本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院
在AI大模型应用开发中,大型语言模型(LLMs)的内在知识局限性始终是核心挑战。模型训练数据的有限性(如时效性问题和私域数据缺失)导致其无法独立处理动态或垂直领域的任务。为此,检索增强生成(RAG) 技术应运而生,并经历了从简单流水线到高度自主智能体的重大演化。本文将深入探讨RAG的技术演进、关键突破(如Agentic RAG和DeepSearch),以及未来向通用型智能体的发展趋势,为开发者提供实用洞见。
一、模型内在知识的有限性:RAG的诞生背景
LLMs的知识源于训练数据,但数据分布存在两大瓶颈:
- 时效性问题:训练数据有严格的截止日期(cut-off),无法涵盖新生信息(如实时新闻或科研进展)。
- 私域数据缺失:公开数据无法覆盖企业专有知识(如内部业务文档),导致模型在垂直场景表现不佳。 这些问题本质上是分布外泛化(OOD) 的挑战------模型在未见数据上性能下降。传统解决方式包括:
- 训练阶段增强:通过微调注入新知识,但成本高且灵活性低。
- 推理阶段增强:利用RAG技术,在生成时动态检索外部知识,通过上下文学习(ICL)提升回答质量。
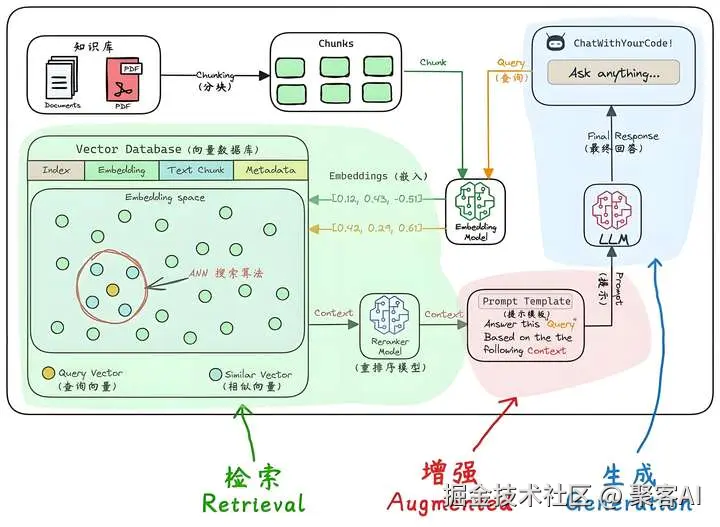
RAG的核心优势在于其"无训练"特性:直接根据用户问题,从知识库召回相关上下文,再生成答案。这成为AI应用开发的基石。
二、RAG技术的三大演进阶段:从机械到智能
RAG并非一成不变,其发展可分为三个阶段,逐步减少人工干预,增强模型自主性。
1. 阶段一:简单的固定2步骤(Naive RAG)
早期RAG采用刚性流水线:先检索后生成,单轮执行。
流程:用户问题 → 检索模块(如BM25或向量检索)→ 生成模块(LLM)。
缺点:检索质量依赖关键词匹配,易受问题表述影响;生成阶段无法迭代优化。 这一阶段是RAG的"雏形",适用于简单问答,但无法处理复杂查询。

2. 阶段二:优化用户问题与检索技术(Enhanced RAG)
为提升效果,重点优化检索环节:
用户问题优化:
基础方法:规范化、改写或扩展查询(如将"AI的未来?"扩展为"人工智能发展趋势2024")。
高级方法:
- 假设文档(Hypothetical Document):用LLM生成假想答案文档,拉近查询与目标文档的语义距离(对称相似匹配)。
- 上下文适应(Context Adaptation):结合任务上下文优化问题(如"退一步提示"技术),提升查询的独立性和完整性。
检索技术升级:
- 从文本检索到混合检索(向量+关键词)、知识图谱检索。
- 引入重排模块:使用交叉编码器(Cross-Encoder)或LLM对召回结果排序。 此阶段显著提升召回率,但仍依赖人工设计规则,灵活性不足。
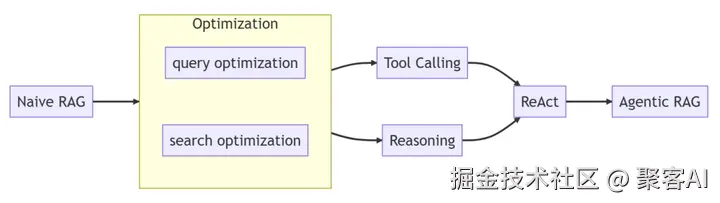
3. 阶段三:从固定工作流到自主智能体(Agentic RAG)
随着推理模型(如GPT-4、Claude)的崛起,RAG进化到Agentic范式,核心是模型自主决策:
自主性体现:
- LLM通过深度思考(Reasoning)决定检索策略:优化问题、选择工具、判断是否继续搜索。
- 循环执行:基于结果动态调整,直至收集足够知识(如多轮检索)。
技术框架:
- 基于ReAct框架(Reasoning + Action),模型推理触发工具调用(如搜索API)。
- 升级为工具增强生成(TAG) 或 工具集成推理(TIR):工具与模型能力深度融合。

