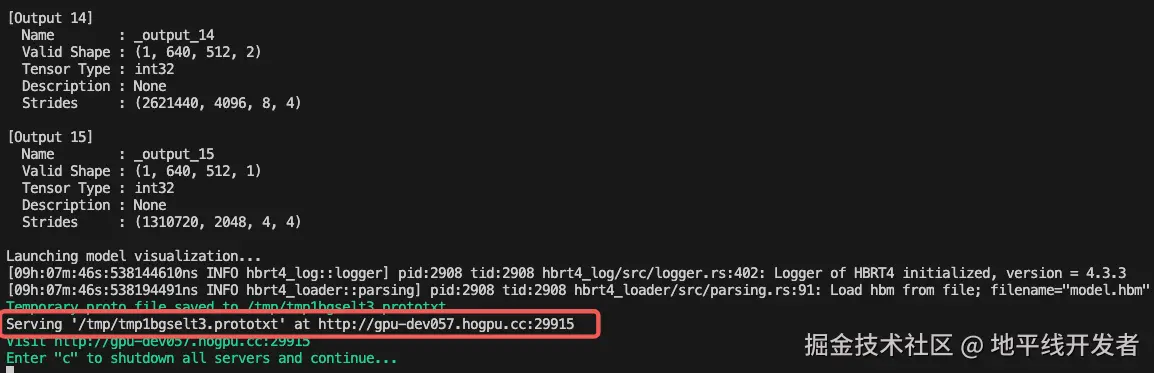
hbm 可视化页面:
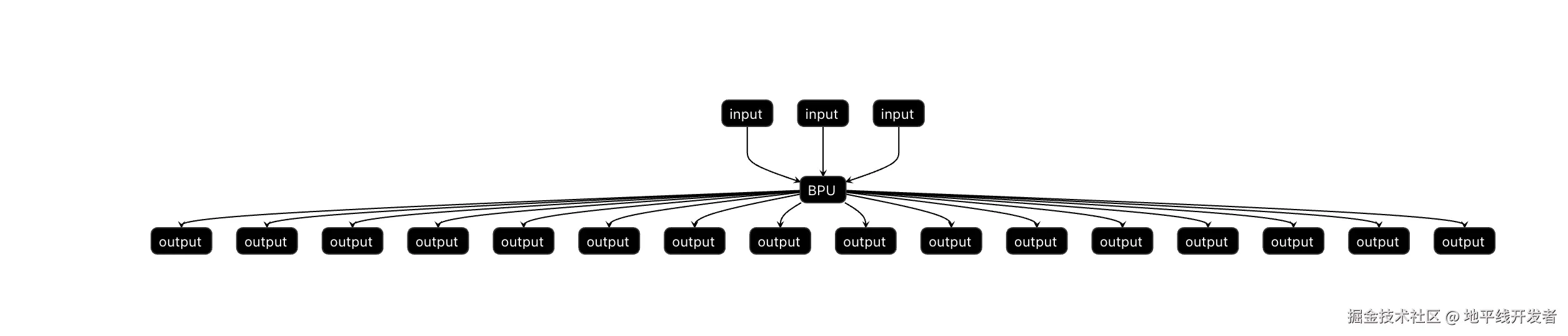
可以看出 hbm 模型是全 BPU 的。
2.3 hbm desc 信息获取与修改
Plain
from hbdk4.compiler import Hbm
def get_desc_safe(desc):
"""安全获取 desc 内容,支持 None、str、bytes 类型"""
if desc is None:
return "(no description)"
if hasattr(desc, "data"):
return desc.data
return str(desc) # 防止是 str 类型直接传进来
def print_model_info(hbm_path, title):
m = Hbm(hbm_path)
func = m.functions[0]
print(f"\n{'--'*20}{title}{'--'*20}")
print(f"Model desc : {get_desc_safe(func.desc)}")
print(f"Input[0] desc : {get_desc_safe(func.inputs[0].desc)}")
print(f"Output[0] desc : {get_desc_safe(func.outputs[0].desc)}")
return m
def update_model_desc(m):
func = m.functions[0]
func.staged_desc = "multitask v1.0"
func.inputs[0].staged_desc = b"Y input of 1x384x256x64"
func.outputs[0].staged_desc = b"bbox output"
def main():
original_file = "model.hbm"
updated_file = "updated.hbm"
# 1. 打印初始描述信息
m = print_model_info(original_file, "Initial model desc info")
# 2. 更新 staged_desc 信息并保存
update_model_desc(m)
m.save_by_staged_info(updated_file)
# 3. 读取保存后的模型并打印描述信息
print_model_info(updated_file, "Model desc after edit")
if __name__ == "__main__":
main()打印修改前后的 desc 信息:
从打印的页面可以看出,hbm 模型、inputs0、outputs0的 desc 信息已经修改完成。
2.4 python 端推理 hbm
目前使用 python 端推理 hbm 有两种方式:
调用编译器的 feed 推理接口,这种方式支持 X86 端和远程连接开发板进行推理,但是速度比较慢,仅适用于单帧推理;
使用 hbm_infer 工具远程连接开发板进行推理,在网络环境良好的情况下,这种方式推理速度比较快,优先推荐这种方式。
hbm_infer 工具请联系地平线技术支持人员获取。
下面会以简单的示例来演示两种推理方式的使用。
2.4.1 feed 接口
Plain
from hbdk4.compiler import Hbm
import numpy as np
import pickle
import time
# 模型和数据路径
hbm_path = "./model.hbm"
input_pkl_path = "data.pkl"
# 加载 HBM 模型
hbm_model = Hbm(hbm_path)
func = hbm_model.functions[0]
input_names = func.flatten_inputs
# 加载输入数据
with open(input_pkl_path, 'rb') as f:
load_data = pickle.load(f)
# 构造输入字典
input_data = {}
for i, input_tensor in enumerate(input_names):
input_data[input_tensor.name] = load_data[i].cpu().numpy()
# X86 本地推理
start_x86 = time.time()
hbm_x86_output = hbm_model[0].feed(input_data)
end_x86 = time.time()
print(f"X86 inference time: {end_x86 - start_x86:.4f} seconds")
# 板端远程推理
start_board = time.time()
hbm_board_output = hbm_model[0].feed(input_data, remote_ip="xx.xx.xx.xx")
end_board = time.time()
print(f"Board inference time: {end_board - start_board:.4f} seconds")2.4.2 hbm_infer(推荐)
Plain
from hbdk4.compiler import Hbm
import numpy as np
import pickle
import time
from hbm_infer.hbm_rpc_session_flexible import (
HbmRpcSession, init_server, deinit_server, init_hbm, deinit_hbm
)
def main():
hbm_path = "./model.hbm"
input_pkl_path = "data.pkl"
remote_ip = "xx.xx.xx.xx"
# 初始化 HBM RPC 服务与模型
hbm_rpc_server = init_server(host=remote_ip) # 注意需要 root 权限
hbm_handle = init_hbm(hbm_rpc_server=hbm_rpc_server, local_hbm_path=hbm_path)
hbm_model = HbmRpcSession(hbm_handle=hbm_handle, hbm_rpc_server=hbm_rpc_server)
print("========= BEGIN test_validate =========")
# 获取输入名称
input_names = Hbm(hbm_path)[0].flatten_inputs
# 加载输入数据
with open(input_pkl_path, 'rb') as f:
load_data = pickle.load(f)
# 构造输入数据字典
input_data = {
input_tensor.name: load_data[i].cpu().numpy()
for i, input_tensor in enumerate(input_names)
}
# 推理 + 时间统计
start_time = time.time()
hbm_arrch64_outputs = hbm_model(input_data)
end_time = time.time()
print(f"Inference time on AArch64 board: {end_time - start_time:.4f} seconds")
if __name__ == "__main__":
main()