Agentic RAG的核心优势在于其泛化性:无需预定义规则,适应动态环境。例如,面对"分析最新AI论文"的查询,模型可自主分解子问题、检索arXiv并综合生成报告。
三、Agentic RAG的边界条件:知识边界 vs 能力边界
智能体的自主性面临两大边界挑战,需外部资源弥合:
知识边界:模型内在知识不足以覆盖问题(如专业医疗数据)。
- 解决方案:通过信息检索工具(如搜索引擎或知识库)获取外部知识。
- 类比:类似CPU从内存读取数据,若缺失则访问外存(互联网或数据库)。
能力边界:模型执行能力不足(如数值计算或代码执行)。
- 解决方案:调用外部工具(如计算器、代码解释器)。
- 关键点:知识边界是理论基础,能力边界是实践拓展------二者相辅相成。例如,检索到代码片段后需解释器执行验证。
边界问题的解决依赖模型推理能力:模型需判断"知识/能力缺口"并触发工具。这推动了训练范式从监督微调(SFT)向强化学习(RL)转变,以优化长期决策能力(如PPO算法)。
四、DeepSearch:Agentic RAG的落地实践
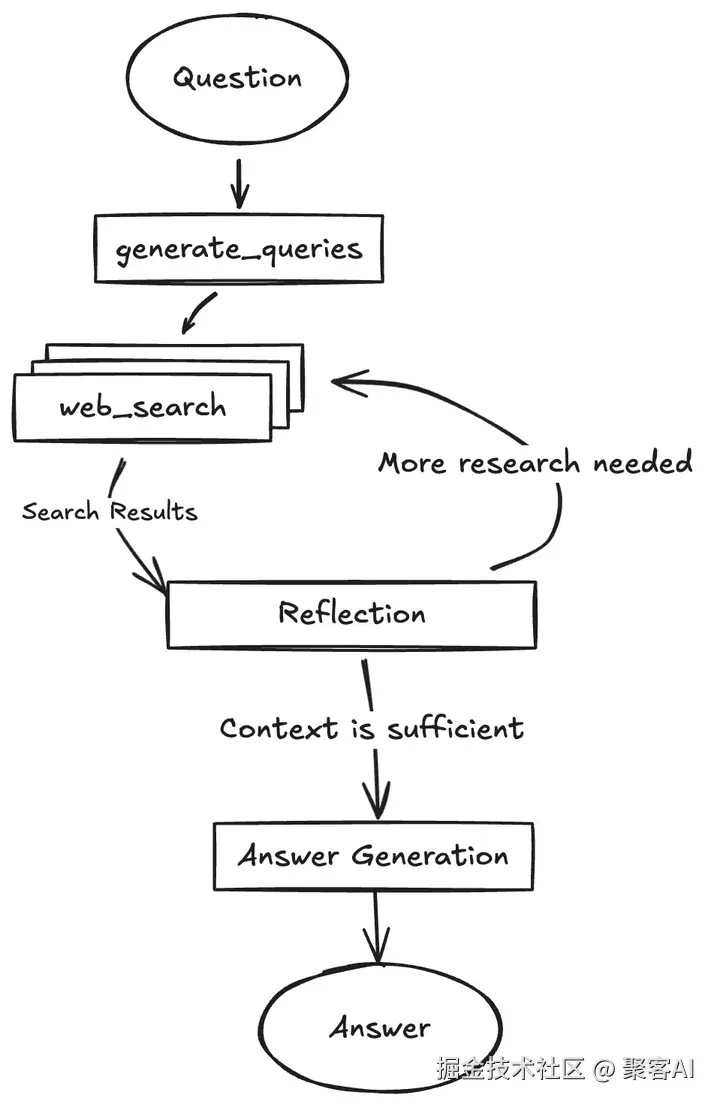
DeepSearch(或DeepResearch)是Agentic RAG的典型应用,代表企业包括Jina AI、Google Gemini等。其核心是模型驱动的深度搜索循环:
- 流程:
- LLM分析问题,生成检索查询(Gap-Driven Query)。
- 检索工具获取外部知识。
- LLM评估知识充分性,若不满足则迭代优化。
- 案例对比:
Jina AI DeepSearch:强调查询优化和结果综合,适用于研究场景。

- Google Gemini Search Agent:集成多工具(如网页搜索和学术数据库),支持复杂任务处理。
DeepSearch已扩展至垂直领域:
- Coding Agent(如Devin、Cursor):结合代码检索与执行,实现自动编程。
- Browser Agent(如Firefox AI插件):实时网页交互,处理动态信息。 AI Search是这些应用的"基础层"------如同人类需先阅读才能创作。
五、未来展望:从专用工具到通用智能体
RAG技术的演进方向明确:
- 模型能力提升:推理模型持续优化(如MoE架构),强化自主决策。
- 多智能体系统:多个Agent协同(如Search Agent + Coding Agent),解决跨域任务(如自动科研分析)。
- 训练范式革新:RL后训练成为主流(如Kimi-Researcher项目),以学习长周期决策。
- 通用型智能体:目标是以AI Search为核心,整合工具库,迈向AGI(如OpenAI的GPT-5愿景)。
作者结语
RAG从简单的检索增强工具,演化为自主智能体的"大脑",解决了LLMs的知识和能力边界问题。其核心在于信息(知识)与工具(能力)的双轮驱动,而模型推理能力是融合二者的关键。作为开发者,拥抱Agentic RAG和DeepSearch范式,将大幅提升应用智能化水平------未来属于能"自主思考"的AI系统。更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。